
Sensitivity analysis of selection bias: a graphical display by bias-correction index
- Published
- Accepted
- Received
- Academic Editor
- Gregory Gilbert
- Subject Areas
- Epidemiology, Public Health, Statistics
- Keywords
- Selection bias, Bias-correction, Sensitivity analysis, Health survey, Observational study
- Copyright
- © 2023 Chung and Lin
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ) and either DOI or URL of the article must be cited.
- Cite this article
- 2023. Sensitivity analysis of selection bias: a graphical display by bias-correction index. PeerJ 11:e16411 https://doi.org/10.7717/peerj.16411
Abstract
Background
In observational studies, how the magnitude of potential selection bias in a sensitivity analysis can be quantified is rarely discussed. The purpose of this study was to develop a sensitivity analysis strategy by using the bias-correction index (BCI) approach for quantifying the influence and direction of selection bias.
Methods
We used a BCI, a function of selection probabilities conditional on outcome and covariates, with different selection bias scenarios in a logistic regression setting. A bias-correction sensitivity plot was illustrated to analyze the associations between proctoscopy examination and sociodemographic variables obtained using the data from the Taiwan National Health Interview Survey (NHIS) and of a subset of individuals who consented to having their health insurance data further linked.
Results
We included 15,247 people aged ≥20 years, and 87.74% of whom signed the informed consent. When the entire sample was considered, smokers were less likely to undergo proctoscopic examination (odds ratio (OR): 0.69, 95% CI [0.57–0.84]), than nonsmokers were. When the data of only the people who provided consent were considered, the OR was 0.76 (95% CI [0.62–0.94]). The bias-correction sensitivity plot indicated varying ORs under different degrees of selection bias.
Conclusions
When data are only available in a subsample of a population, a bias-correction sensitivity plot can be used to easily visualize varying ORs under different selection bias scenarios. The similar strategy can be applied to models other than logistic regression if an appropriate BCI is derived.
Introduction
In observational studies, estimates of the association between certain characteristics and outcomes of interest based on only a subsample of selected participants may be misleading because of selection bias. Selection bias occurs when certain characteristics influence the likelihood of inclusion or exclusion from a sample. This kind of bias cannot be corrected unless additional information regarding to those who were not selected to the sample is available. Statistical strategies for eliminating selection bias include standardization (Hernan & Robins, 2006), inverse probability weighting (Gustafson et al., 2013), and the Heckman two-stage sample selection model (Heckman, 1976). However, these methods require supplementary data to be obtained from the target population. When these data are not available, sensitivity analysis may be conducted to determine the possible magnitude and direction of the selection bias. However, this analysis requires user-specified selection bias parameters, which are based on subjective guesses or on other studies with high transportability (Infante-Rivard & Cusson, 2018).
The magnitude of selection bias on the coefficient of interest can be determined by the influence of outcome and covariates on their selection probability. Few studies, however, have analyzed how these selection probabilities are determined and incorporated as a means of quantifying the magnitude and direction of the potential selection bias in sensitivity analysis. In this study, we focused on practical issues regarding how to quantify and visualize the effect of selection bias in sensitivity analysis with regression models and demonstrated our strategy by using real data. A bias-correction index (BCI) was used to quantify potential selection bias through sensitivity analysis in the absence of external data. In the next sections, we begin with a brief theoretical introduction of six selection bias scenarios in a logistic regression setting (Hosmer & Lemeshow, 2000) and demonstrate how such bias can influence estimates of variable of interest. Finally, a bias-correction sensitivity plot was illustrated to present varying possible estimates under different selection bias scenarios by using data from the National Health Interview Survey (NHIS) in Taiwan, which was conducted among a subsample of individuals who consented to the national health insurance data linkage.
Methods
Selection bias due to of selected participants’ characteristics
Suppose that we are interested in the association between a binary exposure, X, and a binary outcome, Y, where Y =1 is the event of interest. Z denotes a potential confounder of the associations between X and Y. We assume the probability of interested outcome in a population given X and Z as logit P(Y = 1|X, Z) = β0 + β1X + β2Z, where β1 is a parameter of interest. To describe how selection bias influences parameter estimation, we introduce the indicator S, which equals 1 when an individual is selected for the survey sample and 0 otherwise. The probability of an individual being willing to participate (or being selected) in a study can be expressed as a linear logistic form logit P(S = 1|Y , X, Z) = α0 + α1Y + α2X + α3Z. The linear logistic transformation of outcome prevalence with selection bias among selected participants can be written as is a function of coefficients from the equation of , which is called BCI. As seen in the equation: logit P(Y = 1|X, Z, S = 1), BCI is a term that corresponds to the difference between the estimate in the outcome model for the target and that from the sample. Ergo, the BCI represents the bias.
When Z is not only a confounder but also an effect measure modifier in the association between X and Y, it adds complexity to selection bias estimation. We also present another linear logistic form with an interaction term: logit P(Y = 1|X, Z, XZ) = β0 + β1X + β2Z + β3XZ, where β1 is a parameter of interest. Z denotes effect measure modifier. The probability of an individual being willing to participate in a study is written as logit P(S = 1|Y , X, Z, XZ) = α0 + α1Y + α2X + α3Z + α4XZ. The outcome prevalence model with selection bias among the selected participants can be written as is equal to .
There may be many factors influencing participants’ willingness to participate in a study. ∅(α; Y , X) can take different forms, depending on selection probabilities, and these differences directly affect the outcome model. Six scenarios of participant selection models are listed below. Scenarios 1-5 are based on the outcome model without interaction in the population, and Scenario 6 represents a general form of BCI with selection probability depending on Y, X, Z, and XZ.
• Scenario 1: The selection of participants is affected by neither Y nor X.
Selection model: logit P(S = 1|Y , X, Z) = P(S = 1) = α0
Outcome model with selection bias among selected participants: logit P(Y = 1|X, Z, S = 1) = β0 + β1X + β2Z
• Scenario 2: The selection of participants is affected only by Y.
Selection model: logit P(S = 1|Y , X, Z) = P(S = 1|Y ) = α0 + α1Y
Outcome model with selection bias among selected participant: logit P(Y = 1|X, Z, S = 1) =
• Scenario 3: The selection of participants is affected only by X.
Selection model: logit P(S = 1|Y , X, Z) = P(S = 1|X) = α0 + α2X
Outcome model with selection bias among selected participant: logit P(Y = 1|X, Z, S = 1) = β0 + β1X + β2Z
• Scenario 4: The selection of participants is affected by both Y and X.
Selection model: logit P(S = 1|Y , X, Z) = P(S = 1|Y , X) = α0 + α1Y + α2X
Outcome model with selection bias among selected participant:
• Scenario 5:The selection of participants is affected by Y, X and Z.
Z is a confounder variable.
Selection model: P(S = 1|Y , X, Z) = P(S = 1|Y , X, Z) = α0 + α1Y + α2X + α3Z
Outcome model with selection bias among selected participant:
• Scenario 6:The selection of participants is affected by Y, X and Z.
Z is an effect measure modifier.
Selection model: P (S = 1 | Y,X,Z,XZ) = P(S = 1 | Y, X,Z,XZ) = α0 + α1Y + α2X + α3Z + α4XZ
Outcome model with selection bias among selected subjects:
A detailed derivation is shown in Appendix S1. In Appendix S1, it is shown that the probability P (Y = 1 | X, Z, S = 1) can be expressed as a function of P (Y | X, Z) and P (S | Y, X, Z). This observation makes it possible to express P (Y = 1 | X, Z, S = 1) as an equation containing both ∅(α;Y,X) and β0 + β1X + β2Z.
Correction for selection bias and sensitivity analysis
Scenarios 4–6 indicate that when selection probability is influenced by both X and Y, the coefficient of X (the parameter of interest) is biased. For the outcome model without interactions between X and Z (Scenario 5), where selection probability is affected by X, Y, and Z, a BCI is as follows. Bias correction index (BCI) = . When external data are available to estimate the BCI, the selection bias may be corrected by including the BCI as an offset in the outcome model. However, when external data are not available, the conditional probability of selection P (S = 1 | Y, X, Z) with the selection parameters (α0, α1, α2, α3) is unknown. To quantify the magnitude of bias for the odds ratio (OR) of interest, selection parameters (α) can be determined based on the researchers’ understanding of the participants. Alternatively, α can be set within a range of values. We performed sensitivity analyses by assuming selection probability model with different parameters (α1, α2) and presents the results using a graphical display. In the next section, we will illustrate how to construct a bias-correction sensitivity plot, which shows varying possible bias-corrected ORs under different magnitudes of selection parameters.
Application: analysis of survey data with potential selection bias
National Health Interview Survey (NHIS)
The NHIS in Taiwan involves a national representative sample and has been conducted every four years since 2001. The survey is conducted using a multistage stratified systematic sampling design, with sample selection based on probability proportional to size. Goodness-of-fit tests revealed no significant differences of urbanization level, sex, and age between the survey sample and household registration data (National Health Research Institutes & Health Promotion Administration (HPA) of the Ministry of Health and Welfare (MOHW) of Taiwan, 2019).
The NHIS database can be linked to Taiwan’s National Health Insurance Research database (NHIRD) to explore the associations between disease, health utilization outcomes, and health behaviors. The National Health Insurance is a mandatory program for all citizens in Taiwan with coverage rate over 99% (Hsieh et al., 2019). For NHIS data to be linked with the NHIRD, participants in the NHIS must provide written informed consent. The following section will illustrate the practice of a sensitivity analysis using the NHIS data of only those who consented to the data linkage.
The NHIS questionnaires and variables
We used the 2001 NHIS database to perform the sensitivity analysis because these data are often used to link to the NHIRD or cancer registries for long-term follow-up studies (Dai et al., 2020; Lo et al., 2022). This study was approved by the Institutional Review Board (IRB) of National Yang-Ming University (YM108041E).
Interviewers asked all participants through standard questionnaires and collected basic demographic data including age, sex, marital status and education level. Because smokers have a higher risk of colitis and colorectal cancer (Giovannucci, 2002; Srivastava et al., 1990), we hypothesized that nonsmokers have greater health consciousness and are more willing to undergo proctoscopic examination, which served as an example to introduce BCI. Participants were asked whether they had ever smoked in their lives (binary; X; 1 = yes, 0 = no), had undergone a proctoscopic examination in the past year (Y; 1 = yes, 0 = no), and had signed the informed consent for NHIRD linkage (S; 1 = yes, 0 = no).
The parameter of interest was the OR of the association between proctoscopic examination (Y) and smoking status (SMOKE) after adjusting for sex. We performed a sensitivity analysis assuming that data were only available for participants who consented to NHIRD linkage (S = 1). Details regarding variable information and model specifications are described in the following sections.
The main model can be presented as follows: logit P (Y = 1 | smoke, sex) = β0 + β1smoke + β2sex.
Based on previous literature (Tolonen, Dobson & Kulathinal, 2005), health behavior may influence the participants’ willingness to participate in a study. We supposed that both proctoscopic examination (Y) and smoking status (SMOKE) were related to study participation (S = 1) and that sex was not. The selection model can be presented as follows: .
The bias-corrected model is rewritten as follows (Scenario 4): , where BCI = .
In practice, researchers may determine the range of α based on their prior understanding of the relationship between S and other variables. A range of positive and negative α values are included if no prior information is available. The value of α0 is set as 1.96 on the basis of the data, which indicates that marginal proportion of individuals that consented to linkage P(S = 1) was approximately 88%. The bias parameters (α1, α2) were set to between −2.5 and 2.5, with an increment of 0.3 for each value. The BCIs were calculated using varying combinations of (α1, α2). Then, the bias-corrected ORs of SMOKE and Y were calculated using different BCIs. A bias-correction sensitivity plot was performed by BCI to understand how selection bias influenced the estimate of the variable of interest (exposure-outcome relationship).
In addition to the sensitivity analysis, we also calculated the OR without selection bias (i.e., the OR based on the entire data) for demonstration, so that readers can observe the influence of varying BCIs. In practice, the OR without selection bias is unknown. However, the data of individuals who did not provide informed consent for NHIRD linkage (S = 0) are available. Therefore, in the present study, we were able to demonstrate the difference between the target estimate based on the entire data obtained from the main model and that based on the selected sample obtained from the outcome model in the bias-correction sensitivity plot.
All analyses were conducted two-sided with alpha set at 0.05. We conducted all statistical analyses and generated all charts by using lme4 (Bates et al., 2015), jtools (Long, 2020) and ggplot2 (Wickham, 2016) packages of R (version 4.0.0; R Core Team, 2020).
Results
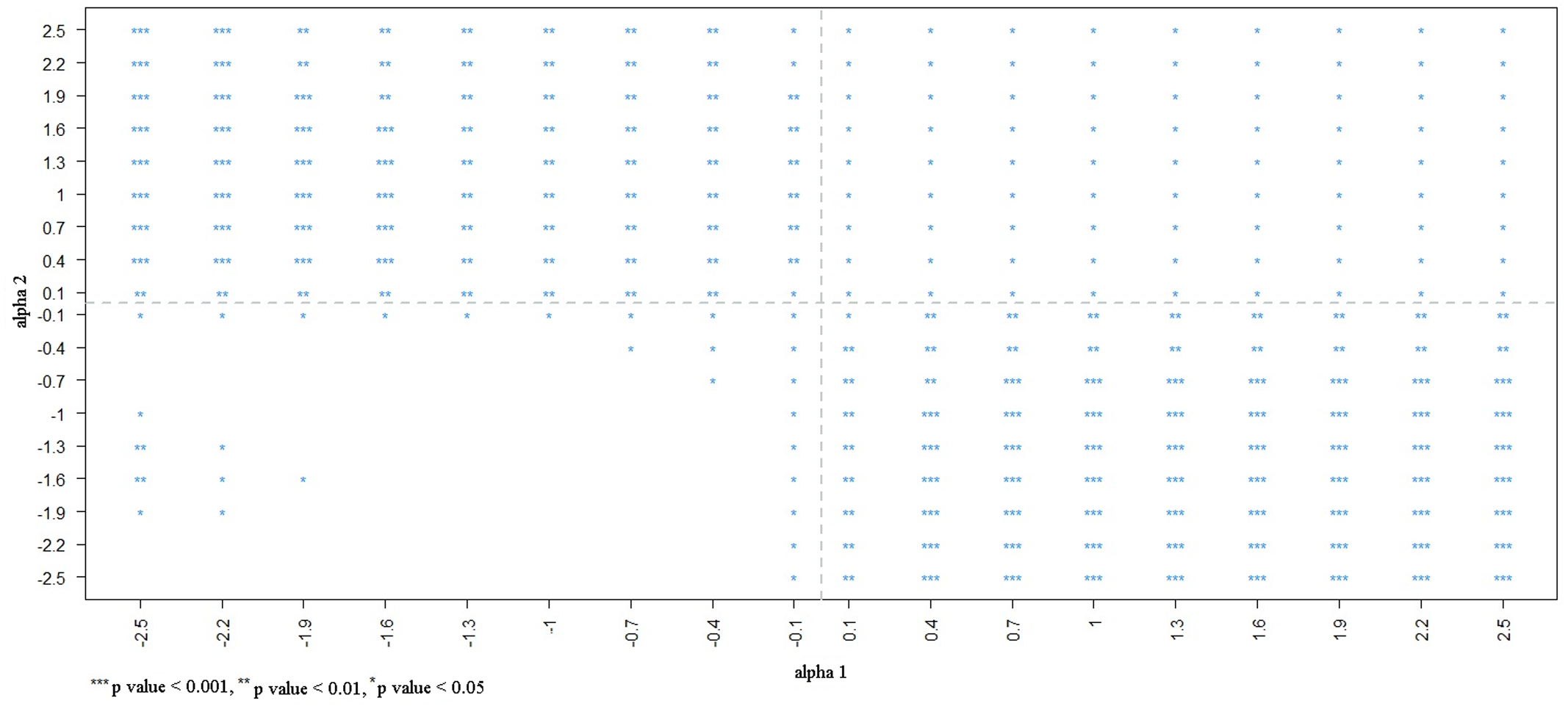
We identified 15,247 individuals aged ≥20 years from the 2001 NHIS, 87.74% of whom provided informed consent for their data to be linked. Among the consenting population, smokers were less likely to undergo proctoscopic examination than nonsmokers were (OR: 0.76; 95% CI [0.62–0.94]). To evaluate the potential influence of selection bias, a sensitivity analysis was performed. Figure 1 presents the estimates corrected by BCI under different degrees of selection bias. The estimated OR based on the selected sample (S = 1) is marked in purple. In the bias-correction sensitivity plot, the bias-corrected parameters [log(OR)] beyond or below two standard errors (0.21) of the estimate obtained from the selected sample (OR = 0.76) corresponded to bias parameters α1 ≤−1.0 and α2 ≤ −1.0, and α1 ≥ 1.0 and α2 ≤ −1.3, which are marked in red. When the bias parameters (α1, α2) were extremely negative (≤−1.0), the smoking effect changed from being a risk factor to a protective factor for proctoscopic examination, rendering the significant association nonsignificant. At values < −0.4, the significant association between smoking status and proctoscopic examination became nonsignificant (Fig. 2).
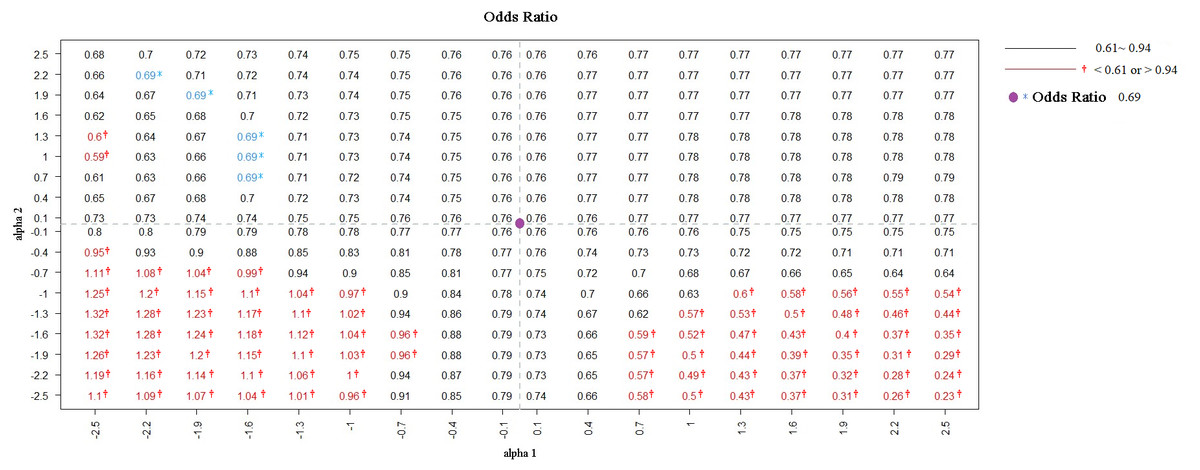
Figure 1: ORs were adjusted by BCI in diûerent degrees of selection bias from NHIS selected sample.
Note. Purple dot is the intersection of the two dotted lines representing the OR = 0.76 among the selected sample (S = 1). The OR = 0.69 was marked in blue (unobserved).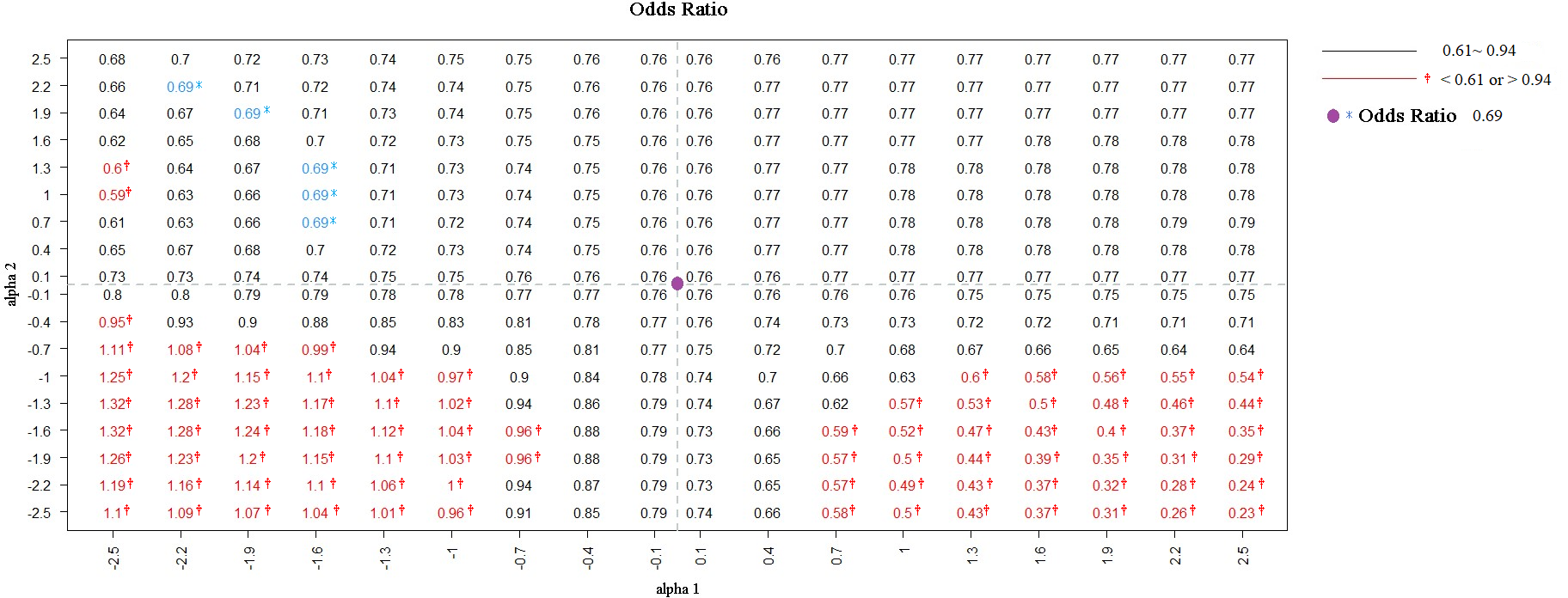{kind=link}
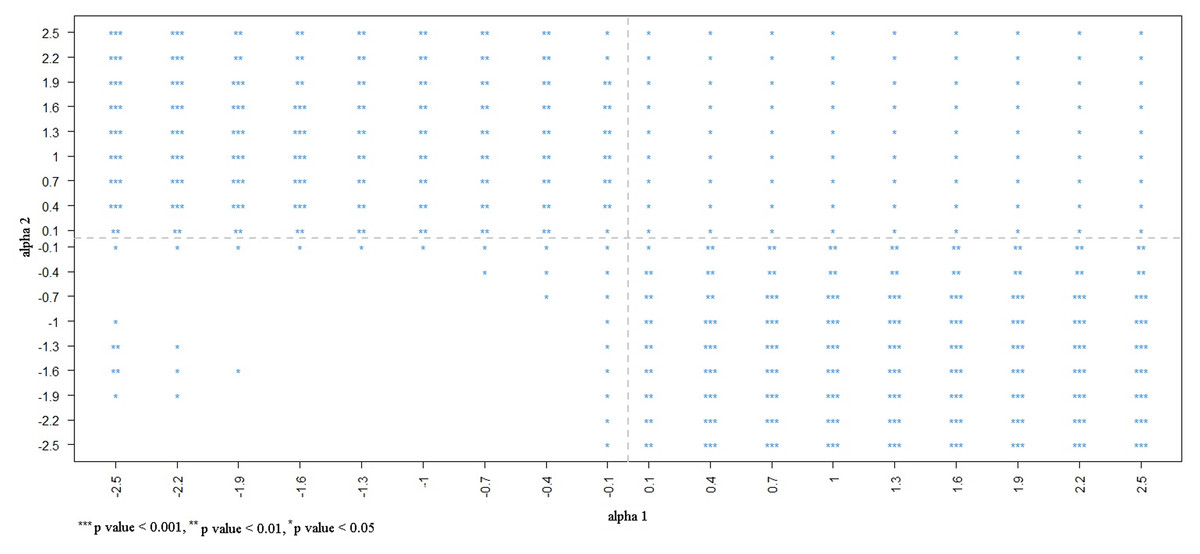
Figure 2: Statistical significance in different degrees of selection bias from NHIS selected sample.
{kind=link}
For illustrative purpose, if we performed the same analysis using the entire data without selection bias, the estimated OR was 0.69 (95% CI [0.57–0.84]; in Fig. 1), showing that smokers were less likely to undergo proctoscopic examination, which is similar to the results obtained using only the selected sample (S = 1). However, the OR of 0.69 was not observed in practice when only the data of a selected sample were available. If we wanted to get an OR of 0.69 based on the selected sample, we would need to set α1 at approximately −1.6 to −2.2 and α2 at about 0.7 to 2.2. This indicated that individuals who underwent proctoscopy and smokers were 0.1–0.2 and 2–9 times, respectively, more likely to sign an informed consent form. When the bias parameter α1 took an extreme value and α2 took extreme negative values (far away from 0), the bias-corrected OR was markedly different from had large difference with the estimate based on the entire data without selection bias.
Discussion
In our analysis of the data from individuals who consented to NHIRD linkage, the estimated OR (0.76) was slightly higher than that (0.69) based on the entire data set, implying minor selection bias.
When α1 and α2 were both less than −1 (i.e., smokers had odds of participation of 0.37 [exp(−1)] or even lower than that of nonsmokers), the negative association between smoking status and proctoscopic examination had the potential to become a positive association (lower left red area of Fig. 1). When α1 was greater than 1.9 (i.e., those who underwent proctoscopic examination tended to participate in the study) and α2 was less than −1.9 (i.e., smokers had odds of participation of 0.15 [exp(−1.9)] or even lower than that of nonsmokers), the negative association between smoking status and proctoscopic examination had the potential to be exaggerated (lower right red area of Fig. 1). However, given that these two extreme situations are unlikely in practice, we can consider the estimates from the selected sample to be reliable.
Our results reveal the following scenarios. When selection probability is associated with neither the main predictor (X) nor the outcome (Y) (Scenario 1), the OR point estimate is unbiased. However, because the sample size of the selected sample is smaller than the entire sample, the confidence interval is wider. When selection probability is only associated with the main predictor (X) and not with the outcome (Y) (Scenario 3), the OR point estimate is unbiased. When selection probability is only associated with the outcome (Y), not with the main predictor (X) (Scenario 2), the OR point estimate is unbiased but the intercept changes. When selection probability is associated with both the main predictor (X) and outcome (Y) (Scenario 4), the OR point estimate and intercept are both biased.
Thompson & Arah (2014) used inverse probability weighting and externally obtained bias parameters to adjust selection bias, and this method can be applied to any type of observational study. The Heckman model includes a sample selection equation and main equation, and the main equation links the covariates of interest to the outcome (Heckman, 1976). However, implementing these methods can be challenging when external data containing information regarding the characteristics of the underlying source population are not available.
Through a bias-correction sensitivity plot, we can easily figure out the possible range of estimates obtained from a selected sample. The worst scenario with respect to selection bias occurs when participant selection in a specific study is related to both the exposure and outcome of the study. However, by evaluating the association between selection probability and key variables, researchers can quantify the magnitude of bias and boost confidence in the estimate of interested exposure-outcome relation, even when the data of non-participants are unavailable.
The BCI in this study was derived using a logistic outcome model, and a similar strategy may be applied for different outcome models. For example, when the main outcome model is a linear regression with a continuous outcome variable (Y), because the association of the expected value of Y is linear to the coefficients, a BCI can be constructed by the selection model.
This study has some limitations. In practice, the bias parameters in developed selection model need to be determined before the model is implemented, and justification for selected values is quite arbitrary. Researchers can select a broad but reasonable range of parameter values to figure out possible outcomes. However, interpretation of the association would not be easier because of the broad range of values.
Conclusions
This study presents a visualized sensitivity analysis by given reasonable selection parameters to obtain the magnitude and direction of selection bias. We demonstrated the application of this analysis by using real-world data and provided a step-by-step explanation to guide readers of its implementation. When selection bias is unavoidable, we encourage researchers to be cautious and perform bias-correction sensitivity plot by following our steps, especially when no external data are available for correction. Our strategy can be applied to models other than logistic regression if an appropriate BCI is derived.