
SKIMMR: facilitating knowledge discovery in life sciences by machine-aided skim reading
- Published
- Accepted
- Received
- Academic Editor
- Harry Hochheiser
- Subject Areas
- Bioinformatics, Computational Science, Human-Computer Interaction, Neuroscience
- Keywords
- Machine reading, Skim reading, Publication search, Text mining, Information visualisation
- Copyright
- © 2014 Nováček and Burns
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
- Cite this article
- 2014. SKIMMR: facilitating knowledge discovery in life sciences by machine-aided skim reading. PeerJ 2:e483 https://doi.org/10.7717/peerj.483
Abstract
Background. Unlike full reading, ‘skim-reading’ involves the process of looking quickly over information in an attempt to cover more material whilst still being able to retain a superficial view of the underlying content. Within this work, we specifically emulate this natural human activity by providing a dynamic graph-based view of entities automatically extracted from text. For the extraction, we use shallow parsing, co-occurrence analysis and semantic similarity computation techniques. Our main motivation is to assist biomedical researchers and clinicians in coping with increasingly large amounts of potentially relevant articles that are being published ongoingly in life sciences.
Methods. To construct the high-level network overview of articles, we extract weighted binary statements from the text. We consider two types of these statements, co-occurrence and similarity, both organised in the same distributional representation (i.e., in a vector-space model). For the co-occurrence weights, we use point-wise mutual information that indicates the degree of non-random association between two co-occurring entities. For computing the similarity statement weights, we use cosine distance based on the relevant co-occurrence vectors. These statements are used to build fuzzy indices of terms, statements and provenance article identifiers, which support fuzzy querying and subsequent result ranking. These indexing and querying processes are then used to construct a graph-based interface for searching and browsing entity networks extracted from articles, as well as articles relevant to the networks being browsed. Last but not least, we describe a methodology for automated experimental evaluation of the presented approach. The method uses formal comparison of the graphs generated by our tool to relevant gold standards based on manually curated PubMed, TREC challenge and MeSH data.
Results. We provide a web-based prototype (called ‘SKIMMR’) that generates a network of inter-related entities from a set of documents which a user may explore through our interface. When a particular area of the entity network looks interesting to a user, the tool displays the documents that are the most relevant to those entities of interest currently shown in the network. We present this as a methodology for browsing a collection of research articles. To illustrate the practical applicability of SKIMMR, we present examples of its use in the domains of Spinal Muscular Atrophy and Parkinson’s Disease. Finally, we report on the results of experimental evaluation using the two domains and one additional dataset based on the TREC challenge. The results show how the presented method for machine-aided skim reading outperforms tools like PubMed regarding focused browsing and informativeness of the browsing context.
Introduction
In recent years, knowledge workers in life sciences are increasingly overwhelmed by an ever-growing quantity of information. PubMed1 contained more than 23 million abstracts as of November 2013, with a new entry being added every minute. The current textual content available online as PubMed abstracts amount to over 2 billion words (based on estimates derived from a random sample of about 7,000 records). Information retrieval technology helps researchers pinpoint individual papers of interest within the overall mass of documents, but how can scientists use that to acquire a sense of the overall organization of the field? How can users discover new knowledge within the literature when they might not know what they are looking for ahead of time?
Strategic reading aided by computerised solutions may soon become essential for scientists (Renear & Palmer, 2009). Our goal is to provide a system that can assist readers to explore large numbers of documents efficiently. We present ‘machine-aided skim-reading’ as a way to extend the traditional paradigm of searching and browsing a text collection (in this case, PubMed abstracts) through the use of a search tool. Instead of issuing a series of queries to reveal lists of ranked documents that may contain elements of interest, we let the user search and browse a network of entities and relations that are explicitly or implicitly present in the texts. This provides a simplified and high-level overview of the domain covered by the text, and allows users to identify and focus on items of interest without having to read any text directly. Upon discovering an entity of interest, the user may transition from our ‘skimming’ approach to read the relevant texts as needed.
This article is organised as follows. ‘Methods’ describes methods used in SKIMMR for: (1) extraction of biomedical entities from data; (2) computation of the co-occurrence and similarity relationships between the entities; (3) indexing and querying of the resulting knowledge base; (4) evaluating the knowledge base using automated simulations. Each of the methods is explained using examples. ‘Results’ presents the SKIMMR prototype and explains typical usage of the tool in examples based on user interactions. We also describe evaluation experiments performed with three different instances of the tool. In ‘Discussion’ we discuss the results, give an overview of related work and outline our future directions. There is also ‘Formulae Definitions’ that provides details on some of the more complex formulae introduced in the main text.
The main contributions of the presented work are: (1) machine-aided skim-reading as a new approach to semi-automated knowledge discovery; (2) fuzzy indexing and querying method for efficient on-demand construction and presentation of the high-level graph-based article summaries; (3) detailed examples that explain the applied methods in a step-by-step fashion even to people with little or no computer science background; (4) an open-source prototype implementing the described method, readily available for processing custom data, and also in the form of two pre-computed instances deployed on Spinal Muscular Atrophy and Parkinson’s Disease data; (5) an evaluation methodology based on simulations and formally defined measures of semantic coherence, information content and complexity that can be used not only for evaluating SKIMMR (as we did in the article), but also for assessment of other tools and data sets utilising graph structures.
Methods
This section describes how the knowledge base supporting the process of machine-aided skim reading is generated from the input data (i.e., biomedical articles and data). Firstly we describe extraction of entities and basic co-occurrence relationships between them (‘Extracting basic co-occurrence statements from texts’). ‘Computing a knowledge base from the extracted statements’ is about how we compute more general, corpus-wide relationships from the basic extracted co-occurrence statements. ‘Indexing and querying the knowledge base’ explains how the processed content can be indexed and queried in order to generate the graph-based summaries with links to the original documents. Finally, ‘Evaluation methodology’ introduces a method for a simulation-based evaluation of the generated content in the context of machine-aided skim reading. For the research reported in this article, we received an exemption from IRB review by the USC UPIRB, under approval number UP-12-00414.
Extracting basic co-occurrence statements from texts
We process the abstracts by a biomedical text-mining tool2 in order to extract named entities (e.g., drugs, genes, diseases or cells) from the text. For each abstract with a PubMed ID PMID, we produce a set of (ex, ey, cooc((ex, ey), PubMedPMID), PubMedPMID) tuples, where ex, ey range over all pairs of named entities in the abstract with the PMID identifier, and cooc((ex, ey), PubMedPMID) is a co-occurrence score of the two entities computed using the formula (1) detailed in ‘Co-occurrences’. The computation of the score is illustrated in the following example.
Imagine we want to investigate the co-occurrence of the parkinsonism and DRD (dopamine-responsive dystopia) concepts in a data set of PubMed abstracts concerned with clinical aspects of Parkinson’s disease.3 There are two articles in the data set where the corresponding terms co-occur:
Jeon BS, et al. Dopamine transporter density measured by 123Ibeta-CIT single-photon emission computed tomography is normal in dopa-responsive dystonia (PubMed ID: 9629849).
Snow BJ, et al. Positron emission tomographic studies of dopa-responsive dystonia and early-onset idiopathic parkinsonism (PubMed ID: 8239569).
| … | … |
| 12 | Therefore, we performed 123Ibeta-CIT single-photon emission computed tomography (123Ibeta-CIT SPECT) in clinically diagnosed DRD, PD, and JPD, and examined whether DAT imaging can differentiate DRD from PD and JPD. |
| … | … |
| 14 | Five females (4 from two families, and 1 sporadic) were diagnosed as DRD based on early-onset foot dystonia and progressive parkinsonism beginning at ages 7–12. |
| … | … |
| 17 | 123Ibeta-CIT striatal binding was normal in DRD, whereas it was markedly decreased in PD and JPD. |
| … | … |
| 22 | A normal striatal DAT in a parkinsonian patient is evidence for a nondegenerative cause of parkinsonism and differentiates DRD from JPD. |
| 23 | Finding a new mutation in one family and failure to demonstrate mutations in the putative gene in other cases supports the usefulness of DAT imaging in diagnosing DRD. |
| 1 | There are two major syndromes presenting in the early decades of life with dystonia and parkinsonism: dopa-responsive dystonia (DRD) and early-onset idiopathic parkinsonism (EOIP). |
| 2 |
DRD presents predominantly in childhood with prominent dystonia and lesser degrees of parkinsonism. |
| … | … |
| 5 | Some have suggested, however, that DRD is a form of EOIP. |
| … | … |
Computing a knowledge base from the extracted statements
From the basic co-occurrence statements, we compute a knowledge base, which is a comprehensive network of interlinked entities. This network supports the process of navigating a skeletal structure of the knowledge represented by the corpus of the input PubMed articles (i.e., the actual skim reading). The knowledge base consists of two types of statements: (1) corpus-wide co-occurrence and (2) similarity. The way to compute the particular types of statements in the knowledge base is described in the following two sections.
Corpus-wide co-occurrence
The basic co-occurrence tuples extracted from the PubMed abstracts only express the co-occurrence scores at the level of particular documents. We need to aggregate these scores to examine co-occurrence across the whole corpus. For that, we use point-wise mutual information (Manning, Raghavan & Schütze, 2008), which determines how much two co-occurring terms are associated or disassociated, comparing their joint and individual distributions over a data set. We multiply the point-wise mutual information value by the absolute frequency of the co-occurrence in the corpus to prioritise more frequent phenomena. Finally, we filter and normalise values so that the results contain only scores in the [0, 1] range. The scores are computed using the formulae (2)–(5) in ‘Co-occurrences’.
The aggregated co-occurrence statements that are added to the knowledge base are in the form of (x, cooc, y, ν(fpmi(x, y), P)) triples, where x, y range through all terms in the basic co-occurrence statements, the scores are computed across all the documents where x, y co-occur, and the cooc expression indicates co-occurrence as the actual type of the relation between x, y. Note that the co-occurrence relation is symmetric, meaning that if (x, cooc, y, w1) and (y, cooc, x, w2) are in the knowledge base, w1 must be equal to w2.
Assuming our corpus consists only of the two articles from Example 1, the point-wise mutual information score of the (parkinsonism,DRD) tuple can be computed using the following data:
p(parkinsonism, DRD)–joint distribution of the (parkinsonism,DRD) tuple within all the tuples extracted from the PubMed abstracts with IDs 9629849 and 8239569, which equals (sum across all the (parkinsonism,DRD) basic co-occurrence tuples);
p(parkinsonism), p(DRD)–individual distributions of the parkinsonism,DRD arguments within all extracted tuples, which equal 28.987 and 220.354, respectively (sums of the weights in all basic co-occurrence statements that contain parkinsonism or DRD as one of the arguments, respectively);
F(parkinsonism, DRD), |T|–the absolute frequency of the parkinsonism,DRD co-occurrence and the number of all basic co-occurrence statements extracted from the abstracts, which equals to 2 and 1,414, respectively;
P–the percentile for the normalisation, equal to 95, which results in the normalisation constant 2.061 (a non-normalised score such that only 5% of the scores are higher than that).
Similarity
After having computed the aggregated and filtered co-occurrence statements, we add one more type of relationship–similarity. Many other authors have suggested ways for computing semantic similarity (see d’Amato, 2007 for a comprehensive overview). We base our approach on cosine similarity, which has become one of the most commonly used approaches in information retrieval applications (Singhal, 2001; Manning, Raghavan & Schütze, 2008). The similarity and related notions are described in detail in ‘Similarities’, formulae (6) and (7).
Similarity indicates a higher-level type of relationship between entities that may not be covered by mere co-occurrence (entities not occurring in the same article may still be similar). This adds another perspective to the network of connections between entities extracted from literature, therefore it is useful to make similarity statements also a part of the SKIMMR knowledge base. To do so, we compute the similarity values between all combinations of entities x, y and include the statements (x, sim, y, sim(x, y)) into the knowledge base whenever the similarity value is above a pre-defined threshold (0.25 is used in the current implementation).4
A worked example of how to compute similarity between two entities in the sample knowledge base is given below.
Let us use ‘parkinsonisms’, ‘mrpi values’ as sample entities a, b. In a full version of Parkinson’s disease knowledge base (that contains the data used in the previous examples, but also hundreds of thousands of other statements), there are 19 shared entities among the ones related to a, b (for purposes of brevity, each item is linked to a short identifier to be used later on): (1) msa − p ∼ t0, (2) clinically unclassifiable parkinsonism ∼ t1, (3) cup ∼ t2, (4) vertical ocular slowness ∼ t3, (5) baseline clinical evaluation ∼ t4, (6) mr ∼ t5, (7) parkinsonian disorders ∼ t6, (8) psp phenotypes ∼ t7, (9) duration ∼ t8, (10) patients ∼ t9, (11) clinical diagnostic criteria ∼ t10, (12) abnormal mrpi values ∼ t11, (13) pd ∼ t12, (14) magnetic resonance parkinsonism index ∼ t13, (15) parkinson disease ∼ t14, (16) mri ∼ t15, (17) parkinson’s disease ∼ t16, (18) psp ∼ t17, (19) normal mrpi values ∼ t18.
The co-occurrence complements a, b of the parkinsonisms, mrpi values entities (i.e., associated co-occurrence context vectors) are summarised in the following table:
t0
t1
t2
t3
t4
t5
t6
t7
t8
t10
t11
t13
t14
t15
t17
t18
a
0.14
0.39
1.0
0.08
0.26
0.06
0.18
0.4
0.07
0.27
0.09
0.7
0.03
0.14
0.33
0.25
b
0.26
0.57
1.0
0.3
0.82
0.2
0.33
0.26
0.39
0.43
0.36
0.41
0.06
0.34
1.0
1.0
Indexing and querying the knowledge base
The main purpose of SKIMMR is to allow users to efficiently search and navigate in the SKIMMR knowledge bases, and retrieve articles related to the content discovered in the high-level entity networks. To support that, we maintain several indices of the knowledge base contents. The way how the indices are built and used in querying SKIMMR is described in the following two sections.
Knowledge base indices
In order to expose the SKIMMR knowledge bases, we maintain three main indices: (1) a term index–a mapping from entity terms to other terms that are associated with them by a relationship (like co-occurrence or similarity); (2) a statement index–a mapping that determines which statements the particular terms occur in; (3) a source index–a mapping from statements to their sources, i.e., the texts from which the statements have been computed. In addition to the main indices, we use a full-text index that maps spelling alternatives and synonyms to the terms in the term index.
The main indices are implemented as matrices that reflect the weights in the SKIMMR knowledge base: where:
-
T1, …, Tn are identifiers of all entity terms in the knowledge base and ti,j∈[0, 1] is the maximum weight among the statements of all types existing between entities Ti, Tj in the knowledge base (0 if there is no such statement);
-
S1, …, Sm are identifiers of all statements present in the knowledge base and si,j∈{0, 1} determines whether an entity Ti occurs in a statement Sj or not;
-
P1, …, Pq are identifiers of all input textual resources, and pi,j∈[0, 1] is the weight of the statement Si if Pj was used in order to compute it, or zero otherwise.
To illustrate the notion of the knowledge base indices, let us consider a simple knowledge base with only two statements from Examples 1 and 3: S1 ∼ (parkinsonism,cooc,DRD,0.545), S2 ∼ (parkinsonisms,sim,mrpi values,0.365). Furthermore, let us assume that: (i) the statement S1 has been computed from the articles with PubMed identifiers 9629849, 8239569 (being referred to by the P1, P2 provenance identifiers respectively); (ii) the statement S2 has been computed from articles with PubMed identifiers 9629849, 21832222, 22076870 (being referred to by the P1, P3, P4 provenance identifiers, respectively5). This corresponds to the following indices:
Querying
The indices are used to efficiently query for the content of SKIMMR knowledge bases. We currently support atomic queries with one variable, and possibly nested combinations of atomic queries and propositional operators of conjunction (AND), disjunction (OR) and negation (NOT). An atomic query is defined as ?↔T, where ? refers to the query variable and T is a full-text query term.6 The intended purpose of the atomic query is to retrieve all entities related by any relation to the expressions corresponding to the term T. For instance, the ?↔parkinsonism query is supposed to retrieve all entities co-occurring-with or similar-to parkinsonism.
Combinations consisting of multiple atomic queries linked by logical operators are evaluated using the following algorithm:
-
Parse the query and generate a corresponding ‘query tree’ (where each leaf is an atomic query and each node is a logical operator; the levels and branches of this tree reflect the nested structure of the query).
-
Evaluate the atomic queries in the nodes by a look-up in the term index, fetching the term index rows that correspond to the query term in the atomic query.
-
The result of each term look-up is a fuzzy set (Hájek, 1998) of terms related to the atomic query term, with membership degrees given by listed weights. One can then naturally combine atomic results by applying fuzzy set operations corresponding to the logical operators in the parsed query tree nodes (where conjunction, disjunction and negation correspond to fuzzy intersection, union and complement, respectively).
-
The result is a fuzzy set of terms , with their membership degrees reflecting their relevance as results of the query.
The term result set RT can then be used to generate sets of relevant statements (RS) and provenances (RP) using look-ups in the corresponding indices as follows: (a) , where , (b) , where . νs, νp are normalisation constants for weights. The weight for a statement Si in the result set RS is computed as a normalised a dot product (i.e., sum of the element-wise products) of the vectors given by: (a) the membership degrees in the term result set RT, and (b) the column in the statement index that corresponds to Si. Similarly, the weight for a provenance Pi in the result set RP is a normalised dot product of the vectors given by the ST membership degrees and the column in the provenance index corresponding to Pi.
The fuzzy membership degrees in the term, statement and provenance result sets can be used for ranking and visualisation, prioritising the most important results when presenting them to the user. The following example outlines how a specific query is evaluated.
Let us assume we want to query the full SKIMMR knowledge base about Parkinson’s Disease for the following: This aims to find all statements (and corresponding documents) that are related to parkinsonism and either magnetic resonance parkinsonism index or its mrpi abbreviation. First of all, the full-text index is queried, retrieving two different terms conforming to the first atomic part of the query due to its stemming features: parkinsonism and parkinsonisms. The other two atomic parts of the initial query are resolved as is. After the look-up in the term index, four fuzzy sets are retrieved: 1. Tparkinsonism (3,714 results), 2. Tparkinsonisms (151 results), 3. Tmrpi (39 results). 4. Tmagneticresonanceparkinsonismindex (29 results). The set of terms conforming to the query is then computed as When using maximum and minimum as t-conorm and t-norm for computing the fuzzy union and intersection (Hájek, 1998), respectively, the resulting set has 29 elements with non-zero membership degrees. The top five of them are
with membership degrees 1.0, 1.0, 0.704, 0.39, 0.34, respectively. According to the statement index, there are 138 statements corresponding to the top five term results of the initial query, composed of 136 co-occurrences and 2 similarities. The top five co-occurrence statements and the two similarity statements are:(1) cup, (2) mrpi, (3) magnetic resonance parkinsonism index, (4) clinically unclassifiable parkinsonism, (5) clinical evolution
| Type | Entity1 | Entity2 | Membership degree |
|---|---|---|---|
| cooc | mrpi | cup | 1.0 |
| cooc | mrpi | magnetic resonance parkinsonism index | 0.852 |
| cooc | cup | magnetic resonance parkinsonism index | 0.852 |
| cooc | mrpi | clinically unclassifiable parkinsonism | 0.695 |
| cooc | cup | clinically unclassifiable parkinsonism | 0.695 |
| sim | psp patients | magnetic resonance parkinsonism index | 0.167 |
| sim | parkinsonism | clinical evolution | 0.069 |
| PMID | Title | Authors | Weight |
|---|---|---|---|
| 21832222 | The diagnosis of neurodegenerative disorders based on clinical and pathological findings using an MRI approach |
Watanabe H et al. | 1.0 |
| 21287599 | MRI measurements predict PSP in unclassifiable parkinsonisms: a cohort study |
Morelli M et al. | 0.132 |
| 22277395 | Accuracy of magnetic resonance parkinsonism index for differentiation of progressive supranuclear palsy from probable or possible Parkinson disease |
Morelli M et al. | 0.005 |
| 15207208 | Utility of dopamine transporter imaging (123-I Ioflupane SPECT) in the assessment of movement disorders |
Garcia Vicente AM et al. | 0.003 |
| 8397761 | Alzheimer’s disease and idiopathic Parkinson’s disease coexistence | Rajput AH et al. | 0.002 |
Evaluation methodology
In addition to proposing specific methods for creating knowledge bases that support skim reading, we have also come up with a specific methodology for evaluating the generated knowledge bases. An ideal method for evaluating the proposed approach, implemented as a SKIMMR tool, would be to record and analyse user feedback and behaviour via SKIMMR instances used by large numbers of human experts. We do have such means for evaluating SKIMMR implemented in the user interface.7 However, we have not yet managed to collect sufficiently large sample of user data due to the early stage of the prototype deployment. Therefore we implemented an indirect methodology for automated quantitative evaluation of SKIMMR instances using publicly available manually curated data. The methodology is primarily based on simulation of various types of human behaviour when browsing the entity networks generated by SKIMMR. We formally define certain properties of the simulations and measure their values in order to determine the utility of the entity networks for the purposes of skim reading. Details are given in the following sections.
Overview of the evaluation methods
The proposed methods intend to simulate human behaviour when using the data generated by SKIMMR. We apply the same simulations also to baseline data that can serve for the same or similar purpose as SKIMMR (i.e., discovery of new knowledge by navigating entity networks). Each simulation is associated with specific measures of performance, which can be used to compare the utility of SKIMMR with respect to the baseline.
The primary evaluation method is based on random walks (Lovász, 1993) in an undirected entity graph corresponding to the SKIMMR knowledge base. For the baseline, we use a network of MeSH terms assigned by human curators to the PubMed abstracts that have been used to create the SKIMMR knowledge base.8 This represents a very similar type of content, i.e., entities associated with PubMed articles. It is also based on expert manual annotations and thus supposed to be a reliable gold standard (or at least a decent approximation thereof due to some level of transformation necessary to generate the entity network from the annotations).
Returning to the knowledge base statement from Example 2 in ‘Corpus-wide co-occurrence’: (parkinsonism,cooc,DRD,0.545). In the SKIMMR entity graph, this corresponds to two nodes (parkinsonism,DRD) and one edge between them with weight 0.545. We do not distinguish between the types of the edges (i.e., co-occurrence or similarity), since it is not of significant importance for the SKIMMR users according to our experience so far (they are more interested in navigating the connections between nodes regardless of the connection type).
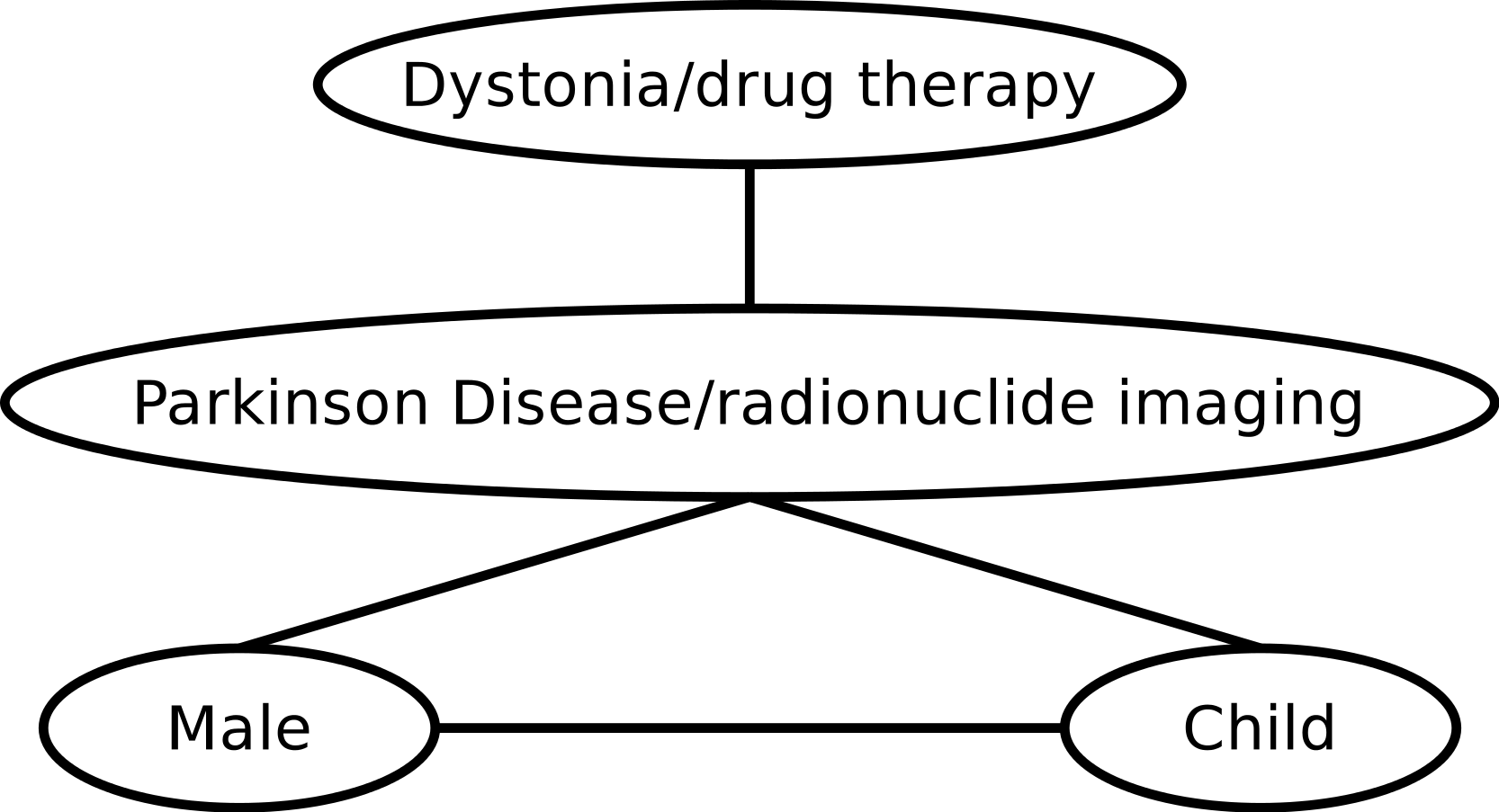
A baseline entity graph is generated from the PubMed annotations with MeSH terms. For all entities X, Yassociated with an abstract A, we construct an edge connecting the nodes X and Y in the entity graph. The weight is implicitly assumed to be 1.0 for all such edges. To explain this using concrete data, let us consider the two PubMed IDs from Example 1, 9629849 and 8239569. Selected terms from the corresponding MeSH annotations are {Parkinson Disease/radionuclide imaging,Male,Child}, {Parkinson Disease/radionuclide imaging,Dystonia/drug therapy}, respectively. The graph induced by these annotations is depicted in Fig. 1.

Figure 1: Example of an entity graph derived from PubMed.
{kind=link}
The secondary evaluation method uses an index of related articles derived from the entities in the SKIMMR knowledge bases. For the baseline, we use either an index of related articles produced by a specific service of PubMed (Lin & Wilbur, 2007), or the evaluation data from the document categorisation task of the TREC’04 genomics track (Cohen & Hersh, 2006) where applicable. We use the TREC data since they were used also for evaluation of the actual algorithm used by PubMed to compute related articles.
To generate the index of related articles from the SKIMMR data, we first use the knowledge base indices (see ‘Extracting basic co-occurrence statements from texts’) to generate a mapping EP:E → 2P from entities from a set E to a set of corresponding provenance identifiers (subsets of a set P). In the next step, we traverse the entity graph GE derived from the statements in the SKIMMR knowledge base and build an index of related articles according to the following algorithm:
-
Initialise a map MP between all possible (Pi, Pj) provenance identifier pairs and the weight of an edge between them so that all values are zero.
-
For all pairs of entities E1, En (i.e., nodes in GE), do:
-
If there is a path of edges {(E1, E2), (E2, E3), …, (En−1, En)} in GE:
-
compute an aggregate weight of the path as (as a multiplication of all weights along the path );
-
set the values MP(Pi, Pj) of the map MP to for every Pi, Pj such that Pi∈EP(E1), Pj∈EP(En) (i.e., publications corresponding to the source and target entities of the path).
-
-
-
Interpret the MP map as an adjacency matrix and construct a corresponding weighted undirected graph GP.
-
For every node P in GP, iteratively construct the index of related articles by associating the key P with a list L of all neighbours of P in GP sorted by the weights of the corresponding edges.
Note that in practice, we restrict the maximum length of the paths to three and also remove edges in GP with weight below 0.1. This is to prevent a combinatorial explosion of the provenance graph when the entity graph is very densely connected.
The baseline index of related publications according to the PubMed service is simply a mapping of one PubMed ID to an ordered list of the related PubMed IDs. The index based on the TREC data is generated from the article categories in the data set. For a PubMed ID X, the list of related IDs are all IDs belonging to the same category as X, ordered so that the definitely relevant articles occur before the possibly relevant ones.9
Motivation of the evaluation methods
The random walks are meant to simulate user’s behaviour when browsing the SKIMMR data, starting with an arbitrary entry point, traversing a number of edges linking the entities and ending up in a target point. Totally random walk corresponds to when a user browses randomly and tries to learn something interesting along the way. Other types of user behaviour can be simulated by introducing specific heuristics for selection of the next entity on the walk (see below for details). To determine how useful a random walk can be, we measure properties like the amount of information along the walk and in its neighbourhood, or semantic similarity between the source and target entities (i.e., how semantically coherent the walk is).
The index of related articles has been chosen as a secondary means for evaluating SKIMMR. Producing links between publications is not the main purpose of our current work, however, it is closely related to the notion of skim reading. Furthermore, there are directly applicable gold standards we can use for automated evaluation of the lists of related articles generated by SKIMMR, which can provide additional perspective on the utility of the underlying data even if we do not momentarily expose the publication networks to users.
Running and measuring the random walks
To evaluate the properties of random walks in a comprehensive manner, we ran them in batches with different settings of various parameters. These are namely: (1) heuristics for selecting the next entity (one of the four defined below); (2) length of the walk (2, 5, 10 or 50 edges); (3) radius of the walk’s envelope, i.e., the maximum distance between the nodes of the path and entities that are considered its neighbourhood (0, 1, 2); (4) number of repetitions (100-times for each combination of the parameter (1–3) settings).
Before we continue, we have to introduce few notions that are essential for the definition of the random walk heuristics and measurements. The first of them is a set of top-level (abstract) clusters associated with an entity in a graph (either from SKIMMR or from PubMed) according to the MeSH taxonomy. This is defined as a function CA:E → M, where E, M are the sets of entities and MeSH cluster identifiers, respectively. The second notion is a set of specific entity cluster identifiers CS, defined on the same domain and range as CA, i.e., CS:E → M.
The MeSH cluster identifiers are derived from the tree path codes associated with each term represented in MeSH. The tree path codes have the form L1.L2.….Ln−1.Ln where Li are sub-codes of increasing specificity (i.e., L1 is the most general and Ln most specific). For the abstract cluster identifiers, we take only the top-level tree path codes into account as the values of CA, while for CS we consider the complete codes. Note that for the automatically extracted entity names in SKIMMR, there are often no direct matches in the MeSH taxonomy that could be used to assign the cluster identifiers. In these situations, we try to find a match for the terms and their sub-terms using a lemmatised full-text index implemented on the top of MeSH. This helps to increase the coverage two- to three-fold on our experimental data sets.
For some required measures, we will need to consider the number and size of specific clusters associated with the nodes in random walks and their envelopes. Let us assume a set of entities Z⊆E. The number of clusters associated with the entities from Z, cn(Z), is then defined as where C is one of CA, CS (depending on which type of clusters are we interested in). The size of a cluster Ci∈C(X), cs(Ci), is defined as an absolute frequency of the mentions of Ci among the clusters associated with the entities in Z. More formally, cs(Ci) = |{X|X∈Z∧Ci∈C(X)}|. Finally, we need a MeSH-based semantic similarity of entities simM(X, Y), which is defined in detail in the formula (8) in ‘Similarities’.
To illustrate the MeSH-based cluster annotations and similarities, let us consider two entities, supranuclear palsy, progressive, 3 and secondary parkinson disease. The terms correspond to the MeSH tree code sets {C10.228.662.700, …, C23.888.592.636.447.690, …, C11.590.472.500, …} and {C10.228.662.600.700}, respectively, which are also the sets of specific clusters associated with the terms. The top-level clusters are {C10, C11, C23}and {C10}, respectively. The least common subsumer of the two terms is C10.228.662 of depth 3 (the only possibility with anything in common is C10.228.662.700 and C10.228.662.600.700). The depths of the related cluster annotations are 4 and 5, therefore the semantic similarity is .
We define four heuristics used in our random walk implementations. All the heuristics select the next node to visit in the entity graph according to the following algorithm:
-
Generate the list L of neighbours of the current node.
-
Sort L according to certain criteria (heuristic-dependent).
-
Initialise a threshold e to ei, a pre-defined number in the (0, 1) range (we use 0.9 in our experiments).
-
For each node u in the sorted list L, do:
-
Generate a random number r from the [0, 1] range.
-
If r ≤ e:
-
return u as the next node to visit.
-
-
Else:
-
set e to e⋅ei and continue with the next node in L.
-
-
-
If nothing has been selected by now, return a random node from L.
All the heuristics effectively select the nodes closer to the head of the sorted neighbour list more likely than the ones closer to the tail. The random factor is introduced to emulate the human way of selecting next nodes to follow, which is often rather fuzzy according to our observations of sample SKIMMR users.
The distinguishing factor of the heuristics are the criteria for sorting the neighbour list. We employed the following four criteria in our experiments: (1) giving preference to the nodes that have not been visited before (H = 1); (2) giving preference to the nodes connected by edges with higher weight (H = 2); (3) giving preference to the nodes that are more similar, using the simM function introduced before (H = 3); (4) giving preference to the nodes that are less similar (H = 4). The first heuristic simulates a user that browses the graph more or less randomly, but prefers to visit previously unknown nodes. The second heuristic models a user that prefers to follow a certain topic (i.e., focused browsing). The third heuristic represents a user that wants to learn as much as possible about many diverse topics. Finally, the fourth heuristic emulates a user that prefers to follow more plausible paths (approximated by the weight of the statements computed by SKIMMR).
Each random walk and its envelope (i.e., the neighbourhood of the corresponding paths in the entity graphs) can be associated with various information-theoretic measures, graph structure coefficients, levels of correspondence with external knowledge bases, etc. Out of the multitude of possibilities, we selected several specific scores we believe to soundly estimate the value of the underlying data for users in the context of skim reading.
Firstly, we measure semantic coherence of the walks. This is done using the MeSH-based semantic similarity between the nodes of the walk. In particular, we measure: (A) coherence between the source S and target T nodes as simM(S, T); (B) product coherence between all the nodes U1, U2, …, Un of the walk as Πi∈{1,…,n−1}simM(Ui, Ui+1); (C) average coherence between all the nodes U1, U2, …, Un of the walk as . This family of measures helps us to assess how convergent (or divergent) are the walks in terms of focus on a specific topic.
The second measure we used is the information content of the nodes on and along the walks. For this, we use the entropy of the association of the nodes with clusters defined either (a) by the MeSH annotations or (b) by the structure of the envelope. By definition, the higher the entropy of a variable, the more information the variable contains (Shannon, 1948). In our context, a high entropy value associated with a random walk means that there is a lot of information available for the user to possibly learn when browsing the graph. The specific entropy measures we use relate to the following sets of nodes: (D) abstract MeSH clusters, path only; (E) specific MeSH clusters, path only; (F) abstract MeSH clusters, path and envelope; (G) specific MeSH clusters, path and envelope; (H) clusters defined by biconnected components (Hopcroft & Tarjan, 1973) in the envelope. 10 The entropies of the sets (D–G) are defined by formulae (9) and (10) in ‘Entropies’.
The last family of random walk evaluation measures is based on the graph structure of the envelopes: (I) envelope size (in nodes); (J) envelope size in biconnected components; (K) average component size (in nodes); (L) envelope’s clustering coefficient. The first three measures are rather simple statistics of the envelope graph. The clustering coefficient is widely used as a convenient scalar representation of the structural complexity of a graph, especially in the field of social network analysis (Carrington, Scott & Wasserman, 2005). In our context, we can see it as an indication of how likely it is that the connections in the entity graph represent non-trivial relationships.
To facilitate the interpretation of the results, we computed also the following auxiliary measures: (M) number of abstract clusters along the path; (N) average size of the abstract clusters along the path; (O) number of abstract clusters in the envelope; (P) average size of the abstract clusters in the envelope; (Q) number of specific clusters along the path; (R) average size of the specific clusters along the path; (S) number of specific clusters in the envelope; (T) average size of the specific clusters in the envelope. Note that all the auxiliary measures use the MeSH cluster size and number notions, i.e., cs(…) and cn(…) as defined earlier.
Comparing the indices of related articles
The indices of related articles have quite a simple structure. We can also use the baseline indices as gold standard, and therefore evaluate the publication networks implied by the SKIMMR data using classical measures of precision and recall (Manning, Raghavan & Schütze, 2008). Moreover, we can also compute correlation between the ranking of the items in the lists of related articles which provides an indication of how well SKIMMR preserves the ranking imposed by the gold standard.
For the correlation, we use the standard Pearson’s formula (Dowdy, Weardon & Chilko, 2005), taking into account only the ranking of articles occurring in both lists. The measures of precision and recall are defined using overlaps of the sets of related articles in the SKIMMR and gold standard indices. The detailed definitions of the specific notions of precision and recall we use are given in formulae (11) and (12) in ‘Precision and recall’. The gold standard is selected depending on the experimental data set, as explained in the next section. In order to cancel out the influence of different average lengths of lists of related publications between the SKIMMR and gold standard indices, one can take into account only a limited number of the most relevant (i.e., top) elements in each list.
Results
We have implemented the techniques described in the previous section as a set of software modules and provided them with a search and browse front-end. This forms a prototype implementation of SKIMMR, available as an open source software package through the GitHub repository (see ‘Software packages’ for details). We here describe the architecture of the SKIMMR software (‘Architecture’) and give examples on the typical use of SKIMMR in the domains of Spinal Muscular Atrophy and Parkinson’s Disease (‘Using SKIMMR’). ‘Evaluation’ presents an evaluation of the proposed approach to machine-aided skim reading using SKIMMR running on three domain-specific sets of biomedical articles.
Architecture
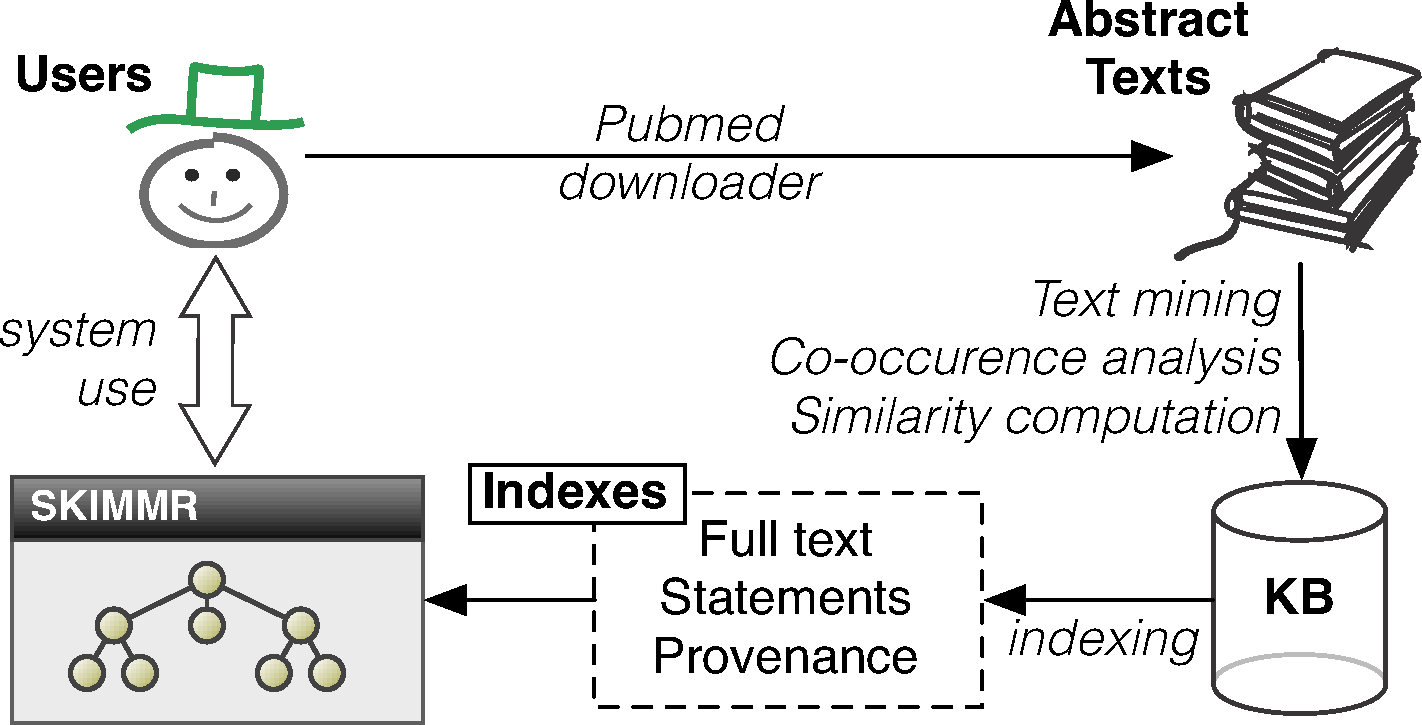
The SKIMMR architecture and data flow is depicted in Fig. 2. First of all, SKIMMR needs a list of PubMed identifiers (unique numeric references to articles indexed on PubMed) specified by the user of system administrator. Then it automatically downloads the abstracts of the corresponding articles and stores the texts locally. Alternatively, one can export results of a manual PubMed search as an XML file (using the ‘send to file’ feature) and then use a SKIMMR script to generate text from that file. From the texts, a domain-specific SKIMMR knowledge base is created using the methods described in ‘Extracting basic co-occurrence statements from texts’ and ‘Computing a knowledge base from the extracted statements’. The computed statements and their article provenance are then indexed as described in ‘Indexing and querying the knowledge base’. This allows users to search and browse the high-level graph summaries of the interconnected pieces of knowledge in the input articles. The degrees in the result sets (explained in detail in ‘Indexing and querying the knowledge base’) are used in the user interface to prioritise the more important nodes in the graphs by making their font and size proportional to the sum of the degrees of links (i.e., the number of statements) associated with them. Also, only a selected amount of the top scoring entities and links between them is displayed at a time.

Figure 2: Architecture of the SKIMMR system.
{kind=link}
Using SKIMMR
The general process of user interaction with SKIMMR can be schematically described as follows:
-
Search for an initial term of interest in a simple query text box.
-
A graph corresponding to the results of the search is displayed. The user has two options then:
-
Follow a link to another node in the graph, essentially browsing the underlying knowledge base along the chosen path by displaying the search results corresponding to the selected node and thus going back to step 1 above.
-
Display most relevant publications that have been used for computing the content of the result graph, going to step 3 below.
-
-
Access and study the displayed publications in detail using a re-direct to PubMed.
The following two sections illustrate the process using examples from two live instances of SKIMMR deployed on articles about Spinal Muscular Atrophy and Parkinson’s Disease.11 The last section of this part of the article gives a brief overview of the open source software packages of SKIMMR available for developers and users interested in deploying SKIMMR on their own data.
Spinal muscular atrophy
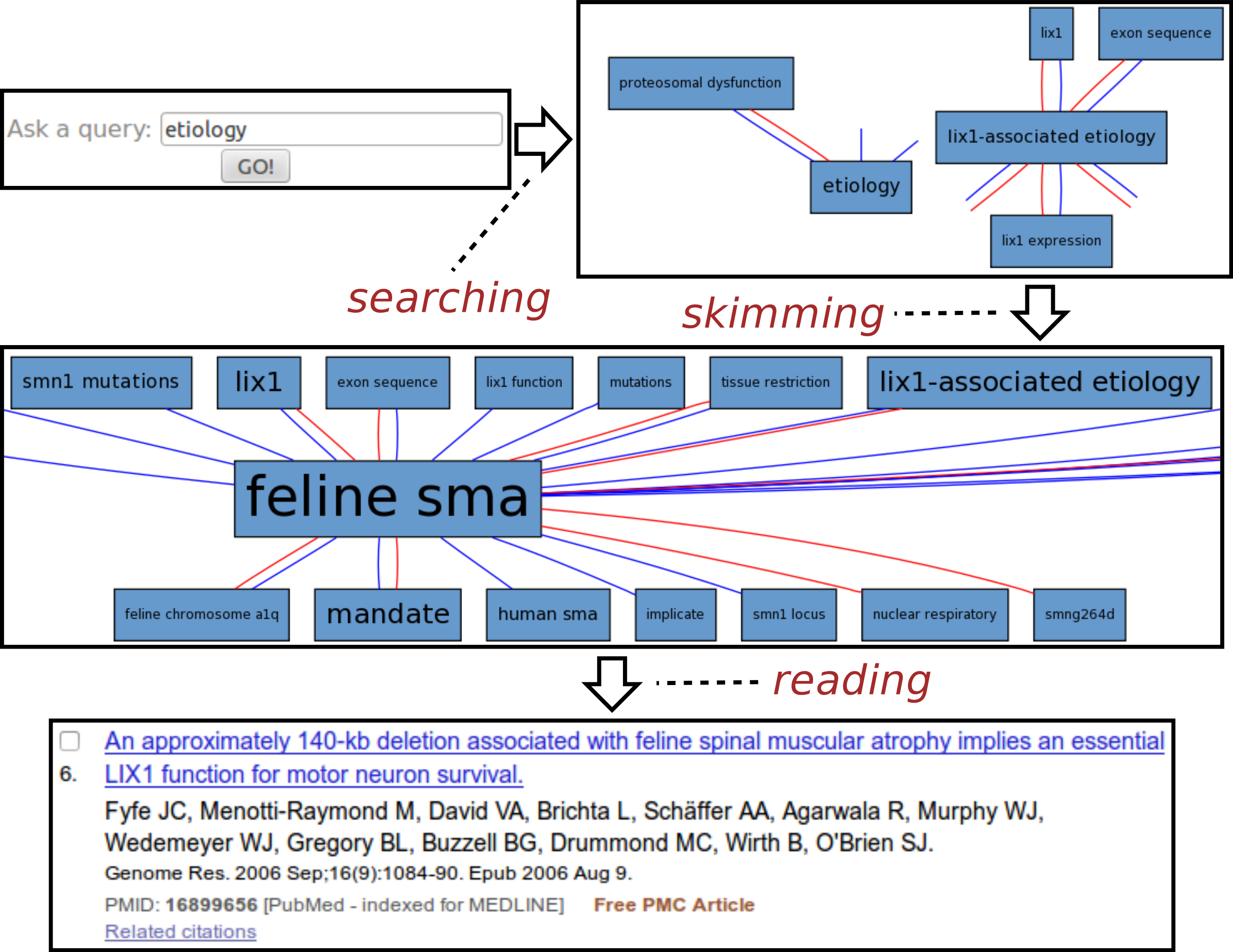
Fig. 3 illustrates a typical session with the Spinal Muscular Atrophy12 instance of SKIMMR. The SMA instance was deployed on a corpus of 1,221 abstracts of articles compiled by SMA experts from the SMA foundation.13
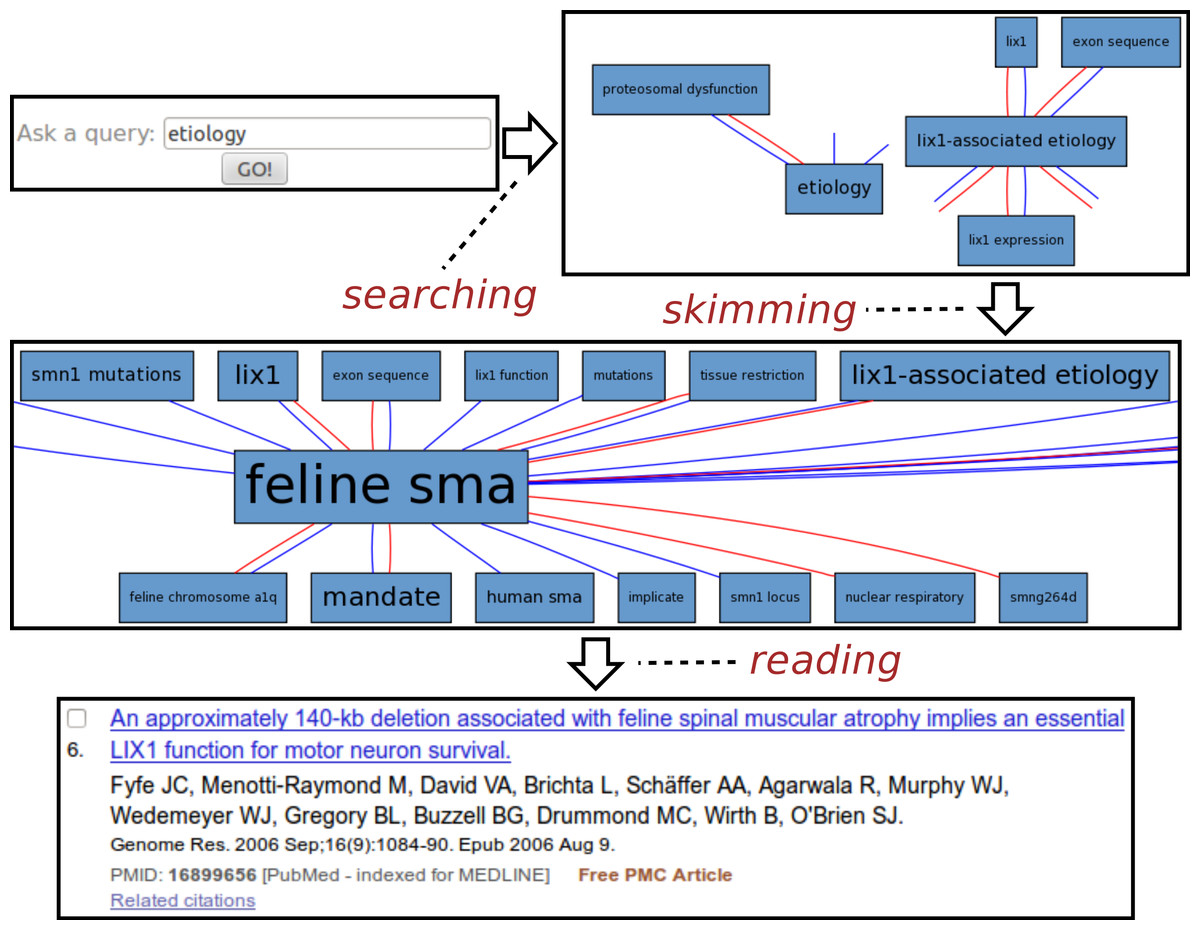
Figure 3: Exploring SMA etiology.
{kind=link}
The usage example is based on an actual session with Maryann Martone, a neuroscience professor from UCSD and a representative of the SMA Foundation who helped us to assess the potential of the SKIMMR prototype. Following the general template from the beginning of the section, the SMA session can be divided into three distinct phases:
-
Searching: The user was interested in the SMA etiology (studies on underlying causes of a disease). The key word etiology was thus entered into the search box.
-
Skimming: The resulting graph suggests relations between etiology of SMA, various gene mutations, and the Lix1 gene. Lix1 is responsible for protein expression in limbs which seems relevant to the SMA manifestation, therefore the Lix1 − associated etiology path was followed in the graph, moving on to a slightly different area in the underlying knowledge base extracted from the SMA abstracts. When browsing the graph along that path, one can quickly notice recurring associations with feline SMA. According to the neuroscience expert we consulted, the cat models of the SMA disease appear to be quite a specific and interesting fringe area of SMA research. Related articles may be relevant and enlightening even for experienced researchers in the field.
-
Reading: The reading mode of SKIMMR employs an in-line redirect to a specific PubMed result page. This way one can use the full set of PubMed features for exploring and reading the articles that are mostly relevant to the focused area of the graph the user skimmed until now. The sixth publication in the result was most relevant for our sample user, as it provided more details on the relationships between a particular gene mutation in a feline SMA model and the Lix1 function for motor neuron survival. This knowledge, albeit not directly related to SMA etiology in humans, was deemed as enlightening by the domain expert in the context of the general search for the culprits of the disease.
The whole session with the neuroscience expert lasted about two minutes and clearly demonstrated the potential for serendipitous knowledge discovery with our tool.
Parkinson’s disease
Another example of the usage of SKIMMR is based on a corpus of 4,727 abstracts concerned with the clinical studies of Parkinson’s Disease (PD). A sample session with the PD instance of SKIMMR is illustrated in Fig. 4. Following the general template from the beginning of the section, the PD session can be divided into three distinct phases again:
-
Searching: The session starts with typing parkinson’s into the search box, aiming to explore the articles from a very general entry point.
-
Skimming: After a short interaction with SKIMMR, consisting of few skimming steps (i.e., following a certain path in the underlying graphs of entities extracted from the PD articles), an interesting area in the graph has been found. The area is concerned with Magnetic Resonance Parkinsons Index (MRPI). This is a numeric score calculated by multiplying two structural ratios: one for the area of the pons relative to that of the midbrain and the other for the width of the Middle Cerebellar Peduncle relative to the width of the Superior Cerebellar Peduncle. The score is used to diagnose PD based on neuroimaging data (Morelli et al., 2011).
-
Reading: When displaying the articles that were used to compute the subgraph surrounding MRPI, the user reverted to actual reading of the literature concerning MRPI and related MRI measures used to diagnose Parskinson’s Disease as well a range of related neurodegenerative disorders.
This example illustrates once again how SKIMMR provides an easy way of navigating through the conceptual space of a subject that is accessible even to novices, reaching interesting and well-specified components areas of the space very quickly.

Figure 4: Exploring Parkinson’s disease.
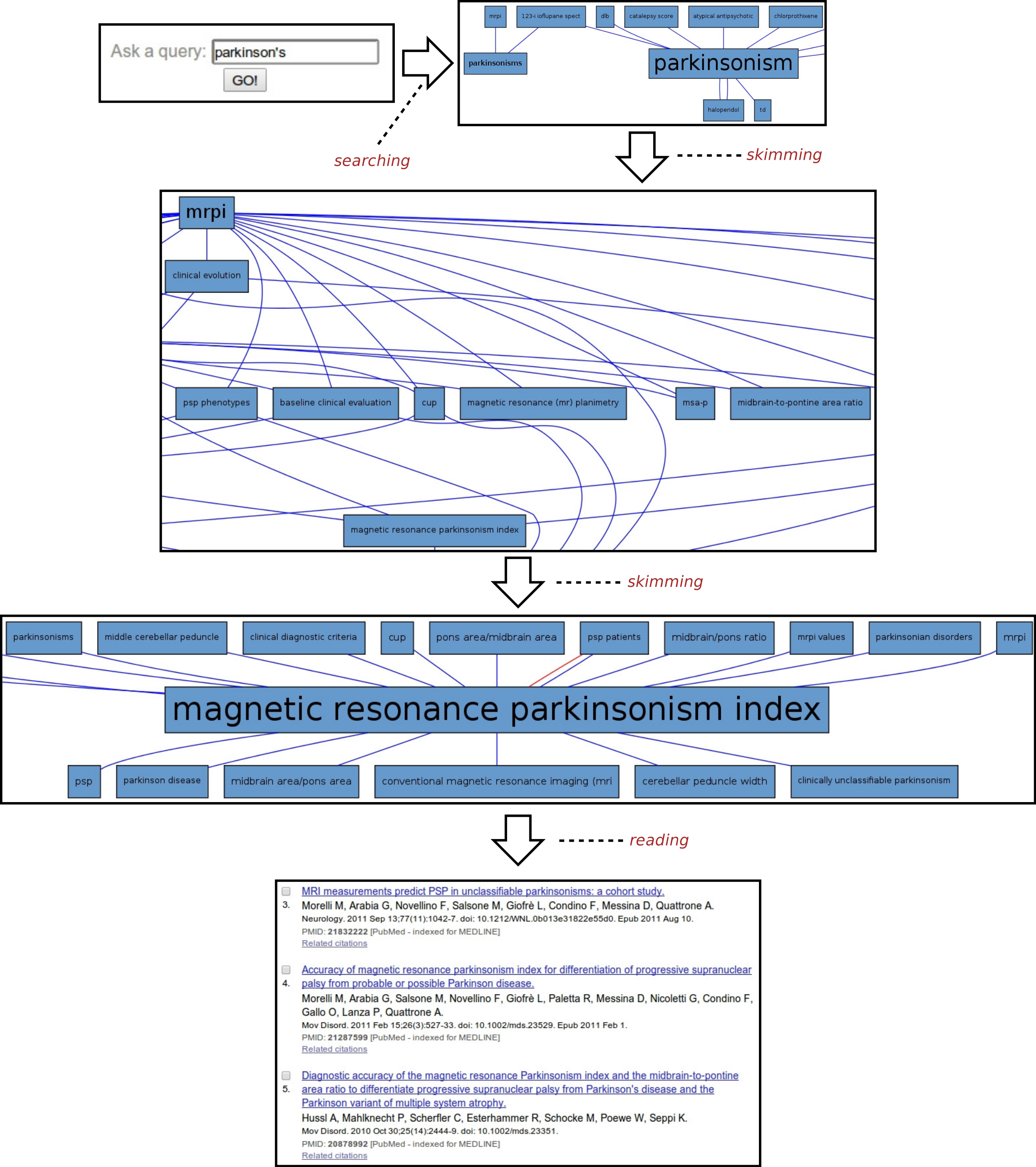{kind=link}
Software packages
In addition to the two live instances described in the previous sections, SKIMMR is available for local installation and custom deployment either on biomedical article abstracts from PubMed, or on general English texts. Moreover, one can expose SKIMMR via a simple HTTP web service once the back-end has compiled a knowledge base from selected textual input. The latter is particularly useful for the development of other applications on the top of the content generated by SKIMMR. Open source development snapshots (written in the Python programming language) of SKIMMR modules are available via our GitHub repository14 with accompanying documentation.
Evaluation
In the following we report on experiments we used for evaluating SKIMMR using the method explained in ‘Evaluation methodology’. The results of our experiments empirically demonstrate that the SKIMMR networks allow for more focused browsing of the publication content than is possible with tools like PubMed. SKIMMR also has the potential for offering more information of higher complexity during the browsing process. The following sections provide details on the data sets used in the experiments and the results of the evaluation.
Evaluation data
We have evaluated SKIMMR using three corpora of domain-specific biomedical articles. The first one was SMA: a representative corpus of 1,221 PubMed abstracts dealing with Spinal Muscular Atrophy (SMA), compiled by experts from SMA Foundation. The second corpus was PD: a set of 4,727 abstracts that came as results (in February 2013) of a search for clinical studies on Parkinson’s Disease on PubMed. The last corpus was TREC: a random sample15 of 2,247 PubMed abstracts from the evaluation corpus of the TREC’04 genomics track (document categorisation task).
For running the experiment with random walks, we generated two graphs for each of the corpora (using the methods described in Example 6): (1) network of SKIMMR entities; (2) network of MeSH terms based on the PubMed annotations of the articles that were used as sources for the particular SKIMMR instance.
As outlined before in the methods section, we also used some auxiliary data structures for the evaluation. The first auxiliary resource was the MeSH thesaurus (version from 2013). From the data available on the National Library of Medicine web site, we generated a mapping from all MeSH terms and their synonyms to the corresponding tree codes indicating their position in the MeSH hierarchy. We also implemented a lemmatised full-text index on the MeSH mapping keys to increase the coverage of the tree annotations when the extracted entity names do not exactly correspond to the MeSH terms.
The second type of auxiliary resource (a gold standard) were indices of related articles based on the corresponding PubMed service. For the other type of gold standard, we used the TREC’04 category associations from the genomics track data. This is essentially a mapping between PubMed IDs, category identifiers and a degree of membership of the specific IDs in the category (definitely relevant, possibly relevant, not relevant). From that mapping, we generated the index of related articles as a gold standard for the secondary evaluation method (the details of the process are described in the previous section).
Note that for the TREC corpus, the index of related articles based on the TREC data is applicable as a gold standard for the secondary evaluation. However, for the other two data sets (SMA and PD), we used the gold standard based on the PubMed service for fetching related articles. This is due to almost zero overlap between the TREC PubMed IDs and the SMA, PD corpora, respectively.
Data statistics
Corpus and knowledge base statistics
Basic statistics of the particular text corpora are given in Table 1, with column explanations as follows: (1) |SRC| is the number of the source documents; (2) |TOK| is the number of tokens (words) in the source documents; (3) |BC| is the number of base co-occurrence statements extracted from the sources (see ‘Extracting basic co-occurrence statements from texts’ for details); (4) |LEX| is the vocabulary size (i.e., the number of unique entities occurring in the basic co-occurrence statements); (5) |KBcooc| is the number of aggregate co-occurrence statements in the corresponding SKIMMR knowledge base (see ‘Corpus-wide co-occurrence’); (6) |KBsim| is the number of similarity statements in the corresponding SKIMMR knowledge base (see ‘Similarity’).
| Data set ID | |SRC| | |TOK| | |BC| | |LEX| | |KBcooc| | |KBsim| |
|---|---|---|---|---|---|---|
| SMA | 1,221 | 223,257 | 333,124 | 15,288 | 308,626 | 23,167 |
| PD | 4,727 | 943,444 | 1,096,037 | 43,410 | 965,753 | 57,876 |
| TREC | 2,247 | 439,202 | 757,762 | 39,431 | 745,201 | 65,510 |
Derived statistics on the SKIMMR instances are provided in Table 2, with column explanations as follows: (1) T/S is an average number of tokens per a source document; (2) B/S is an average number of basic co-occurrence statements per a source document; (3) L/T is a ratio of the size of the lexicon with respect to the overall number of tokens in the input data; (4) SM/KB is a ratio of the similarity statements to the all statements in the knowledge base; (5) KB/S is an average number of statements in the knowledge base per a source document; (6) KB/L is an average number of statements in the knowledge base per a term in the lexicon. The values in the columns are computed from the basic statistics as follows:
| Data set ID | T/S | B/S | L/T | SM/KB | KB/S | KB/L |
|---|---|---|---|---|---|---|
| SMA | 182.848 | 272.829 | 0.068 | 0.07 | 271.739 | 21.703 |
| PD | 199.586 | 231.867 | 0.046 | 0.057 | 216.549 | 23.58 |
| TREC | 195.462 | 337.233 | 0.09 | 0.081 | 360.797 | 20.56 |
The statistics of the data sets are relatively homogeneous. The TREC data contains more base co-occurrence statements per article, and has an increased ratio of (unique) lexicon terms per absolute number of (non-unique) tokens in the documents. TREC knowledge base also contains more statements per article than the other two, but the ratios of number of statements in it per lexicon term are more or less balanced. We believe that the statistics do not imply the need to treat each of the data sets differently when interpreting the results reported in the next section.
Graph statistics
The statistics of the graph data that are utilised in the random walks experiment are given in Tables 3 and 4 for PubMed and SKIMMR, respectively. The specific statistics provided on the graphs are: (1) number of nodes (|V|); (2) number of edges16 (|E|); (3) average number of edges per a node (); (4) density (, i.e., a ratio of the actual bidirectional connections between nodes relative to the maximum possible number of connections); (5) diameter (d, computed as an arithmetic mean of the longest possible paths in the connected components of the graph, weighted by the size of the components in nodes); (6) average shortest path length (lG, computed similarly to d as an average weighted mean of the value for each connected component); (7) number of connected components (|C|).
| Data set ID | |V| | |E| | D | d | lG | |C| | |
|---|---|---|---|---|---|---|---|
| SMA | 5,364 | 78,608 | 14.655 | 5.465⋅10−3 | 5.971 | 3.029 | 2 |
| PD | 8,622 | 133,188 | 15.447 | 3.584⋅10−3 | 6 | 2.899 | 2 |
| TREC | 10,734 | 161,838 | 15.077 | 2.809⋅10−3 | 7.984 | 3.146 | 3 |
| Data set ID | |V| | |E| | D | d | lG | |C| | |
|---|---|---|---|---|---|---|---|
| SMA | 15,287 | 305,077 | 19.957 | 2.611⋅10−3 | 5 | 2.642 | 1 |
| PD | 43,411 | 952,296 | 21.937 | 1.011⋅10−3 | 5 | 2.271 | 2 |
| TREC | 37,184 | 745,078 | 20.038 | 1.078⋅10−3 | 5.991 | 2.999 | 12 |
The statistics demonstrate that the SKIMMR graphs are larger and have higher absolute number of connections per a node, but are less dense than the PubMed graphs. All the graphs exhibit the “small-world” property (Watts & Strogatz, 1998), since the graphs have small diameters and there are also very short paths between the connected nodes despite the low density and relatively large size of the graphs.
Auxiliary data statistics
The MeSH data contained 719,877 terms and 54,935 tree codes, with ca. 2.371 tree code annotations per term in average. The statistics of the indices of related publications for SKIMMR and for gold standards are provided in Table 5. We provide values for the size of the index in numbers of publications covered (|P|) and an average number of related publications associated with each key (). The average length of the lists of related publications is much higher for all three instances of SKIMMR. This is a result of the small-world property of the SKIMMR networks which makes most of the publications connected with each other (although the connections mostly have weights close to zero).
| Gold standard | SKIMMR | |||
|---|---|---|---|---|
| Data set ID | |P| | |P| | ||
| SMA | 1,221 | 36.15 | 1,220 | 959.628 |
| PD | 4,727 | 28.61 | 4,724 | 4327.625 |
| TREC | 434 | 18.032 | 2,245 | 1251.424 |
Evaluation results
In the following we report on the results measured using the specific SKIMMR knowledge bases and corresponding baseline data. Each category of the evaluation measures is covered in a separate section. Note that we mostly provide concise plots and summaries of the results here in the article, however, full results can be found online (Data Deposition).
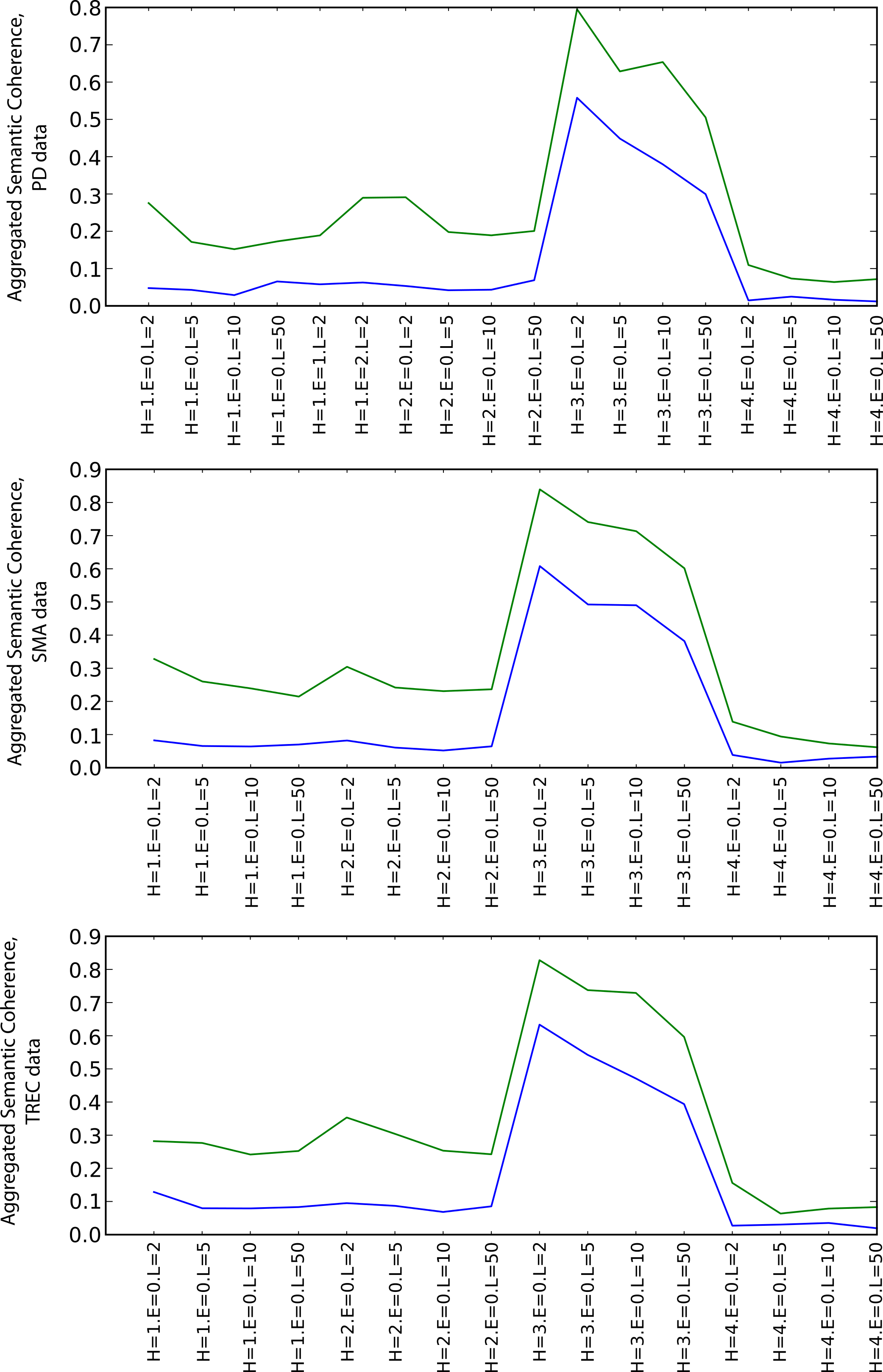
Semantic coherence
Figure 5 shows the values of the aggregated semantic coherence measures (i.e., source-target coherence, product path coherence and average path coherence) for the PD, SMA and TREC data sets. The values were aggregated by computing their arithmetic means and are denoted by the y-axis of the plots. The x-axis corresponds to different combinations of the heuristics and path lengths for the execution of the random walks (as the coherence does not depend on the envelope size, this parameter is zero all the time in this case).17 The combinations are grouped by heuristics (random preference, weight preference, similarity preference, dissimilarity preference from left to right). The path length parameter increases from left to right for each heuristic group on the x-axis. The green line is for the SKIMMR results and the blue line is for the PubMed baseline.

Figure 5: Aggregated semantic coherence (blue: PubMed, green: SKIMMR).
{kind=link}
For any combination of the random walk execution parameters, SKIMMR outperforms the baseline by quite a large relative margin. The most successful heuristic in terms of coherence is the one that prefers more similar nodes to visit next (third quarter of the plots), and the coherence is generally lower for longer paths, which are all observations corresponding to intuitive assumptions.
Information content
Figure 6 shows the values of the arithmetic mean of all types of information content measures for the particular combinations of the random walk execution parameters (including also envelope sizes in increasing order for each heuristic). Although the relative difference is not as significant as in the semantic coherence case, SKIMMR again performs consistently better than the baseline. There are no significant differences between the specific heuristics. The information content increases with longer walks and larger envelopes, which is due to generally larger numbers of clusters occurring among more nodes involved in the measurement.
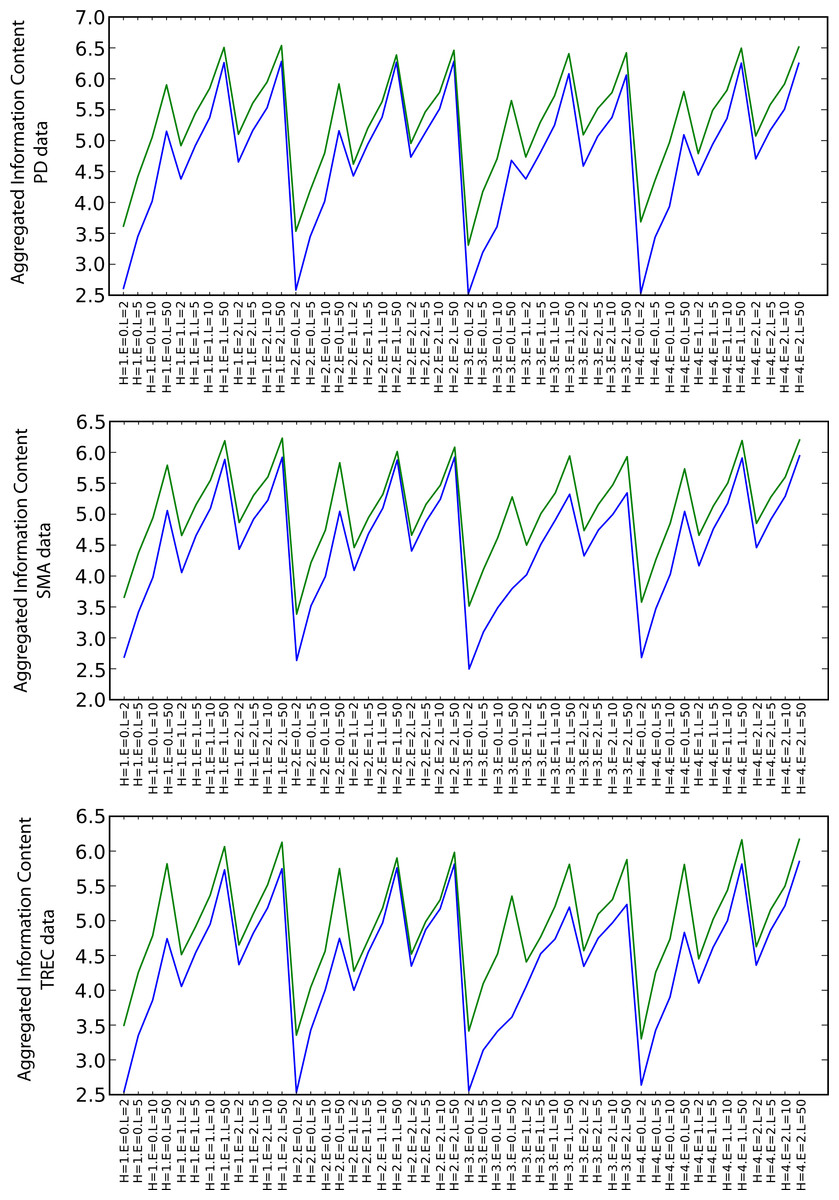
Figure 6: Aggregated information content (blue: PubMed, green: SKIMMR).
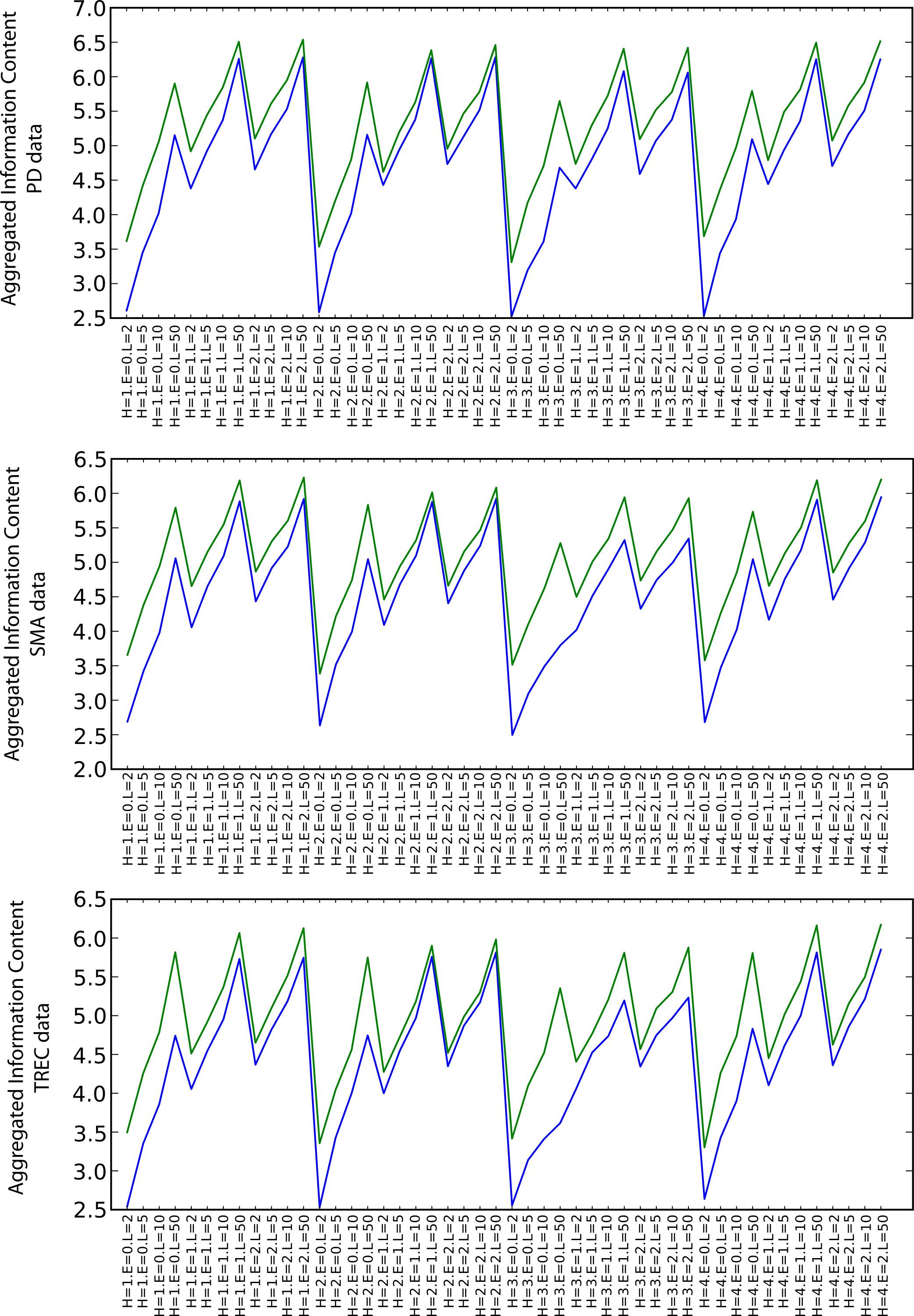{kind=link}
Graph Structure
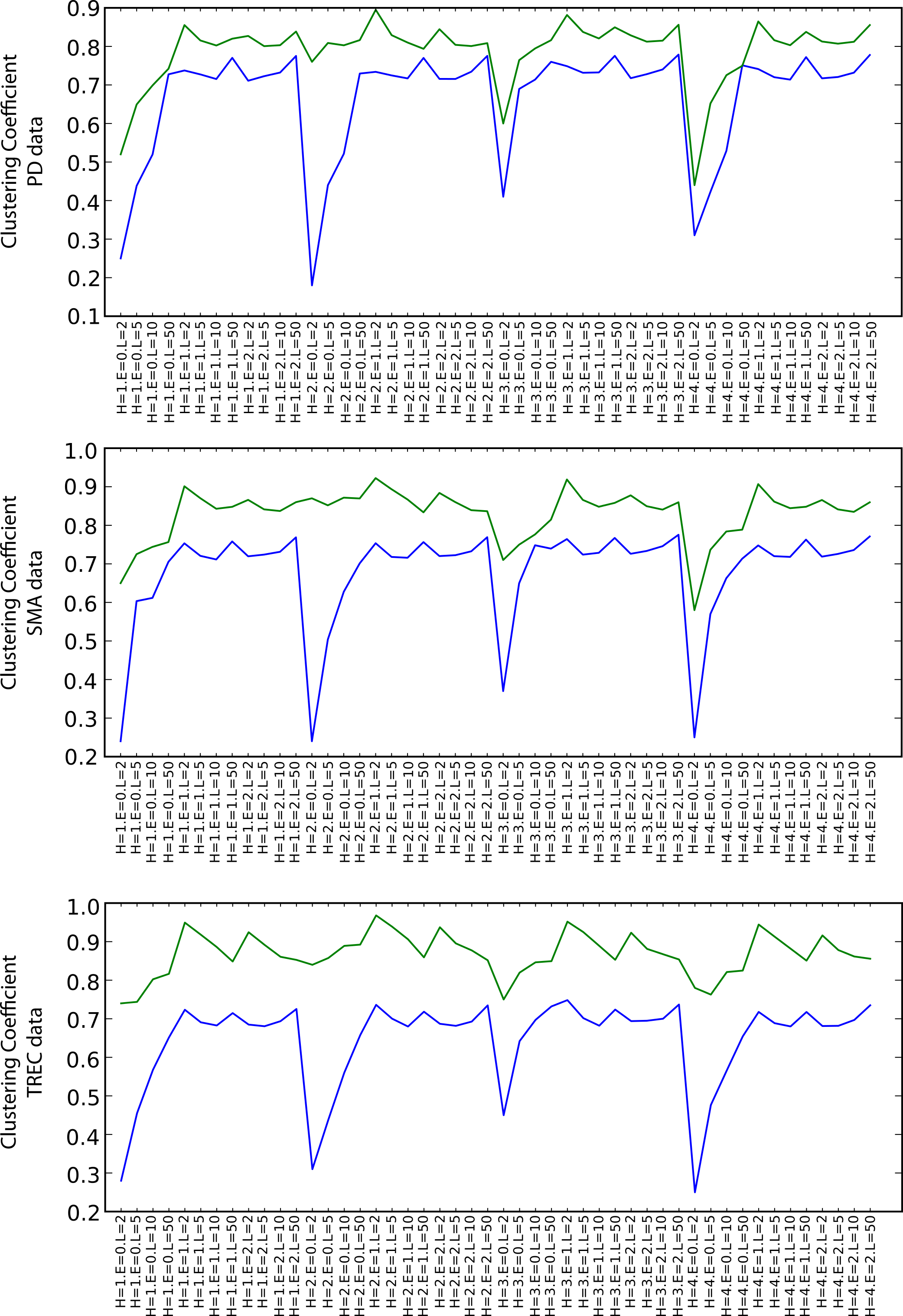
Figure 7 shows the values of the clustering coefficient, again with green and blue lines for the SKIMMR and PubMed baseline results, respectively. SKIMMR exhibits larger level of complexity than the baseline in terms of clustering coefficient, with moderate relative margin in most cases. There are no significant differences between the particular walk heuristics. The complexity generally increases with the length of the path, but, interestingly enough, does not so with the size of the envelopes. The highest complexity is typically achieved for the longest paths without any envelope. We suspect this to be related to the small world property of the graphs–adding more nodes from the envelope may not contribute to the actual complexity due to making the graph much more “uniformly” dense and therefore less complex.
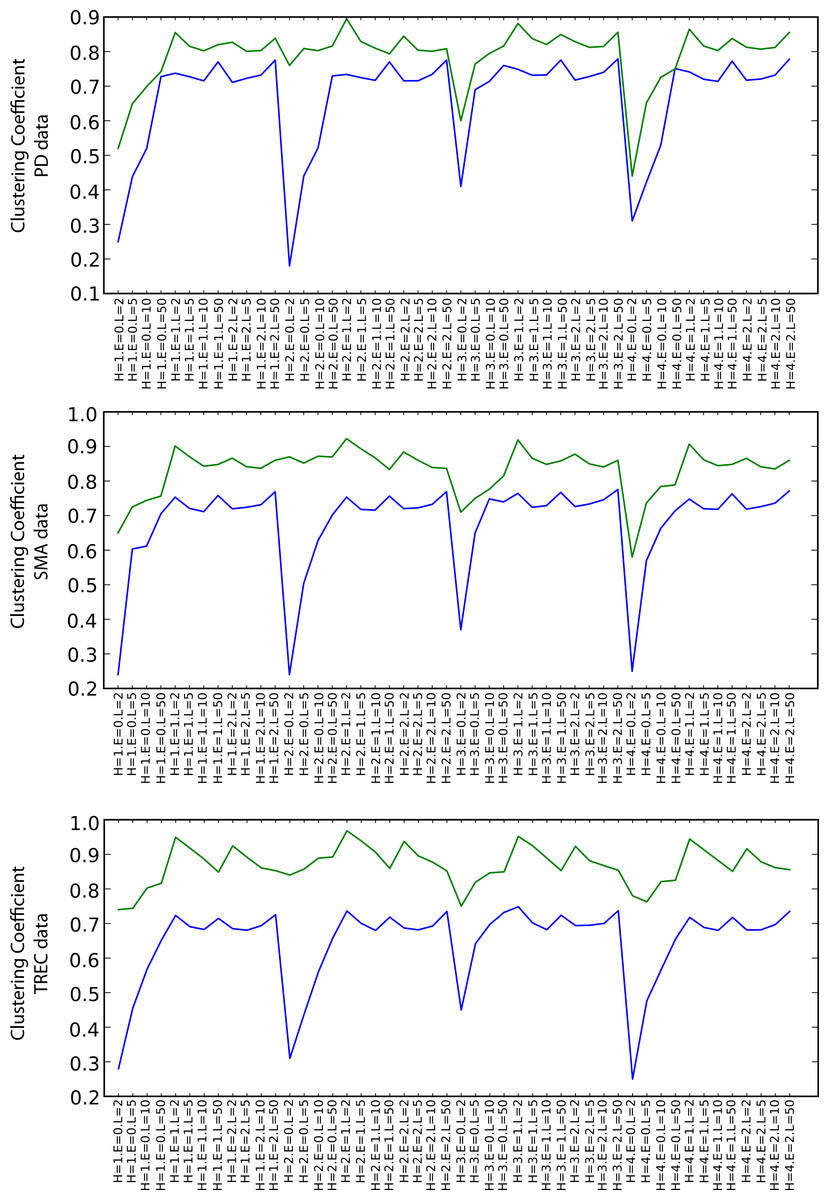
Figure 7: Clustering coefficient (blue: PubMed, green: SKIMMR).
{kind=link}
Auxiliary measures
The number of clusters associated with the nodes on the paths (measures M and Q) is always higher for SKIMMR than for the PubMed baseline. The number of clusters associated with the whole envelopes (measures O and S) is almost always higher for SKIMMR with few exceptions of rather negligible relative differences in favour of the baseline. The average numbers of nodes per cluster on the path (measures N and R) are higher for SKIMMR except for the heuristic that prefers similar nodes to visit next. This can be explained by the increased likelihood of populating already “visited” clusters with this heuristic when traversing paths with lower numbers of clusters along them. Finally, the average number of nodes per cluster in the envelope (measures P and T) is higher for SKIMMR in most cases.
The general patterns observed among the auxiliary measure values indicates higher topical variability in the SKIMMR graphs, as there are more clusters that have generally higher cardinality than in the PubMed baselines. This is consistent with the observation of the generally higher information content associated with the random walks in SKIMMR graphs.
Related articles
The results of the evaluation measures based on the lists of related articles generated by SKIMMR and by related baselines are summarised in Table 6. Note that as explained in ‘Evaluation data’, we used actual TREC evaluation data for the TREC dataset, while for PD and SMA, we used the related articles provided by PubMed due to negligible overlap with the TREC gold standard.
| PD | SMA | TREC | ||||||
|---|---|---|---|---|---|---|---|---|
| preavg | recavg | C ≥ 0.7 | preavg | recavg | C ≥ 0.7 | preavg | recavg | C ≥ 0.7 |
| 0.0095 | 0.0240 | 0.5576 | 0.0139 | 0.0777 | 0.5405 | 0.0154 | 0.0487 | 0.5862 |
The preavg and recavg columns in Table 6 contain the precision and recall values for each data set, respectively, and the C ≥ 0.7 contains the ratio of SKIMMR results that have significant correlation (i.e., at least 0.7) with the corresponding baseline. The absolute values of the average precision and recall are very poor, in units of percents. The correlation results are more promising, showing that more than half of the related document rankings produced by SKIMMR are reasonably aligned with the gold standard. Moreover, the correlation is highest for the TREC data set based on the only gold standard that is manually curated.
Discussion
SKIMMR provides a computational instantiation of the concept of ‘skim reading.’ In the early prototype stage, we generally focussed on delivering as much of the basic functionality as possible in a lightweight interface. Lacking enough representative data collected from ongoing user studies, we have designed a series of automated experiments to simulate several skim reading modes one can engage in with SKIMMR. We evaluated these experiments using gold standards derived from manually curated biomedical resources. Here we offer a discussion of the results in relation to the concept of machine-aided skim reading as realised by the SKIMMR prototype. The discussion is followed by an overview of related work and an outline of possible future directions.
Interpreting the results
The secondary evaluation using lists of related publications induced by the SKIMMR knowledge bases did not bring particularly good results in terms of precision and recall. However, the correlation with the related document ranking provided by baselines was more satisfactory. This indicates that with better methods for pruning the rather extensive lists of related publications produced with SKIMMR, we may be able to improve the precision and recall substantially. Still, this evaluation was indirect since generating lists of related publications is not the main purpose of SKIMMR. Apart from indirect evaluation, we were also curious whether the data produced by SKIMMR could not be used also for a rather different task straightaway. The lesson learned is that this may be possible, however, some post-processing of the derived publication lists would be required to make the SKIMMR-based related document retrieval more accurate for practical applications.
Our main goal was to show that our approach to machine-aided skim reading can be efficient in navigating high-level conceptual structures derived from large numbers of publications. The results of the primary evaluation experiment—simulations of various types of skimming behaviour by random walks—demonstrated that our assumption may indeed be valid. The entity networks computed by SKIMMR are generally more semantically coherent, more informative and more complex than similar networks based on the manually curated PubMed article annotations. This means that users will typically be able to browse the SKIMMR networks in a more focused way. At the same time, however, they will learn more interesting related information from the context of the browsing path, and can also potentially gain additional knowledge from more complex relationships between the concepts encountered on the way. This is very promising in the context of our original motivations for the presented research.
Experiments with actual users would have brought many more insights regarding the practical relevance of the SKIMMR prototype. Still, the simulations we have proposed cover four distinct classes of possible browsing behaviour, and our results are generally consistent regardless of the particular heuristic used. This leads us to believe that the evaluation measures computed on paths selected by human users would not be radically different from the patterns observed within our simulations.
Related work
The text mining we use is similar to the techniques mentioned in Yan et al. (2009), but we use a finer-grained notion of co-occurrence. Regarding biomedical text mining, tools like BioMedLEE (Friedman et al., 2004), MetaMap (Aronson & Lang, 2010) or SemRep (Liu et al., 2012) are closely related to our approach. The tools mostly focus on annotation of texts with concepts from standard biomedical vocabularies like UMLS which is very useful for many practical applications. However, it is relatively difficult to use the corresponding software modules within our tool due to complex dependencies and lack of simple APIs and/or batch scripts. The tools also lack the ability to identify concepts not present in the biomedical vocabularies or ontologies. Therefore we decided to use LingPipe’s batch entity recogniser in SKIMMR. The tool is based on a relatively outdated GENIA corpus, but is very easy to integrate, efficient and capable of capturing unknown entities based on the underlying statistical model, which corresponds well to our goal of delivering a lightweight, extensible and easily portable tool for skim-reading.
The representation of the relationships between entities in texts is very close to the approach of Baroni & Lenci (2010), however, we have extended the tensor-based representation to tackle a broader notion of text and data semantics, as described in detail in Nováček, Handschuh & Decker (2011). The indexing and querying of the relationships between entities mentioned in the texts is based on fuzzy index structures, similarly to Zadrozny & Nowacka (2009). We make use of the underlying distributional semantics representation, though, which captures more subtle features of the meaning of original texts.
Graph-based representations of natural language data have previously been generated using dependency parsing (Ramakrishnan et al., 2008; Biemann et al., 2013). Since these representations are derived directly from the parse structure, they are not necessarily tailored for the precise task of skim-reading but could provide a valuable intermediate representation. Another graph-based representation that is derived from the text of documents are similarity-based approaches derived from ‘topic models’ of document corpora (Talley et al., 2011). Although these analyses typically provide a visualization of the organization of documents, not of their contents, the topic modeling methods provide statistical representation of the text that can then be leveraged to examine other aspects of the context of the document, such as its citations (Foulds & Smyth, 2013).
A broad research area of high relevance to the presented work is the field of ‘Machine Reading’ that can be defined as “the autonomous understanding of text” (Etzioni, Banko & Cafarella, 2006). It is an ambitious goal that has attracted much interest from NLP researchers (Mulkar et al., 2007; Strassel et al., 2010; Poon & Domingos, 2010). By framing the reading task as ‘skimming’ (which provides a little more structure than simply navigating a set of documents, but much less than a full representation of the semantics of documents), we hope to leverage machine reading principles into practical tools that can be used by domain experts straightforwardly.
Our approach shares some similarities with applications of spreading activation in information retrieval which are summarised for instance in the survey (Crestani, 1997). These approaches are based on associations between search results computed either off-line or based on the “live” user interactions. The network data representation used for the associations is quite close to SKIMMR, however, we do not use the spreading activation principle to actually retrieve the results. We let the users to navigate the graph by themselves which allows them to discover even niche and very domain-specific areas in the graph’s structure that may not be reached using the spreading activation.
Works in literature based discovery using either semantic relationships (Hristovski et al., 2006) or corresponding graph structures (Wilkowski et al., 2011) are conceptually very similar to our approach to skim reading. However, the methods are quite specific when deployed, focusing predominantly on particular types of relationships and providing pre-defined schema for mining instances of the relationships from the textual data. We keep the process lightweight and easily portable, and leave the interpretation of the conceptual networks on the user. We do lose some accuracy by doing so, but the resulting framework is easily extensible and portable to a new domain within minutes, which provides for a broader coverage compensating the loss of accuracy.
From the user perspective, SKIMMR is quite closely related to GoPubMed (Dietze et al., 2008), a knowledge-based search engine for biomedical texts. GoPubMed uses Medical Subject Headings and Gene Ontology to speed up finding of relevant results by semantic annotation and classification of the search results. SKIMMR is oriented more on browsing than on searching, and the browsing is realised via knowledge bases inferred from the texts automatically in a bottom-up manner. This makes SKIMMR independent on any pre-defined ontology and lets users to combine their own domain knowledge with the data present in the article corpus.
Tools like DynaCat (Pratt, 1997) or QueryCat (Pratt & Wasserman, 2000) share the basic motivations with our work as they target the information overload problem in life sciences. They focus specifically on automated categorisation of user queries and the query results, aiming at increasing the precision of document retrieval. Our approach is different in that it focuses on letting users explore the content of the publications instead of the publications themselves. This provides an alternative solution to the information overload by leading users to interesting information spanning across multiple documents that may not be grouped together by Pratt (1997) and Pratt & Wasserman (2000).
Another related tool is Exhibit (Huynh, Karger & Miller, 2007), which can be used for faceted browsing of arbitrary datasets expressed in JSON (Crockford, 2006). Using Exhibit one can dynamically define the scope from which they want to explore the dataset and thus quickly focus on particular items of interest. However, Exhibit does not provide any solution on how to get the structured data to explore from possibly unstructured resources (such as texts).
Textpresso (Müller, Kenny & Sternberg, 2004) is quite similar to SKIMMR concerning searching for relations between concepts in particular chunks of text. However, the underlying ontologies and their instance sets have to be provided manually which often requires years of work, whereas SKIMMR operates without any such costly input. Moreover, the system’s scale regarding the number of publications’ full-texts and concepts covered is generally lower than the instances of SKIMMR that can be set up in minutes.
CORAAL (Nováček et al., 2010) is our previous work for cancer publication search, which extracts relations between entities from texts, based on the verb frames occurring in the sentences. The content is then exposed via a multiple-perspective search and browse interface. SKIMMR brings the following major improvements over CORAAL: (1) more advanced back-end (built using our distributional data semantics framework introduced in Nováček, Handschuh & Decker, 2011); (2) simplified modes of interaction with the data leading to increased usability and better user experience; (3) richer, more robust fuzzy querying; (4) general streamlining of the underlying technologies and front-ends motivated by the simple, yet powerful metaphor of machine-aided skim reading.
Future work
Despite the initial promising results, there is still much to do in order to realise the full potential of SKIMMR as a machine-aided skim reading prototype. First of all, we need to continue our efforts in recruiting coherent and reliable sample user groups for each of the experimental SKIMMR instances in order to complement the presented evaluation by results of actual user studies. Once we get the users’ feedback, we will analyse it and try to identify significant patterns emerging from the tracked behaviour data in order to correlate them with the explicit feedback, usability assessments and the results achieved in our simulation experiments. This will provide us with a sound basis for the next iteration of the SKIMMR prototype development, which will reflect more representative user requirements.
Regarding the SKIMMR development itself, the most important things to improve are as follows. We need to extract more types of relations than just co-occurrence and rather broadly defined similarity. One example of domain specific complex relation are associations of potential side effects with drugs. Another, more general example, is taxonomical relations (super-concept, sub-concept), which may help provide additional perspective to browsing the entity networks (i.e., starting with high-level overview of the relations between more abstract concepts and then focusing on the structure of the connections between more specific sub-concepts of selected nodes). Other improvements related to the user interface are: (1) smoother navigation in the entity networks (the nodes have to be active and shift the focus of the displayed graph upon clicking on them, they may also display additional metadata, such as summaries of the associated source texts); (2) support of more expressive (conjunctive, disjunctive, etc.) search queries not only in the back-end, but also in the front-end, preferably with a dedicated graphical user interface that allows to formulate the queries easily even for lay users; (3) higher-level visualisation features such as evolution of selected concepts’ neighbourhoods in time on a sliding scale. We believe that realisation of all these features will make SKIMMR a truly powerful tool for facilitating knowledge discovery (not only) in life sciences.