
Dynamic multiple-graph spatial-temporal synchronous aggregation framework for traffic prediction in intelligent transportation systems
- Published
- Accepted
- Received
- Academic Editor
- Xiangjie Kong
- Subject Areas
- Algorithms and Analysis of Algorithms, Artificial Intelligence, Data Mining and Machine Learning, Spatial and Geographic Information Systems, Neural Networks
- Keywords
- Traffic prediction, Graph neural network, Spatial-temporal synchronous, Multiple-graph, External factors
- Copyright
- © 2024 Yu et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2024. Dynamic multiple-graph spatial-temporal synchronous aggregation framework for traffic prediction in intelligent transportation systems. PeerJ Computer Science 10:e1913 https://doi.org/10.7717/peerj-cs.1913
Abstract
Accurate traffic prediction contributes significantly to the success of intelligent transportation systems (ITS), which enables ITS to rationally deploy road resources and enhance the utilization efficiency of road networks. Improvements in prediction performance are evident by utilizing synchronized rather than stepwise components to model spatial-temporal correlations. Some existing studies have designed graph structures containing spatial and temporal attributes to achieve spatial-temporal synchronous learning. However, two challenges remain due to the intricate dynamics: (a) Accounting for the impact of external factors in spatial-temporal synchronous modeling. (b) Multiple perspectives in constructing spatial-temporal synchronous graphs. To address the mentioned limitations, a novel model named dynamic multiple-graph spatial-temporal synchronous aggregation framework (DMSTSAF) for traffic prediction is proposed. Specifically, DMSTSAF utilizes a feature augmentation module (FAM) to adaptively incorporate traffic data with external factors and generate fused features as inputs to subsequent modules. Moreover, DMSTSAF introduces diverse spatial and temporal graphs according to different spatial-temporal relationships. Based on this, two types of spatial-temporal synchronous graphs and the corresponding synchronous aggregation modules are designed to simultaneously extract hidden features from various aspects. Extensive experiments constructed on four real-world datasets indicate that our model improves by 3.68–8.54% compared to the state-of-the-art baseline.
Introduction
Intelligent transportation systems (ITS) provide efficient guidance for real-time traffic management and assist people in scheduling their travel plans in advance (Shaygan et al., 2022). An essential function of ITS is traffic prediction, based on which it can optimize the allocation of road network resources and reduce traffic problems such as congestion and accidents (Kong et al., 2024). Therefore, the operation of ITS is heavily dependent on precise traffic prediction, the core of which is modeling spatial-temporal dynamics of traffic features. Recent years have witnessed a widespread application of graph convolutional network (GCN) for extracting spatial correlations, where the distribution of traffic sensors is modeled as a series of nodes and edges in a graph (Bao et al., 2023; Kong et al., 2022; Chen et al., 2022; Huang et al., 2022). In addition, recurrent neural network (RNN) and its variants, also known as long short-term memory (LSTM) and gated recurrent unit (GRU) have been extensively applied to model temporal dependency due to their outstanding performance in processing time series (Zhao et al., 2023; Ma et al., 2023; Afrin & Yodo, 2022; Ma, Dai & Zhou, 2022). Some studies employ convolutional neural network (CNN) instead of RNN to learn temporal dynamics (Wen et al., 2023; Ni & Zhang, 2022). To synchronize the extraction of spatial-temporal features, some work has designed graph structures that contain both spatial and temporal attributes (Song et al., 2020; Li & Zhu, 2021; Jin et al., 2022; Wei et al., 2023). In spite of the pioneering advances in these studies, there is still a lack of sufficiently practical approaches in spatial and temporal synchronous learning owing to the complexity of traffic dynamics.
Firstly, traffic features depend not only on their historical data but are also influenced by external factors. As illustrated in Fig. 1A, the traffic flow varies significantly with meteorological factors. For example, in the case of sunny weather and comfortable temperatures, there is a significant increase in traffic flow in the tourist area. In contrast, there is a remarkable decrease in the same area in the case of heavy rain and cold environments. Secondly, there are multiple spatial-temporal relationships between traffic nodes. Spatially, different nodes can be measured by neighborhood or distance. Temporally, the traffic flow between different nodes shows the same pattern or exhibits the same trend. As shown in Fig. 1B, nodes A and B’s traffic flow rise between 5:00 and 10:00 and fall between 17:00 and 22:00, and their rising and falling rates are almost the same, showing a strong linear correlation, thus confirming that they have the same pattern. The traffic flow of node C, although it has a similar variation interval, alters more gently and shows a weaker linear correlation with the flow of node A. Therefore, they exhibit the same trend despite their different patterns. For these reasons, two challenges remain in learning spatial-temporal dependencies of traffic features.
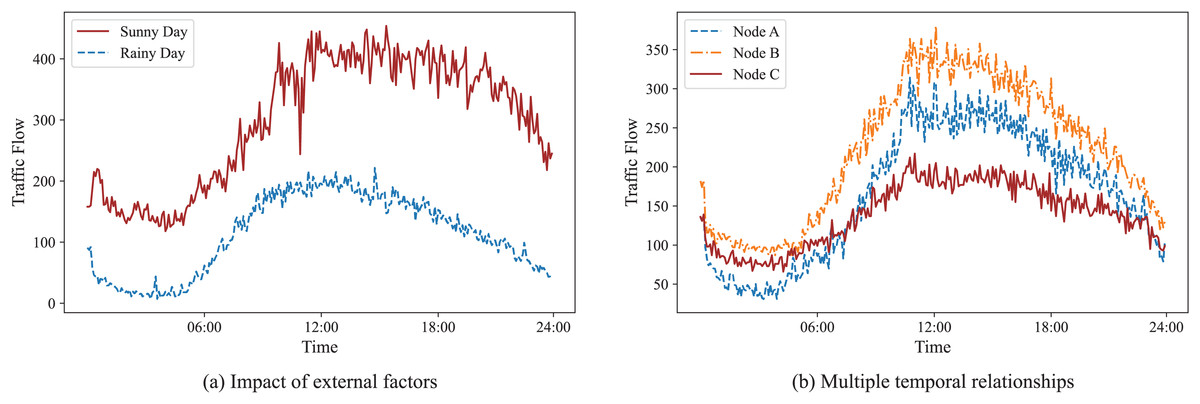
Figure 1: Examples of the impact of external factors and the multiple temporal relationships.
(A) Graph showing that the traffic flow on a sunny day is distinctly different from that on a rainy day. (B) Graph illustrating that nodes A and B, with a strong linear correlation, have the same pattern, while nodes C and A exhibit the same trend.{kind=link}
(a) Accounting for the impact of external factors in spatial-temporal synchronous modeling. Traffic features change in response to external factors, so learning the effects of external factors in spatial-temporal synchronous modeling is necessary. Zhu et al. (2021) introduced dynamic and static external factors and then encoded them into a graph convolutional network to obtain predictions that take external factors into account. The study by Qi et al. (2022) proposed an attribute feature unit to fuse weather conditions, temperature, visibility, as well as traffic flow, and fed the fused features into temporal graph convolutional network (T-GCN) for modeling spatial-temporal dependencies. Sun et al. (2022) utilized interactive and internal attention mechanisms to embed traffic data and external factors into high-dimensional sequences, which increased the accuracy of predictions. These studies took into consideration the influence of external factors, but they failed to accomplish spatial-temporal simultaneous modeling. In contrast, spatial-temporal synchronous graph convolutional networks (STSGCN) (Song et al., 2020), spatial-temporal fusion graph neural networks (STFGNN) (Li & Zhu, 2021), automated dilated spatio-temporal synchronous graph network (Auto-DSTSGN) (Jin et al., 2022) and spatial-temporal graph synchronous aggregation model (STGSA) (Wei et al., 2023) synchronously learned spatial and temporal dynamics. However, they only adopted traffic features as inputs to the model and ignored the impact of external factors. Overlooking external factors in spatial-temporal synchronous modeling causes obvious deficiencies in traffic prediction.
(b) Multiple perspectives in constructing spatial-temporal synchronous graphs. Both spatial and temporal relationships of traffic features are intricate and can be characterized through various perspectives. Modeling spatial and temporal dependencies from a single aspect can result in the neglect of some vital information. STSGCN (Song et al., 2020) built localized synchronous graphs according to whether nodes are adjacent in time or space. Based on this, STFGNN (Li & Zhu, 2021) introduced temporal graphs produced by a dynamic time warping algorithm to model temporal dependency. Further, Auto-DSTSGN (Jin et al., 2022) reduced the size of synchronous graphs while keeping the spatial and temporal graphs consistent. STGSA (Wei et al., 2023) proposed heuristic spatial graphs, but its synchronous graphs are limited to simple connections in the time dimension. Learning spatial or temporal correlation from only one perspective limits existing models’ capabilities to extract hidden features.
To address the mentioned limitations, a novel model called dynamic multiple-graph spatial-temporal synchronous aggregation framework (DMSTSAF) is proposed in this article. Specifically, we design a feature augmentation module (FAM) that employs spatial and temporal attention mechanisms to integrate traffic features and external factors. In addition, we construct multiple spatial-temporal synchronous graphs to model various spatial-temporal dynamics. Our main contributions to this work are as follows:
We propose a feature augmentation module to combine traffic features with external factors, in which spatial and temporal attention mechanisms are applied to integrate the two inputs adaptively and generate fused features.
We construct diverse spatial and temporal graphs, and consequently design two kinds of dynamic spatial-temporal synchronous graphs and the corresponding synchronous aggregation modules, which model spatial and temporal correlations simultaneously in multiple perspectives.
To test the performance of our model in diverse cases, we conduct extensive experiments on four real-world datasets. The numerical results indicate that DMSTSAF improves by 3.68–8.54% in comparison to the state-of-the-art baseline, demonstrating the consistent superiority of the proposed model.
The rest of this article is organized as follows. “Literary Review” provides the related work on graph neural network and traffic prediction. “Preliminary” introduces the mathematical definition of the task. “Methodology” presents the detailed process of our methodology. In “Experiments”, extensive experiments are demonstrated, and the results are analyzed. “Discussion” states the concluding remarks.
Literary review
Graph neural network
Compared to CNN, graph neural network (GNN) can handle non-Euclidean data, which has led to its wide application in many fields such as feature extraction, node classification, etc. The classifications of GNN are categorized into two types: spectral domain and spatial domain. The former, also known as GCN, has undergone three important developments. Bruna et al. (2014) implemented graph convolution operations by replacing the convolution kernel with a learnable diagonal matrix. To overcome the problem of excessive computation, Defferrard, Bresson & Vandergheynst (2016) introduced Chebyshev polynomials to approximate the convolutional kernel. Kipf & Welling (2017) further reduced Chebyshev polynomials to the first order, which greatly simplified the computation and obtained the most common GCN expressions. The latter aims to define GNN by iteratively updating the representation of nodes from spatial neighbor aggregation. In order to avoid excessive nodes participating in the computation, graph sample and aggregate (GraphSAGE) et al. (Hamilton, Ying & Leskovec, 2017) limited the number of neighboring nodes by sampling and then achieved information aggregation through pooling operations. Atwood & Towsley (2016) defined the weights of neighbors using the K-hop transfer probabilities obtained after a random walk. Graph attention network (GAT) (Velivčkovič et al., 2018) employed the attention mechanism to define the weights for various neighbors, which allowed for a more flexible characterization of the aggregation in different scenarios.
Traffic prediction
In recent years, neural network has been extensively utilized for traffic prediction, which offers superior modeling performance compared to traditional methods (Guo et al., 2021). Most studies utilized graph convolution network to capture spatial feature (Li et al., 2022; Wang et al., 2022; Zhu et al., 2022; Yao et al., 2023; Yang et al., 2022). GraphSAGE has also been used to model spatial dependency for inductive learning (Liu et al., 2023; Liu, Ong & Chen, 2022). Temporal modules based on RNN and its LSTM, as well as GRU, have been introduced to learn temporal dependence (Pan et al., 2022; Subramaniyan et al., 2023; Bao et al., 2022; Shu, Cai & Xiong, 2022; Wan et al., 2022). To improve computational efficiency, some studies employed CNN instead of RNN to model temporal correlation (Ji, Yu & Lei, 2023; Zhang et al., 2022). Li et al. (2018) designed an encoder-decoder architecture that employed a diffusion process characterized by a bidirectional walk of a graph to learn spatial dependency and proposed the diffusion convolutional gated recurrent unit to model temporal dynamics. Based on this, Wu et al. (2019) further introduced an adaptive adjacency matrix in diffusion convolution to discover hidden spatial features and then employed dilated stacked 1D convolutions with larger receptive fields to capture temporal trends. Yu, Yin & Zhu (2018) defined the problem on a graph and then modeled spatial correlation by utilizing graph convolution with Chebyshev polynomials approximation, and took advantage of gated CNN to extract temporal features. On this foundation, Guo et al. (2019) incorporated GCN and attention mechanisms to enhance the representation of features, then deployed three parallel sets of components to learn different temporal trends. T-GCN (Zhao et al., 2020) integrated GCN with GRU as a way to learn the complex dynamics of traffic features. Graph multi-attention network (GMAN) (Zheng et al., 2020) adopted exclusively attention mechanisms rather than convolutional network to transform input features into predictions, which had a high computational complexity but improved the prediction accuracy.
To achieve synchronous modeling of spatial-temporal correlations, STSGCN (Song et al., 2020) constructed localized synchronous graphs, which aggregated information from neighbor nodes at the current time step and from themselves at adjacent time steps. Based on this, STFGNN (Li & Zhu, 2021) further fused spatial graphs and temporal graphs to learn the hidden correlations simultaneously. Auto-DSTSGN (Jin et al., 2022) designed an automated dilated spatial-temporal synchronous graph module to extract the short-range and long-range correlations by stacked layers with dilated factors. STGSA (Wei et al., 2023) proposed a specialized graph aggregation to capture spatial-temporal dynamics.
To summarize, most of the studies adopted separate components to learn spatial and temporal correlations, failing to achieve synchronous modeling. A few works implemented simultaneous aggregation of spatial and temporal features, but their models only took into account the hidden dependencies of traffic data itself, failing to model the impacts of external factors. In addition, their spatial-temporal synchronous graphs represented only a single correlation in terms of space and time, with a failure to model spatial and temporal dynamics from multiple perspectives, resulting in the overlook of certain dependencies. To address these shortcomings in spatial-temporal synchronous modeling, this article proposes a novel approach that learns the influence of external factors by fusing them with traffic features through attention mechanisms, and constructs diverse spatial-temporal synchronous graphs to extract spatial-temporal features in multiple ways.
Preliminary
A traffic road network containing N sensors can be described as a graph , where denotes the -th node in graph , and each element of denotes an undirected edge between two nodes. The structure of is represented by a spatial adjacency matrix , which is determined by the distribution of nodes. Each element of denotes the connection between node and node .
The traffic features (traffic flow, speed, occupancy) of node at time step are expressed as , while the historical traffic features of graph at can be described as:
(1)
The task of traffic prediction is to learn a multivariant regression function with parameters for forecasting future traffic features based on historical traffic features , which can be defined as:
(2) where denotes the length of historical traffic features. The aim of this task is to obtain the optimal parameters to minimize the error between the prediction and the ground truth, which can be formulated as:
(3) where is the ground truth, denotes the length of future traffic features, and L is the loss function.
Methodology
The overall architecture of our model is presented in Fig. 2. We design FAM to take into account the influence of external factors on traffic prediction. Specifically, traffic features and external factors are first concatenated, then fused through spatial and temporal attention mechanisms, and finally mapped to a high-dimensional space and used as inputs to the model. FAM introduces external factors as part of inputs to the model and enhances the representation of traffic features, which addresses the first limitation mentioned in “Introduction”. Then, we stack several dynamic multiple-graph spatial-temporal synchronous aggregation layers (DMSTSAL) to model spatial-temporal dependencies. In each layer, we construct two kinds of dynamic spatial-temporal synchronous graphs in parallel: trend spatial-temporal synchronous graph and pattern spatial-temporal synchronous graph. We then deploy a spatial-temporal synchronous aggregation module (STSAM) for each spatial-temporal synchronous graph. The outputs of the two types of modules are fused through a gating mechanism. The design of dynamic multiple graphs instead of a single graph empowers the model to learn spatial-temporal correlations comprehensively, which overcomes the second limitation mentioned in “Introduction”. In addition, dilated gated convolution module (DGCM) is also designed to extract long-term dependencies in each layer, and its output is integrated with the outputs of both types of STSAMs. We further design the output module with concatenation and fully connected layers to transform the outputs of DMSTSALs into predictions.
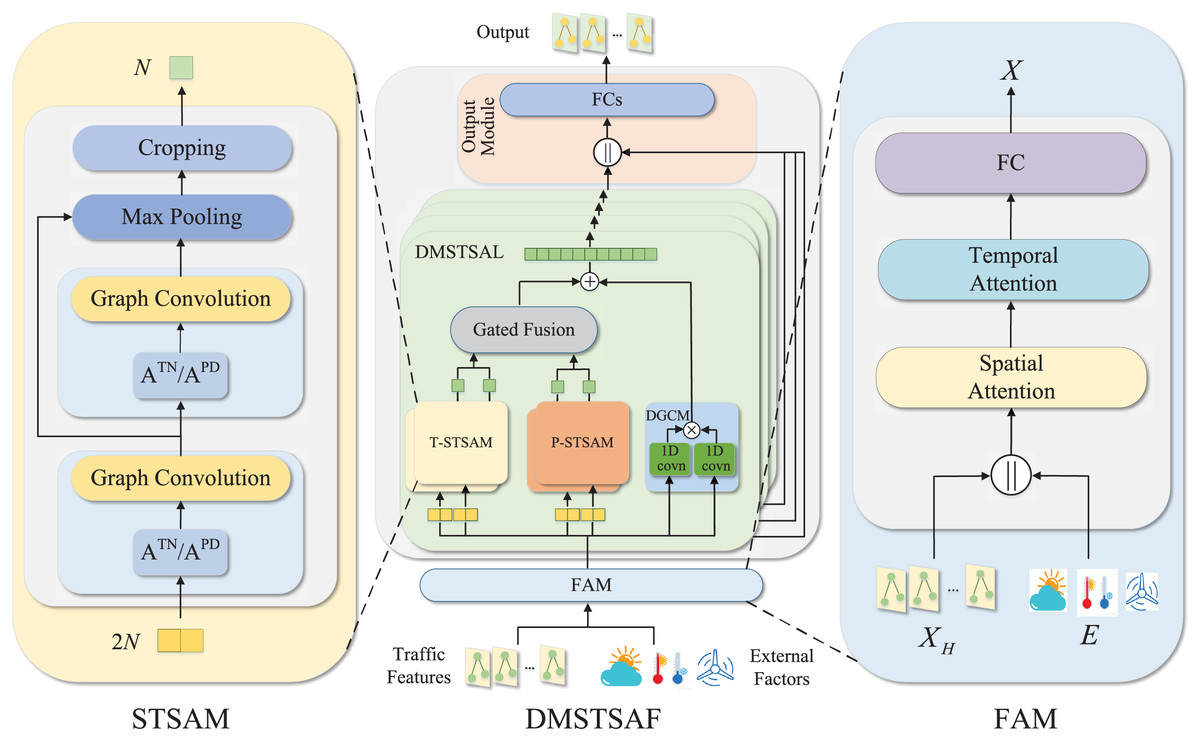
Figure 2: Detailed framework of DMSTSAF, FAM, and STSAM.
A DMSTSAF contains an FAW, four DMSTSALs, and an output module. Traffic features and external factors are first concatenated, then spatial attention and temporal attention are applied to enhance representation, and then high-dimensional hidden features are obtained via a fully connected layer. Independent T-STSAMs and parallel P-STSAMs in each DMSTSAL are designed to model spatial-temporal dependencies from multiple perspectives. In STSAMs, stacked graph convolutions followed by the max pooling and the cropping operation are incorporated with spatial-temporal synchronous graphs to extract spatial-temporal features synchronously. Gated 1D convolutions with shared parameters are utilized to learn long-term correlations in DGCM. Finally, the output module yields the predictions of the model.{kind=link}
In the next subsections, we describe in detail the various components of DMSTSAF, including FAW, graph construction, STSAM, DTCM, DMSTSL, and output module. To facilitate the understanding of this study, we explain the definitions of some notations used throughout this article in Table 1.
| Notations | Explanations |
|---|---|
| Historical traffic features | |
| E | External factors |
| S | Spatial attention matrix |
| U | Temporal attention matrix |
| X | Fused feature |
| Trend spatial-temporal synchronous graph | |
| Pattern spatial-temporal synchronous graph | |
| Dynamic adjacency matrix of | |
| Dynamic adjacency matrix of | |
| Output of T-STSAM | |
| Output of P-STSAM | |
| Output of gated fusion | |
| Output of gated 1D convolution | |
| Number of step pairs in the -th DMSTSAL | |
| Output of the -th DMSTSAL |
Feature augmentation module
Traffic features are affected by external factors such as weather, temperature, wind, etc. In order to integrate external factors with traffic features for accurate traffic prediction, we design FAW, whose structure is shown in Fig. 2. The comfort of the temperature is closely related to people’s willingness to travel, and the traffic flow in the road network shows varying intensities under different weather conditions (e.g., sunny, rainy). In addition, wind also affects people’s travel plans. Therefore, we take account of the effects of four external factors that have the most impact on traffic, namely, maximum temperature, minimum temperature, weather, and wind. The external factors matrix is denoted as . The historical traffic feature matrix is denoted as , where C is the dimension of traffic features. To better illustrate the point in spatial and temporal attention, we define a fully connected layer as:
(4) where W and are learnable parameters, and is the activation function.
represents the spatial attention matrix of N nodes in T time steps. We consider both traffic features and external factors to measure the spatial attention of different nodes. To be specific, we concatenate traffic features with external factors, and calculate the spatial correlation coefficient between node and at time step based on the scaled dot-product, which can be formulated as:
(5) where represents the inner product, denotes the concatenation, and represent two different fully connected layers respectively, , and . The spatial attention coefficient is then obtained by normalizing via softmax:
(6)
denotes the temporal attention matrix of T time steps among N nodes. We take into consideration both traffic features and external factors to learn the temporal attention of various time steps. Specifically, we first concatenate traffic features with external factors, and then employ the scaled dot-product to compute the temporal correlation coefficient. After that, the temporal attention coefficient is obtained by softmax, which can be described as:
(7) where denotes the temporal correlation coefficient of node between time step and , is the temporal attention coefficient, represent two independent fully connected layers respectively.
After obtaining the spatial attention matrix S and the temporal attention matrix U, traffic features and external factors are fused and mapped to the high-dimensional space, and the mathematical expression can be defined as:
(8) where is the fused feature.
Dynamic spatial-temporal synchronous graph construction
Traffic features are related in multiple ways over time and space. On the one hand, nodes in different locations have adjacency and distance relationships. On the other hand, different traffic features may have the same temporal pattern or trend. A single spatial or temporal graph can only focus on one aspect of spatial-temporal dependencies while ignoring others. Aiming to model spatial-temporal correlations from multiple perspectives, we first propose two spatial graphs, i.e., the neighbor graph and the distance graph , as well as two temporal graphs, i.e., the trend graph and the pattern graph , and then design two dynamic spatial-temporal synchronous graphs based on them, i.e., the trend spatial-temporal synchronous graph and the pattern spatial-temporal synchronous graph .
Neighbor graph. denotes the spatial adjacency of nodes, and the elements of its adjacency matrix are defined as:
(9)
Distance graph. represents the distance relationship between nodes, the elements of are fomulated as:
(10) where denotes the Euclidean distance between node and , denotes the standard deviation of Euclidean distance, is hyperparameters used to control the sparsity of .
Trend graph. In order to capture the trend similarity between traffic features, we propose the trend graph based on dynamic time warping (DTW) algorithm. Given two sequences and , the element of distance matrix can be calculated by (Li & Zhu, 2021), and the DTW distance between P and Q can be obtained by the iteration of the following equations:
(11)
The adjacency matrix can be formulated as:
(12) where come from (11), denotes the hyperparameter to control the sparsity of .
Pattern graph. Some traffic nodes exhibit strong linear correlation in their features because they are located in the same functional area (e.g., residential area, commercial area, etc.), as shown in Fig. 1B. For the purpose of extracting pattern similarity, we design the pattern graph by Pearson correlation coefficient. The traffic feature series of nodes and are denoted as , respectively. The Pearson correlation coefficient between and can be defined as:
(13) and the adjacency matrix of can be formulated as:
(14) where denotes the hyperparameter to manipulate the sparsity of .
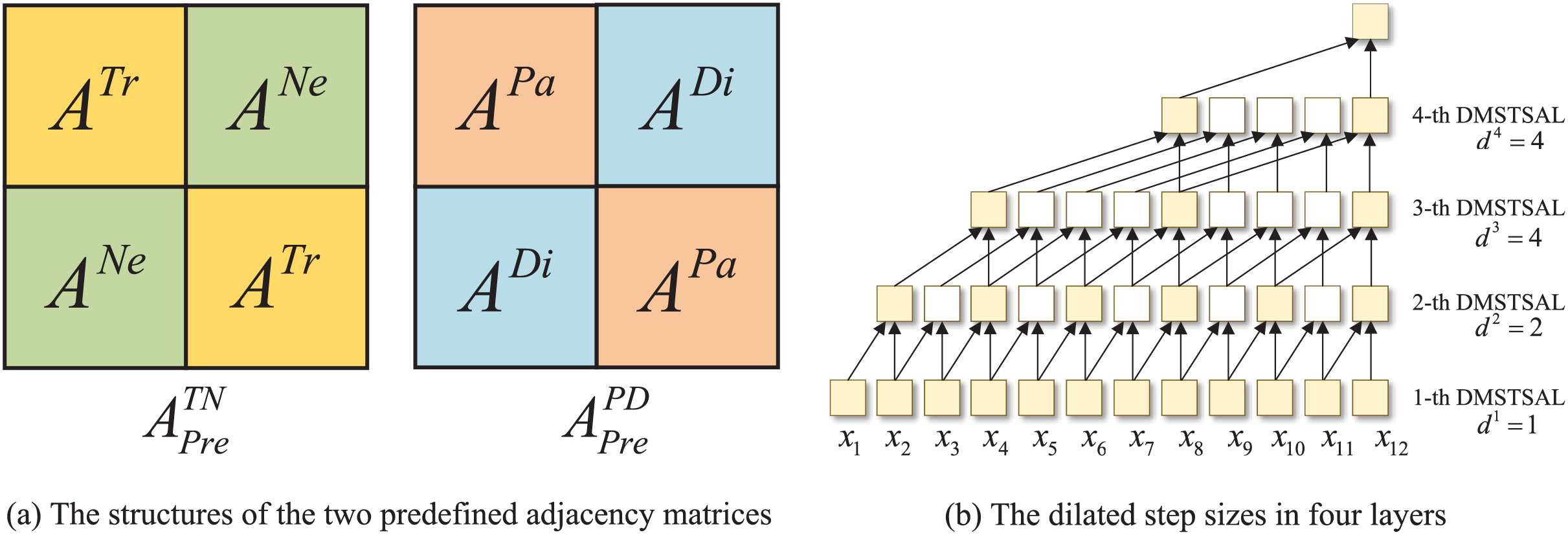
Dynamic spatial-temporal synchronous graphs. The spatial and temporal correlations of traffic features exist simultaneously, and to model this intricate spatial-temporal dependencies synchronously from multiple perspectives, we propose the trend spatial-temporal synchronous graphs and the pattern spatial-temporal synchronous graphs inspired by STSGCN (Song et al., 2020) and STFGNN (Li & Zhu, 2021). First, we design two predefined spatial-temporal synchronous graphs as well as , each of which contains two time steps, and the adjacency matrices are denoted as and , respectively. The structure of and is illustrated in Fig. 3A. The main diagonals are and , separately, denoting that each node has connectivity to nodes with the same trend or pattern at the same time step, while the counter-diagonal are and , respectively, indicating that nodes are connected to their neighboring nodes or proximity nodes at the adjacent time step. Then, the two predefined adjacency matrices are multiplied by the learnable parameters of the same shape to obtain the adjacency matrices of the dynamic spatial-temporal synchronous graphs as follows:
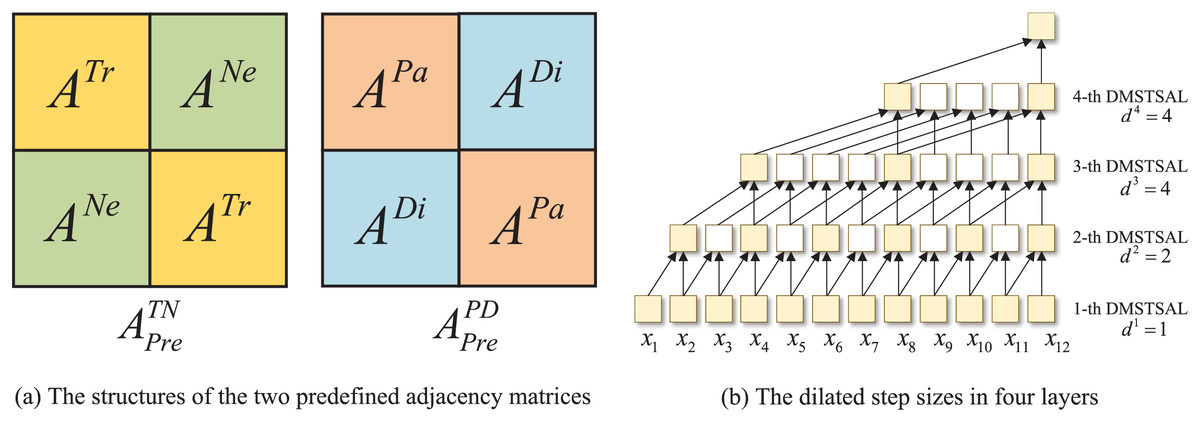
Figure 3: The structures of the two predefined adjacency matrices and the dilated step sizes in four layers.
{kind=link}
(15) where denote the adjacency matrices of and respectively, is element-wise product, are learnable parameters.
Spatial-temporal synchronous aggregation module
Aiming to learn the hidden spatial and temporal correlations synchronously, we build spatial-temporal synchronous aggregation modules corresponding to and , that is, the trend spatial-temporal synchronous aggregation module (T-STSAM) and the pattern spatial-temporal synchronous aggregation module (P-STSAM), which have the same architecture but with different adjacency matrices, as shown in Fig. 2. Multiple gated graph convolutions are stacked in each STSAM to learn spatial-temporal correlations simultaneously, and each gated graph convolution can be formulated as:
(16) where denotes the input, denotes the tanh activation function, denotes the sigmoid activation function, and are learnable parameters. The output of the previous gated graph convolution is used as the input of the next one. In addition, max pooling and a cropping operation are also included in a STSAM.
The gated graph convolution in T-STSAM allows simultaneous aggregation of information from nodes with similar temporal trends and nodes with spatial adjacencies, the mathematical equation can be formulated as:
(17) where denote the input and output of the -th gated graph convolution in T-STSAM, respectively.
The gated graph convolution in P-STSAM implements synchronous modeling of dependencies from nodes with the same temporal pattern and nodes with short spatial distances, and the computational formula is defined as:
(18) where denote the input and output of the -th gated graph convolution in P-STSAM, respectively.
In each STSAM, we take advantage of jump knowledge network (JK-Net) to aggregate the outputs of various gated graph convolutions and then retain the most potent representation by max pooling, which can be described as:
(19) $$\eqalign{ & h_{max}^{TN} = MaxPooling\left( {h_1^{TN},h_2^{TN}, \ldots ,h_M^{TN}} \right), \cr & h_{max}^{PD} = MaxPooling\left( {h_1^{PD},h_2^{PD}, \ldots ,h_M^{PD}} \right), \cr} $$where denote the outputs of max pooling in T-STSAM and P-STSAM, respectively, M denotes the number of gated graph convolutions.
The cropping operation is performed after the max pooling to reduce the hidden features from dimensions to N dimensions, leading to the output of STSAM, which can be expressed as:
(20) where denote the outputs of T-STSAM and P-STSAM, respectively.
Dilated gated convolution module
Regarding time dimension, parallel STSAMs are conducive to extracting short-term dependencies due to their independent parameters while still lacking in modeling long-term correlations. To address this limitation, gated 1D convolution with shared parameters is utilized to extract long-term temporal features, which can be formulated as:
(21) where denotes the output of gated 1D convolution, denotes the input of -th layer, denote two 1D convolution respectively, and are learnable parameters.
Inspired by Graph WaveNet (Wu et al., 2019), dilated instead of fixed step sizes are introduced to and for expanding the receptive fields of 1D convolutions. However, the three-layer convolutions with step sizes of [1,2,4] in Graph WaveNet only cover eight historical time steps, while the length of the input sequences in our model is 12. Therefore, we deploy four layers in which the step sizes of 1D convolutions are set as [1,2,4,4] respectively, while the kernel size of 1D convolution in each layer is fixed as 2, as shown in Fig. 3B. With this set of mechanisms, the receptive field of four-layer 1D convolutions can be expanded to the length of the input time series in our model.
Dynamic multiple-graph spatial-temporal synchronous aggregation layer
T-STSAMs and P-STSAMs with gated fusion, as well as a DGCM, compose a DMSTSAL, four DMSTSALs are stacked in a DMSTSAF, and the output of the previous layer is used as the input to the next layer, which is presented in Fig. 2. In each DMSTSAL, we first slide from the input sequence to obtain the time step pairs, and then construct two kinds of dynamic spatial-temporal synchronous graphs for every time step pair. In order to expand the receptive field and reduce the number of layers, the distances between two time steps in four layers are set to be dilated with the same step sizes as in DGCMs, which are [1,2,4,4], as shown in Fig. 3B.
Denoting the input of the -th DMSTSAL as and the distance of the two time steps as , the time step pairs generated by its sliding in the -th layer can be described as , then the number of time step pairs can be formulated as:
(22)
To achieve simultaneous learning of spatial-temporal dependencies from multiple perspectives, we construct a trend spatial-temporal synchronous graph and a pattern spatial-temporal synchronization graph for each time step pair. The number of each type of dynamic spatial-temporal graph is the same as the number of time step pairs, which can be obtained from (22).
Traffic features are heterogeneous across time, and to capture hidden features more accurately, we design parallel rather than shared STSMs to extract spatial-temporal dependencies. Specifically, a T-STSAM is deployed for each , and a P-STSAM is allocated for each . Thus, T-STSAMs and P-STSAMs are laid out in the -th DMSTSL.
Both T-STSAMs and P-STSAMs are able to represent spatial-temporal correlations in some way, so it is necessary to fuse the outputs of two types of STSAMs. To achieve this goal, we start by aggregating the outputs of each kind of STSAM into a sequence, which can be defined as:
(23) where denote the outputs of T-STSAMs and P-STSAMs, respectively, they represent the results of spatial-temporal synchronous aggregation, which is the core component that forms the prediction of our model. Their elements can be obtained from (20). Then, the gating mechanism is applied to incorporate the outputs of two concatenation operations, which can be formulated as:
(24) where is one of the two parts that compose the output of the current layer, is employed to manipulate the proportion of information in the fusion, whose mathematical equation can be defined as:
(25) where are learnable parameters. Another part of the current layer’s outcome is the result of the DGCM, which can be obtained from (21). The outcome of the fusion operation and the output of the DGCM are added together to form the result of the -th DMSTSAL, which can be formulated as:
(26)
The results of the four DMSTSALs are the inputs to the output module.
Output module
The output module is responsible for generating the final predictions of our model, in which a concatenation that aggregates the outputs of four layers is first employed to capture comprehensive spatial-temporal correlations, which can be defined as:
(27) where can be obtained from (26). A series of fully connected layers are then utilized to produce the final predictions of time steps. Specifically, we design two-fully-connected-layers to produce the prediction of time step , which can be formulated as:
(28) where are learnable parameters. Finally, the results of (28) repeated times compose the final predictions of our model, which can be described as:
(29)
Smooth L1 loss rather than L1 loss is chosen as the loss function, which deals with the unsmooth disadvantage at the zero-point and can be defined as:
(30) where denote the true value and the predicted value, respectively, and denotes a threshold parameter to determine the sensitivity.
Experiments
Datasets
Four public datasets are chosen for evaluating the prediction performance of DMSTSAF: PEMS03, PEMS04, PEMS07, and PEMS08. All datasets are generated by Caltrans Performance Measurement System (PeMS). Concretely, traffic features in these datasets are collected by sensors located on California highways at 5-min intervals, which means there are 12 time steps in an hour. Spatial graphs are constructed from the distribution of sensors. The distinctions among the datasets are the geographic locations of sensors and the temporal ranges of data. The detailed information of four datasets can be found in Table 2.
| Datasets | Samples | Number of nodes | Traffic features | Time span |
|---|---|---|---|---|
| PEMS03 | 26,208 | 358 | Flow | 09/01/2018–11/30/2018 |
| PEMS04 | 16,992 | 307 | Flow, Speed, Occupancy | 01/01/2018–02/28/2018 |
| PEMS07 | 28,224 | 883 | Flow, Speed, Occupancy | 05/01/2017–08/31/2017 |
| PEMS08 | 17,856 | 170 | Flow | 07/01/2016–08/31/2016 |
Experiment settings and evaluation metrics
In our experimental implementation, each dataset is partitioned for training, validation, and testing in a ratio of 60%, 20%, and 20%. We employ the traffic flow of 12 historical time steps (1 h) to predict the traffic flow of 12 future time steps. The traffic flow in each dataset is standardized using Z-score normalization.
DMSTSAF is performed by Pytorch using a PC with NVIDIA RTX 3080. We chose hyperparameters of our model experimentally to ensure superior performance. The sparsity of the adjacency matrices for the distance graph, the trend graph, and the pattern graph are set as 0.01. Each STSAM consists of two graph convolutions, and the output dimension of the fully connected layer in FAW and the hidden dimensions of graph convolutions in STSAM are set as . The hidden representations of two fully-connected layers to generate predictions are tuned as [128,1], respectively. The optimizer in experiments is set as Adam. The batch sizes for four datasets are tuned as [32,32,8,64], respectively. The initial learning rate is set as 0.003 and scaled down to 0.3 times every 30 epochs to shorten the training time. Enroll up to 200 epochs in each training.
We take three metrics to evaluate the performance of models, which are mean absolute error (MAE), mean absolute percentage error (MAPE), and root mean square error (RMSE). Smaller values indicate better performance for these metrics, and their mathematical equation can be formulated as:
(31) where , denote the true value and the predicted value, respectively.
Baseline methods
We compare DMSTSAF with the following seven models for traffic flow prediction:
FC-LSTM (Sutskever, Vinyals & Le, 2014): Long short-term memory network with fully connected layers, a variant of the recurrent neural network, which consists of the forget gate, the input gate, and the output gate.
GRU (Fu, Zhang & Li, 2016): Gate recurrent unit, a variant of LSTM, which simplifies the three gates in LSTM to two, i.e., the reset gate and the update gate.
T-GCN (Zhao et al., 2020): Temporal graph convolutional network, which incorporates GCN with GRU to extract spatial-temporal features.
DCRNN (Li et al., 2018): Diffusion convolution recurrent neural network, in which random walks of a graph are utilized to model spatial dependence, GRU is employed to learn temporal correlation.
STGCN (Yu, Yin & Zhu, 2018): Spatio-temporal graph convolution network, which takes advantage of GCN to extract spatial features, and makes use of 1D convolution rather than recurrent neural network to model temporal dependency.
STSGCN (Song et al., 2020): Spatial-temporal graph convolutional network, which constructs localized spatial-temporal graphs based on spatial and temporal adjacencies, and designs spatial-temporal synchronous graph convolutional modules to learn spatial-temporal correlations synchronously.
STFGNN (Li & Zhu, 2021): Spatial-temporal fusion graph neural network, an improved study based on STSGCN, which designs temporal graphs with dynamic time warping algorithm and proposes spatial-temporal fusion graphs to model localized spatial-temporal dependencies, and then designs gated CNN to extract long-range dependencies.
Experimental results
The experiments of traffic flow prediction are performed on four datasets, and a comparison of the results for all models is shown in Table 3. DMSTSAF obtains the smallest metrics on all four datasets, demonstrating the consistent superiority of DMSTSAF over the baselines. Compared to the state-of-the-art baseline STFGNN, DMSTSAF improves 4.27%, 3.72%, 8.54%, and 7.89% in terms of MAE on PEMS03, PEMS04, PEMS07, and PEMS08 respectively, while the improvements of MAPE are 6.63%, 7.49%, 7.95%, and 7.85%. In addition, our model also achieves 3.68%, 4.23%, 8.38%, and 7.65% improvements in terms of RMSE.
| Datasets | Metric | FC-LSTM | GRU | T-GCN | DCRNN | STGCN | STSGCN | STFGNN | DMSTSAF |
|---|---|---|---|---|---|---|---|---|---|
| PEMS03 | MAE | 27.35 | 27.19 | 20.83 | 21.07 | 20.29 | 18.30 | 17.33 | 16.59 |
| MAPE (%) | 25.16 | 24.92 | 21.58 | 20.43 | 18.98 | 17.58 | 16.90 | 15.78 | |
| RMSE | 42.32 | 42.24 | 31.18 | 33.23 | 33.08 | 30.20 | 29.04 | 27.97 | |
| PEMS04 | MAE | 34.33 | 34.13 | 26.02 | 27.57 | 25.37 | 22.38 | 20.14 | 19.39 |
| MAPE (%) | 21.72 | 21.53 | 17.08 | 18.29 | 15.50 | 15.03 | 13.76 | 12.73 | |
| RMSE | 50.01 | 49.98 | 38.19 | 42.07 | 39.11 | 35.33 | 32.62 | 31.24 | |
| PEMS07 | MAE | 38.33 | 37.79 | 30.37 | 31.29 | 30.91 | 25.15 | 23.76 | 21.73 |
| MAPE (%) | 16.71 | 16.83 | 13.83 | 15.09 | 14.49 | 10.74 | 9.96 | 9.17 | |
| RMSE | 57.56 | 56.72 | 43.39 | 47.21 | 47.12 | 40.79 | 38.48 | 35.25 | |
| PEMS08 | MAE | 28.90 | 28.12 | 21.37 | 21.21 | 21.39 | 17.72 | 16.99 | 15.65 |
| MAPE (%) | 17.77 | 16.92 | 13.66 | 13.08 | 13.13 | 11.61 | 10.96 | 10.10 | |
| RMSE | 41.83 | 41.85 | 30.69 | 31.43 | 31.42 | 27.21 | 26.80 | 24.75 |
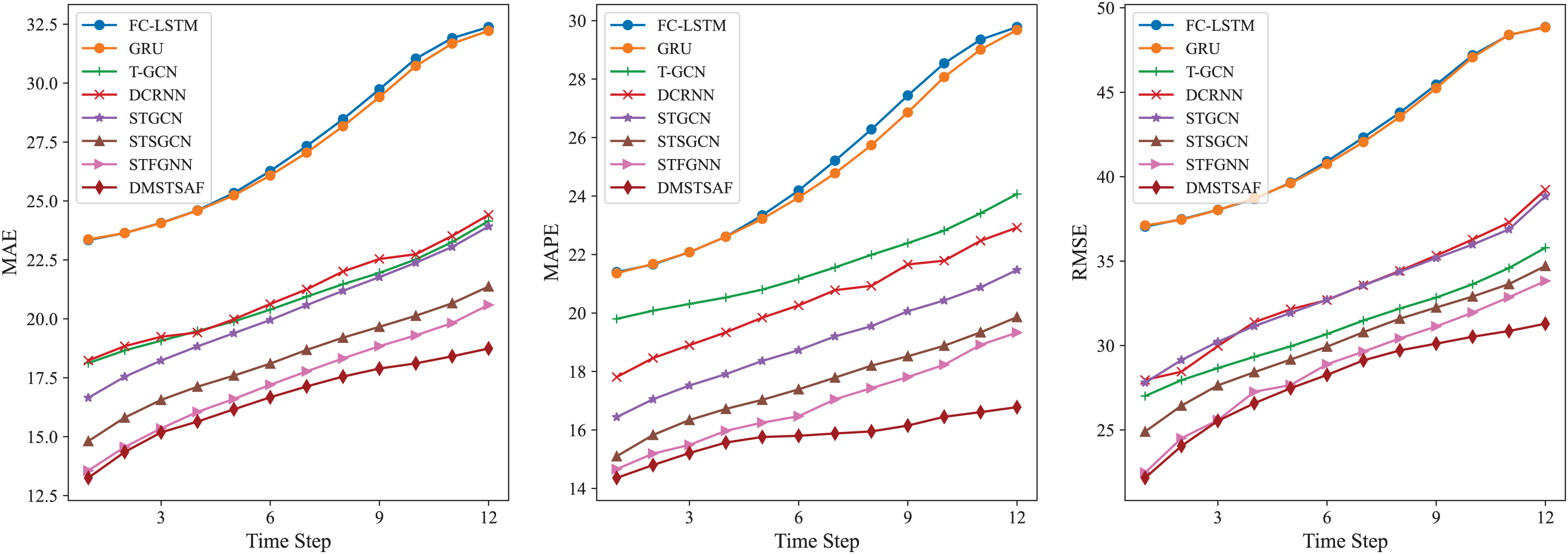
Moreover, for the purpose of evaluating the ability of models on multi-step prediction, we conduct prediction experiments for 12 future time steps on PEMS03. In comparison to STFGNN, our model shows 1.11–8.89% improvement in terms of MAE, 1.81–13.19% improvement for MAPE, and 1.38–7.48% improvement for RMSE. To achieve a more intuitive comparison, we illustrate the results of each model with a line plot, as shown in Fig. 4, which verifies that DMSTSAF overwhelmingly outperforms all the baselines.
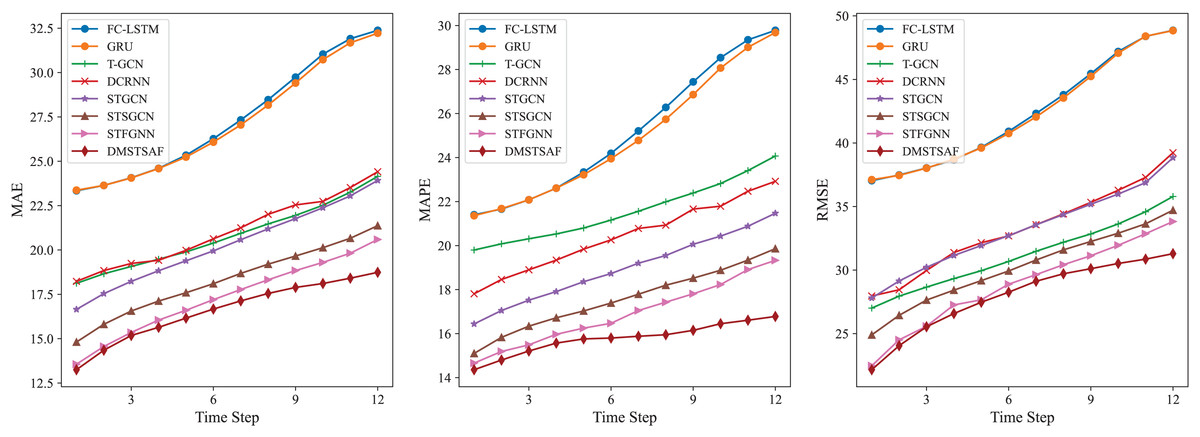
Figure 4: Results of multi-step prediction on PEMS03.
{kind=link}
To further demonstrate the prediction performances of DMSTSAF and the best baselines, we visualize the ground-truth and predictions of STSGCN, STFGNN, and DMSTSAF on PEMS03 test set for both sunny and rainy days, as presented in Fig. 5. It can be seen that compared to the best baselines, our proposed DMSTSAF can fit the ground-truth more accurately in different weather conditions.
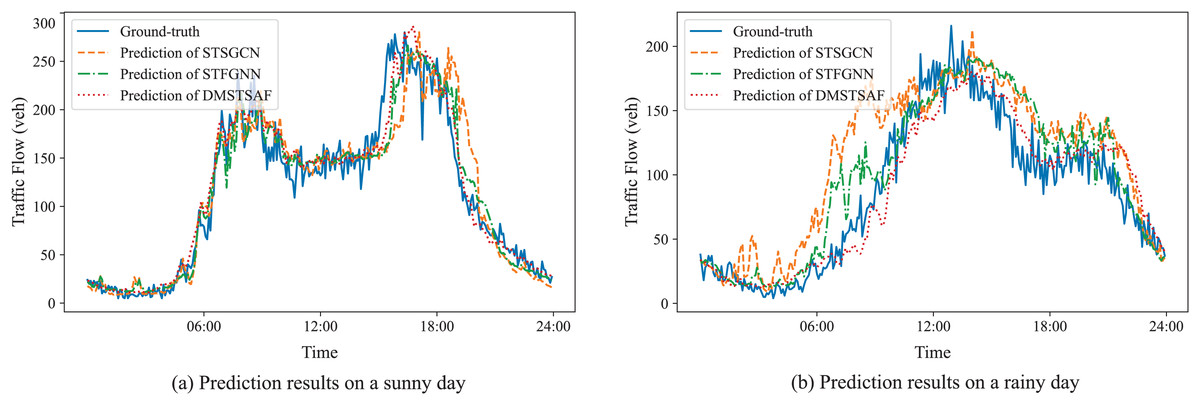
Figure 5: Prediction results of STSGCN, STFGNN, DMSTSAF.
{kind=link}
Ablation study
To evaluate the validity of different modules in DMSTSAF, ablation studies are implemented on PEMS04 and PEMS08. We design six variants, a short illustration is introduced as follows:
-FAW, which uses only traffic features as the input to the model, and utilizes an FC rather than a feature augmentation module to transform the input from C dimensions to D dimensions.
- , which removes trend spatial-temporal synchronous graphs and the corresponding T-STSAM, and retains only pattern spatial-temporal synchronous graphs as well as P-STSAM.
- , which is the opposite of - , removing and P-STSAM, while retaining as well as T-STSAM.
-Dilation, the step sizes of 1D convolutions in DGCM and the distance between two time steps to construct dynamic spatial-temporal synchronous graphs are fixed to 1.
-Concatenation, which removes the concatenation on the outputs of four DMSTSALs, and treats the output of the -th DMSTSAL as the input to the output module.
-DGCM, which removes dilated gated convolution modules from four DMSTSALs.
Table 4 demonstrates the results of ablation studies, which illustrates that DMSTSAF outperforms variants on PEMS04 as well as PEMS08. Compared to the three indicators of -FAW, our model achieves 1.92%, 2.60% as well as 1.67% improvement on PEMS04. Furthermore, it improves by 3.04%, 2.79%, and 1.39% on PEMS08. These improvements indicate the effectiveness of fusing traffic features and external factors in learning spatial-temporal correlations. In contrast with - , DMSTSAF achieves 1.02%, 1.53%, 1.01% improvements on PEMS04, as well as 1.39%, 2.23%, 0.88% improvements on PEMS08. In comparison to - , improvements of 0.6%, 0.94%, 0.54% on PEMS04 are obtained by our model, while improvements of 0.70%, 1.56%, 0.52% are achieved on PEMS08. These achievements verify the validity of dynamic multiple-graph in modeling spatial-temporal dependencies. Compared to -DGCM, our model achieves 1.87%, 2.68%, as well as 2.74% improvement on PEMS04. Furthermore, it improves 2.49%, 4.54%, and 1.67% on PEMS08. These improvements illustrate the positive role of DGCM in capturing long-term correlations. In addition, there are also different levels of improvement in our model compared to other variants, which demonstrates the efficiencies of the corresponding components.
| Model & Variants | PEMS04 | PEMS08 | ||||
|---|---|---|---|---|---|---|
| MAE | MAPE (%) | RMSE | MAE | MAPE (%) | RMSE | |
| DMSTSAF | 19.39 | 12.73 | 31.24 | 15.65 | 10.10 | 24.75 |
| -FAW | 19.77 | 13.07 | 31.77 | 16.14 | 10.39 | 25.10 |
| - | 19.59 | 12.93 | 31.56 | 15.87 | 10.33 | 24.97 |
| - | 19.46 | 12.85 | 31.41 | 15.76 | 10.26 | 24.88 |
| -Dilation | 19.62 | 13.05 | 31.61 | 15.95 | 10.37 | 25.05 |
| -Concatenation | 20.12 | 13.35 | 32.52 | 17.01 | 10.89 | 26.67 |
| -DGCM | 19.76 | 13.08 | 32.12 | 16.05 | 10.58 | 25.17 |
Parameters study
In order to further validate our model, parameters study are implemented on PEMS04 and PEMS08. The number of graph convolutions and the hidden dimensions D in STSAM are under consideration, Fig. 6 presents the results of experiments. Our model achieves minimal errors as each STSAM consists of two graph convolutions. As for the hidden dimensions, it can be found in Fig. 6 that our model obtains optimal metrics when D equals to 64.
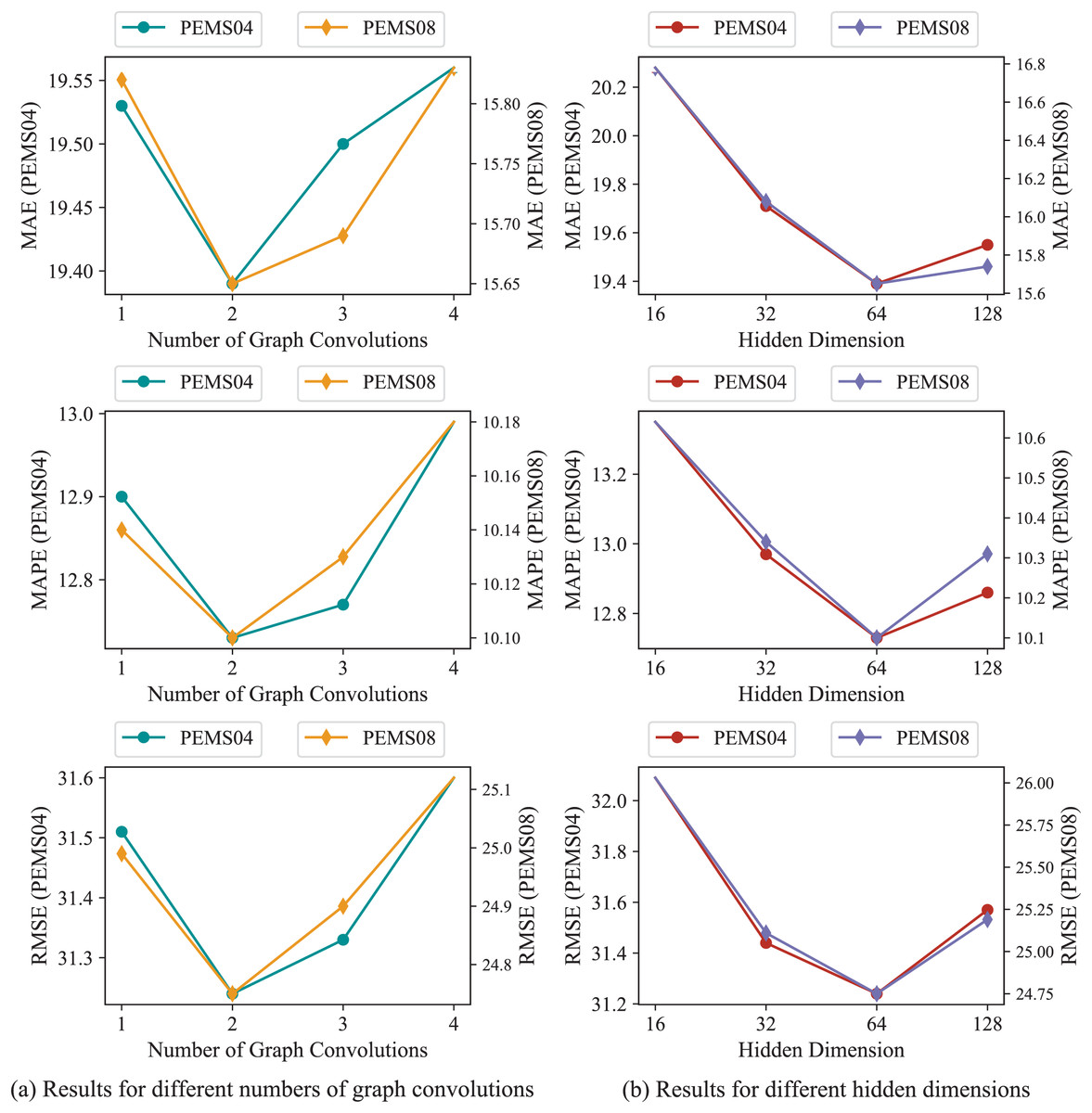
Figure 6: Experimental results of parameters on PEMS04 and PEMS08.
{kind=link}
Discussion
By means of the results in “Experimental Results”, it can be inferred that our proposed model outperforms the seven baselines. FC-LSTM and GRU are not satisfactory since they only take into account temporal dependency and ignore spatial relationships. T-GCN, DCRNN, and STGCN utilize graph convolution network to model spatial dependence and further employ temporal components to extract temporal features, leading to improved performance than models only applicable for time sequences. However, their separate modules for spatial and temporal modeling limit the efficiency of feature extraction. STSGCN designs synchronous graphs to characterize spatial-temporal correlations simultaneously. Further, STFGNN proposes temporal graphs generated by a dynamic time warping algorithm, and then designs spatial-temporal fusion graphs. Although they both achieve synchronous learning compared to previous work, their performances are still insufficient. First, neither of them takes account of the impact of external factors, which weakens the ability of models to extract comprehensive dependencies. Second, their single spatial-temporal graph structures result in overlooking certain potential correlations. Our model integrates maximum temperature, minimum temperature, weather, as well as wind with traffic features by spatial and temporal attention, and then feeds the fused features into subsequent modules. Therefore the influence of external factors is taken into consideration in spatial-temporal modeling. In addition, we introduce four graphs that lead to two dynamic spatial-temporal synchronous graphs, bringing about multi-perspective spatial-temporal simultaneous modeling of hidden features, enhancing the proposed model’s performance for learning spatial and temporal dependencies.
Ablation studies in “Ablation Study” illustrate the effectiveness of various components in our model. FAW is effective for feature extraction because traffic features vary significantly with different external factors. Both and contribute noticeably to the improved performance of DMSTSAF due to their capacity for learning spatial-temporal correlations from different perspectives. Other components are also beneficial to strengthening the model’s performance. Specifically, dilated step sizes expand the receptive fields of stacked layers, the concatenate operation on outputs of four layers retains more useful hidden information, and DGCM captures long-term temporal dependence.
Furthermore, the excellent performance of DMSTSAF benefits from the appropriate number of graph convolutions and the suitable hidden dimensions D in STSAM, which is indicated in “Parameters Study”. When each STSAM comprises only one graph convolution, this leads to the inefficient representation of hidden dimensions, while three or four graph convolutions consisting of one STSAM result in over-smoothing. If we tuned hidden dimensions in STSAM to 16 or 32, the inability to obtain efficient deep representations restricts the capacity to model dependencies, but tuning hidden dimensions to 128 results in over-fitting.
Although diverse experiments confirm the effectiveness of our model, there are still some shortcomings. First, the proposed method cannot efficiently deal with the missing data in datasets. Second, the external factors only include meteorological conditions, and further extensions are yet to be made. In future work, we plan to introduce processing algorithms for missing data and incorporate additional external factors to improve our model further.
Conclusion
In this article, a novel dynamic multiple-graph spatial-temporal synchronous aggregation framework is proposed for traffic prediction, which incorporates traffic features with external factors via spatial-temporal attention as the input, thus modeling the impact of external factors on traffic features. Meanwhile, it characterizes spatial-temporal dependencies from multiple perspectives through two kinds of dynamic spatial-temporal synchronous graphs. In addition, two types of spatial-temporal synchronous aggregation modules empower the model to extract spatial-temporal features synchronously, and the dilated step sizes expand the receptive field. Finally, the many-to-one mechanism in the output module transforms hidden features into accurate predictions. Extensive experiments are implemented on four real-world datasets, and numerical results demonstrate that the proposed model consistently outperforms all baselines, achieving average improvements ranging from 5.99–7.48% on three metrics compared to the state-of-the-art study. In the future, we will attempt to deal with missing data in datasets and take into account additional external factors, such as traffic accidents, to improve our model’s performance further.