
Urban public bicycle dispatching optimization method
- Published
- Accepted
- Received
- Academic Editor
- Xiangjie Kong
- Subject Areas
- Data Mining and Machine Learning, Software Engineering
- Keywords
- Multi-objective optimization, Public bicycle system, Community discovery algorithm, Regional scheduling workload, Elite strategy
- Copyright
- © 2019 Lin et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2019. Urban public bicycle dispatching optimization method. PeerJ Computer Science 5:e224 https://doi.org/10.7717/peerj-cs.224
Abstract
Unreasonable public bicycle dispatching area division seriously affects the operational efficiency of the public bicycle system. To solve this problem, this paper innovatively proposes an improved community discovery algorithm based on multi-objective optimization (CDoMO). The data set is preprocessed into a lease/return relationship, thereby it calculated a similarity matrix, and the community discovery algorithm Fast Unfolding is executed on the matrix to obtain a scheduling scheme. For the results obtained by the algorithm, the workload indicators (scheduled distance, number of sites, and number of scheduling bicycles) should be adjusted to maximize the overall benefits, and the entire process is continuously optimized by a multi-objective optimization algorithm NSGA2. The experimental results show that compared with the clustering algorithm and the community discovery algorithm, the method can shorten the estimated scheduling distance by 20%–50%, and can effectively balance the scheduling workload of each area. The method can provide theoretical support for the public bicycle dispatching department, and improve the efficiency of public bicycle dispatching system.
Introduction
With the progress of urbanization, people’s awareness of low carbon life and health is increasing. The public bicycle system can provide a green and healthy way to travel, and gradually become an important part of the public transport system. However, the study of the division of public bicycle dispatching area is still in the primary stage. The division of the public bicycle scheduling area has two purposes: decomposing the scheduling between large-scale sites, and reducing the computational complexity of path planning.
At present, the mainstream regional division method is based on the urban administrative area, and each area is an independent scheduling area. However, the boundaries of residents’ travel are not as clear as the administrative areas. With the development of the city, the links between the areas are more closely related, so the division based on urban administrative areas is lack of scientific basis. Tulabandhula & Bodas (2018) proposed a passenger monitoring system for dispatching vehicles in a public transportation network, it monitors passengers at the station, vehicle scheduling information and processed hardware equipment. Because the size and population density of each administrative area are different, the number of sites in each area varies greatly. Pan, Jun-Yi & Min (2015) designed a heuristic simulated annealing hybrid search algorithm for large-scale VRP distributed problems. Firstly, based on the actual road network of GIS, the mathematical model is established. Secondly, the large-scale VRP path planning problem is studied. The administrative area is large in size and concentrated in population. Forma, Raviv & Tzur (2015) considers the spatial nature of public bicycle rentals, and the original inventory factor of bicycles. Then the paper establishes a regional maximum diameter distance constraint model. Finally, the best classification results are obtained by heuristic algorithms to minimize the overall inventory cost. Therefore, there are more sites, public bicycle turnover is high, and dispatching workload is large; but if there are fewer sites, public bicycle turnover is low, and dispatching workload is small. Above all, lack of a scientific planning method often leads to higher scheduling capital costs. Schuijbroek, Hampshire & Hoeve (2016) applied the maximum algebra algorithm to the division of the public bicycle scheduling area, and the paper established the corresponding partition mathematical model. The goal of zoning is to minimize the maximum completion time based on a reasonable level of service.
Aiming at the problems, this paper proposes an improved community discovery algorithm based on multi-objective optimization. By using this innovative algorithm, the results show that the algorithm brings three major benefits: it can effectively shorten the public bicycle scheduling distance, improve the scheduling efficiency, and effectively balance the workload of regional scheduling.
Related Work
The division of the public bicycle dispatching area involves operational research, and researchers have made significant contribution. Public bicycles and buses, as well as cargo transport vehicles are public transport, and their operations have similarities. Therefore, they can learn dispatching methods from each other. Kloimllner (Miranda-Bront et al., 2017) decomposes the problem of public bicycles into two sub-problems: scheduling area partitioning and scheduling path planning. Then create an integer programming model to achieve as few bicycle rental points as possible.
In addition, other researchers chose to use clustering algorithms. Phanikrishnakishore & Madamsetti (2014) used the rental rules between public bicycle stations, the space of public bicycle stations, and the non-spatial attributes of public bicycle stations, as well as the self-flow characteristics, using association rules to classify sites with strong correlation into the same category. Finally, various types of site space enclosed areas serve as the scheduling area for public bicycles. Zhang, Liang & Wei (2017) proposed a public bicycle scheduling area division scheme based on the improved K-means clustering algorithm. In the data analysis, the algorithm effectively estimates the k central sites at the initial central site. After the K-means clustering algorithm is divided, the edge sites are clustered and adjusted again according to the scheduling requirements. Xu, Qin & Ma (2017) integrates the spatial relationship between the sites, and the lease relationship of the bicycle, establishes the similarity matrix of the site, and proposes the parameters of the regional coupling, quantifies the degree of connection between the regions, and finally uses the clustering algorithm to obtain the corresponding result. Long, Szeto & Huang (2014) established a dynamic regional scheduling model, for large-scale public bicycle scheduling problems, and proposed a multi-stage re-optimized dynamic clustering algorithm, integrates optimal division, task balance between regions and regions. Within the balance of demand, three factors are progressively clustered, and in the process of solving, the abnormal sites are continuously split to gradually improve the clustering results. Dziauddin, Powe & Alvanides (2015) has studied the public bicycle dispatching area, found that there are often abnormal sites in the division, and he proposed a K-Center algorithm, adaptively limits the capacity of the rental site. Hartmann Tolić, Martinović & Crnjac Milić (2018) analyzed the spatial attributes and community structure of public bicycles, and the paper used the community discovery algorithm to analyze the community structure of public bicycles in Washington, London and Boston, and verified the existence of community structure in the public bicycle network.
The main method of scheduling area division is model method (Dubey & Borkar, 2015) and clustering algorithm (Sun, Zhang & Du, 2015). The model method requires abstract research, and there are many constraints and it is not easy to solve. Clustering algorithm is very difficult to determine the number of clusters, and it is difficult to evaluate. Moreover, the scheduling workload has no evaluation criteria, and it does not consider whether the workload is balanced. Therefore, this paper proposes a new method to solve the problem.
Scheduling Area Division Model Design
This part establishes the division model of public bicycle scheduling area, including the description of the model, and the assumptions of some conditions, and some interpretations of the parameters. Finally, this chapter will propose a lease/return point demand forecasting model, the data obtained from this model can help this paper verify whether CDoMO’s estimated total dispatch distance is the shortest.
Problem description
At present, the clustering algorithm is mainly used to solve the problem of scheduling area division. The data set abbreviated to DS is preprocessed using a data preprocessing program. Turn a data set into a lease/return relationship abbreviated to LRR between sites. Then, through the similarity calculation between the sites, the similarity matrix abbreviated to SM is generated (Yanping, Decai & Duoning, 2017). Conversion from DS to SM, as shown in Eq. (3.1), where Rij represents the similarity between site i and site j, Qij represents the number of bicycles rented from the site i and returned to the site j, Qji represents the number of bicycles rented from the site j and returned to the site i. (3.1)
The conversion process represented by c1 and c2 is as follows: Eqs. (3.2), (3.3), M represents the time range, which is based on the number of days: (3.2) (3.3) (3.4)
Finally, the clustering algorithm abbreviated to CA is used for dividing, Rn stands for dividing into n independent scheduling areas is shown in Eq. (3.4). If the division result abbreviated to DR conforms to the lease/return law abbreviated to LRL, the user can actively complete a part of the scheduling work to reduce the scheduling workload. However, in the actual scheduling area division, in order to obtain the highest comprehensive benefits, the regional division should not only conform to the law, but also achieve the balance of scheduling workload as much as possible (Shpak et al., 2017). The regional scheduling workload is mainly determined by the distance within the area and the number of stations in the area. Z1 and Z2 should be as small as possible if the regional workload is balanced. This balance problem can be transformed into a multi-objective optimization problem. The objective function f is shown in Eq. (3.5): (3.5) Z1: Variance of the dispatch distance Z2: variance of the number of sites
MOO: Multi-objective optimization
Calculation of Z1 in the following Eq. (3.6), n represents the number of areas, Di represents the estimated dispatch distance of area i, and represents the average of the estimated dispatch distances: (3.6)
Calculation of Z2 in the following Eq. (3.7), n represents the number of areas, Ni represents the number of internal sites in area i, and represents the average number of internal sites: (3.7) (3.8)
Equation (3.8) indicates that each site must be divided into an area. Si and Sj represent the partition set. P represents the parking lot sites collection: (3.9)
Equation (3.9) indicates that a site can only be divided into an area: (3.10)
Equation (3.10) indicates that each scheduling area contains at least one dispatch center. There are two optimization goals for this issue:
-
Minimize the variance between the estimated dispatch distance between each area;
-
Minimize the variance between the numbers of sites in each area.
Model assumptions and parameter description
The scheduling area dividing process is complicated, and the abstract model involves many parameters. In order to make the model as close as possible to the actual division, before the model is established, some assumptions about the scheduling area dividing process are assumed:
-
The scheduling distance of each area can be estimated theoretically, the estimated scheduling distance is approximately equal to the actual scheduling distance;
-
Dispatching vehicles are not limited by driving time and mileage;
-
Only one dispatching vehicle in each area is responsible for bicycle dispatch;
-
Model of the dispatching vehicle is consistent with all parameters;
-
The dispatching vehicle departs from the dispatching center, completes the dispatching task, and then returns to the original dispatching center, regardless of vehicle failure, and other unexpected factors.
Based on the problem description and model assumptions, the parameters and variables of the model in Table 1 are defined.
| Parameters/variables | Parameter/variable meaning |
|---|---|
| n | The number of areas |
| i, j | Area number |
| Di | The estimated scheduling distance of the area i |
| Dj | The estimated scheduling distance of the area j |
| Regional estimated dispatch distance average | |
| Ni | The number of sites in area i |
| Nj | The number of sites in area j |
| Average number of sites within the area | |
| S | Collection of sites |
| Si | Site division set for area i |
| Sj | Site division set for area j |
| P | parking lot site collection |
| Weather | Value |
|---|---|
| Heavy snow, heavy rain | 1 |
| Snow, light snow, moderate rain, light rain | 0.75 |
| Foggy | 0.5 |
| Sunny and cloudy | 0.25 |
Leasing demand forecasting model
After the scheduling area is divided, in order to calculate the estimated total distance of the scheduling, it is necessary to ensure that the demand for the lease/return site is known, so it is necessary to predict the scheduling demand for the lease/return site in the future. This section will be divided into 24-time periods in hours per day named t, . A Meteorology Similarity Weighted K-Nearest-Neighbour (MSWK) method is introduced to predict the number of least and returned bicycle at the site.
Leasing number forecast model
MSWK is an improved method for predicting lease/return bicycle quantity based on KNN algorithm. Analysed the amount of leasing in a similar time period to predict future leasing. Weather, temperature, humidity, winds speed, and visibility are measured in five indicators.
In the measurement of the similarity of weather, the weather is split into five levels and assigned corresponding values. The exact values are shown in Table 2.
The quantified weather conditions at p and q for two days t is denoted by and , respectively, and the weather similarities for t in p and q are defined as follows (Eq. (3.11)): (3.11)
The temperatures of the p and q two days t periods are denoted by and . The temperature similarities of the t time periods in p and q are defined as follows (Eq. (3.12)): (3.12)
The three dimensions of humidity, wind speed, and visibility are represented by a 3-D Gaussian kernel function, and represents the humidity, wind speed, and visibility of the t time period in p, respectively. The humidity, wind speed, and visibility similarity of p and q periods in t are defined as follows (Eq. (3.13)): (3.13)
In order to simplify the calculation, the temperature, humidity, wind speed, and visibility are normalized and all σ1, σ2, σ3, σ4, σ5 are set to 1, thereby simplifying the calculation; finally, by weighting the above three similarity indexes, p and q can be obtained. The overall similarity indicator at time t as follows (Eq. (3.14)): (3.14)
Where is a judgment function, when both p and q are working days or all non-working days, , otherwise . If you want to predict the amount of rent in the t time period in q, select the most similar K days and use the MSWK algorithm to calculate the predicted value. The specific Eq. (3.15) is as follows: (3.15)
Returning number forecast model
After a user rents a bicycle, they often return the bicycle to an adjacent site within a certain period of time. Therefore, there is a need for prediction data of the number of bicycles based on neighbouring sites, which is used to predict the number of bicycles returned to the site. Bicycles rented from site i during time t may be returned to site j adjacent to i during time t or t+1. For the forecast of the number of return bicycles within the lease time t period, it is necessary to first estimate the number of bicycles rented from the site i and at the site j within the time period t. The specific Eq. (3.16) is as follows: (3.16)
Among them, is the predicted value of bicycle rental quantity from site i in time period t, eij⋅f is historical record of bicycle rental from site i and is still at site j. si⋅pd is historical total bicycle rental record from site i. Through the analysis of historical data, it is found that the user’s riding time law can be fitted by the 2-Gaussian function. Therefore, the riding time between rental sites i and j can be estimated by Eq. (3.17): (3.17)
Assume that the user’s return time is evenly distributed, and the user’s behaviour of returning the leased bicycle is completed within the t time period or t+1-time period. During the time periods t and t+1, the user t1 rents a bicycle from the site i at the moment, and the probability of returning the ticket at the site j at t2 is as follows (Eqs. (3.18) and (3.19)): (3.18) (3.19)
Finally, considering the traffic patterns and the corresponding probabilities of the adjacent sites, the formula for predicting the number of return bicycles within the sites is obtained as follows: (3.20)
So far, the demand ΔN of the site i at the time t in the future will be calculated by combining the demand for rental and return of the rental site i at the time t in the future. The specific formula is as follows: (3.21)
If ΔN is less than zero, it means that the site i will not be able to meet the user’s bicycle rental demand at the time t in the future, and it is necessary to dispatch the bicycle through dispatch (Feng, Zhu & Liu, 2018). If ΔN is greater than the number of parking spots at the leased site, it means that the site i at the time t in the future cannot satisfy the user’s demand for returning the car. It is necessary to reduce the number of bicycles by scheduling.
Community Discovery Algorithm Based on Multi-Objective Optimization
Community discovery algorithm based on multi-objective optimization, which combines quantitative indicators of regional scheduling workloads, community discovery algorithms (Shivach, Nautiyal & Ram, 2018), and multi-objective optimization algorithms (Mori & Saito, 2016). Firstly, the Fast Unfolding community discovery algorithm (Sun et al., 2018) is performed based on the similarity matrix of the site. Secondly, the workload adjusts the results of the community discovery algorithm. Throughout the process, the results are continuously optimized through a multi-objective optimization algorithm.
CDoMO scheduling workload analysis
Scheduling workload is an indicator to measure the workload of a dispatch line. The scheduling itself involves many fields, so there is no uniform standard (Kim, Jeong & Lee, 2017). The generalized scheduling workload is mainly determined by the scheduling distance, the delivery volume and the number of service outlets. The three parameters are weighted and integrated, and the workload of the dispatching line can be quantified. Suppose W is the generalized scheduling workload, D is the driving distance (km), N is the number of outlets (pieces), S is the delivery amount (pieces), and ρ1, ρ2, ρ3 is the driving distance weight, the delivery amount weight, and the service outlet quantity weight as follows Eq. (4.1): (4.1)
This paper combines generalized scheduling workload with public bicycles, and then obtains a quantitative formula for regional scheduling workload, Wi is the scheduling workload of area i, and Di is the scheduling distance of area i, which is calculated by the maximum generation star algorithm. Ni is the number of stations in area i, Si is the number of stations in area i, and ρ1, ρ2, ρ3 is the corresponding weight coefficient as follows Eq. (4.2): (4.2)
Since the regional scheduling is based on all stations in the entire area, and in the scheduling area division stage, the waiting scheduling sites and scheduling quantities of each area are unknown, so in this paper, the impact of Si on the scheduling workload is ignored, that is, let ρ3 = 0. So, the Eq. (4.3) can be simplified to: (4.3)
In the quantitative formula of scheduling workload, the weight coefficient cannot be determined manually, but when the scheduling workload balance is satisfied, the estimated scheduling distance variance in each area, and the variance of the number of stations in each area should be as small as possible, so the scheduling balance the problem can be turned into a multi-objective optimization problem. The objective function is . NSGA2 is the most popular multi-objective genetic algorithm. NSGA2 first genetically manipulates the population P to obtain the population Q; then the populations are combined and then combined with non-inferior sorting and crowding distance sorting, and then a new population is established. Repeat the above process, until the termination condition is met. The detailed process is as follows:
-
Randomly generate the initial population P 0, then sort the populations non-inferiorly, and assign a non-dominant value to each individual; then perform the operations of selection, crossover, and mutation on the initial population P 0 to obtain a new population Q 0, set to i = 0.
-
Combine the populations of the father and offspring, then form a new population Ri = Pi∪Qi, and then sort the population Ri non-inferiorly to obtain the non-inferior layer F1, F2, ⋯.
-
Perform replication, crossover, and mutation operators on population Pi+1 to form population Qi+1.
-
If the termination condition holds, then it ends; otherwise, i = i+1, go to step (2).
The main process diagram of NSGA2 is shown in Fig. 1:
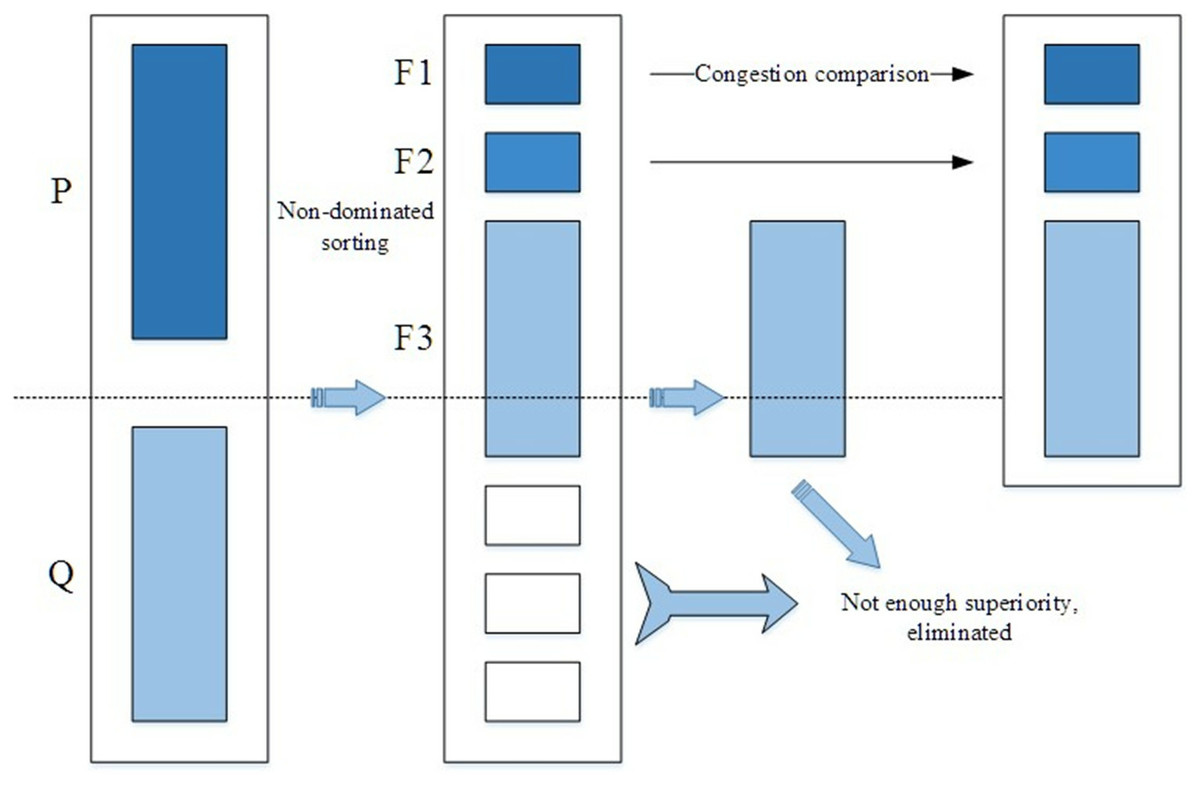
Figure 1: The main process of NSGA2 algorithm.
{kind=link}
This paper uses the NSGA2 multi-objective optimization algorithm to resolve the scheduling area partition model (Wu, 2014). The length of the chromosome in NSGA2 is 2 (Basch et al., 2015), which corresponds to the value of the weight parameter in the area scheduling workload. Each individual corresponds to a scheduling workload formula, based on schedule the workload adjustment community found the results of the division. Figure 2 shows the restricted flow of NSGA2 algorithm.
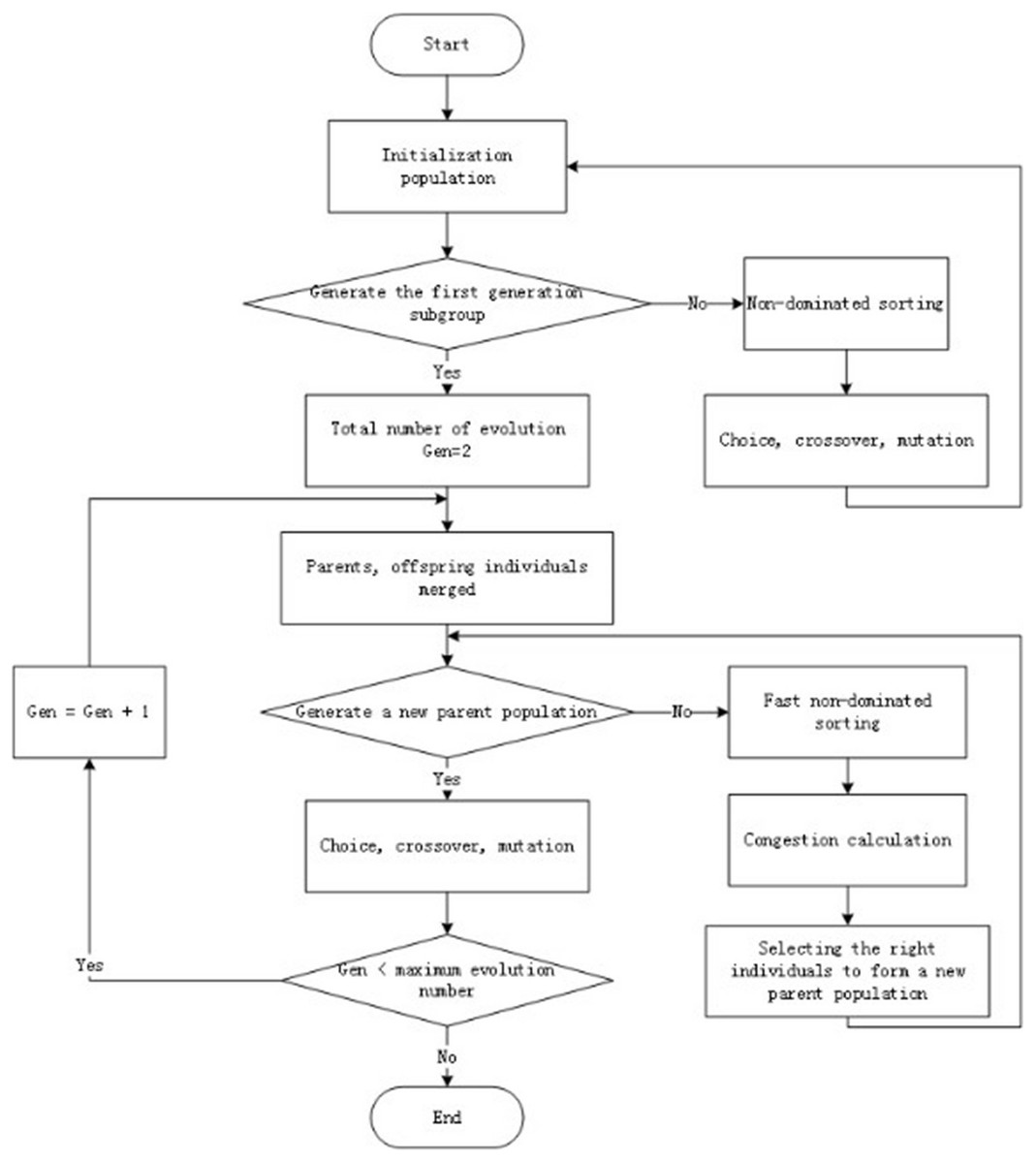
Figure 2: Specific flow of NSGA2 algorithm.
{kind=link}
CDoMO algorithm design
Community discovery algorithm built on multi-objective integrates quantitative indicators of regional scheduling workloads, community discovery algorithms and multi-objective optimization algorithms. Firstly, the Fast Unfolding community discovery algorithm is implemented based on the similarity matrix of the least sites; secondly, the workload index is used to adjust the results of the community discovery algorithm. The entire process continuously optimizes the results from a multi-objective optimization algorithm.
Table 3 displays the detailed algorithm calculation.
Experiment and Analysis
The rest of the paper is part of the experiment and analysis. The experimental section was divided into two groups, which were experiments using New York public bicycle data and Chicago public bicycle data. In the analysis section, the two groups of experiments use K-means clustering algorithm, and Fast Unfolding community discovery algorithm as comparisons, it compares the three aspects of the number of rental sites, the variance of the number of scheduled bicycles, and the estimated total distance of scheduling. The comparative data show that the algorithm is effective against both sets of experiments.
New York public bicycle
Data set introduction
Citi Bikes (Jiang et al., 2018) is a people-benefit project launched by the New York City Government. Figure 3 displays the spatial distribution of rental sites. Blue represents Manhattan, with 250 rental sites; green represents Brooklyn, with 77 sites. Each Citi Bicycle rental site has GPS location information, so it is not difficult to locate the rental site. The system records the user’s data onto each cycle. The package contains the location and time data onto the start and the end of the site, the entire riding process, the bicycle ID, and the user’s gender and birth date. This experiment will use the May 2016 rent-return dataset of New York public bicycles to conduct an experiment, a total of 96, and 1986 rent-return data. The dataset contains 16 fields, and the nine fields related to this experiment are shown in Table 4.
| Algorithm: | Community discovery algorithm based on multi-objective optimization |
|---|---|
| Input: | Site similarity matrix X, population number popsize, maximum number of iterations MaxGen. |
| Output: | Optimal regional division results and workload index parameters . |
| 1. | Initialize the historical optimal solution f∗ and its workload index parameter . |
| 2. | Perform a pass phrase of the Fast Unfolding community discovery algorithm, and obtain the results of the preliminary zoning division as R. |
| 3. | Calculate the estimated distance Di of each area in R, number of regional sites Ni. |
| 4. | Individual genes in the population as weight coefficients ρ1, ρ2. Finally, the scheduling workload of each area is calculated by the formula Wi = ρ1⋅Di + ρ2⋅Ni. The variance of the regional workload is denoted as V. |
| 5. | For each rental site i, try to put i into other communities and calculate the incremental ΔV of the adjustment workload, the entire process records the maximum ΔVmax and the corresponding community k. If ΔVmax< 0, site node i does not adjust; if ΔVmax >0, node i is adjusted to community k. Traverse all the site until all the site are adjusted and the result is recorded as R∗. |
| 6. | Define the variance function f1 of the regional site, and define the regional dispatch distance variance function f2, they are two objective functions to perform fast non-dominated sorting on the results, the records of the optimal solution in the contemporary population as f′, and its corresponding scheduling workload parameters are denoted as If f′ > f∗ after comparison, letting . |
| 7. | Determine whether the number of program iterations exceeds the maximum number of iterations MaxGen. If it exceeds, the optimal regional division results, and workload index parameters are output; otherwise, a new population is generated through elite strategy selection, which can ensure that certain elite individuals will not be discarded during the evolution process, thereby improving the accuracy of the optimization results, and expanding the sampling space. And gene crossover and mutation processes and the execution continue from 1. |
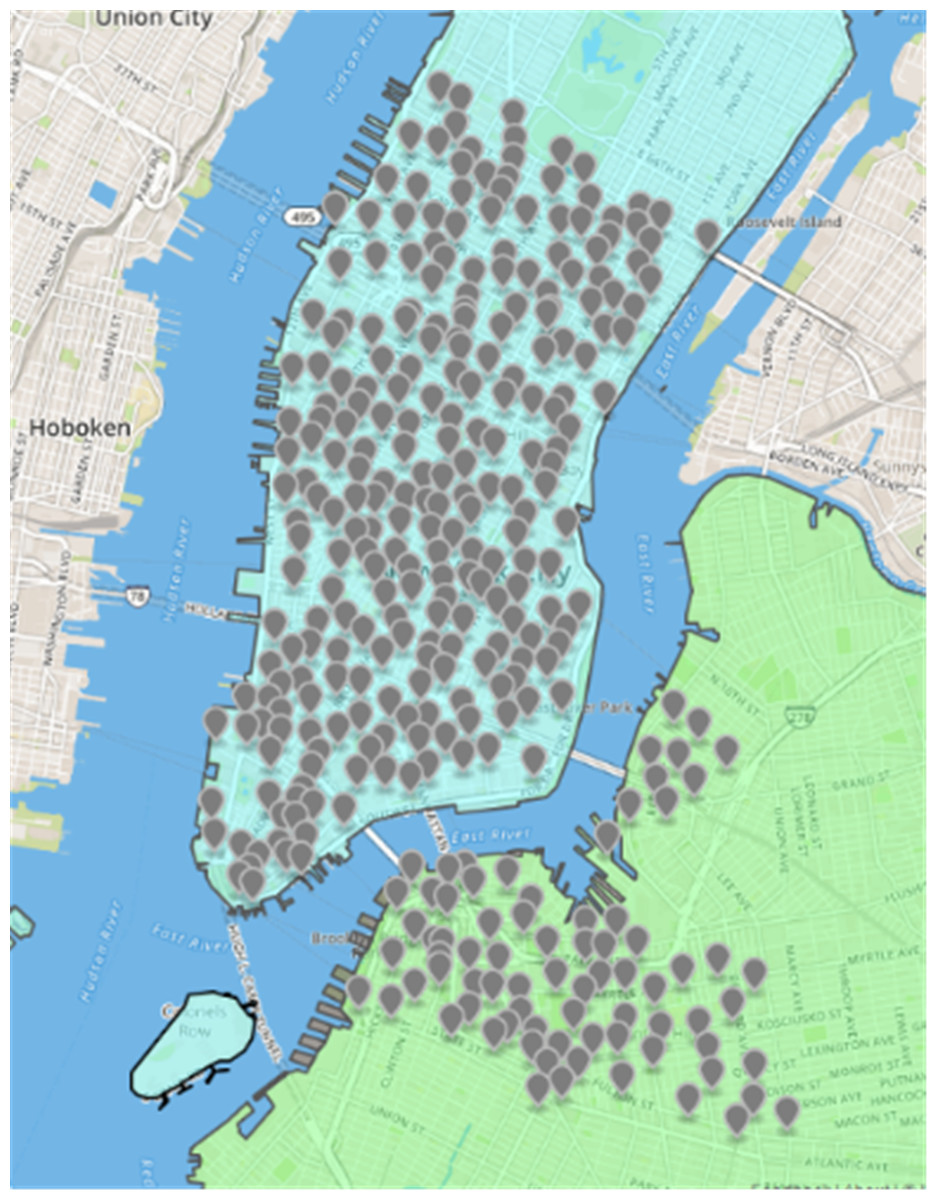
Figure 3: Spatial distribution map of public bicycles in New York.
{kind=link}
This paper uses the pre-processing program to process the leased data, it turned into the lease-return relationship between the least sites (Guo et al., 2017). It also generates a similarity matrix based on the rent-return relationship. The similarity calculation formula for the least sites is as follows (Eq. (4.4)): (4.4)
Among them, Rij represents the similarity between site i and site j; Qij represents the number of times to rent a bicycle from site i and site j to return the bicycle; Qji represents the number of times of renting a bicycle from site i and returning it at site j; M represents the time range in days. In this experiment, the data set was a total of 31 days in May 2016, so M = 31.The corresponding abstract network can be generated through the lease-return relationship (Fig. 4). Due to the dense population, dense sites, and prosperous business, the sites in Manhattan are more closely linked, and Brooklyn is a river is separated from Manhattan, so the connection between the two regional sites is sparse except for the leases along the river.
| No. | Fields | Meaning |
|---|---|---|
| 1 | start time | Starting time |
| 2 | stop time | End Time |
| 3 | start_station_id | Bicycle rental site ID |
| 4 | start_station_name | Name of bicycle rental site |
| 4 | start_station_longitude | Longitude of rental bicycle rental site |
| 5 | start_station_latitude | Latitude of rental bicycle rental |
| 6 | end_station_id | Return bicycle rental ID |
| 7 | end_station_name | The name of the bicycle rental site |
| 8 | end_station_longitude | The longitude of the bicycle rental site |
| 9 | end_station_latitude | The longitude of the bicycle rental site |
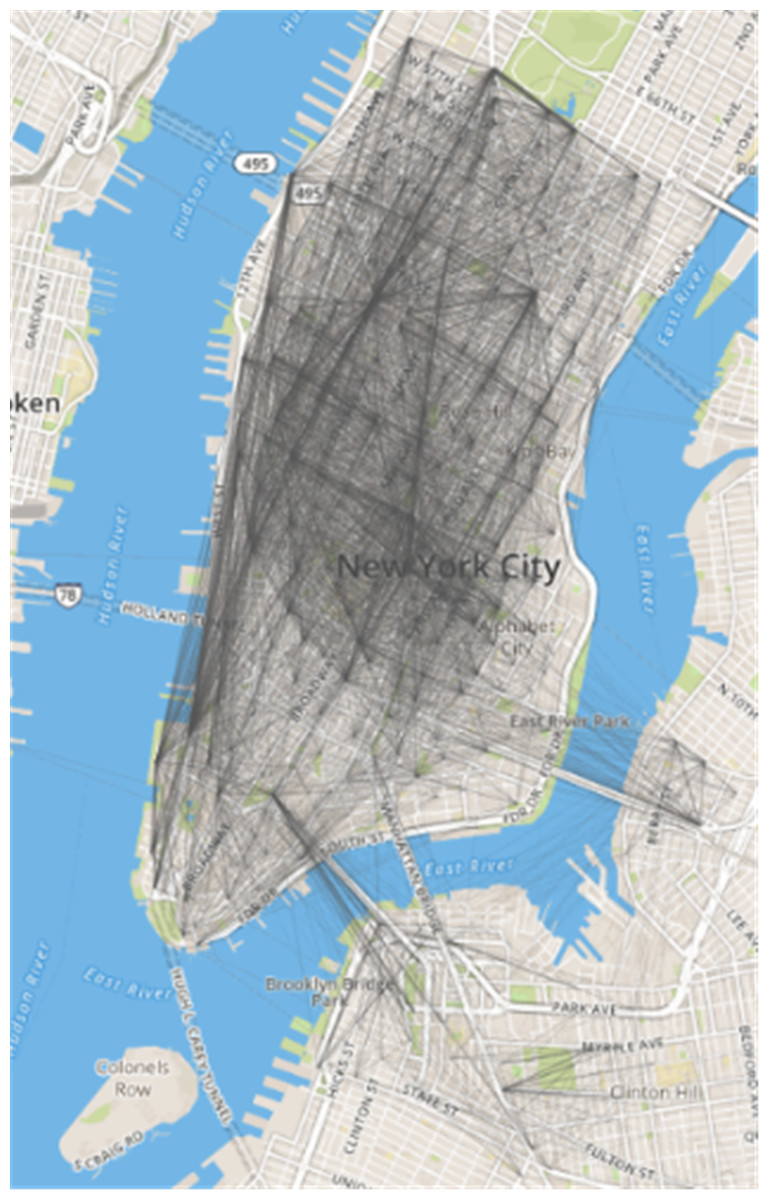
Figure 4: Abstract network of public bicycles in New York City.
{kind=link}
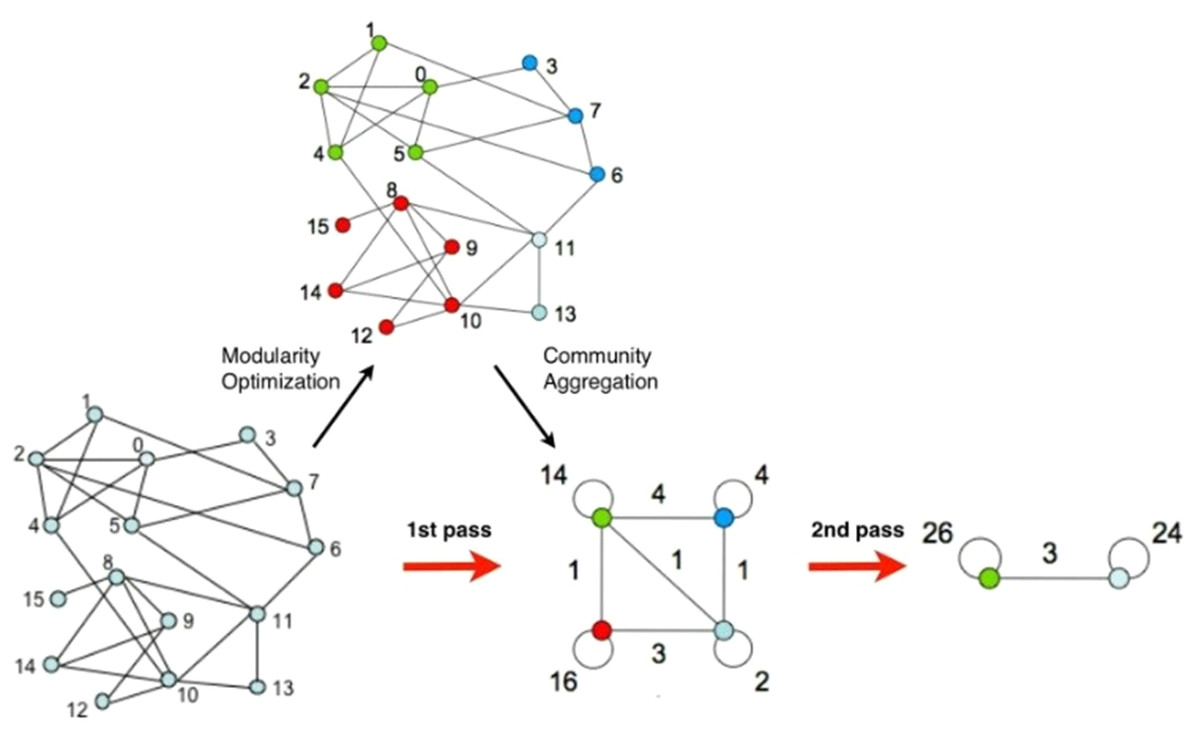
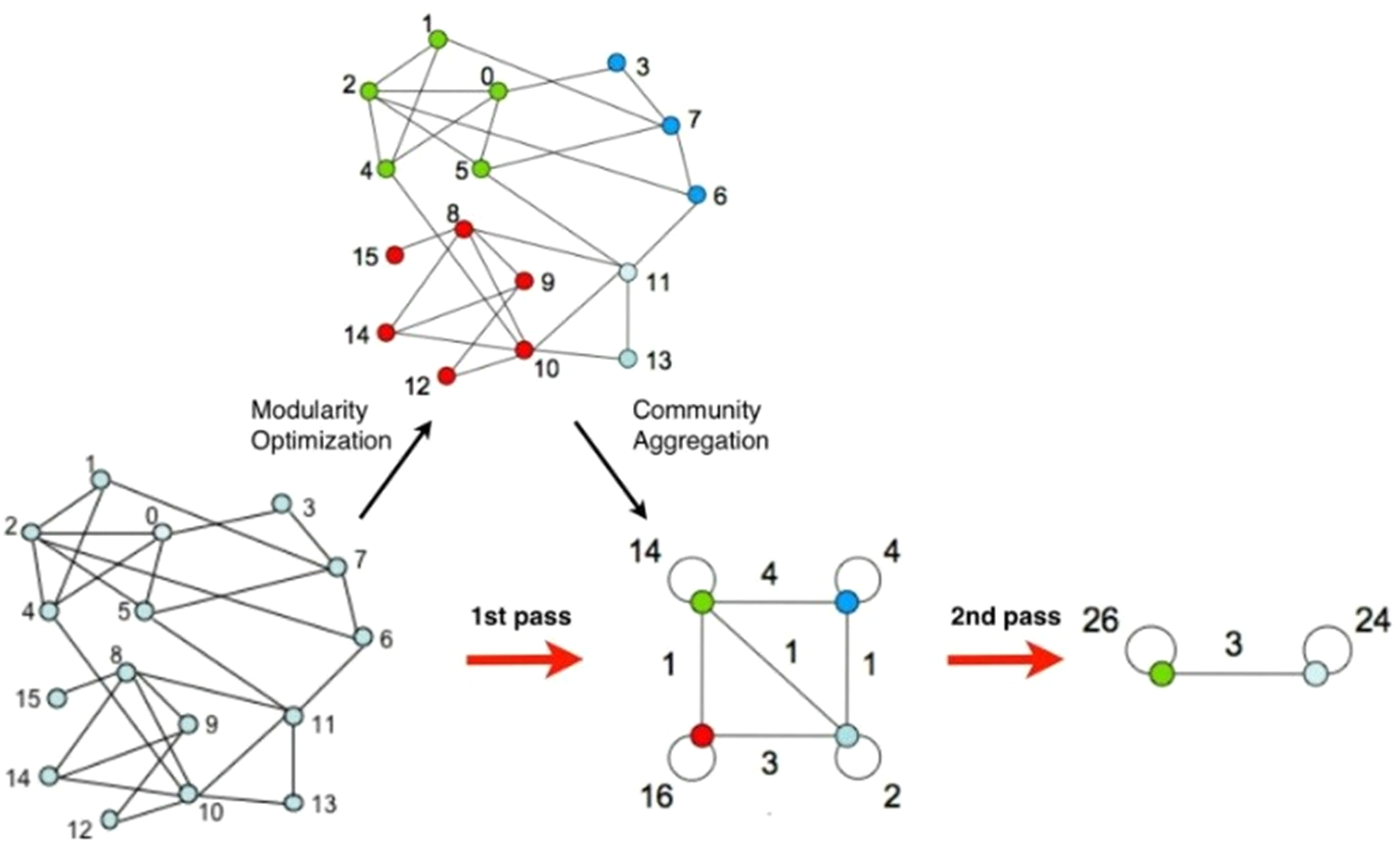
Figure 5: Schematic diagram of community discovery algorithm.
{kind=link}

Figure 6: Schematic diagram of analysis results of the Gephi Visual Network Analysis platform.
{kind=link}
Experimental result
In the experiment, we first used the Gephi visualization network analysis platform to analyse the community structure in the data (Hu, An & Wang, 2018). The Gephi platform uses the integrated Fast Unfolding algorithm, it divides the public bicycle abstraction network according to the rules of public bicycle rental. The Fast Unfolding algorithm mainly includes two phases. The first phase is known as Modularity Optimization. The main part is to divide each node into the community, its neighbourhood nodes are located, so that the value of the module degree becomes larger; the second phase is called community. Aggregation is mainly to aggregate the communities divided in the first step into one site, that is, to rebuild the network based on the community structure generated in the previous step. Repeat the above process, until the structure of the network no longer changes (Fig. 5).
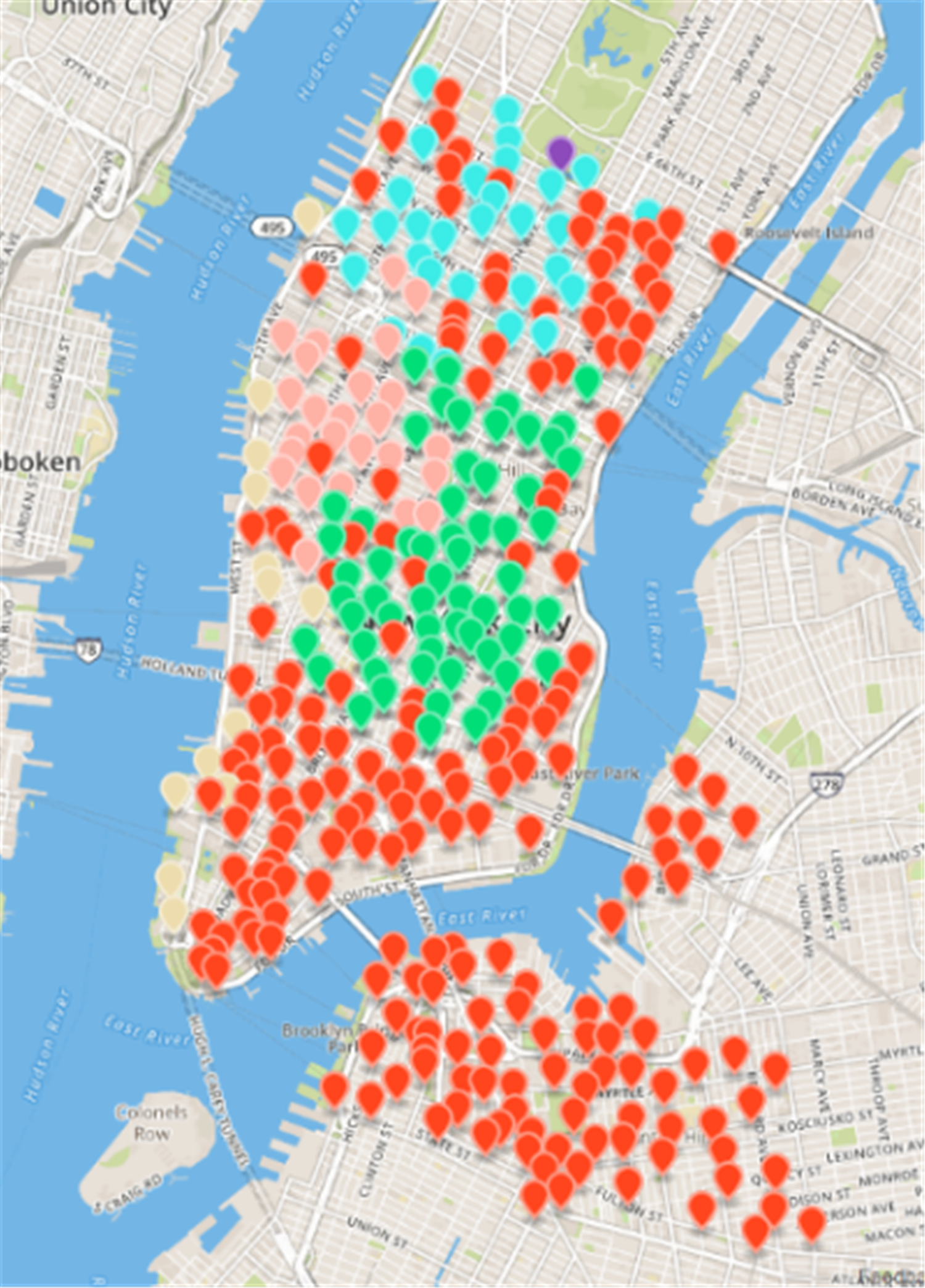
After the Fast Unfolding algorithm for the New York public bicycle rental site in this paper, Fig. 6 shows the internal community structure of the abstract network of New York’s public bicycles, where the dots represent sites, where the sites of different communities are represented by different colours, and the lines represent the relationships between the sites; obviously, six communities have more close contact with leases within the same community, and the links between different societies are relatively sparse. The results of the Fast Unfolding community discovery algorithm are mapped to map on New York (Fig. 7). Manhattan is a densely populated administrative district, and the vast majority of public bicycles in the area ride on the inside, so the Manhattan District is divided into five areas according to the law of rent. Brooklyn is structured in a district. Although the division results are relatively reasonable, there are still many abnormal sites. These abnormal sites are far away from their respective areas; the number of sites of each area is uniform.
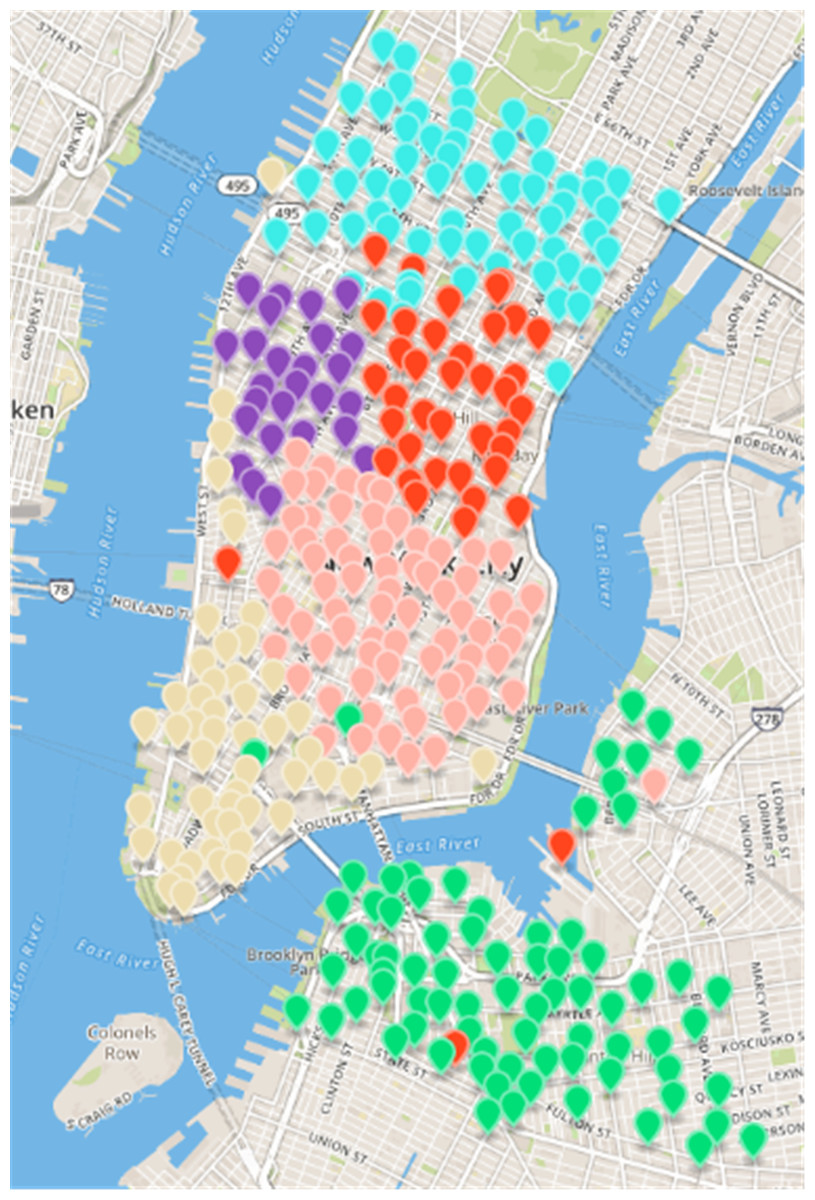
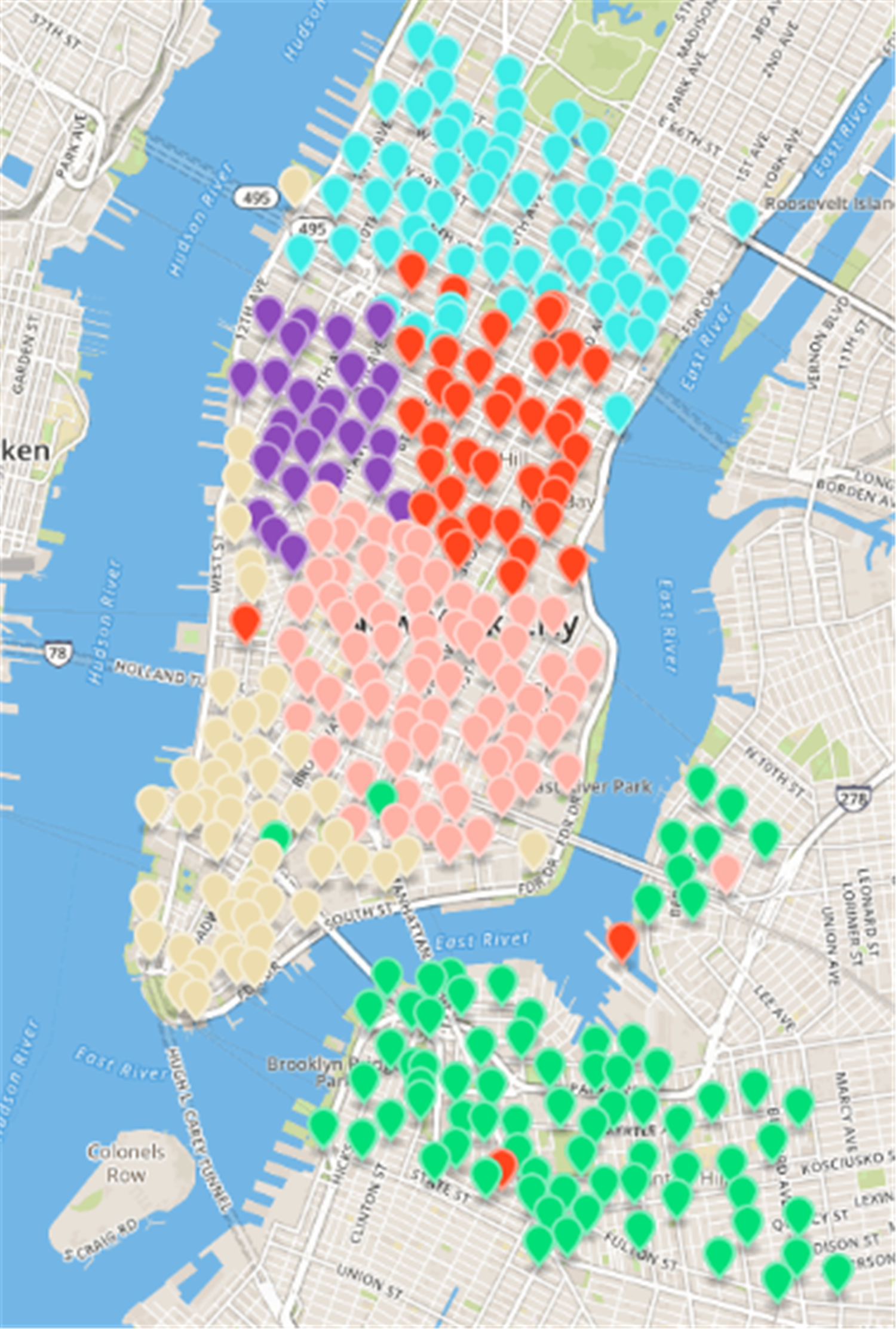
Figure 7: Results of fast unfolding community Discovery algorithm in the New York dataset.
{kind=link}
CDoMO is based on community discovery algorithm, considering the regional scheduling workload factors. The regional scheduling workload is determined by estimated dispatch distance and the number of regional least sites. If the community finds out that there are abnormal sites, it will cause regional forecasting scheduling distance become larger, so that the variance between the scheduling distances will become larger. If there is a major difference in the number of sites between areas, the variance between the numbers of sites will increase. The goal of CDoMO is to optimize the variance of the distance between the regional scheduling, and optimize the variance of the number of sites. In the optimization process, the division results can be adjusted to make it more reasonable. The division process does not take into consideration the deficiencies in the workload balance in each scheduling area. After the community discovery algorithm based on multi-objective optimization solves the division model of the public bicycle scheduling area, the experimental results shown in Fig. 8 are obtained. By comparing the result shows that the sites along the Williamsburg Bridge and the riverside along Manhattan is divided into the same dispatch area, which is more n line with the rules of public bicycle rental and resolving the anomaly (Zhang et al., 2011). The difference between the number of sites and regional sites is too large (Manju & Fred, 2018).
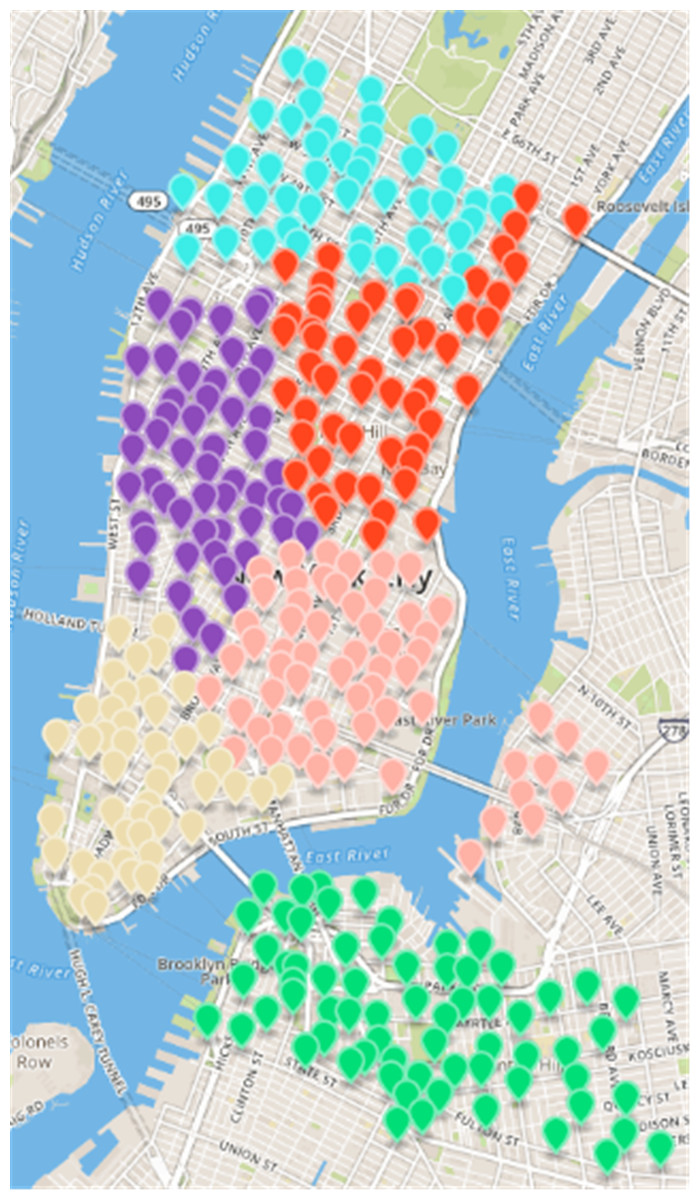
Figure 8: Results of region partition based on multi-objective optimization algorithm in the New York dataset.
{kind=link}
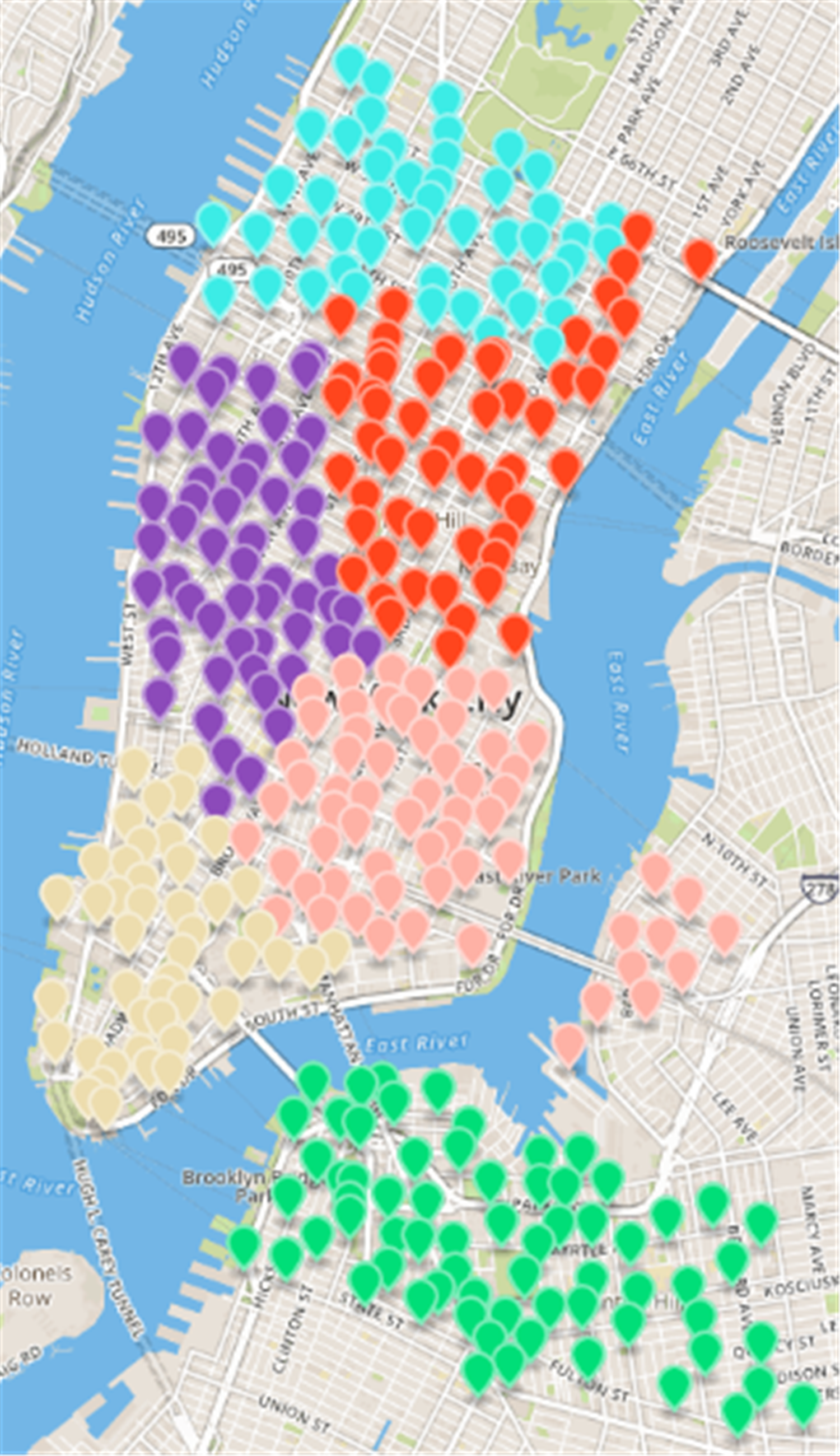
In order to maintain the consistency of the experiment, the value of k in the classical clustering algorithm K-means algorithm is set to 6 (Lin & Song, 2017), and then the clustering is based on the same data set; the space area enclosed by the sites in each class as the scheduling area. In order to achieve regional division, the results of the regional division based on the clustering algorithm (Fig. 9). It was found that when the clustering number is k=6, the clustering algorithm achieves a poor regional division. The number of sites in the class represented by the red is very large, while the number of classes represented by purple and beige is very small, and the number of sites to vary greatly from the types. In addition, the boundaries of each scheduling area are unclear and are overlapped (Zhen et al., 2016).
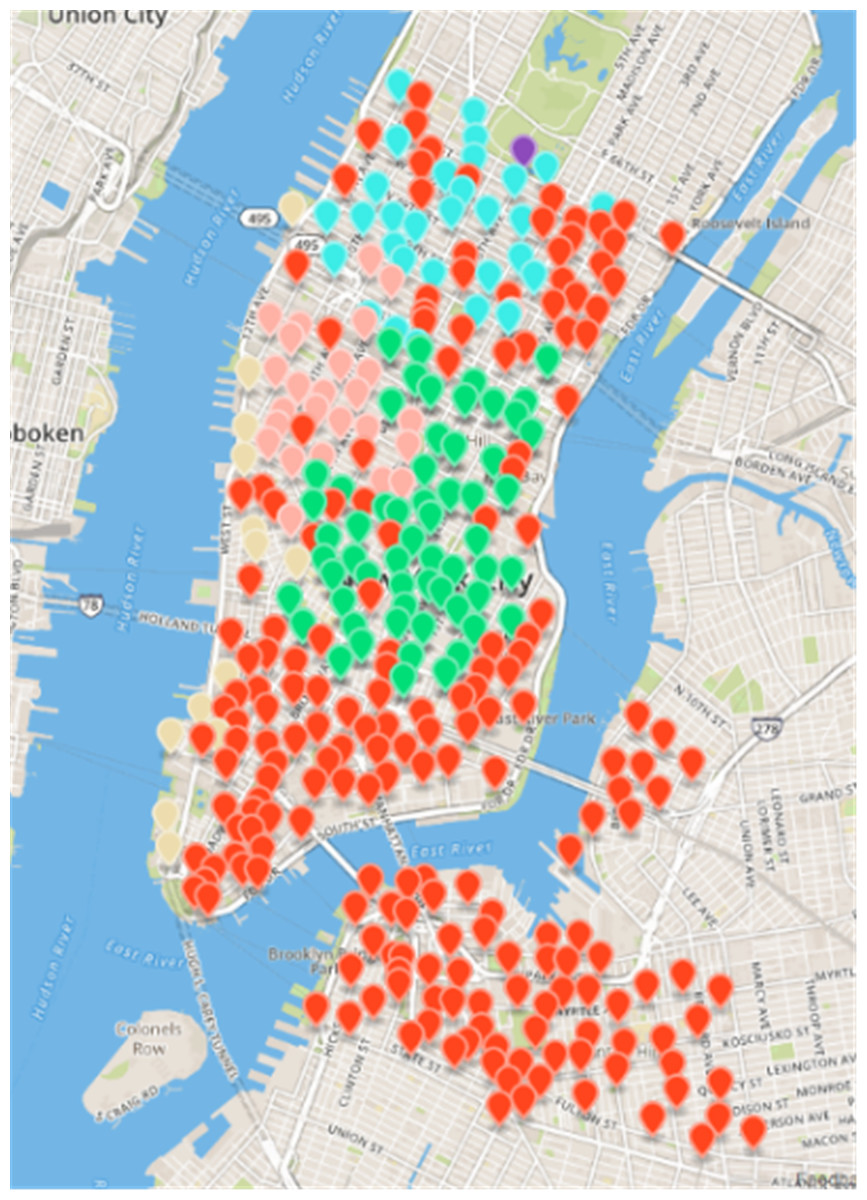
Figure 9: Results of region partition based on clustering algorithm in the New York dataset.
{kind=link}
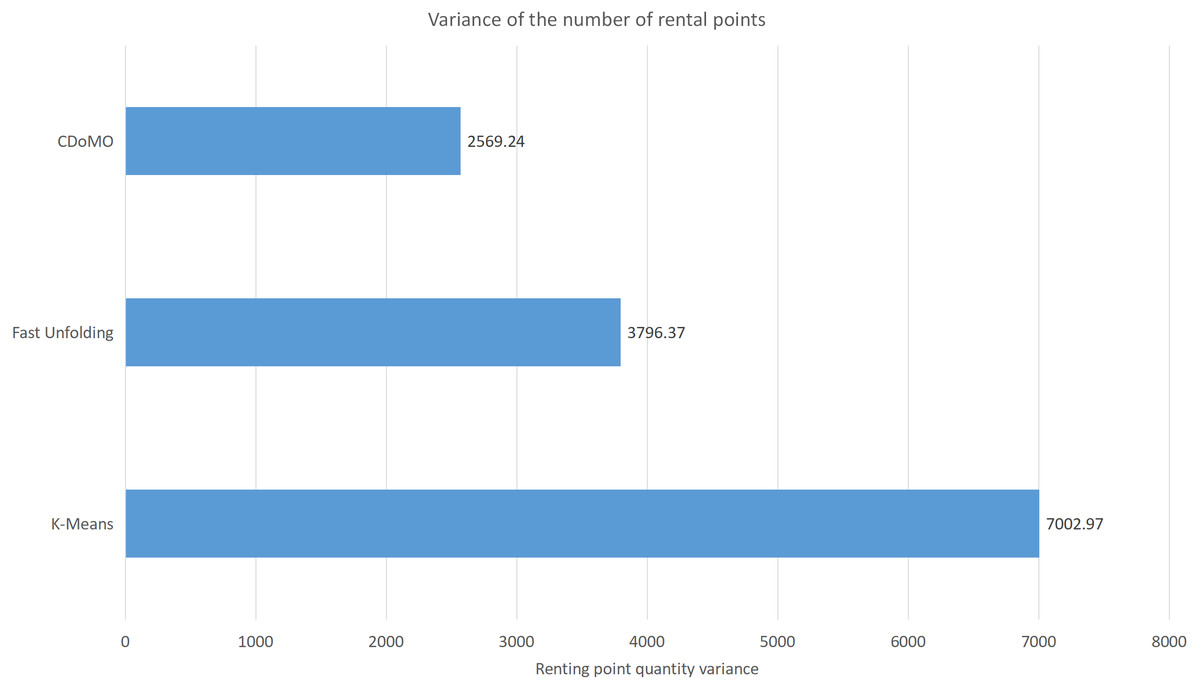
Figure 10: Difference in the number of bicycle rental points under three algorithms in the New York dataset.
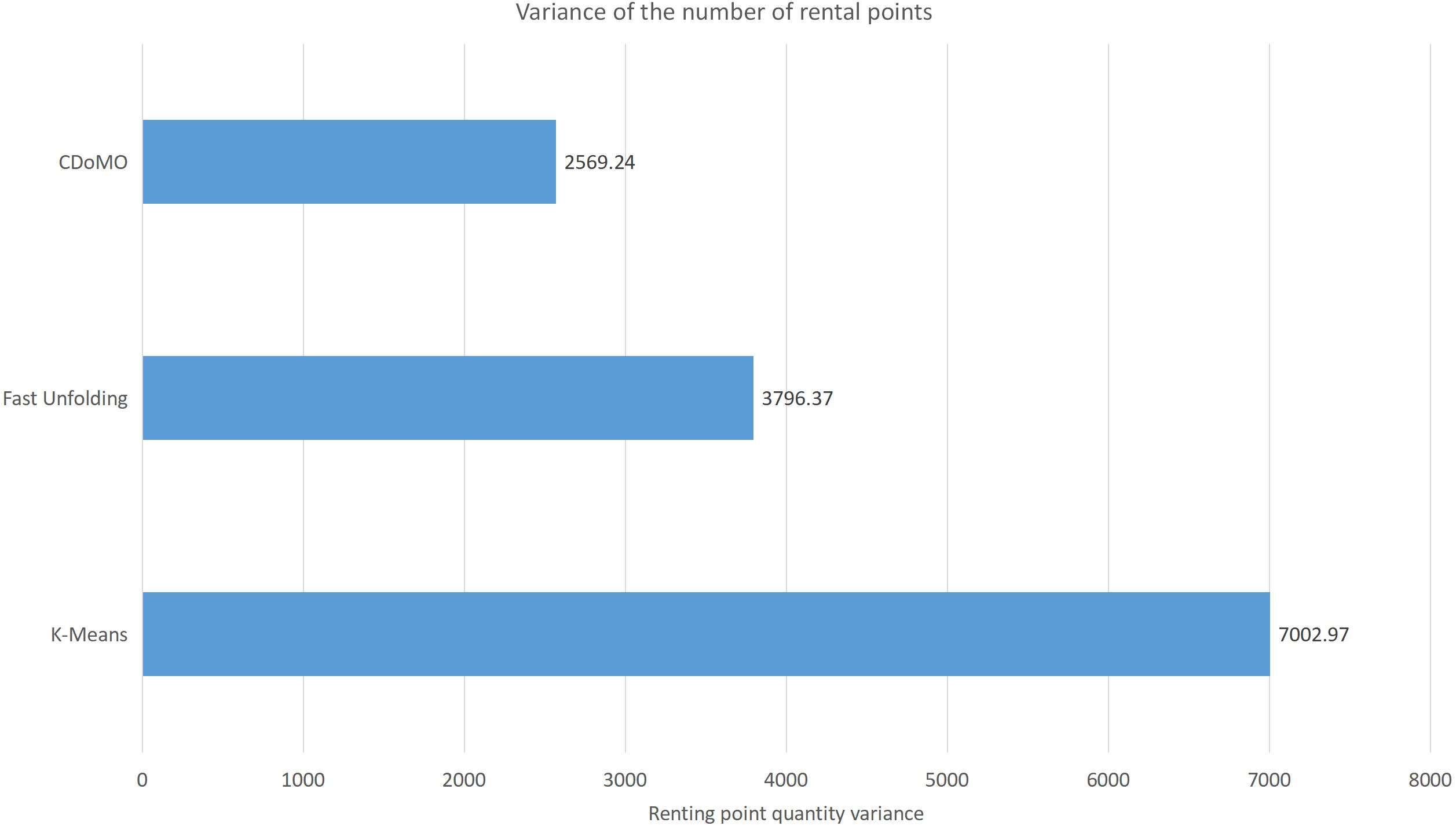{kind=link}
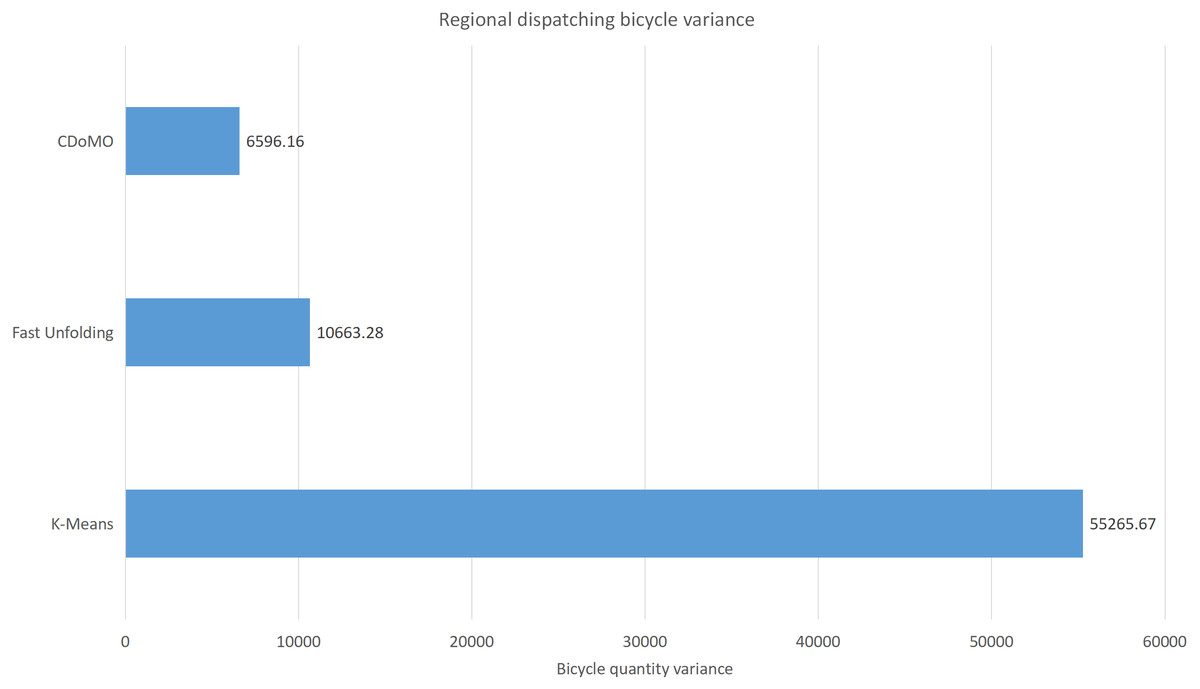
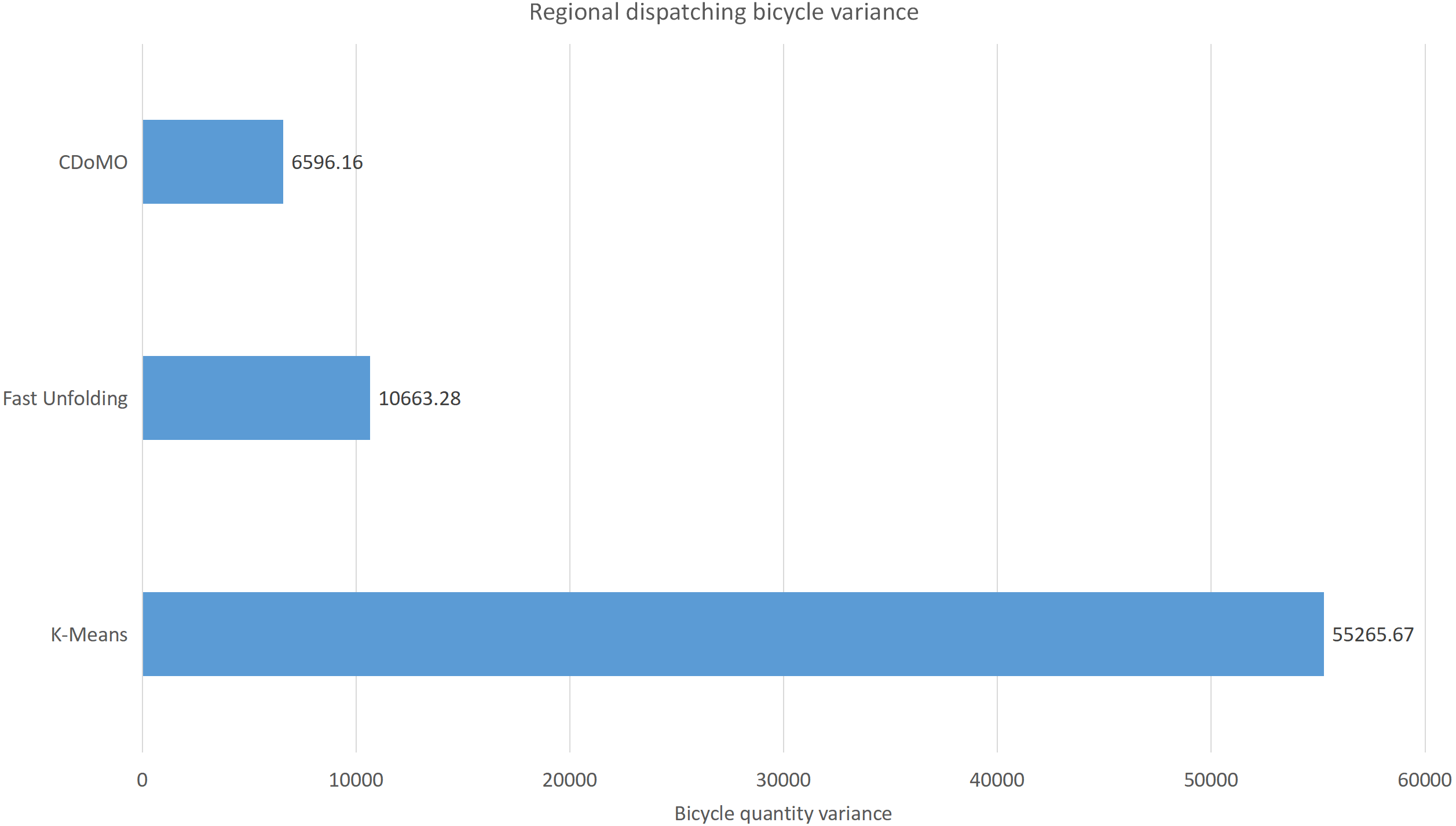
Figure 11: Distance difference of bicycle scheduling area under three algorithms in the New York dataset.
{kind=link}
Algorithm performance comparison results
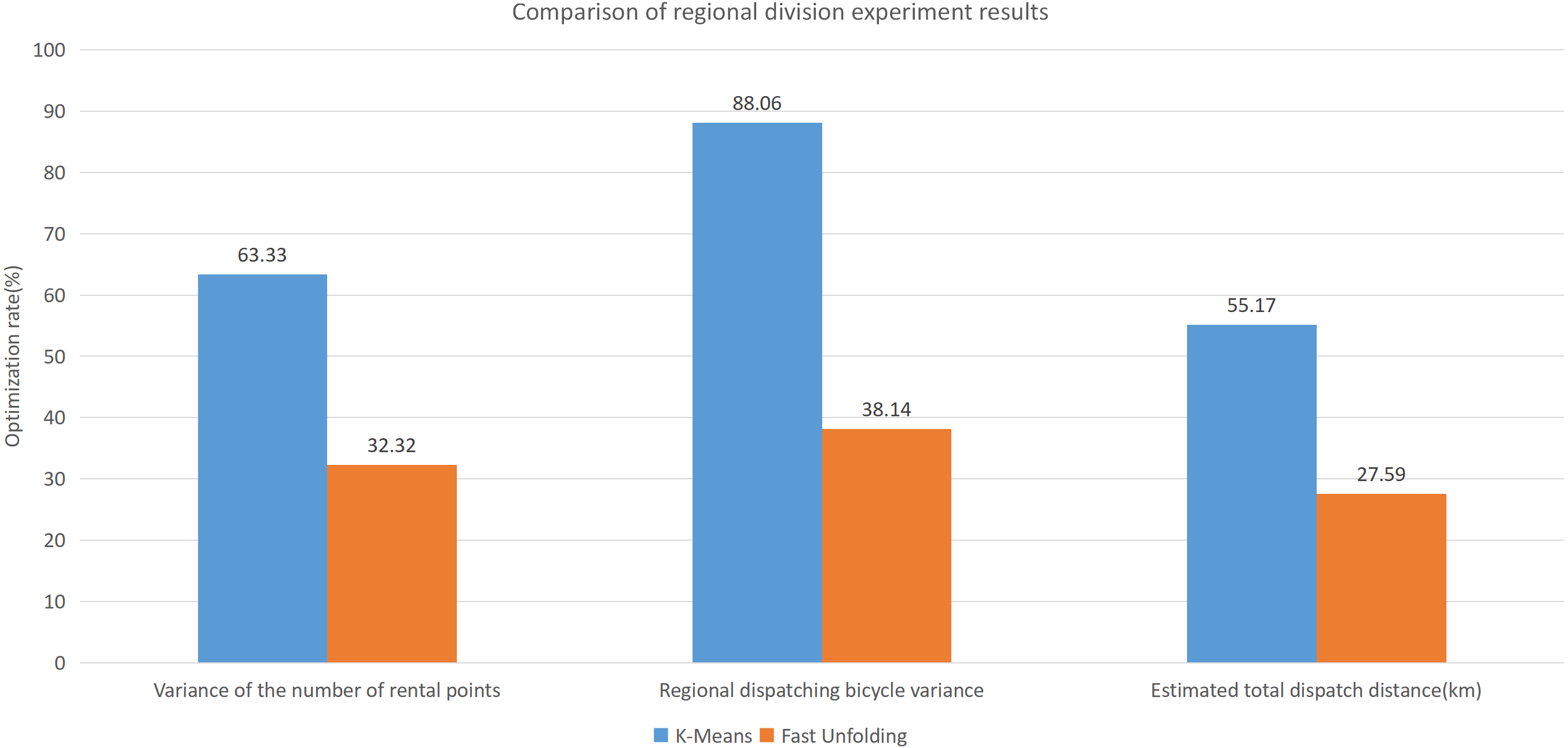
Built on the overall experimental results of the above three methods, it is found that the multi-objective optimization-based community discovery algorithm proposed to this paper can make the division of the areas consistent with the rules and make the regional scheduling workload as balanced as possible. In addition to the analysis of the overall distribution of provincial division space, the paper also compares and analyses the three dimensions of the regional rental site variance, the regional dispatch distance variance, and the estimated total dispatch distance. Figure 10 compares the variance between the numbers of sites. The data show that the variance between the CDoMO compared to the K-means algorithm is reduced by 63.31%, and the variance of the Fast Unfolding algorithm is reduced by 32.32%. Figure 11 compares the variance of the number of bicycles dispatched in the area. The data show that the variance of the CDoMO algorithm compared to the K-means algorithm is reduced by 88.06%, and the variance of the Fast Unfolding algorithm is reduced by 38.14%. Figure 12 compares the estimated total scheduled distances. The data show that the variance of the CDoMO algorithm is 55.17% compared with the K-means algorithm and 27.54% compared to the Fast Unfolding algorithm. When scheduling and partitioning based on multi-objective optimization algorithm, the estimated scheduling distance can be shortened, and the estimated scheduling distance is positively related to the actual scheduling distance, so the actual scheduling distance will also be shortened; in addition, the scheduling work of each area will also be made. Relatively balanced. Figure 13 is a comparative display of experimental results.
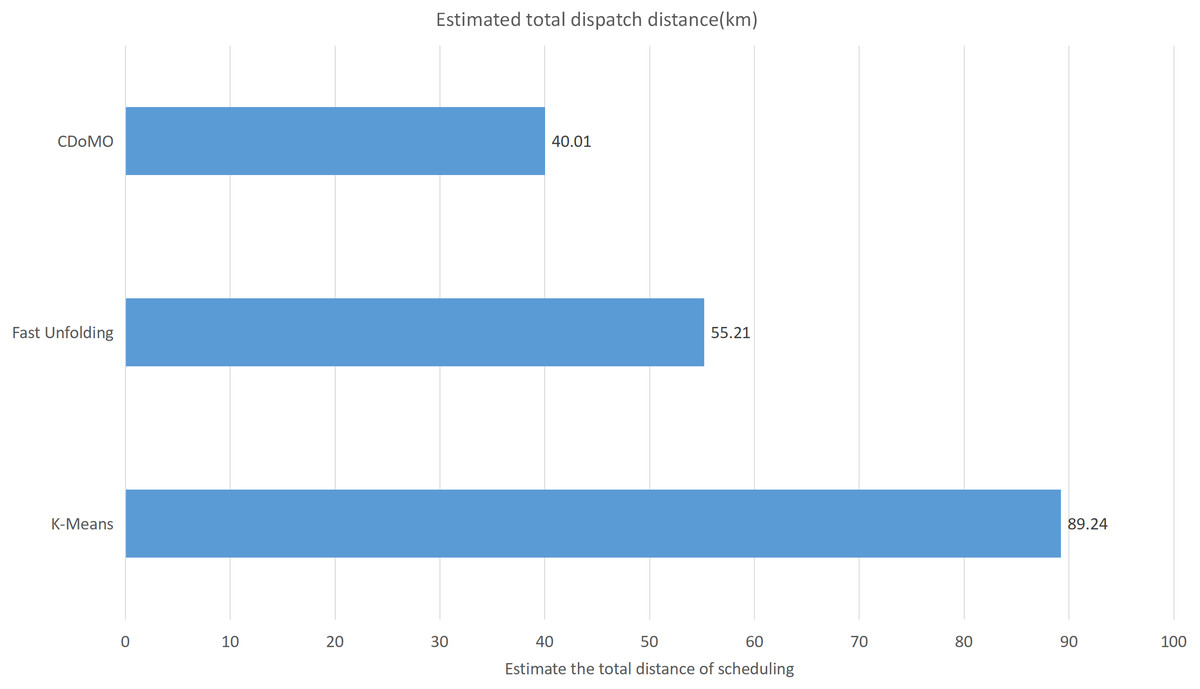
Figure 12: Total distance of estimated scheduling under three algorithms in the New York dataset.
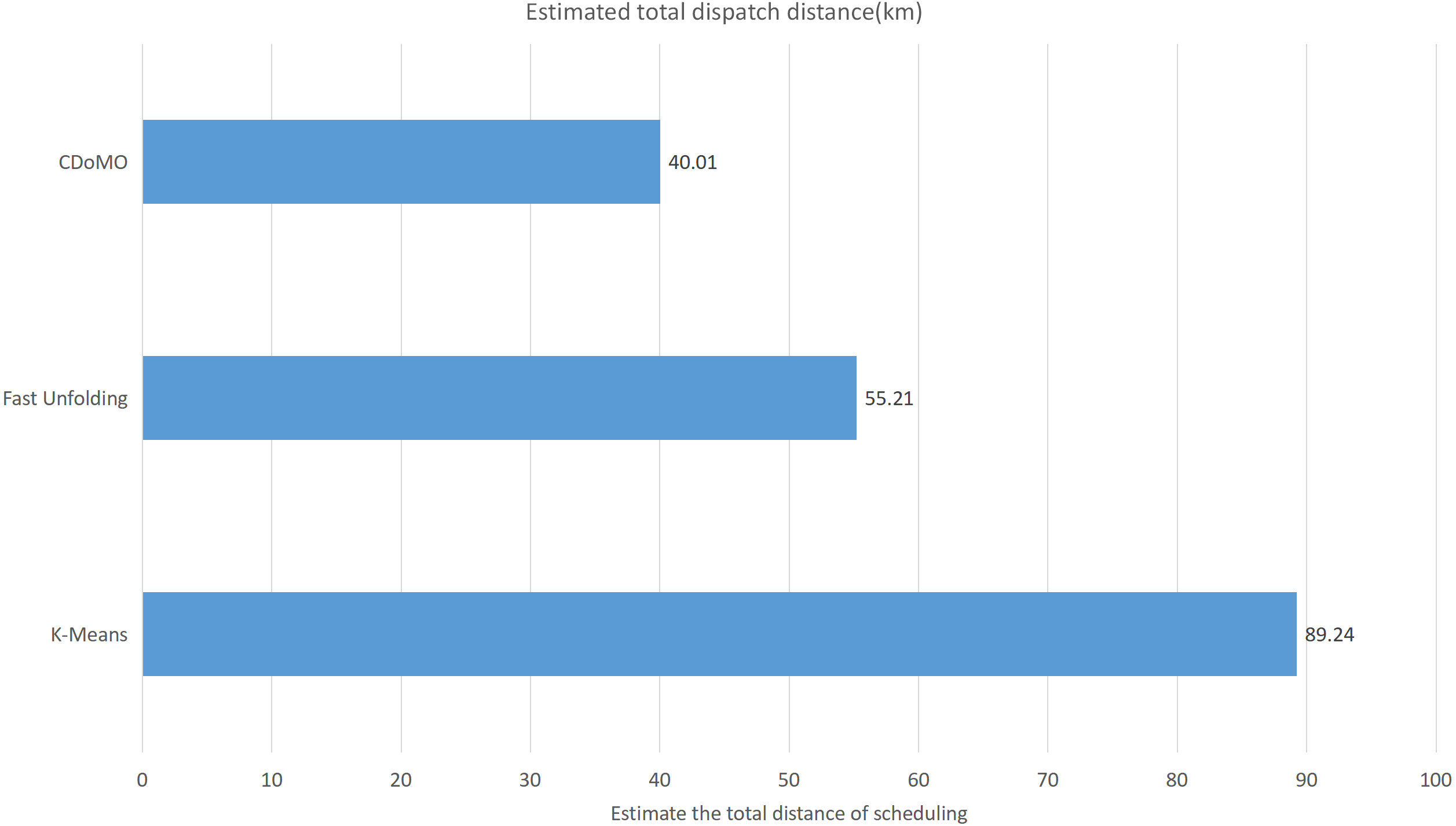{kind=link}
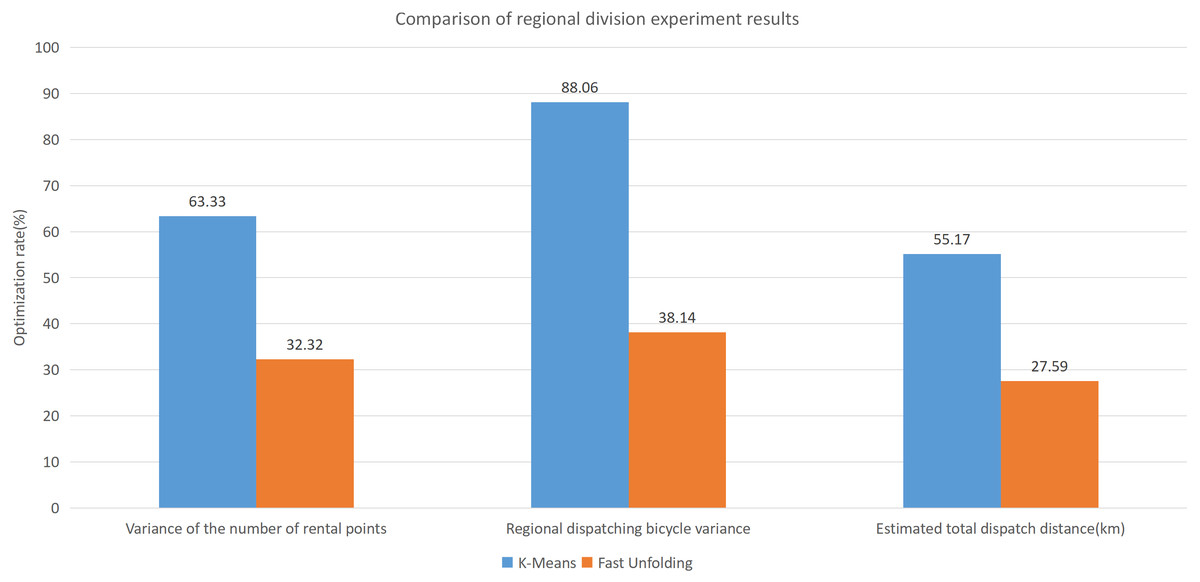
Figure 13: Comparison of experimental results of region partition under three algorithms in New York dataset.
{kind=link}
Chicago public bicycle
Data set introduction
First of all, the data set cited in this paper is from Chicago public bicycle data (Ye, Chu & Xu, 2015). The starting site is 2015-1-1, and the deadline is 2015-6-30. There are two quarters and six months of data, a total of 759,789 data records. This paper did some data pre-processing: Trips that did not include a start or end date were removed from the original table. Then, in order to ensure that the information of the data set more abundant, this paper decided to use the data set, distance information of each pair of source address and destination address. Finally, we utilize certain data pre-processing methods to remove weather and other data because it can be considered as an ideal condition. The dataset contains 12 fields, and the 10 fields related to this experiment are presented in the following Table 5.
| No. | Fields | Meaning |
|---|---|---|
| 1 | start time | day and time trip started, in CST |
| 2 | stop time | day and time trip ended, in CST |
| 3 | from_station_id | ID of station where trip originated |
| 4 | from_station_name | name of station where trip originated |
| 5 | from_station_longitude | Longitude of rental bicycle rental site |
| 6 | from_station_latitude | Latitude of rental bicycle rental |
| 7 | to_station_id | ID of station where trip terminated |
| 8 | to_station_name | name of station where trip terminated |
| 9 | to_station_longitude | The longitude of the bicycle rental site |
| 10 | to_station_latitude | The longitude of the bicycle rental site |
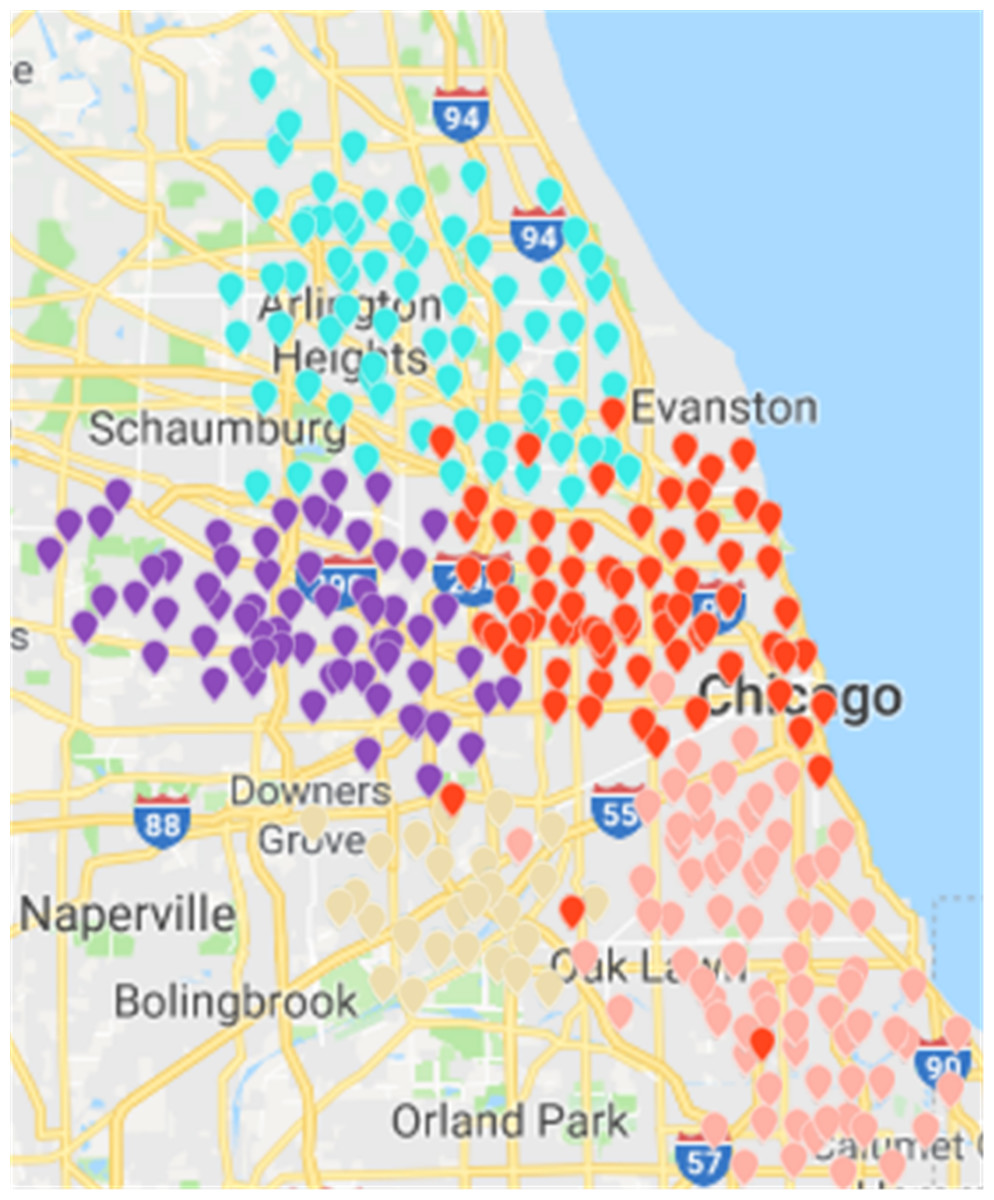
Figure 14: Results of fast unfolding community discovery algorithm in Chicago dataset.
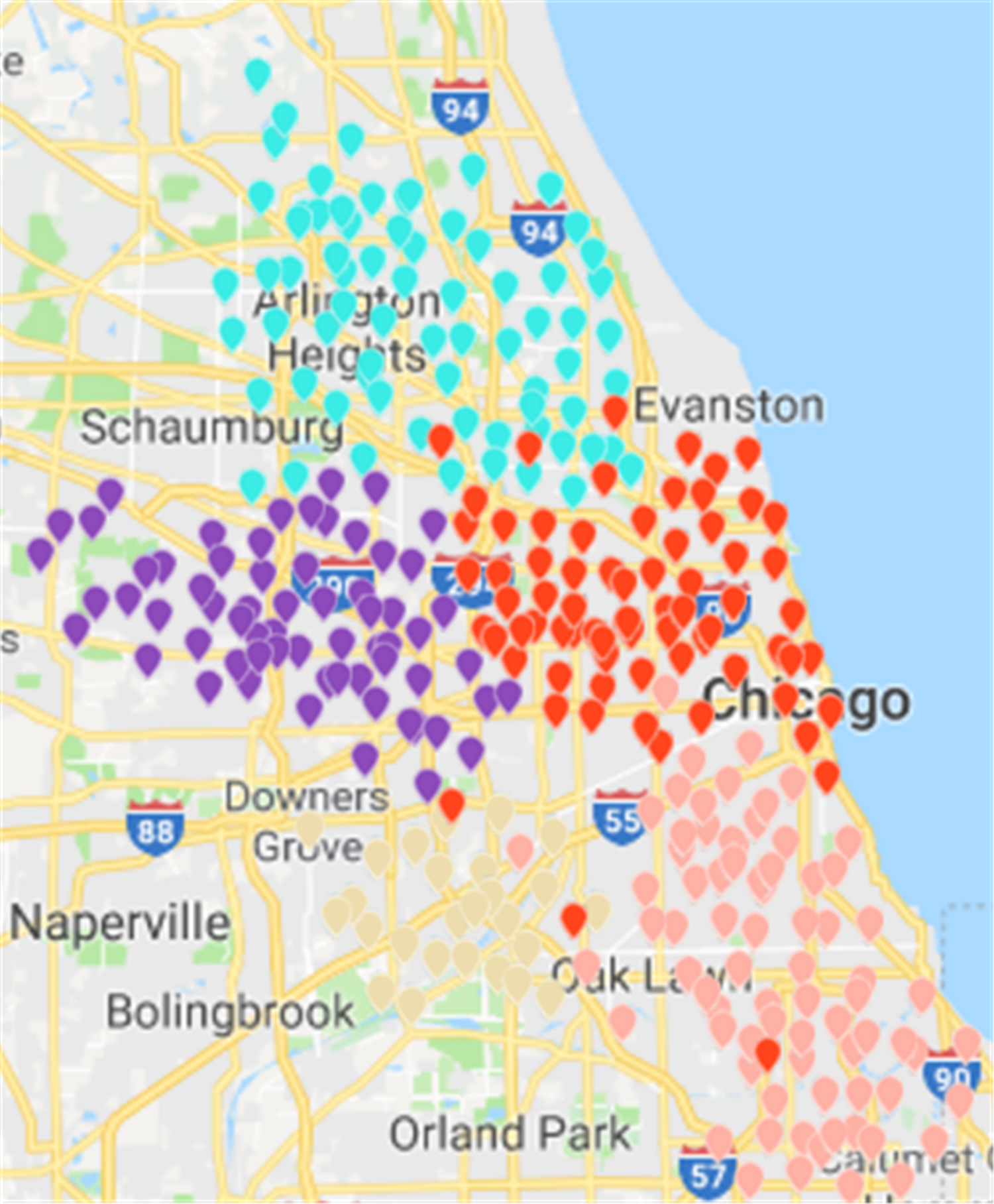{kind=link}
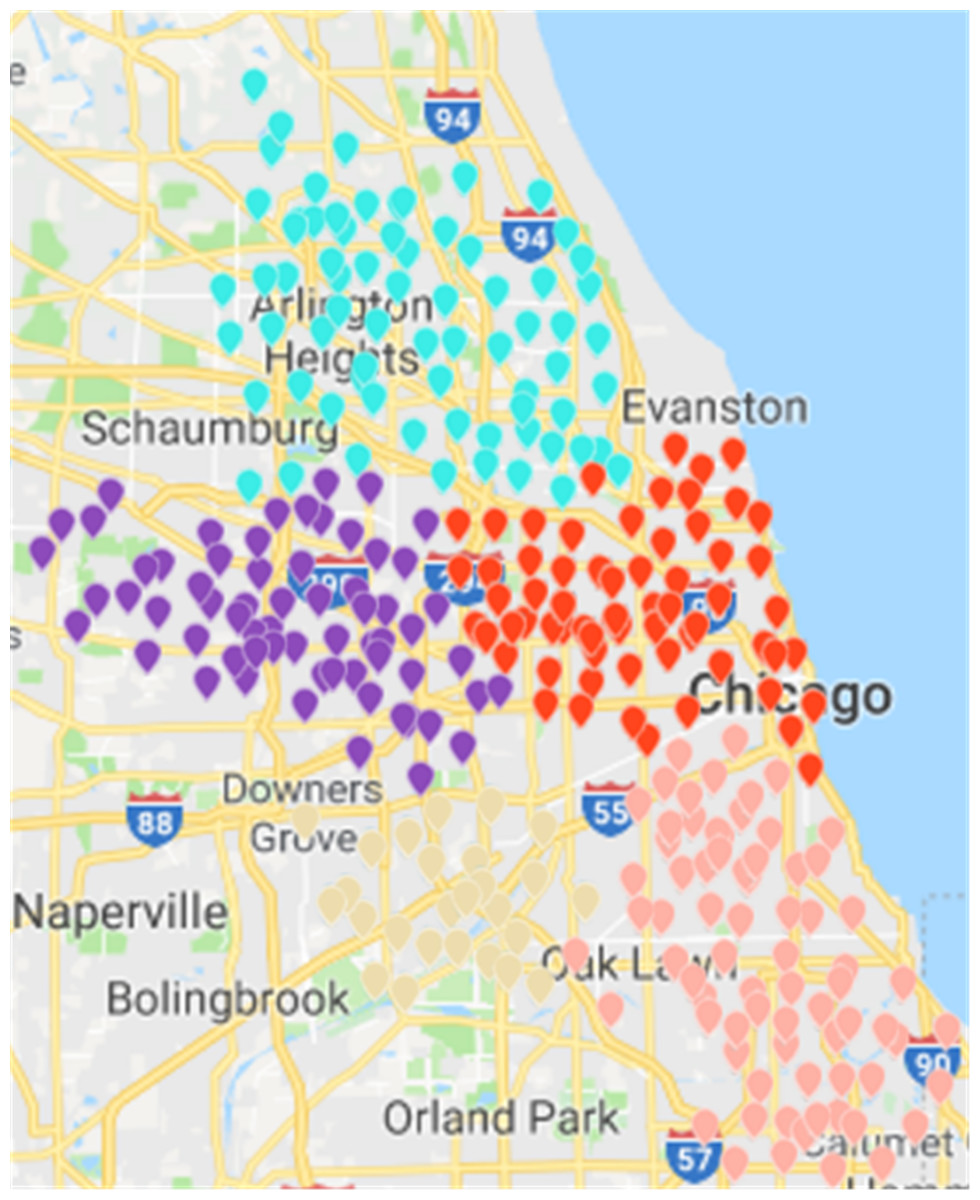
Figure 15: Results of region partition based on multi-objective optimization algorithm in the Chicago dataset.
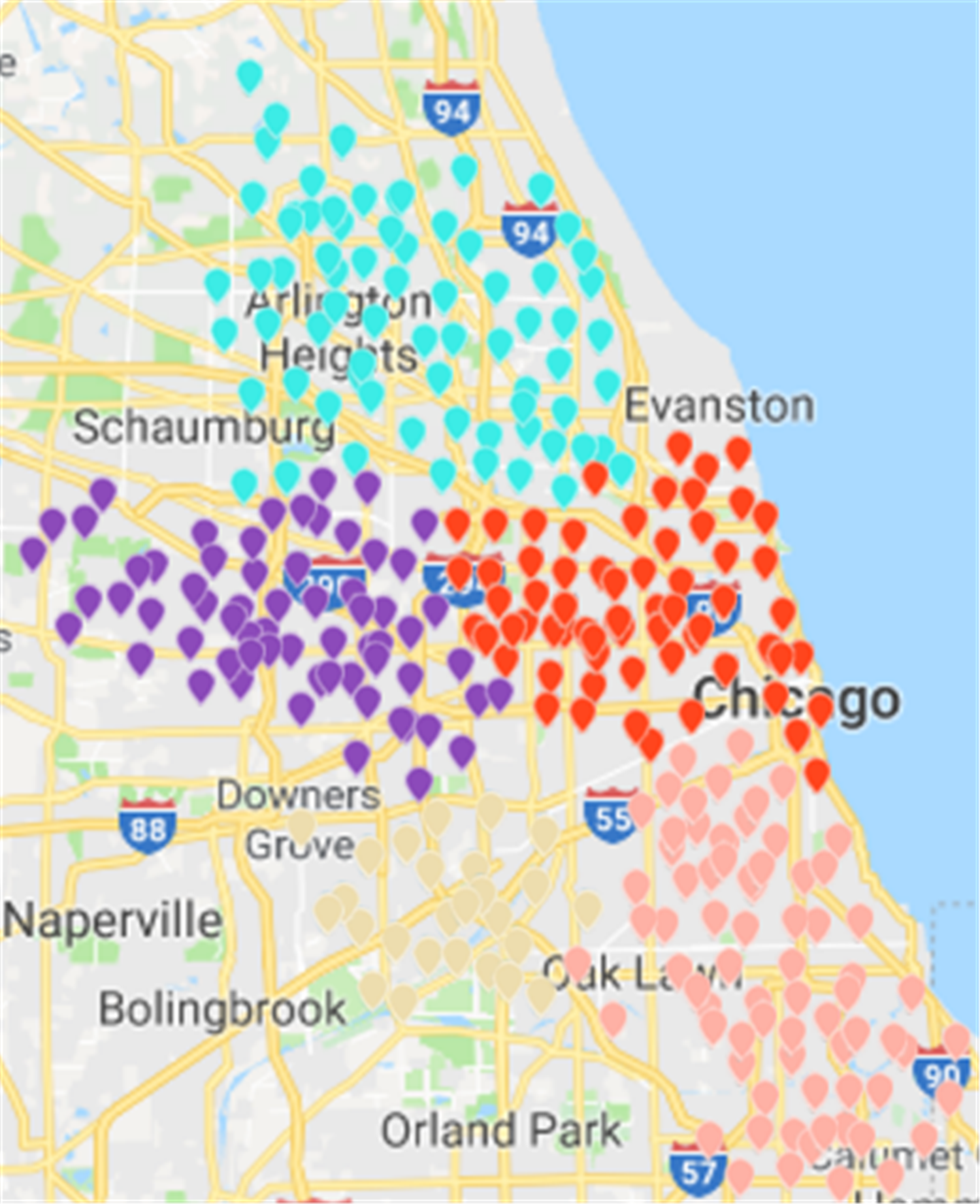{kind=link}
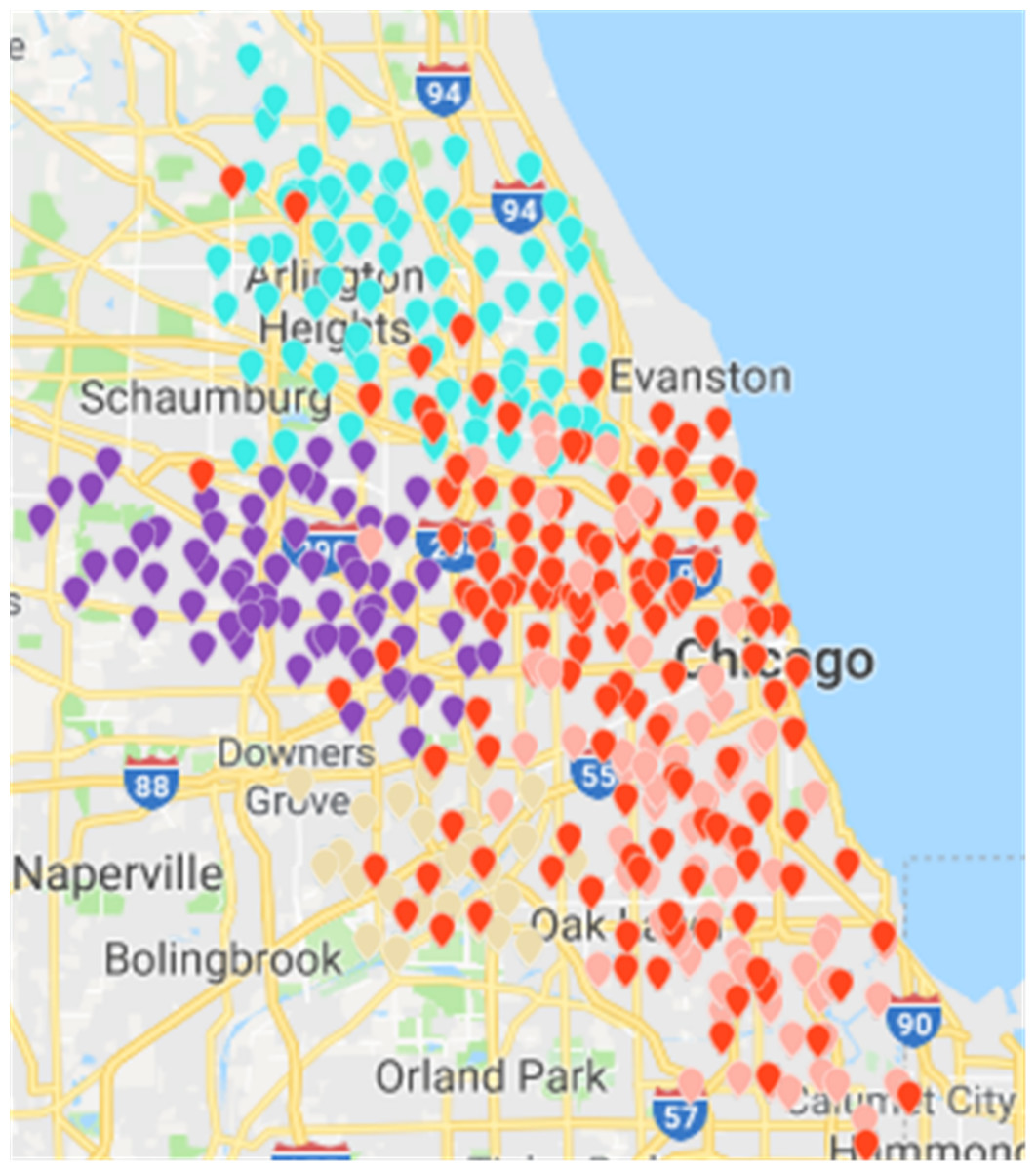
Figure 16: Results of region partition based on clustering algorithm in the Chicago dataset.
{kind=link}
Experimental result
Results of the Fast Unfolding community discovery algorithm can be mapped to Chicago map as the picture shows (Ye, Chu & Xu, 2015). In contrast, the division results are more uniform and reasonable, but there are too many abnormal sites in the middle. These abnormal sites are a long way from where they should have existed. The number of rental sites in a divided area is not particularly uniform (Fig. 14).
Based on CDoMO, in the optimization process, the division results are dynamically adjusted in time. Therefore, in this case, the division result is more reasonable, and the problem of scheduling balance, this algorithm obviously adds more consideration. It not only addresses the problem of abnormal sites, but also solves the problem of differences in the number of regional sites at the same time (Fig. 15). In order to make the experiment consistent, we set the value of k in the K-means algorithm as 5, and then we clustered the uniform data set. The results of the clustering are presented in the figure. This paper believes that the results obtained by the clustering algorithm are very poor, because the red sites represent a particularly large number of sites. The yellow site represents a particularly small number of rental sites. This shows that the various types of leases, the number of differences is too large, in addition, this algorithm also led to the border is not clear, and there is some inevitable overlap. In the actual scheduling work, this situation is not allowed, as showed in Fig. 16.
Algorithm performance comparison results
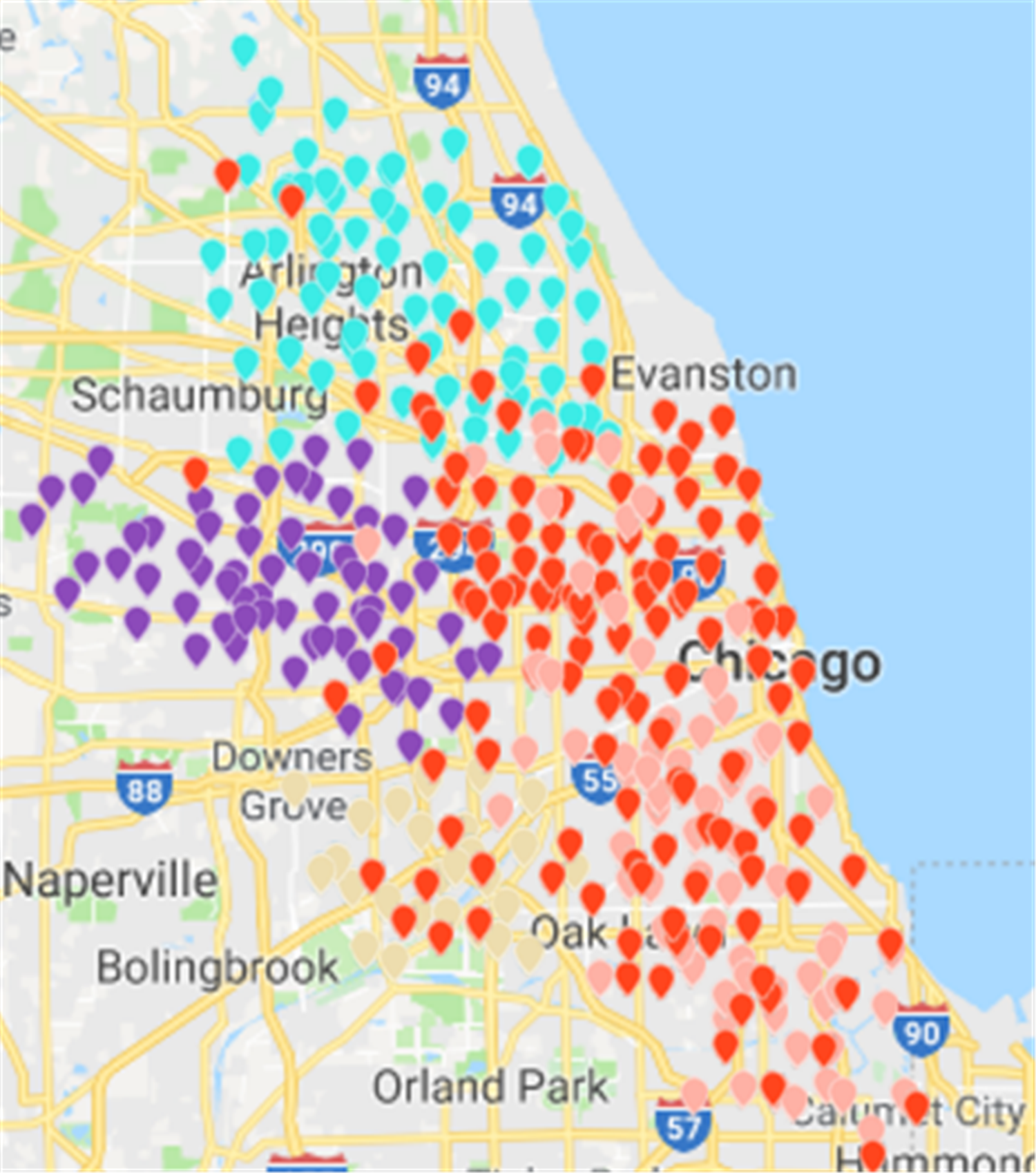
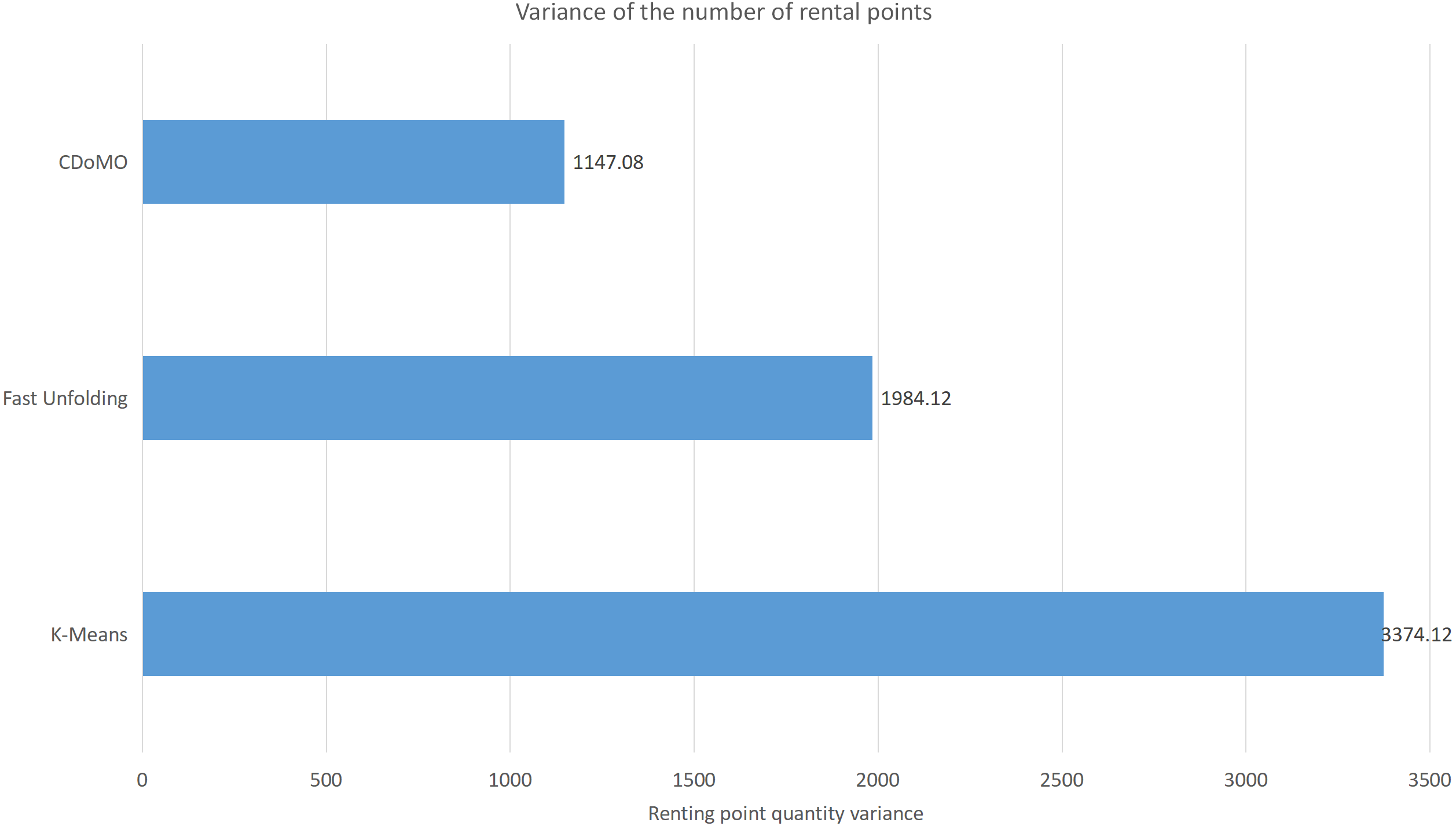
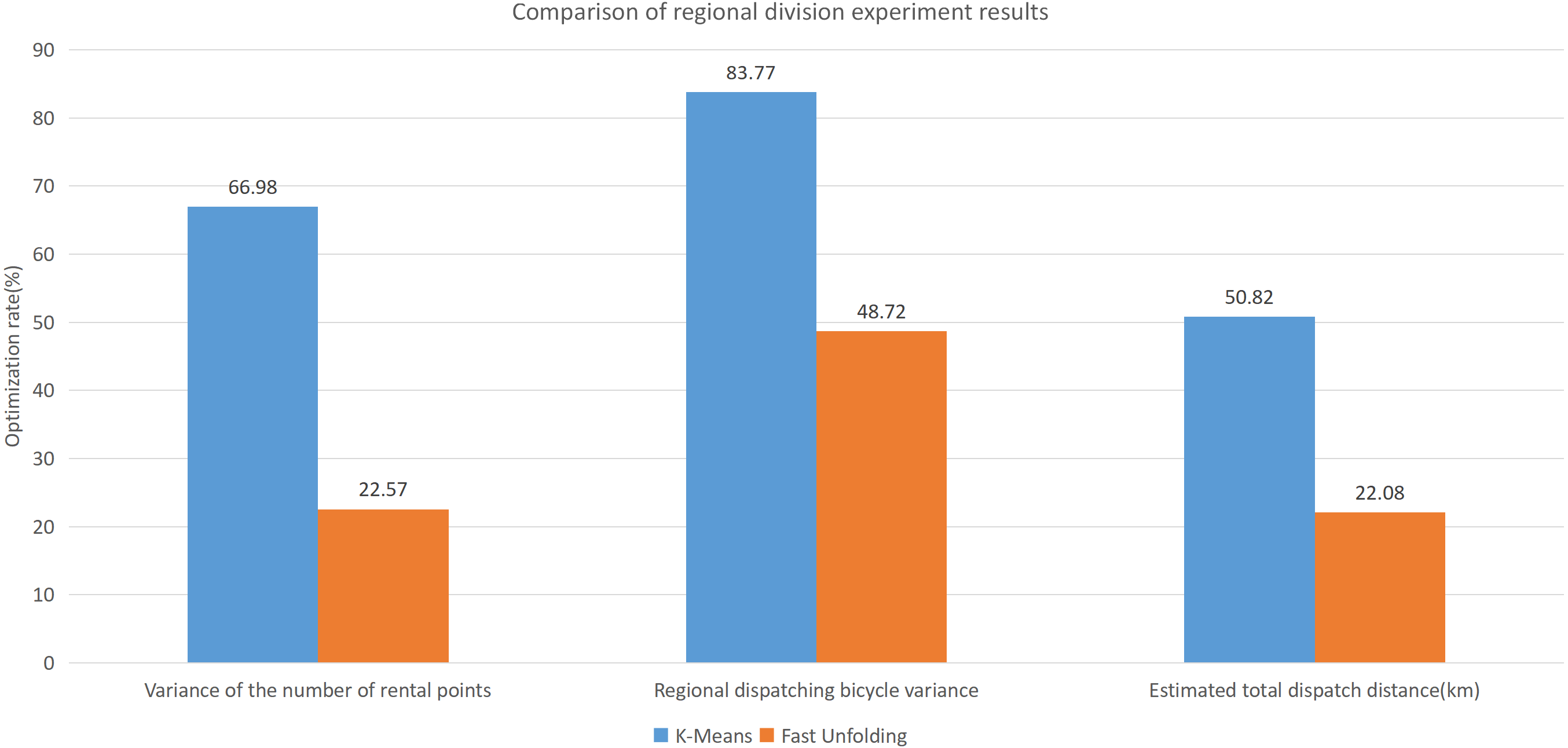
This paper will describe the quantified experimental results of the three methods, it compares the differences between them. It is easy to see that the algorithm proposed in this paper is optimal, compared to the other two algorithms. Figure 17 compares the difference between the numbers of sites. Compared to the K-means clustering algorithm and the Fast Unfolding community discovery algorithm, the variance of the CDoMO algorithm is reduced by 66.98% and 22.57%. Figure 18 in this paper compares the number of scheduled bicycles, it finds that the CDoMO algorithm set out in the present paper is an optimal algorithm. Similarly, opposed to the K-means clustering algorithm and the Fast Unfolding community finding algorithm, the variance is reduced by 83.77% and 48.72% (Fig. 19). Figure 20 compares the estimated total distance of scheduling with the other two algorithms, and the conclusion shows that the distance is decreased by 50.82% and 22.08%.
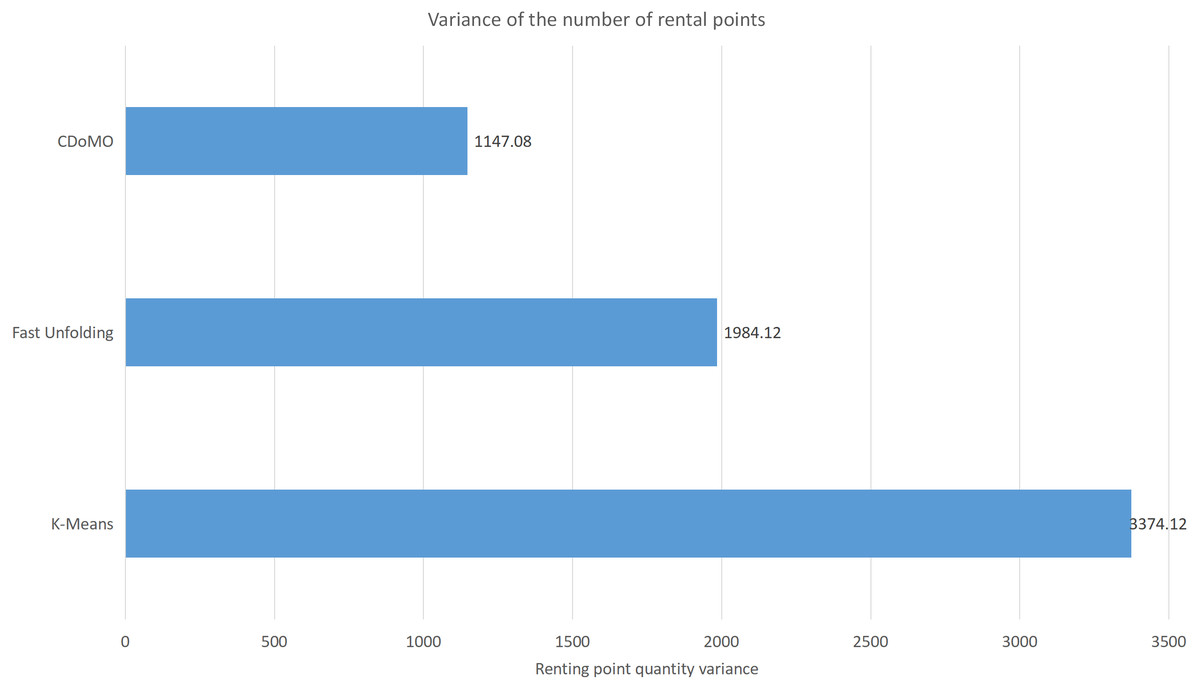
Figure 17: Difference in the number of bicycle rental points under three algorithms in the Chicago dataset.
{kind=link}
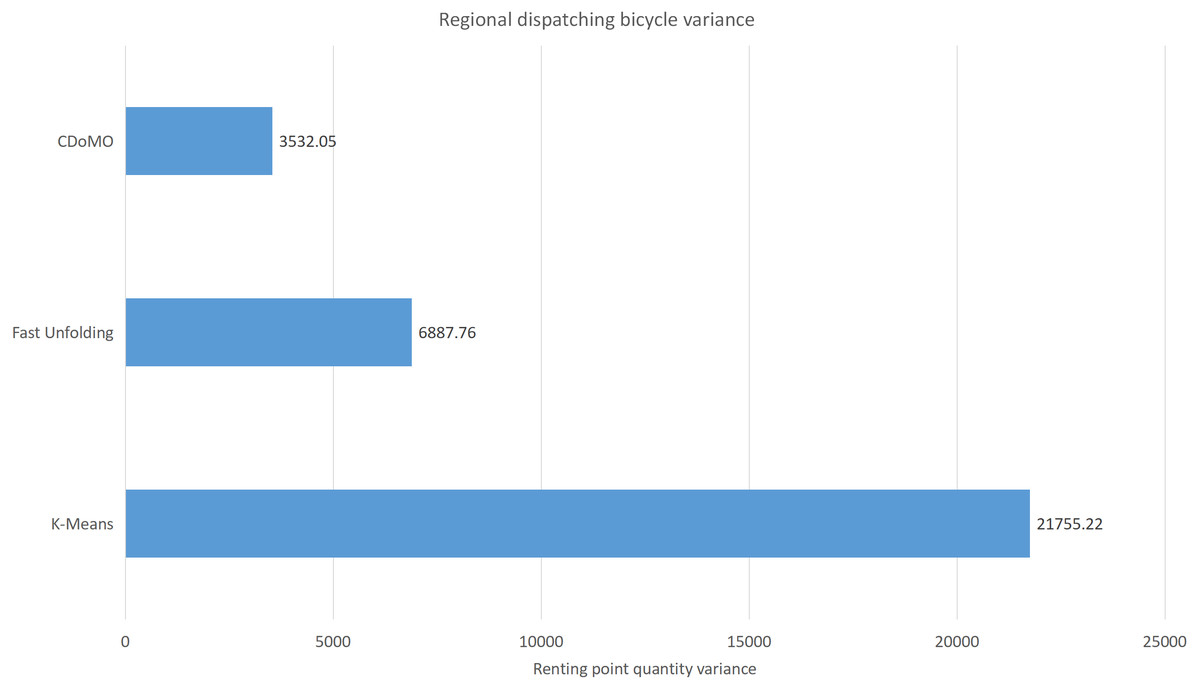
Figure 18: Distance difference of bicycle scheduling area under three algorithms in the Chicago dataset.
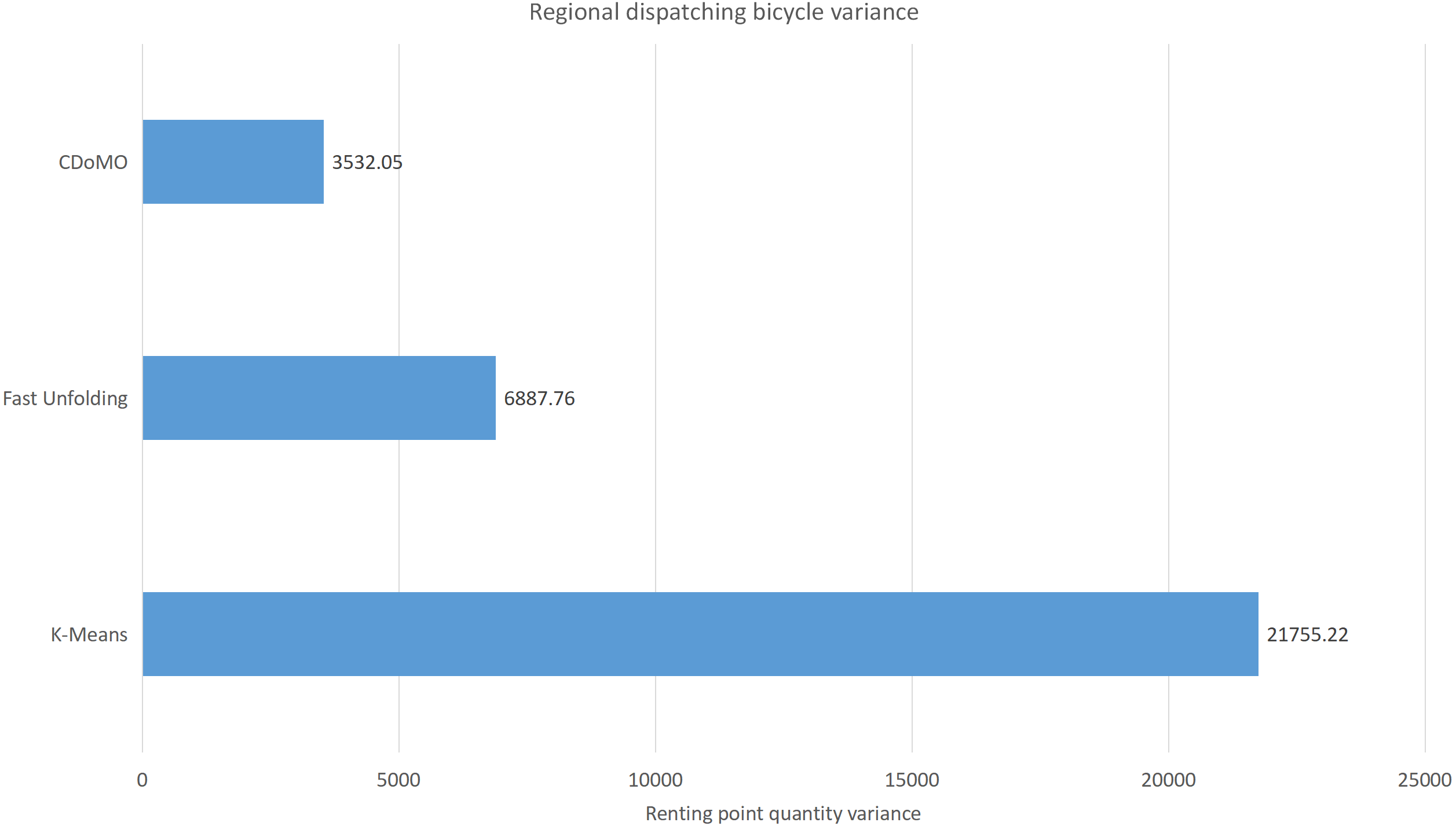{kind=link}
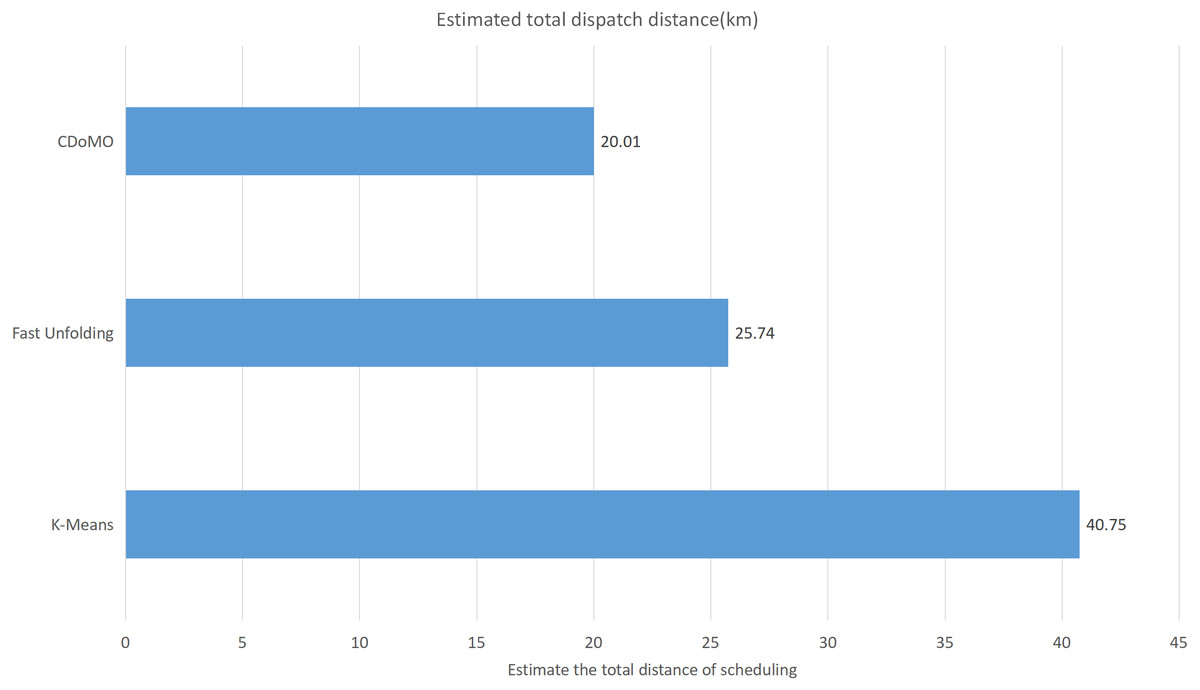
Figure 19: Total distance of estimated scheduling under three algorithms in the Chicago dataset.
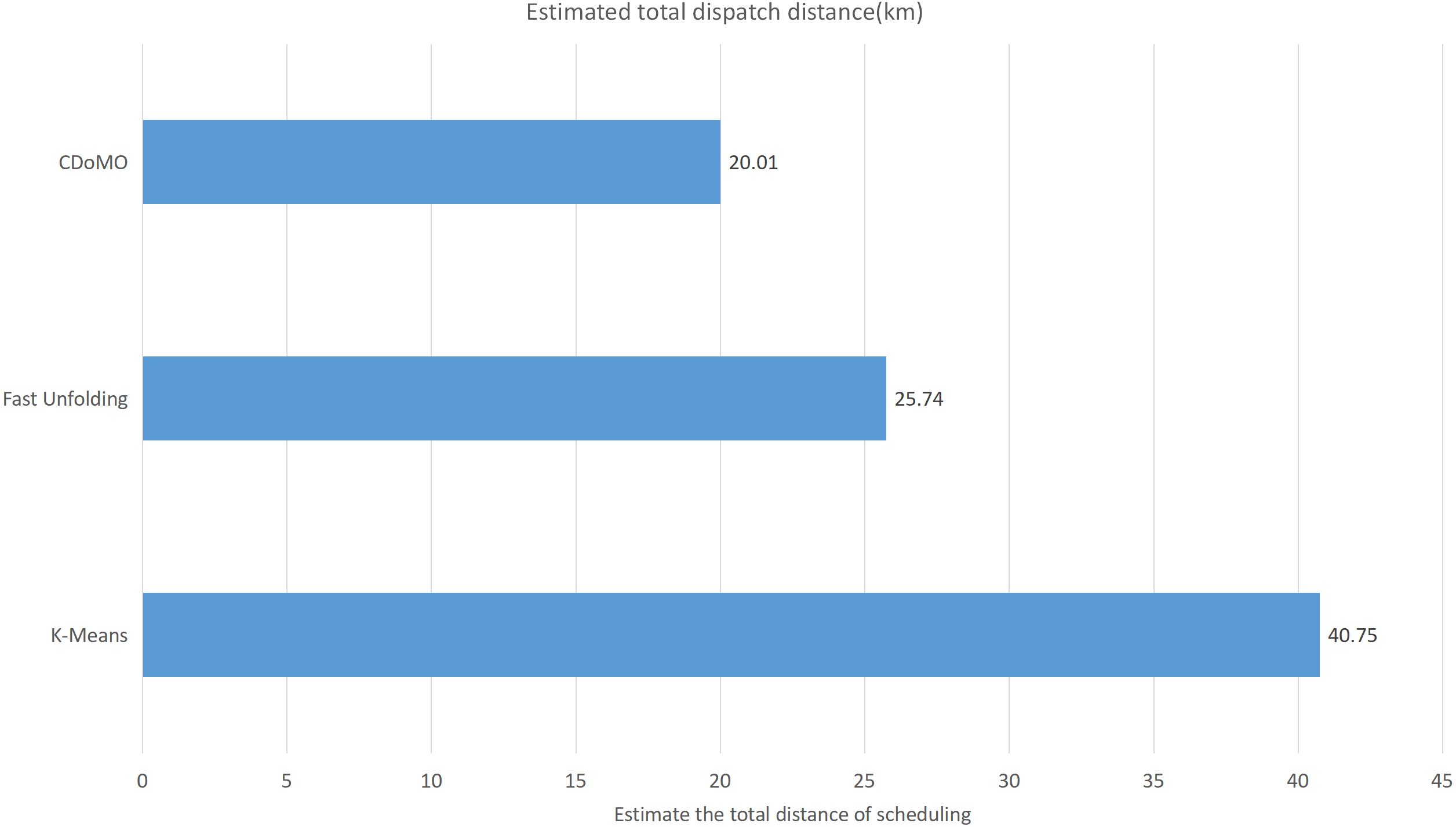{kind=link}
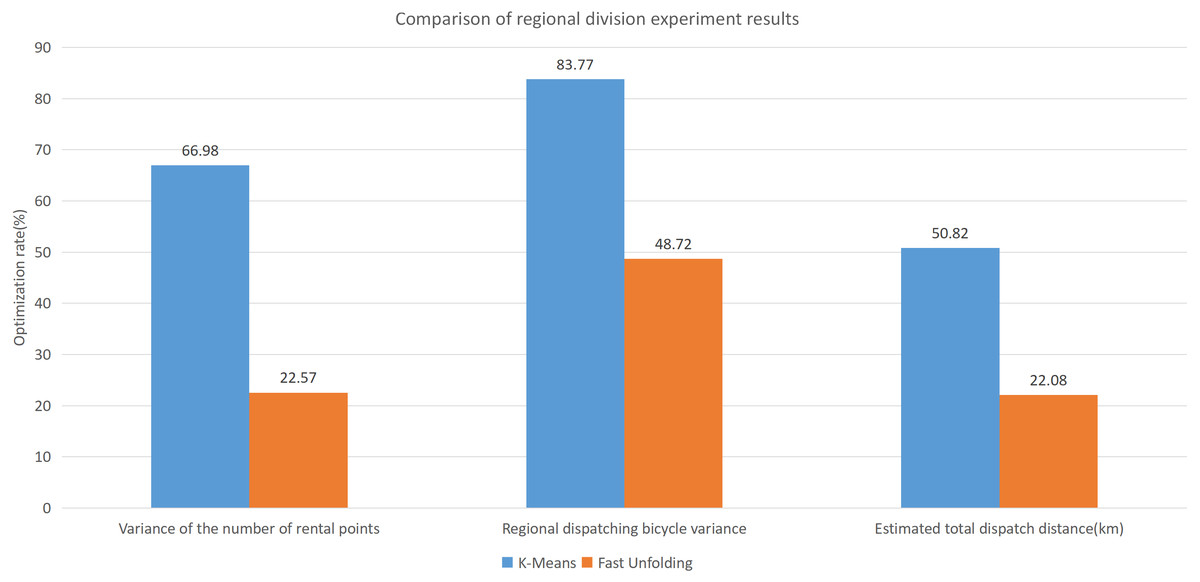
Figure 20: Comparison of experimental results of region partition under three algorithms in the Chicago dataset.
{kind=link}
Then we can conclude that the CDoMO algorithm proposed in this paper: It effectively reduces the number of sites; it effectively reduced the variance in the number of bicycles dispatched; it effectively reduced the estimated total distance for scheduling.
Conclusion
In order to solve the problem of regional division of public bicycles, this paper proposes CDoMO. The algorithm fully considers the special law of public bicycle lease/return, and in order to balance the scheduling workload between areas, the regional scheduling workload index is proposed. This problem is identified as a multi-objective optimization problem with two objective functions: minimize the variance between the estimated dispatch distances between each area; minimize the variance between the numbers of sites in each area. The regional scheduling workload can adjust the results of the community discovery algorithm in real time and dynamically. In the end, the results obtained can meet the special rules of public bicycle lease/return, and balance the workload between the areas. The experimental results show that the CDoMO can effectively shorten the scheduling distance of public bicycle system, effectively improve the scheduling efficiency, and make the workload of each scheduling area relatively balanced. The next step is to have a more appropriate solution if you limit the travel time and mileage of the scheduling vehicle.