

Deep fake detection using a sparse auto encoder with a graph capsule dual graph CNN
- Published
- Accepted
- Received
- Academic Editor
- Imran Ashraf
- Subject Areas
- Algorithms and Analysis of Algorithms, Artificial Intelligence, Computer Vision, Data Mining and Machine Learning, Data Science
- Keywords
- DeepFake, Deep learning, Generative adversarial networks, Long short term memory (LSTM), Graph LSTM, Capsule convolution neural network
- Copyright
- © 2022 Kandasamy et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2022. Deep fake detection using a sparse auto encoder with a graph capsule dual graph CNN. PeerJ Computer Science 8:e953 https://doi.org/10.7717/peerj-cs.953
Abstract
Deepfake (DF) is a kind of forged image or video that is developed to spread misinformation and facilitate vulnerabilities to privacy hacking and truth masking with advanced technologies, including deep learning and artificial intelligence with trained algorithms. This kind of multimedia manipulation, such as changing facial expressions or speech, can be used for a variety of purposes to spread misinformation or exploitation. This kind of multimedia manipulation, such as changing facial expressions or speech, can be used for a variety of purposes to spread misinformation or exploitation. With the recent advancement of generative adversarial networks (GANs) in deep learning models, DF has become an essential part of social media. To detect forged video and images, numerous methods have been developed, and those methods are focused on a particular domain and obsolete in the case of new attacks/threats. Hence, a novel method needs to be developed to tackle new attacks. The method introduced in this article can detect various types of spoofs of images and videos that are computationally generated using deep learning models, such as variants of long short-term memory and convolutional neural networks. The first phase of this proposed work extracts the feature frames from the forged video/image using a sparse autoencoder with a graph long short-term memory (SAE-GLSTM) method at training time. The first phase of this proposed work extracts the feature frames from the forged video/image using a sparse autoencoder with a graph long short-term memory (SAE-GLSTM) method at training time. The proposed DF detection model is tested using the FFHQ database, 100K-Faces, Celeb-DF (V2) and WildDeepfake. The evaluated results show the effectiveness of the proposed method.
Introduction
With the advancement of technology, accessibility to social networks is easier for all users. Therefore, many deepfake images and videos have been spread on social media platforms. Manipulation of digital images or videos on social media involves replacing the image of a person with the face of another person. This manipulation of facial images is called deepfake and has become a very annoying social problem nowadays. Swapping popular faces with celebrities from Hollywood or politicians will mislead people’s opinions and create rumors about celebrities or politicians (Wang et al., 2020; Nataraj et al., 2019). The spread of false information in the form of deepfake through synthetically created images and videos has increased daily. This will become a significant issue for manipulative detection techniques.
Detection and prevention of deepfake images and videos are essential on social media. For these research studies, various organizations, such as Facebook Inc., the US Defense Advanced Research Projects Agency (DARPA), and Google, support researchers in detecting and preventing deepfake images and videos. (Westerlund, 2019; Kwok & Koh, 2021). In the detection of forged images and videos, many research works have been developed, and these research works focus on keeping personality information secret in a secure way. To detect the difference between real and fake images, ocular biometrics, based on the CNN approaches of SqueezeNet, DenseNet, ResNet and light CNN (Nguyen, Yamagishi & Echizen, 2019), is used. To ensure personnel data security and avoid the deepfakes, the researchers are motivated to develop an efficient deepfake detection system using deep learning approaches. The main contributions of this research work are as follows.
Implementing the deepfake face detection method based on the SAE-GLSTM and capsule dual graph CNN model in which dimensionality reduction is used for the features in the face image.
To improve accuracy, preprocessing in this work implements an adaptive median filter and uses GLSTM to extract image features.
Compare to the existing research works, our proposed is efficient in deepfake detection system using deep learning based preprocessing, feature extraction and detection. This system ensures the efficiency, reliability and integrity.
The article is organized as follows. “Review of Literature” describes a review of the literature, “Proposed Methodology” introduces deep detection using SAE-GLSTM and the capsule dual graph CNN model, “Experimental Result & Discussions” discusses the experimental results, and “Conclusion” concludes the article with future directions.
Review of Literature
Deepfake is composed of “deep learning” and “fake” concepts with a technique for synthesizing videos or images using deep learning techniques. Deepfake enthusiasts swap the face of an image or perform video forgery to spread misinformation, mask real information, and promote privacy insecurity using advanced techniques such as artificial intelligence and deep learning techniques. This swapping of images or videos of faces has become an annoyance for social media platforms. Social media users have had difficulty publishing forged images or videos that are developed by combining celebrity or politician images in the video (Kaur, Kumar & Kumaraguru, 2020).
Detection of face tampering using the CNN model is based on the concept of two streams of face classification and patch triplets. In the training process, the face image was classified as having been tampered with (Zhou et al., 2017). One article (Korshunova et al., 2017) proposed the transformation of the original face image into a fake image using a face-swap process. However, it preserves facial expressions, lighting, and position of images from the source to the destination of the image. The first deepfake video was released in 2017 in which a celebrity face was swapped with the face of a porn actor. Additionally, deepfake videos of famous politicians were created as fake speeches. It is a great threat to the world for the preservation of the security and privacy of world-famous actors and politicians (Howcroft, 2018; Chesney & Citron, 2019; Soare & Burton, 2020). Identifying the original face image from the deepfake video is evaluated based on the properties of deepfake videos, which undergo an affine warping process to match the face of the original image (Li & Lyu, 2019).
Fake face videos are exposed using deep-generative networks based on eye blinking features. To achieve this, it detects the faces frame by frame and aligns them with the same coordinate value and observes head movement in a realistic manner (Li, Chang & Lyu, 2018). From each frame of a video, eye blinking is detected using the long-term recurrent convolutional neural network (LRCN) method. In this LRCN method, the swapping of the face in the videos is implemented more easily. A pipeline-based temporal-aware system was proposed to detect deepfake videos automatically. Features are extracted in the form of a frame by a frame (Güera & Delp, 2018). Table 1 shows the results of a survey of the deepfake detection methods.
| Author | Classifier | Type of input | Dataset |
|---|---|---|---|
| Hsu, Zhuang & Lee (2020) | CNN concatenated to CFFN | Image | CelebA, DCGAN WGAN WGAN-GP, least squares GAN PGGAN. |
| Chintha et al. (2020) | Convolutional bidirectional recurrent LSTM network | Videos | FaceForensics++ and Celeb-DF (5,639 deepfake videos) and the ASVSpoof Access audio dataset. |
| Agarwal et al. (2020) | CNN | Videos | Four in-the-wild lip-sync deep fakes from Instagram and YouTube (www.instagram.com/bill posters ukand youtu.be/VWMEDacz3L4). |
| Fernandes et al. (2020) | ResNet50model [102], pretrained on VGGFace2 | Videos | VidTIMIT and two other original datasets obtained from the COHFACE and Deepfake TIMIT datasets. |
| Sabir et al. (2019) | Spatiotemporal features with RCN | Videos | FaceForensics++ dataset, including 1,000 videos. |
| Xuan et al. (2019) | DCGAN, WGAN-GP and PGGAN. | Images | CelebA-HQ, DCGAN, GAN-GP and PGGAN |
| Yang, Li & Lyu (2019) | SVM | Videos/Images | UADFV consists of 49 deepfake videos, and 252 deepfake images from DARPA MediFor GAN Image/Video Challenge. |
| Nguyen, Yamagishi & Echizen (2019) | Capsule networks | Videos/Images | The Idiap Research Institute replayattack, facial reenactment FaceForensics. |
| Afchar et al. (2018) | CNN | Videos | Deepfake one constituted from onlinevideos and the FaceForensics one created by the Face2Face approach. |
| Güera & Delp (2018) | CNN and LSTM | Videos | A collection of 600 videos obtained from multiple websites. |
| Li, Chang & Lyu (2018), Li & Lyu (2019) | LRCN | Videos | Consists of 49 interview and presentation videos, and their corresponding generated deepfakes. |
Proposed Methodology
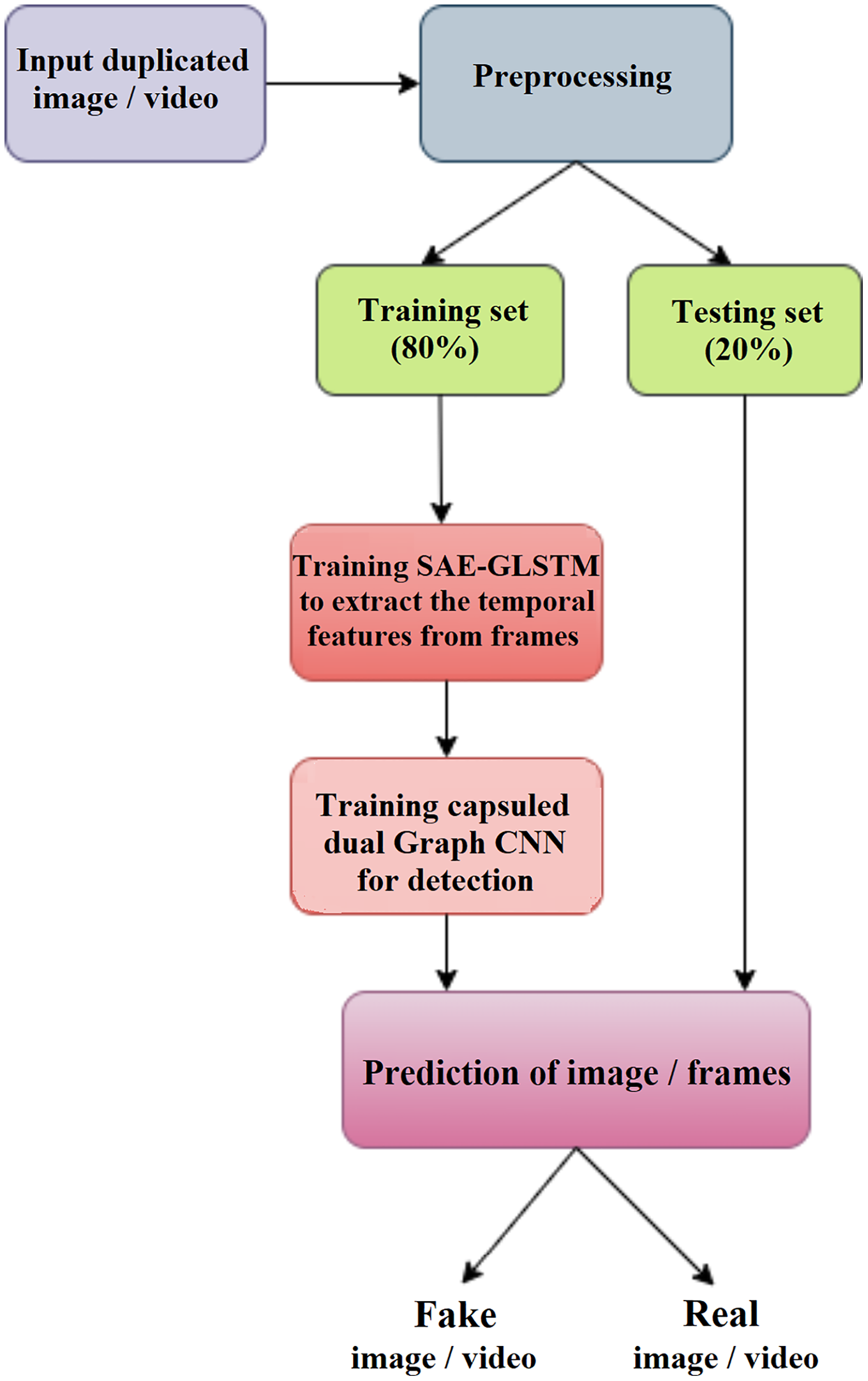
The proposed deepfake detection method shown in Fig. 1 is suitable for video and images. In the pre-processing phase, the deepfake video input is split into frames, and detection is performed from the frames. During the training phase, the features of the video frames or images are extracted using the graph LSTM method. The extracted feature subset is given as input to phase II for detection using a capsule network, the capsule dual graph CNN, which identifies the frame sequence/image as real or fake.

Figure 1: Overview of proposed DeepFake detection system.
{kind=link}
Preprocessing
The preprocessing of fake videos/images is shown in Fig. 2. Initially, the input fake videos are split into frames. Using multitask cascaded convolutional neural networks (MTCNNs) (Zhang et al., 2016), the face is detected and cropped from video frames. MTCNN is a Python face detection module with an accuracy of 95%. It can extract the face that focuses on computer vision transformation. This extracted face is pre-processed using the sequence of operations listed below to enhance image quality. The feature vector was generated by extracting the computer vision features from the preprocessed image using the graph LSTM method.

Figure 2: Proposed stages of preprocessing.
{kind=link}
Image rescaling
The input image/frames consist of RGB values in the range of 0 to 255. The values are rescaled to the interval [0,1] to be fed as input into the proposed model using the 1/255 scaling method.
Shear mapping
Each image in the frames is converted from the edge to the vertical direction. From the original frame, this parameter controls the angle of deviation of the horizontal line and the displacement rate. The value of the shear range is 0.3.
Noise removal
Accurate noise removal of input data will build up the improved quality training data set. This will improve the accuracy of the detection system. The background noise of the normalized image is removed using an adaptive median filter. An adaptive median filter solves issues related to median filters, such as the capability of the median filter to remove only salt and pepper noise. If there is no proper kernel size smoothing and if the spatial density is high, then the median filter is not effective. Various adaptive median filters are suitable for kernels with variable sizes, and all pixels are not replaced with median values. In Algorithm 1, we follow Soni & Sankhe (2019), in which the idea of a two-level median filter appeared. This algoritm consists of two steps. For each kernel, the median value is calculated and the pixel value of salt and pepper noise is checked. We consider the input grayscale image with pixel dimensions m × n. We assume that this image is given as the matrix G of the gray levels of all pixels in the image, so G = (gx,y), where , , and gx,y is a gray level of the pixel in the coordinates (x,y). Algorithm 1 will transform the input gray level gx,y of the pixel in the coordinates (x,y) into the noise removed value of the gray level of this pixel. The method of transformation of the value gx,y is done in the construction of all s-neighborhoods Us of the pixel in coordinates (x,y) (this pixel lies in the center of these squre-neighborhoods) with the side of this square equal to s (the initial value is s = 3) and we manage this transformation in two levels LA and LB, in which we compare the value gx,y with the minimal, maximal, and median grayscale values of all pixels in neighborhood Us for s ≥ 3. The exact procedure of Algorithm 1 is evident from the pseudocode below; only we must realize that for the smallest s-neighborhood with the side s = 3, the pixel inside the image has eight adjacent pixels, but the pixels in the corners have only three neighbors, and the other pixels at the edge of the image have five neighbors.
| Input: The gray level gx,y of the pixel at the coordinates (x,y), the maximal value smax of the side of the square Us. |
| Output: The noise removed value of the gray level of the pixel in the coordinates (x,y). |
| Step 1: Assume that LA and LB are the two levels of noise pollution. |
| Step 2: Consider a s-neighborhood Us. Initially, we take s = 3. |
| Step 3: Calculate gmed, gmin, gmax as the median, minimal, and maximal gray level of the pixels in Us. |
| Step 4: Level LA. |
| Step 5: if (A11 > 0 && A12 < 0) then go to Step 11. |
| Step 6: else s = s + 2 // We increase the size of s-neighborhood Us (s must be an odd number, as the pixel (x,y) must be in the center). |
| Step 7: end if |
| Step 8: if s ≤ smax then go to Step 4. |
| Step 9: else Output: . |
| Step 10: end if |
| Step 11: Level LB. |
| Step 12: if (B11 ≥ 0 && B12 ≤ 0) then Output: . |
| Step 13: else Output: . |
| Step 14: end if |
Data augmentation
During the training process, the augmentation method is as follows:
Zooming augmentation: zooming augmentation is used to view the input image as larger with the value 0.2 in the range [0.8, 0.2]. The parameter values vary from the 1 − value to the 1 + value.
Horizontal flipping: with the help of Boolean value ‘true’, the zoomed image is horizontally flipped.
Random rotation of approximately 30°.
Random contrast, brightness and saturation jitter.
Coarse dropout with the size of 0.03.
Feature extraction using the sparse autoencoder (SAE) with graph LSTM
The pre-processed image is fed into this section to extract the computer vision features using the proposed sparse autoencoder-based LSTM model. The traditional auto-encoder method has some problems, such as its inability to find features by copying memory into an implicit layer (Olshausen & Field, 1996). This problem is resolved with a sparsity approach with an autoencoder called a sparse autoencoder (SAE) (Hoq, Uddin & Park, 2021). It is an unsupervised deep learning method with a single hidden layer (Kang et al., 2017) used to encode the data for feature extraction. This will extract the most relevant features from the expressions of the hidden layer and estimate the error (Leng & Jiang, 2016). The regularization equation for the sparsity is defined in Eq. (1).
(1) where the divergence implemented is the Kullback-Leibler divergence (KL), is the activation function of the hidden node ith, ϑ is the sparsity parameter. The KL-divergence is mathematically defined by Eq. (2)
(2)
The sparse AE is trained with the cost function declared in Eq. (3) which consists of the mean square error defined in Eq. (4). This will reconstruct the input vector X into the output vector throughout the entire training dataset (Ng, 2011). The LASSO regression term is declared in Eq. (3) and the final term of the sparsity transformation is defined in Eq. (1). The importance of LASSO regression in SAE is to extract the most relevant features by assigning the feature coefficients as zero for features that are of little relevance, which will reduce the space of the parameter.
(3)
(4)
(5) where N is the total number of input data points, X represents the input vector, represents the reconstructed output vector, α is the Lasso regression coefficient and β is the sparsity regularization coefficient, l indicates the lth layer, nl is the number of layers, ul is the number of units in the layer l and wlij is the weight value between the ith node of the layer l and the jth node of the layer l + 1. LASSO regression can add the magnitude of the absolute value as a penalty term. To improve the feature extraction process, this penalty coefficient is set to zero. The LSTM trains SAE to improve the feature extraction process. An LSTM is a backpropagation method for training the feature extraction model with three gates: input, forget, and output gates. The input gate is responsible for modifying the memory with the values decided by the sigmoid activation function. The forget gate is used to discard features from the previous state. The output gate is used to control the output features. Traditional LSTM is enhanced with a graph structure in which each node of the graph is represented as a single LSTM unit with forward and backward directions. In one direction, the node history is constructed and in another direction the response is characterized. Figure 3 shows the proposed SAE-GLSTM model to extract deepfake image features.

Figure 3: Deep fake image feature extraction using proposed SAE-GLSTM network.
{kind=link}
An SAE consists of an encoder, a compression/parameter space, and a decoder. The encoder encodes the given input to the parameter space through hidden layers, and the decoder is responsible for decoding the parameter space data to the output layer. Due to the autoencoder nature of dealing with negative values, a rectified linear unit (ReLU) is not suitable, and a sigmoid function is used as an activation function, which will reduce the training ability of the network. SAE can reduce the error between the input and the reconstructed data. The usage of hidden layers is reduced by the sparsity constraint. The regularization used here will avoid the overfitting issue and can be applied to larger datasets. The selected features are then passed on to the LSTM cell to enhance the feature selection process by extracting the relevant features. The LSTM graph model comprises six layers: the input layer, four hidden layers, and the output layer. The input layer of the LSTM graph consists of the features extracted from SAE. Each feature is represented as a neuron in the LSTM graph cell input layer graph, as shown in Fig. 4.

Figure 4: GLSTM cell.
{kind=link}
For the number of iterations t, SAE-GLSTM computes the hidden forward sequence as and the hidden backward sequence as , and the output sequence is represented as Y. The input xt has a hierarchical timing layer and the transition of the node state is declared a vector using the standard LSTM (Zhou, Xiang & Huang, 2020). Figure 5 shows the hierarchical forward and backward timing structure of Graph LSTM.

Figure 5: Hierarchical timing structure of (A) forward GLSTM (B) backward GLSTM.
{kind=link}
Let p(t) be considered the parent node of t and k(t) be the first child node. This hierarchical timing structure has predecessor p(t) and successor s(t) representing the forward and backward siblings, respectively. If there is no child, the values of k(t), p(t), and s(t) are set to null. For the forward GLSTM, the parameters, such as the input gate ig, temporal forget gate fg, hierarchical forget gate hg, cell c, and the output op, are updated and represented in Eqs. (6) to (10) with the vectors igt indicating the new information weight, fgt indicating the memory data of siblings, hgt indicating the memory data of the parents, and σ representing the sigmoid function. For the backward GLSTM, is replaced by k(t), p(t) is replaced by s(t) and is represented in Eqs. (11) to (15) listed in Table 2.
| Forward sequence | Backward sequence |
|---|---|
| (6) | (11) |
| (7) | (12) |
| (8) | (13) |
| (9) | (14) |
| (10) | (15) |
The extracted features from SAE are enhanced with the LSTM graph by sending the SAE output as input to the LSTM unit. The optimal relevant feature subset has been selected as an output of this graph LSTM network. The extracted feature subset has numerical values of specific images in matrix form.
Deepfake detection using capsule dual graph CNN
The proposed detection system consists of three capsules. Two capsules are allotted for output to indicate fake and real images. CNN dual graph is represented in one capsule to perform detection. The features extracted from “Feature Extraction using the Sparse Autoencoder (SAE) with Graph LSTM” are given as input to this detection model. The dual graph neural network is the variance of the traditional neural network with a graph (Scarselli et al., 2008). Each node in the graph is a feature. A dual graph CNN consists of two CNNs and the input set of data points , the set of labels , the first l points have labels , and a graph structure. We assume that each point has at most k features; therefore, we denote the data set as a matrix and represent the structure of the graph by the adjacency matrix . Using the input X, labels L, and A, our model aims to predict the labels of the unlabeled points.
The model is constructed with local consistency (LC) and is a type of feed-forward network that incorporates global consistency (GC) and a regularizer for the ensemble. The feature vector FV and the adjacency matrix A are the inputs of the DGCNN model. The local consistency output for the hidden layer i of the network Z(i) is declared in Eq. (16) (Kipf & Welling, 2017)
(16) where is the adjacency matrix A with self-loops, In is the identity matrix, and . Therefore, is the normalized adjacency matrix, Z(i−1) represents the output of the (i − 1)th layer, Z(0) = X W(i) represents trainable parameters of the network, and σ indicates the activation function (ReLU). The output of the DGCNN can be visualized on the Karate club network, as shown in Fig. 6. The red color of this network indicates a labeled node and the green color indicates an unlabeled node. The local consistency network is optimized with PPMI (positive point-wise information) in the global consistency layer.

Figure 6: Karate club network for LC convolution (Kipf & Welling, 2017).
{kind=link}
Global consistency is formed with PPMI to encode semantic information and is denoted as a matrix . Initially, the frequency matrix FM is calculated by random walk and on the basis of FM we calculate the matrix P. Furthermore, we define the convolution function ConvGP based on P. We can calculate the matrix FM as follows: A random user can choose the random path. If the random user is at node xi at time t, we define the state as s(t) = xi. We set the probability of transition from node xi to one of its neighbors xj by
(17)
The frequency matrix is computed for all pairs of nodes and the path is calculated by random walk. The ith vector of the frequency matrix is the ith node and jth node is the jth column of the frequency matrix. This is called context cj. This frequency matrix is used to calculate the PPMI matrix P, as shown in Eqs. (18) to (21).
(18)
(19)
(20)
(21) where pi,j is the estimated probability that node xi occurs in context cj, pi,* is the estimated probability of node xi, and p*,j is the probability of context cj, thus,
The PPMI matrix P increases the relationship between data points compared to the adjacency matrix A. Using the PPMI matrix, global consistency is calculated in Eq. (22)
(22) where P represents the PPMI matrix and for normalization. To combine the local and global consistency convolution for the dual graph convolutional network, a regularizer was used. The loss function with this regularizer is represented in Eq. (23)
(23)
(24) where c is the number of different labels for prediction, is the output given by ConvLC, is the output of the softamax layer, yL represents the set of data indices whose labels are observed for training and is the ground truth.
(25) where is the output of applying the softmax activation function given by ConvGC (the vectors are ith columns of the matrices , , respectively). For the calculations of and , the activation function called ReLU was used. After applying the activation function, the output matrix is represented as and . The structure of the CNN dual graph capsule is shown in Fig. 7. This proposed network consists of three main capsules. Each capsule consists of a dual graph CNN and two capsules to represent real and fake images or videos. The output of each CNN capsule called OCj|i is directed through dynamic routing to produce the detected output Oj for r iterations, as mentioned in Algorithm 2.

Figure 7: Capsule dual graph CNN structure.
{kind=link}
| Input: FM, A, PPMI, yL, r, λ(t) and hidden convolution layers (H) |
| Output: Training model with best features. |
| Step 1: for t in range (0, Epoch number) do |
| Step 2: using Eq. (16) |
| Step 3: using Eq. (22) |
| Step 4: Compute Loss using Eq. (23) |
| Step 5: if convergence then break loops |
| Step 6: end if |
| Step 7: end for |
| Step 8: Dynamic routing procedure (OCj|i,W′,r). // Where is the matrix of wights. |
| Step 9: |
| Step 10: for all input capsules i and all output capsules j do |
| Step 11: squash (OCj|i)) // Where . |
| Step 12: end for |
| Step 13: for all input capsules i and all output capsules j do |
| Step 14: |
| Step 15: end for |
| Step 16: for r iterations do |
| Step 17: for all input capsules i do |
| Step 18: for all output capsules j do |
| Step 19: for all output capsule networks i do // Where . |
| Step 20: for all input capsules i and output capsules j do |
| Step 21: |
| Step 22: end for |
| Step 23: Return Oj |
| Step 24: end for |
Experimental Result and Discussions
The proposed deep learning-based deepfake detection system with an efficient feature extraction and detection process is tested with fake and real images of public datasets such as FFHQ (Li & Lyu, 2019), 100K-Faces (Li, Chang & Lyu, 2018), Celeb-DF (V2) (Kipf & Welling, 2017) and WildDeepfake. The proposed system is implemented using the machine learning library called PyTorch.
Dataset description
Flickr-Faces-HQ, FFHQ
Flickr-Faces-HQ, FFHQ, is a dataset that contains a group of 70,000 face images with a high-quality resolution generated by generative adversarial networks (GANs).
100K-Faces
The 100K-Faces dataset contains 100,000 unique human face images generated using StyleGAN.
Celeb-DF (V2)
It is a large-scale video dataset with 590 real videos of celebrities and high-quality deepfakes of 5,639 videos constructed using a synthesis process with respect to over two million frames. Real videos gathered from YouTube videos and fake videos are created by swapping each pair of faces.
WildDeepfake
It is a real-world deepfake detection dataset collected from the Internet. The subjects of this dataset are real and fake, and they are collected from the internet sources and consist of various scenes. Each scene consists of more persons with rich facial expressions.
Evaluation metrics
The proposed SAE-GLSTM-based capsule dual graph CNN deepfake detection is evaluated with various evaluation metrics, such as accuracy, sensitivity, specificity, ROC and error detection rate. The deepfake detection system is compared to standard deepfake detection approaches such as VGG19 (Zi et al., 2020; Simonyan & Zisserman, 2015; Zagoruyko & Komodakis, 2016; Sandler et al., 2018).
Accuracy
(26)
Sensitivity
(27)
Specificity
It is used to evaluate the rate between true negatives (TNs) and true positives (TPs)
(28)
The comparison of the accuracy of the proposed SAE-GLSTM-C-DGCNN deepfake detection is shown in Table 3 for various datasets. With the baseline of various approaches such as VGG19, ResNet, and MobileNet, we experimented with the proposed efficient deepfake image/video feature extraction with CNN capsule dual graph CNN for various datasets. For the FFHQ datasets, existing and proposed systems obtained accuracies of 84.5%, 88.32%, 91.15%, and 96.92%. For 100K-Faces datasets, the approaches obtained the corresponding accuracies of 74.12%, 80.11%, 90.21%, and 97.15%. For the Cele-DF dataset, the accuracy values are 88.43%, 89.32%, 90.01%, and 98.12%, and for the WildDeepfake dataset, they are 89.25%, 86.52%, 96.75%, and 98.91%. The results showed that the proposed system achieved better percentage results compared to traditional deepfake detection systems.
| Methods | Datasets | |||
|---|---|---|---|---|
| FFHQ | 100K-Faces | Celeb-DF | WildDeepfake | |
| VGG19 | 84.5 | 74.12 | 88.43 | 89.25 |
| ResNet | 88.32 | 80.11 | 89.32 | 86.52 |
| MobileNet | 91.15 | 90.21 | 90.01 | 96.75 |
| Proposed SAE-GLSTM-CDGCNN | 96.92 | 97.15 | 98.12 | 98.91 |
The sensitivity, specificity, and ROC comparisons of various deepfake detection systems are evaluated using four different datasets, and the results are shown in Table 4 and Fig. 8.

Figure 8: ROC value comparison.
{kind=link}
| Datasets | Sensitivity % | Specificity % | ||||||
|---|---|---|---|---|---|---|---|---|
| VGG19 | ResNet | Mobile- Net | Proposed SAE-GLSTM-CDGCNN | VGG19 | ResNet | Mobile- Net | Proposed SAE-GLSTM-CDGCNN | |
| FFHQ | 87.3 | 81.6 | 84.2 | 91.67 | 84.23 | 86.1 | 85.2 | 92.4 |
| 100K-Faces | 86.2 | 83 | 85.6 | 89.8 | 84.2 | 86.2 | 89.54 | 93.5 |
| Celeb-DF | 84.9 | 88.3 | 83.7 | 89.1 | 87.1 | 87.1 | 89.1 | 94.2 |
| WildDeepfake | 91.2 | 85.3 | 90.1 | 93.1 | 86.1 | 89.4 | 86.3 | 95.2 |
Table 4 shows the sensitivity and specificity analyzes of the proposed SAE-GLSTM with the C-DGCNN system compared to the existing algorithms and various datasets from FFHQ, 100K-Faces, Celeb-DF, and WildDeepfake. The proposed SAE-GLSTM with C-DGCNN obtained a sensitivity score of 91.67% in the FFHQ dataset, 89.8% in the 100K-Faces dataset, 89.1% in the Celeb-DF dataset and 93.1% in the WildDeepfake dataset. Similarly, the specificity of the proposed SAE-GLSTM with the C-DGCNN achieved a score of 92.4% in the FFHQ dataset, 93.5% in the 100K-Faces dataset, 94.2% in the Celeb-DF dataset, and 95.2% in the WildDeepfake dataset. The proposed deepfake detection of fake video/images obtained improved sensitivity and specificity percentages compared to other existing approaches. Figure 8 shows the comparison of the ROC values of various deapfake detection systems with various datasets. From the analysis, the proposed system obtained an improved ROC value of 94.2% for the FFHQ dataset, 94.1% for the 100K-faces dataset, 96.12% for the Celeb-DF dataset, and 86.54% for the WildDeepfake dataset. On the contrary, the baseline VGG19 system obtained ROC values for the FFHQ, 100K-Faces, Celeb-DF, and WildDeepfake datasets of 83.1%, 85.1%, 95.53% and 61.12%, respectively, the baseline ResNet approach secured ROC values of 79.2%, 82.3%, 88.47% and 69.78%, respectively, and the baseline MobileNet approach obtained ROC values of 81.2%, 84.1%, 91.72% and 61.54%, respectively. From the comparison, the proposed deapfake detection system secured an improved ROC value compared to traditional baseline systems.
The error detection rate comparison of the proposed vs existing approaches is shown in Table 4 evaluated on the FFHQ, 100K-Faces, Celeb-DF, and WildDeepfake datasets. These datasets are used in both the training and testing processes by using the deepfake detection classifier baseline methods namely, VGG19, ResNet, and MobileNet, with our proposed work of SAE-GLSTM with the C-DGCNN model. Table 5 shows that the proposed approach obtained a minimum error rate of 5.1 for the WildDeepfake dataset, 7.12 for Celeb-DF, 6.01 for 100K-Faces and 5.91 for FFHQ datasets. The error rate is minimal compared to the baseline deepfake detection methods such as VGG19, ResNet, and MobileNet.
| DF detection methods | Datasets | |||
|---|---|---|---|---|
| FFHQ | 100K-Faces | Celeb-DF | WildDeepfake | |
| VGG19 | 13.11 | 18.32 | 12.3 | 11.4 |
| ResNet | 13.4 | 15.2 | 12.1 | 11.2 |
| MobileNet | 11.2 | 14.22 | 11.65 | 9.21 |
| Proposed SAE-GLSTM-CDGCNN | 5.91 | 6.01 | 7.12 | 5.1 |
Figure 9 illustrates the equal error rate (EER) of various approaches with respect to various datasets. The proposed deapfake detection system secured a minimum EER of 1.9 for the WildDeepfake dataset, 1.67 for the Celeb-DF dataset, 2.1 for the 100K-Faces dataset and 1.32 for the FFHQ dataset. These EERs are minimal compared to traditional baseline systems such as VGG19, ResNet and MobileNet.

Figure 9: EER comparison of DF detection systems.
{kind=link}
Figure 10 shows the comparison of computational time. The proposed system secured 8.1 ms for the WildDeepfake dataset, 10.3 ms for Celeb-DF, 12.1 ms for 100K-Faces and 21.2 ms for the FFHQ dataset. This is minimal compared to other traditional baseline deepfake detection systems, where VGG19 secured computational times for the datasets of 24.2, 34.12, 44.24 and 54.23 ms. ResNet obtained 14.22, 23.45, 34.5, and 36.81 ms, MobileNet secured 30.2, 35.1, 40.2, and 44.4 ms. Therefore, all evaluation results have shown that the proposed SAE-GLSTM with CNN capsule dual graph improved sensitivity, specificity, accuracy, and minimum error rate, EER, and computation time. Ultimately, these findings have proven that the proposed system efficiently detects deepfake images/videos with improved accuracy and minimum error.

Figure 10: Computation time.
{kind=link}
Conclusion
This article demonstrated the two-level deep learning method for the detection of deepfake images and videos. From the frames extracted, face images are extracted for deepfake detection. The features of the face images are extracted using the proposed SAE method. The most relevant features are extracted by enhancing the SAE-based feature extraction with the graph LSTM approach. These relevant extracted features are then fed as input into the capsule network for the detection of deepfakes. There are five capsules, including three input capsules constructed from CNN graph and two output capsules to represent fake and real images or videos. Experimental analysis with various baseline deepfake detection approaches, such as VGG19, ResNet and MobileNet, using the benchmark deepfake image and video datasets, including FFHQ, 100K-Faces, Celeb-DF and WildDeepfake, demonstrated that the proposed two-level deepfake detection approach secures improved accuracy of 96.2%, 97.15%, 98.12% and 98.91%, respectively, on these datasets. The proposed system obtained an improved ROC value of 94.2% for the FFHQ dataset, 94.1% for the 100K-Faces dataset, 96.12% for the Celeb-DF dataset and 86.54% for the WildDeepfake dataset. In terms of the error rate, the proposed system secured the corresponding values of 5.91, 6.01, 7.12 and 5.1. The proposed system secured the computational time as 8.1 ms for the WildDeepfake dataset, 10.3 ms for Celeb-DF, 12.1 ms for 100K-Faces and 21.2 ms for the FFHQ dataset. Therefore, all evaluations have shown that the proposed two-level deepfake detection method is general and effective in detecting a wide range of fake videos and image attacks. In the future, the proposed system will be improved to defend against adversarial machine attacks with enhanced capabilities.