
Multiple comparisons of precipitation variations in different areas using simultaneous confidence intervals for all possible ratios of variances of several zero-inflated lognormal models
- Published
- Accepted
- Received
- Academic Editor
- Guobin Fu
- Subject Areas
- Statistics, Computational Science, Natural Resource Management, Environmental Impacts
- Keywords
- Precipitation variation, Ratio of variances, Bayesian approach, Parametric bootstrap approach, Simulation, Rainfall data, Beta prior
- Copyright
- © 2021 Maneerat and Niwitpong
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ) and either DOI or URL of the article must be cited.
- Cite this article
- 2021. Multiple comparisons of precipitation variations in different areas using simultaneous confidence intervals for all possible ratios of variances of several zero-inflated lognormal models. PeerJ 9:e12659 https://doi.org/10.7717/peerj.12659
Abstract
Flash flooding and landslides regularly cause injury, death, and homelessness in Thailand. An advancedwarning system is necessary for predicting natural disasters, and analyzing the variability of daily precipitation might be usable in this regard. Moreover, analyzing the differences in precipitation data among multiple weather stations could be used to predict variations in meteorological conditions throughout the country. Since precipitation data in Thailand follow a zero-inflated lognormal (ZILN) distribution, multiple comparisons of precipitation variation in different areas can be addressed by using simultaneous confidence intervals (SCIs) for all possible pairwise ratios of variances of several ZILN models. Herein, we formulate SCIs using Bayesian, generalized pivotal quantity (GPQ), and parametric bootstrap (PB) approaches. The results of a simulation study provide insight into the performances of the SCIs. Those based on PB and the Bayesian approach via probability matching with the beta prior performed well in situations with a large amount of zero-inflated data with a large variance. Besides, the Bayesian based on the reference-beta prior and GPQ SCIs can be considered as alternative approaches for small-to-large and medium-to-large sample sizes from large population, respectively. These approaches were applied to estimate the precipitation variability among weather stations in lower southern Thailand to illustrate their efficacies.
Introduction and Motivation
In early 2021, approximately 186,300 people in lower southern Thailand were affected by heavy rainfall resulting in flash flooding, landslides, and windstorms, as reported by Thailand’s Department of Disaster Prevention and Migration (DDPM) (Thailand, 2021). Four provinces in the lower southern region of Thailand were affected by flooding: Songkhla (60 households), Pattani (2,810 households), Yala (12,082 households), and Narathiwat (22,308 households). Meanwhile, landslides occurred in Yala and Narathiwat that affected approximately 57 households (Thailand, 2021). Unfortunately, these natural disasters resulted in deaths and injuries (David, 2021).
It would be possible to reduce the impact of natural disasters if governmental organizations had an early warning system that could be triggered to warn people in high-risk areas in advance of impending catastrophes. Rainfall dispersion data can provide essential information indicating imminent flooding when variation is high by analyzing historical precipitation data. Importantly, it could also be used to predict precipitation variation in each area. From the historical evidence of flooding in lower southern Thailand, the precipitation data in four areas are inflated with zero observations, while the non-zero precipitation records are log-normally distributed, as can be seen in An Empirical Application Section. These properties indicate that precipitation data obey the assumptions for a zero-inflated lognormal (ZILN) distribution and can be modeled accordingly.
The ZILN model, also referred to as the delta-lognormal model, is appropriate for modeling right-skewed data with a proportion of zero (Aitchison & Brown, 1963; Fletcher, 2008; Wu & Hsieh, 2014; Hasan & Krishnamoorthy, 2018; Maneerat, Niwitpong & Niwitpong, 2019). Variance is a dispersion measure of probability used in statistical inference for both point and interval (e.g., confidence interval: CI) estimation. Several researchers have formulated point and interval estimates via various approaches. For example, Burdick & Graybill (1984) established CIs for linear combinations of the variance components using the unbalanced one-way classification model and the Graybill-Wang procedure by considering the inequality of the design (Graybill & Wang, 1980). Ciach & Krajewski (1999) estimated the radar-raingauge difference variances which can be separated into the area-point ground raingauge originating from resolution difference between them, and the error of the radar area-average rainfall estimate. Another important approach for variance estimation is bootstrapping based on t-statistics to formulate nonparametric CIs for a single variance and the difference between variances, which was used to estimate the variance in insurance data for properties (Cojbasic & Tomovic, 2007). Bebu & Mathew (2008) used a modified single log-likelihood ratio procedure to construct CIs for the ratio of bivariate lognormal variances and applied it to compare variation in health care costs. Cojbasic & Loncar (2011) suggested Hall’s bootstrapped-t method for constructing one-sided CIs (lower and upper endpoint CIs) for the variances of skewed distributions and illustrated the efficacy of their method by analyzing revenue variability within the food retail industry.
Later, Herbert et al. (2011) suggested an analytical method for the difference between two independent variances that performed well even with small unequal sample sizes and highly skewed leptokurtic data; they used data from a randomized trial for a cholesterol-lowering drug to portray the efficacies of their proposed methods. Harvey & Merwe (2012) revealed that a Bayesian CI based on the highest posterior density outperformed one based on the equal-tailed interval for the variance of lognormal distribution with zero observations. Maneerat, Niwitpong & Niwitpong (2020) showed that the highest posterior density interval based on a probability matching prior produced the narrowest interval with correct coverage for comparing delta-lognormal variances; they applied it to estimate the difference between rainfall variability in the lower and upper northern regions of Thailand. Recently, Bayesian credible intervals based on a non-informative prior were presented by Maneerat, Niwitpong & Niwitpong (2021a) for the single variance of a delta-lognormal model that was used on daily rainfall records.
Nevertheless, no studies have yet been conducted on simultaneous CIs (SCIs) for pairwise comparisons of the variances of several ZILN models, and so we addressed our research toward filling this gap. Hence, we estimated all possible ratios of variances of several ZILN models by using SCIs based on Bayesian, parametric bootstrap (PB), and generalized pivotal quantity (GPQ) approaches. The reasons for choosing them are that the Bayesian and PB approaches can be used to construct CIs capable of handling situations with large differences in the variances and high proportion of zero values of delta-lognormal models, respectively (Maneerat, Niwitpong & Niwitpong, 2020), while CI based on the GPQ approach perform quite well when the variance was large maneeratEstimatingFishDispersal2020. Their efficacies were determined via simulation studies and precipitation data from four areas of the lower southern region of Thailand in terms of the coverage rate (CR), the lower error rate (LER), the upper error rate (UER), and the average width (AW).
Model and methods
Model
For h groups, di; i = 1, 2, …, h, denotes the probability of having zero observations while the remaining probability for non-zero observations, , follows a lognormal distribution denoted as with mean μi and variance . For random samples from the groups, let Yi = (Yi1, Yi2, …., Yini) denote a ZILN variate based on ni observations from group i with the probability density function given by (1)
For Yi = 0, the number of zero observations ni0 follows a binomial distribution with sample size ni and the probability of having zero observations di, where ni = ni0 + ni1, ni0 = #{j:Yij = 0} and ni1 = #{j:Yij > 0}; j = 1, 2, …, ni. For Yi > 0, Wi = lnYi are normally distributed with mean μi and variance . For a ZILN model, the maximum likelihood estimates of di, μi and are , and , respectively. For the ith group, the population variance of Yi is given by (2)
which can be log-transformed as . Considering the third term of Ti leads to obtaining when is large. Thus, the log-transformed variance of Vi can be approximated as (3)
Given , and from the observations, the estimates of Ti can be written as ; . Using the delta theorem, the variance of becomes (4)
In the present study, the parameter of interest is all pairwise ratios among the log-transformed variances of several ZILN models, which is defined as (5)
Its estimates can be obtained as ; ∀i ≠ k and i, k =1 , 2, …, h. From Eq. (4), the variance of can be expressed as (6)
where the covariance between and is because Yi = (Yi1, Yi2, …., Yini) comprise independent and identically distributed (iid) random vector from a ZILN model. Thus, we can obtain estimates of that are independent random variables. Using estimates and from the samples enables the estimated variance of to become
(7)
where and denote the estimated parameters of and , respectively.
Methods
To estimate λik, the SCIs are formulated based on Bayesian, GPQ and PB approaches.
The Bayesian approach
The essential feature of Bayesian approach is to use the situation-specific prior distribution that reflects knowledge or subjective belief about the parameter of interest; this is modified in accordance with Baye’s Theorem to yield the posterior distribution. Thus, CIs based on the Bayesian approach are derived by using the posterior distribution. In Bayesian theory, the CI is referred to as the credible interval because it is not unique on the posterior distribution. The following methods are used to define suitable credible intervals: the narrowest interval for a univariate distribution (the highest posterior density interval) (Box & Tiao, 1973); the interval when the probability of being below is the same as being above, which is sometimes referred to as the equal-tailed interval (Gelman et al., 2014); or the interval with the mean as the central point (assuming that it exists). In the present study, the SCIs based on the Bayesian approach were constructed based on the equal-tailed interval. Motivated by Maneerat, Niwitpong & Niwitpong (2020), the probability-matching-beta (PMB) and reference-beta (RB) priors were our choice for parameter in this study. Thus, Bayesian SCIs for λik were established as follows:
The PMB prior:
The probability-matching prior for is combined with the prior of as a beta distribution with ai = bi = 1/2. Thus, the PMB prior for can be defined as (8)
When updated with its likelihood, we obtain (9)
The respective marginal posterior distributions of are
(10) (11) (12)
which are denoted as , , and , respectively. Thus, the posterior of λ becomes (13)
where and . In agreement with Ganesh (2009), the 100(1 − α)% Bayesian-based SCI with PMB prior for λik is (14)
where stands for the (1 − α)th percentile of the distribution of .
The RB prior:
This is a non-informative prior derived from the Fisher information matrix (Maneerat, Niwitpong & Niwitpong, 2020). The RB prior of is defined as (15)
in which the prior of d′ is a beta distribution. When combined with its likelihood Eq. (9), the posterior of differs from the PMB prior as follows:
(16) (17)
Moreover, it can be similarly denoted as , and , respectively. The posterior of λik is , where and . According to Ganesh (2009), the 100(1 − α)% Bayesian-based SCI with the RB prior for λik is (18)
where stands for the (1 − α)th percentile of the distribution of .
The GPQ approach
Motivated by Wu & Hsieh (2014), the GPQ of di is formulated using the arcsin square-root transformation of the variance. Moreover, the GPQs for are also obtained from transformation of the normal approximation by using the central limit theorem (Tian, 2005; Hasan & Krishnamoorthy, 2017). The GPQ for Ti can be written as (19)
where . The random variables , and are independent from standard normal, normal and distributions, respectively. Thus, the corresponding GPQ of λik can be expressed as (20)
Similarly, denotes the GPQ of Tk; , , and . Therefore, the 100(1 − α)% SCI for λjk based on the GPQ approach is given by (21)
where denotes the (1 − α)th percentile of the QGPQ distribution; the QGPQ is derived as (22)
In agreement with Hannig et al. (2006), Kharrati-Kopaei & Eftekhar (2017), the asymptotic coverage probability of the SCI for λik based on the GPQ is slightly modified from that in Maneerat, Niwitpong & Niwitpong (2021b) (the proof of Theorem 1 in the Appendix).
Let . For Yi = 0, ni0 is binomially distributed with the proportion of zero inflation di = E(ni0/ni) . For Yi > 0, lnYi is log-normally distributed with mean μi = E(lnYi)and variance . Moreover, let λik = Ti/Tk; from group ibe the log-transformed variance of ZILN. Given yi = (yi1, yi2, …., yini), let be an approximated variance of , where are the estimates of (Ti, Tk). Suppose that ni/n → φi ∈ (0, 1) as , thus it follows that the asymptotically coverage probability of 100 (1 − α)% SCI for λjk based the GPQ approach is given by
for ∀i ≠ k and i, k =1 , …, h.
The PB approach
Here, we assume that the data come from a known distribution with unknown parameters that are estimated by using samples stimulated from the estimated distribution. In the present study, the PB approach is adjusted to suit our particular situation. Let , and be the observed values of , , and representing the estimated values of parameters di, μi, and , respectively. Thus, we can obtain the empirical distribution of T based on the PB approach. In accordance with Sadooghi-Alvandi & Malekzadeh (2014), the respective sampling distributions of (, , ) are
(24) (25) (26)where and are independent random variables with standard normal and Chi-square distributions, respectively. The PB variable-based pivotal quantity is expressed as (27)
where and . By replacing observed values from the samples, we respectively obtain
(28) (29) (30)
where and . Hence, the 100(1 − α)% SCI for λik based on the PB approach is (31)
where is the (1 − α)th percentile of the distribution of MPB. Theorem 2 shows the asymptotic coverage probability of the 100(1 − α)% SCI for λik based on the PB approach (see the proof in the Appendix ).
Suppose that Yi = (Yi1, Yi2, …., Yini) comprise an iid random vector from a ZILN model based on ni observations from population group i. Let be the estimate of λik, where and are the approximately log-transformed variances of and from the population groups ith and kth, respectively. Hence, (32) where is the estimated variance of ; ∀i ≠ k and i, k =1 , 2, .., h.
Simulation studies and results
Simulation studies were conducted to assess the performances of the SCIs based Bayesian, GPQ, and PB approaches for all pairwise ratios of variances of several ZILN distributions: Bayesian SCIs based on PMB and RB priors (Maneerat, Niwitpong & Niwitpong, 2020), the GPQ-based SCI (Wu & Hsieh, 2014), and the PB-based SCI (Sadooghi-Alvandi & Malekzadeh, 2014; Li, Song & Shi, 2015; Kharrati-Kopaei & Eftekhar, 2017). CRs, LERs, UERs, and AWs of the SCIs were determined when the population group size(h) were fixed at 3 and 5; the optimal values of CR, LER, UER, and AW are 95%, 5%, 5% and 0, respectively, which were used to judge the best-performing SCI. Critical values , , and for the Bayesian SCIs based on PMB and RB priors, GPQ and PB, respectively, were also assessed. Throughout the simulation studies, the simulation procedure to estimate the CRs, LERs, and UERs was as follows:
-
Generate random samples Yi = (Yi1, Yi2, …., Yini) from , and compute , ; i = 1, 2, …, h from the samples.
-
Compute the critical values for each method using 2500 Monte Carlo simulations.
-
Apply the SCIs based on Bayesian-based PMB and RB priors, GPQ, and PB approaches given in Eqs. (14), (18), (21) and (31), respectively, and record whether or not the values of (λik; i ≠ k) fall within their corresponding confidence intervals.
-
Repeat steps (i)-(iii) M = 5000 times.
-
For each method: obtain the number of times that all (λik; i ≠ k) are in their corresponding SCIs to estimated the CR.
-
Obtain the number of times that all (λik; i ≠ k) is less than or greater than their corresponding SCIs to estimate the LER and UER, respectively.
For the three-group comparison, the following parameter combinations were used: large variances ; small (30, 30, 30), moderate (50, 50, 50), large [(100, 100, 100) and (100, 100, 200)], small-to-large (30, 50, 100) and medium-to-large (50, 100, 200) sample sizes; and zero-inflation percentages of (10, 20, 30), (10, 30, 50) and (30, 50, 50). For the five-group comparison, the following parameter combinations were used: large variances =(1, 1, 2, 2, 3); small-to-large (30, 50, 50, 100, 200), medium-to-large (50, 50, 50, ) (100, 100), and large (70, 100, 100, 200, 200) sample sizes; and zero-inflation percentages of (10, 10, 20, 20, 20), (20, 20, 30, 30, 50) and (50, 50, 50, 70, 70). The results are reported in Table 1.
| ni | di(%) | B-PMB | B-RB | GPQ | PB | AW | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LER | CR | UER | LER | CR | UER | LER | CR | UER | LER | CR | UER | B-PMB | B-RB | GPQ | PB | ||
| 3 sample groups and | |||||||||||||||||
| (303) | (10,20,30) | 1.993 | 97.973 | 0.033 | 1.307 | 98.693 | 0.000 | 0.707 | 99.293 | 0.000 | 2.460 | 97.540 | 0.000 | 22.961 | 25.493 | 27.764 | 22.942 |
| (10,30,50) | 1.880 | 98.113 | 0.007 | 1.200 | 98.800 | 0.000 | 0.967 | 99.033 | 0.000 | 2.900 | 97.100 | 0.000 | 28.702 | 33.323 | 33.300 | 27.254 | |
| (30,50,50) | 1.120 | 98.873 | 0.007 | 0.427 | 99.573 | 0.000 | 0.620 | 99.380 | 0.000 | 2.520 | 97.480 | 0.000 | 30.764 | 35.737 | 36.813 | 29.113 | |
| (503) | (10,20,30) | 2.833 | 96.800 | 0.367 | 2.300 | 97.567 | 0.133 | 1.107 | 98.887 | 0.007 | 2.347 | 97.627 | 0.027 | 15.521 | 16.544 | 19.078 | 16.893 |
| (10,30,50) | 2.887 | 97.027 | 0.087 | 2.173 | 97.800 | 0.027 | 1.253 | 98.747 | 0.000 | 2.607 | 97.393 | 0.000 | 18.848 | 20.654 | 22.403 | 19.733 | |
| (30,50,50) | 2.087 | 97.840 | 0.073 | 1.413 | 98.567 | 0.020 | 0.973 | 99.027 | 0.000 | 2.320 | 97.673 | 0.007 | 20.104 | 21.996 | 24.567 | 21.096 | |
| (1003) | (10,20,30) | 3.480 | 95.140 | 1.380 | 3.200 | 95.693 | 1.107 | 1.273 | 98.527 | 0.200 | 1.960 | 97.767 | 0.273 | 10.015 | 10.325 | 12.448 | 11.681 |
| (10,30,50) | 3.660 | 95.627 | 0.713 | 3.200 | 96.420 | 0.380 | 1.427 | 98.540 | 0.033 | 2.087 | 97.833 | 0.080 | 11.866 | 12.410 | 14.327 | 13.422 | |
| (30,50,50) | 3.220 | 96.040 | 0.740 | 2.780 | 96.747 | 0.473 | 1.167 | 98.813 | 0.020 | 2.073 | 97.853 | 0.073 | 12.389 | 12.948 | 15.408 | 14.202 | |
| (30,50,100) | (10,20,30) | 1.787 | 96.753 | 1.460 | 1.367 | 97.453 | 1.180 | 0.380 | 99.480 | 0.140 | 1.127 | 98.467 | 0.407 | 12.846 | 13.402 | 16.552 | 14.152 |
| (10,30,50) | 1.853 | 97.127 | 1.020 | 1.387 | 97.993 | 0.620 | 0.420 | 99.553 | 0.027 | 1.420 | 98.353 | 0.227 | 14.348 | 15.042 | 18.368 | 15.604 | |
| (30,50,50) | 1.013 | 97.947 | 1.040 | 0.547 | 98.687 | 0.767 | 0.260 | 99.653 | 0.087 | 1.053 | 98.627 | 0.320 | 16.343 | 17.452 | 20.826 | 17.181 | |
| (50,100,200) | (10,20,30) | 2.580 | 94.773 | 2.647 | 2.247 | 95.293 | 2.460 | 0.467 | 99.047 | 0.487 | 0.847 | 98.307 | 0.847 | 8.637 | 8.822 | 11.261 | 10.230 |
| (10,30,50) | 2.847 | 95.073 | 2.080 | 2.593 | 95.560 | 1.847 | 0.667 | 99.093 | 0.240 | 1.313 | 98.140 | 0.547 | 9.522 | 9.725 | 12.334 | 11.166 | |
| (30,50,50) | 2.173 | 95.880 | 1.947 | 1.793 | 96.533 | 1.673 | 0.380 | 99.380 | 0.240 | 1.020 | 98.460 | 0.520 | 10.618 | 10.939 | 13.751 | 12.189 | |
| (1002,200) | (10,20,30) | 3.253 | 94.213 | 2.533 | 2.953 | 94.693 | 2.353 | 0.967 | 98.673 | 0.360 | 1.507 | 97.920 | 0.573 | 7.952 | 8.090 | 10.266 | 9.647 |
| (10,30,50) | 2.940 | 95.013 | 2.047 | 2.620 | 95.533 | 1.847 | 0.980 | 98.793 | 0.227 | 1.460 | 98.127 | 0.413 | 8.985 | 9.184 | 11.489 | 10.773 | |
| (30,50,50) | 2.567 | 95.387 | 2.047 | 2.227 | 96.007 | 1.767 | 0.900 | 98.893 | 0.207 | 1.547 | 98.047 | 0.407 | 9.888 | 10.197 | 12.666 | 11.709 | |
| 5 sample groups and | |||||||||||||||||
| (30, 502, 100, 200) | (10,10,20,20,20) | 0.326 | 99.504 | 0.170 | 0.232 | 99.626 | 0.142 | 0.344 | 99.568 | 0.088 | 0.756 | 99.002 | 0.242 | 6.224 | 6.471 | 6.310 | 5.600 |
| (20,20,30,30,50) | 0.244 | 99.620 | 0.136 | 0.154 | 99.754 | 0.092 | 0.244 | 99.694 | 0.062 | 0.666 | 99.164 | 0.170 | 6.952 | 7.250 | 7.067 | 6.201 | |
| (20,30,50,50,70) | 0.154 | 99.738 | 0.108 | 0.092 | 99.828 | 0.080 | 0.322 | 99.642 | 0.036 | 0.788 | 99.084 | 0.128 | 8.510 | 8.971 | 8.513 | 7.369 | |
| (50,50,50,70,70) | 0.062 | 99.882 | 0.056 | 0.026 | 99.942 | 0.032 | 0.116 | 99.872 | 0.012 | 0.426 | 99.490 | 0.084 | 9.572 | 10.226 | 9.861 | 8.223 | |
| (503, 1002) | (10,10,20,20,20) | 0.398 | 99.504 | 0.098 | 0.338 | 99.582 | 0.080 | 0.558 | 99.414 | 0.028 | 1.122 | 98.788 | 0.090 | 6.614 | 6.826 | 6.557 | 5.914 |
| (20,20,30,30,50) | 0.392 | 99.512 | 0.096 | 0.312 | 99.618 | 0.070 | 0.526 | 99.448 | 0.026 | 1.092 | 98.810 | 0.098 | 7.791 | 8.100 | 7.567 | 6.768 | |
| (20,30,50,50,70) | 0.358 | 99.618 | 0.024 | 0.244 | 99.748 | 0.008 | 0.582 | 99.398 | 0.020 | 1.196 | 98.754 | 0.050 | 10.067 | 10.737 | 9.488 | 8.354 | |
| (50,50,50,70,70) | 0.204 | 99.766 | 0.030 | 0.136 | 99.850 | 0.014 | 0.254 | 99.746 | 0.000 | 0.822 | 99.166 | 0.012 | 10.687 | 11.352 | 10.571 | 9.039 | |
| (70, 1002, 2002) | (10,10,20,20,20) | 0.784 | 99.038 | 0.178 | 0.710 | 99.140 | 0.150 | 0.810 | 99.120 | 0.080 | 1.232 | 98.640 | 0.128 | 4.499 | 4.565 | 4.507 | 4.237 |
| (20,20,30,30,50) | 0.666 | 99.174 | 0.160 | 0.580 | 99.280 | 0.140 | 0.620 | 99.310 | 0.070 | 1.058 | 98.826 | 0.116 | 5.218 | 5.321 | 5.116 | 4.783 | |
| (20,30,50,50,70) | 0.620 | 99.290 | 0.090 | 0.550 | 99.380 | 0.060 | 0.750 | 99.200 | 0.060 | 1.158 | 98.744 | 0.098 | 6.546 | 6.743 | 6.202 | 5.753 | |
| (50,50,50,70,70) | 0.374 | 99.548 | 0.078 | 0.310 | 99.630 | 0.060 | 0.370 | 99.600 | 0.030 | 0.680 | 99.258 | 0.062 | 6.938 | 7.139 | 6.892 | 6.249 | |
Notes:
Note: (1003, 2002) = (100, 100, 100, 200, 200). Bold denotes the best-performing method.
For h = 3 with large variance, Table 1 and Fig. 1 reveal that all of the methods provided CR performances close to and greater than the nominal confidence level (95%). Meanwhile, the SCIs based on the Bayesian approach based on the PMB prior and GPQ maintained a good balance between LER and UER. Importantly, the AW of PB was narrower than the other methods for small sample sizes, while those of the Bayesian approach based on the PMB prior were slightly narrower than the others for the other sample sizes. When a group comparison was h = 5 (Table 1 and Fig. 2), the PB approach provided the best CRs and narrowest AWs for all scenarios tested.
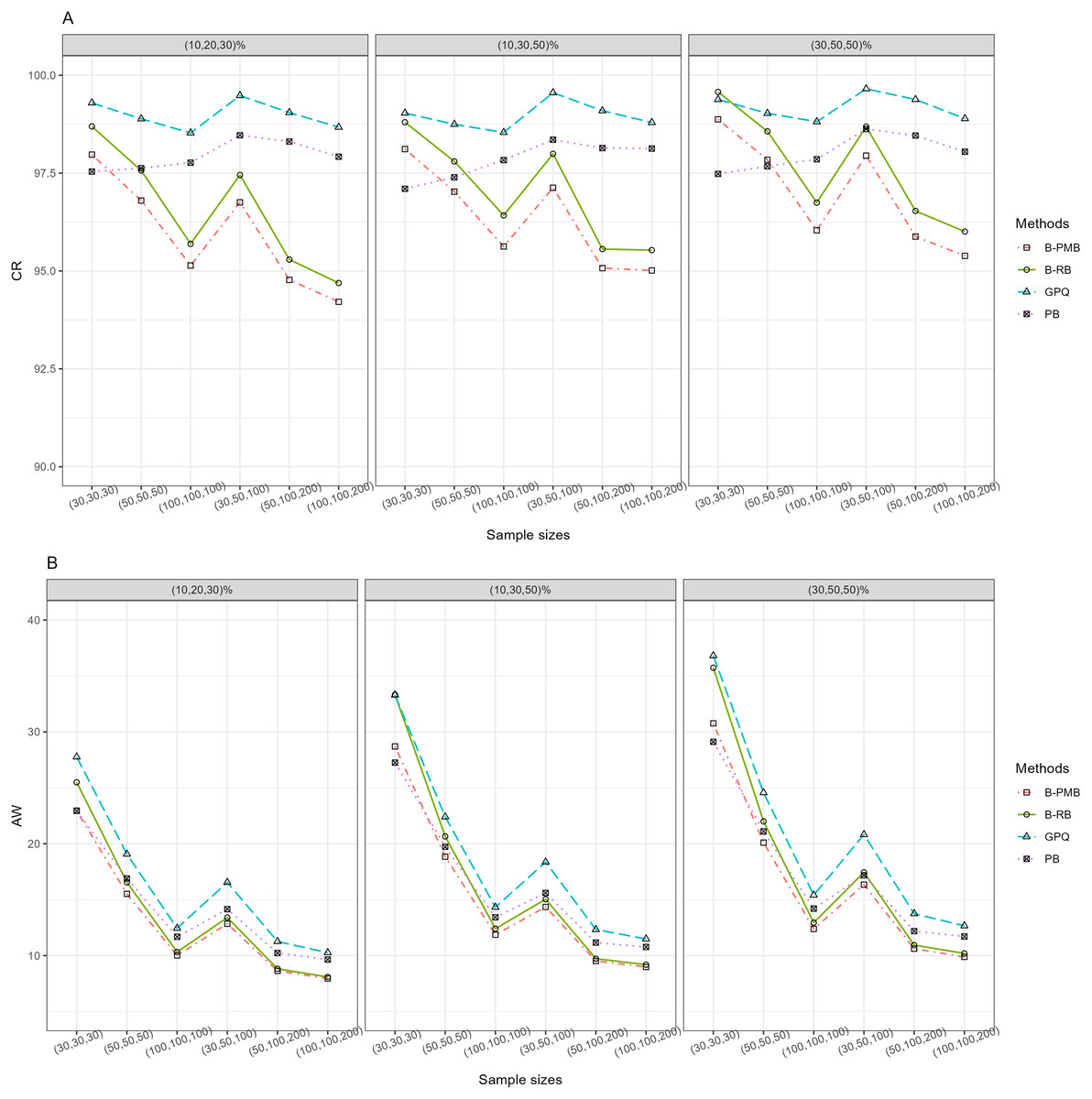
Figure 1: The CR and AW performance measures for three sample groups: (A) CR (B) AW.
{kind=link}
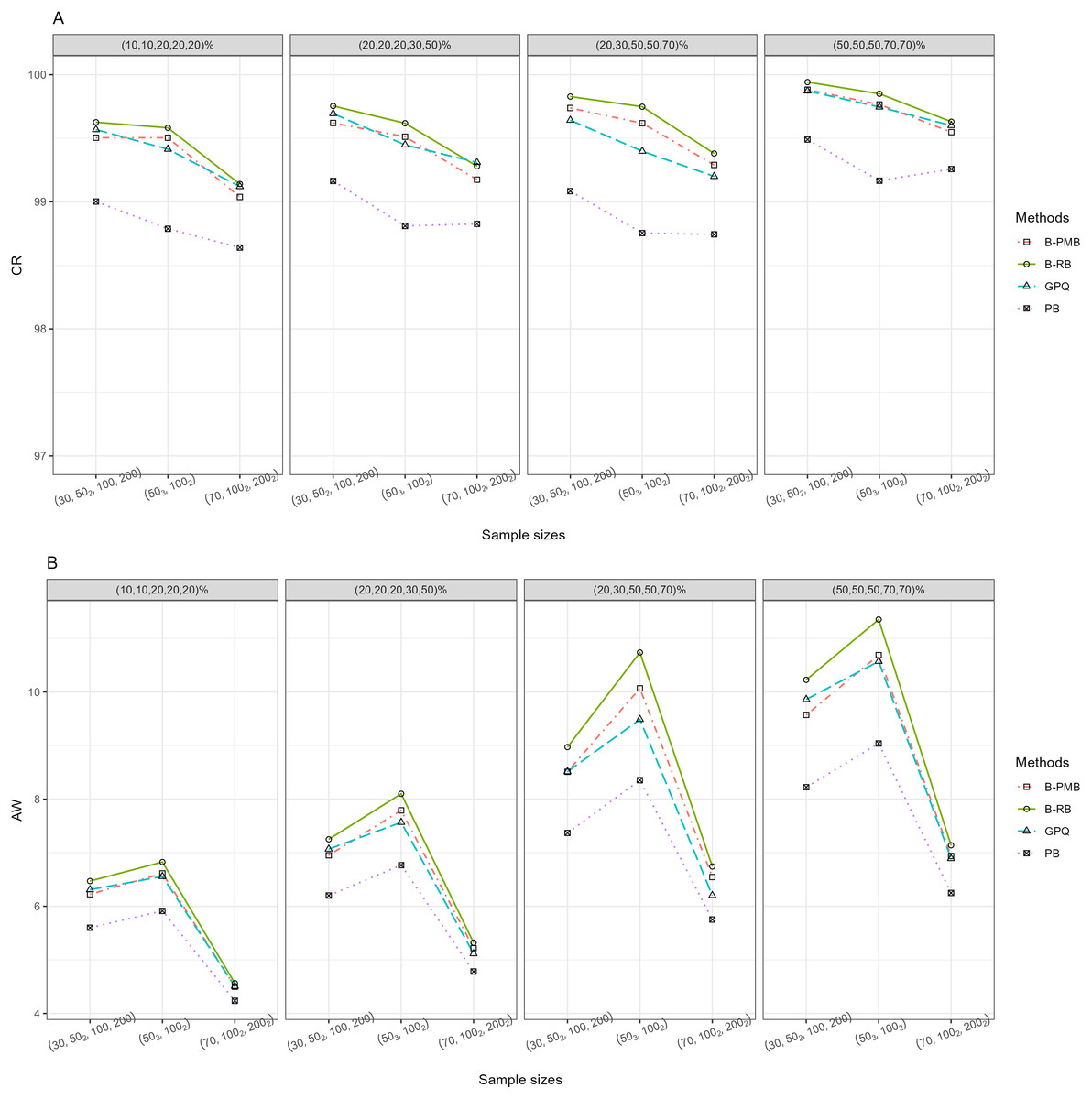
Figure 2: The CR and AW performance measures for five sample groups: (A) CR (B) AW.
{kind=link}
An empirical application of the four methods to daily precipitation data
Daily precipitation records comprise publicly available data from the Thailand Meteorology Department (Department, 2021). Flash floods, landslides, and windstorms caused by heavy rainfall occurred in the four provinces in the lower southern area of Thailand: Songkhla, Yala, Narathiwat, and Pattani during January 2021, as reported by Thailand’s Department of Disaster Prevention and Mitigation (Thailand, 2021). According to automatic weather system (Department, 2021), Songkhla has two weather stations in the Songkhla and Sadao districts, which means that we could simultaneously estimate variations in precipitation at five weather stations.
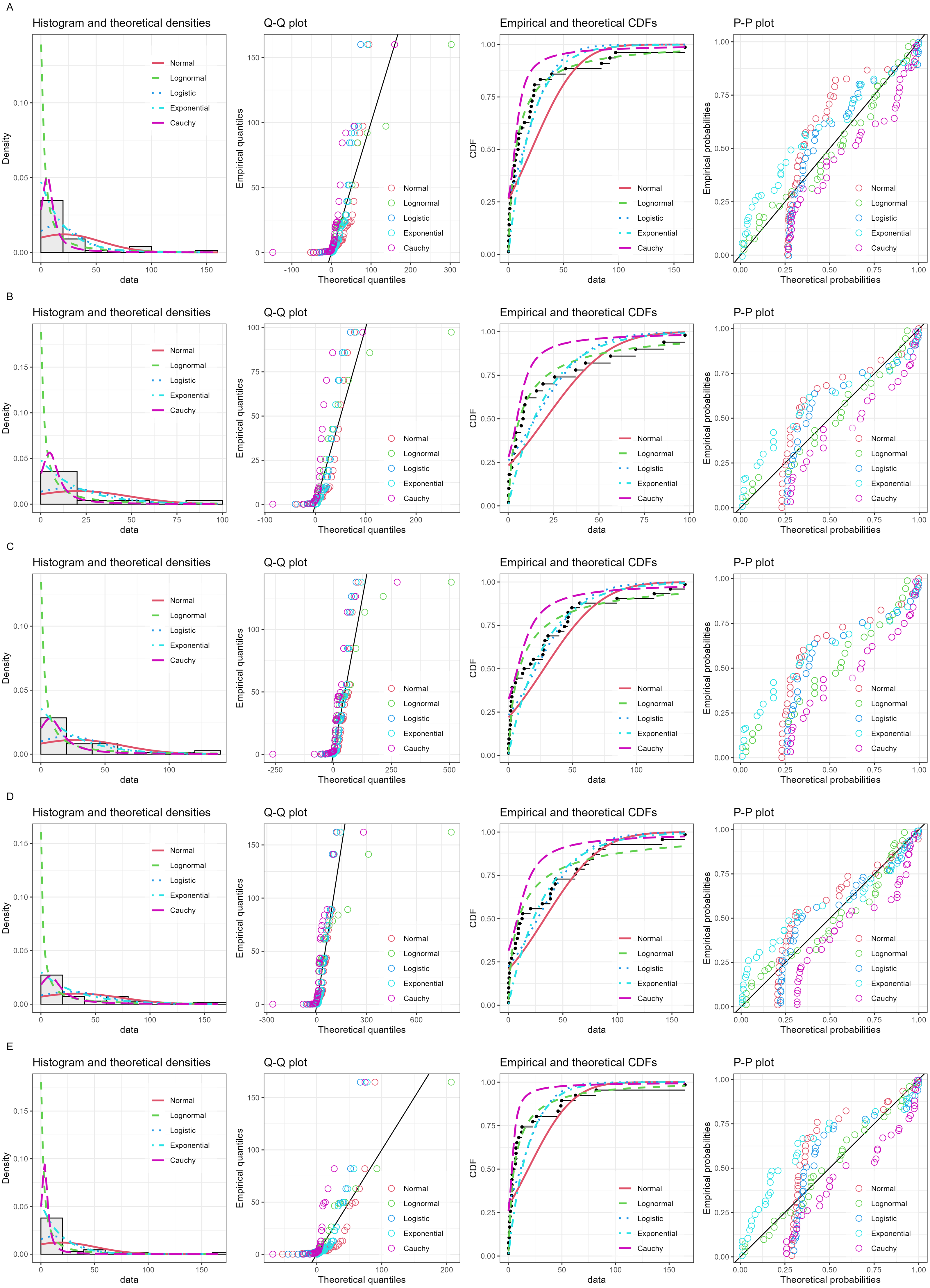
Daily precipitation data from December 2020 to January 2021 (Table 2) were used in the analysis. Figure 3 shows histogram along with normal quantile–quantile (Q-Q), cumulative density function (CDF) and probability-probability (P-P) plots. Furthermore, the Akaike information criterion (AIC) and Bayesian information criterion (BIC) values of five models: normal, logistic, lognormal, exponential, and Cauchy applied to fitting the non-zero precipitation data were compared to check the appropriateness of each model for fitting the data (Table 3). The AIC and BIC results for the lognormal model were the lowest, and thus it was the most efficient. The data from all of the stations were zero-inflated, thereby verifying that they follow the assumptions for ZILN.
| Dates | Weather stations: December 2020 | Dates | Weather stations: January 2021 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Shongklha | Songkhla-based Sadao district |
Yala | Narathiwat | Pattani | Shongklha | Songkhla-based Sadao district |
Yala | Narathiwat | Pattani | ||
| 1 | 160.0 | 56.4 | 46.4 | 38.6 | 82.0 | 1 | 0.8 | 4.2 | 6.6 | 31.2 | 0.8 |
| 2 | 14.6 | 85.8 | 46.6 | 70.0 | 0.0 | 2 | 1.4 | 8.2 | 5.6 | 6.4 | 2.0 |
| 3 | 20.8 | 4.2 | 55.8 | 74.2 | 0.0 | 3 | 2.6 | 42.6 | 49.6 | 38.6 | 49.8 |
| 4 | 8.8 | 0.2 | 27.0 | 0.4 | 7.2 | 4 | 21.4 | 8.4 | 28.6 | 10.4 | 4.4 |
| 5 | 0.0 | 0.0 | 0.2 | 0.0 | 0.0 | 5 | 9.2 | 70.2 | 137.8 | 62.8 | 49.0 |
| 6 | 0.0 | 0.0 | 0.0 | 0.0 | 0.2 | 6 | 0.2 | 2.8 | 84.8 | 13.2 | 0.2 |
| 7 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 7 | 0.0 | 0.0 | 1.8 | 9.2 | 2.8 |
| 8 | 0.2 | 0.0 | 1.6 | 0.0 | 0.0 | 8 | 0.4 | 0.0 | 0.4 | 0.0 | 1.2 |
| 9 | 52.0 | 0.0 | 0.0 | 0.0 | 0.0 | 9 | 0.8 | 0.0 | 0.0 | 1.4 | 0.0 |
| 10 | 39.4 | 0.0 | 0.0 | 0.8 | 3.6 | 10 | 29.0 | 15.6 | 2.8 | 12.6 | 22.8 |
| 11 | 0.6 | 0.0 | 2.8 | 9.2 | 9.8 | 11 | 23.0 | 0.6 | 0.2 | 0.2 | 0.0 |
| 12 | 12.2 | 4.2 | 17.2 | 0.0 | 8.0 | 12 | 5.0 | 0.2 | 0.6 | 3.6 | 1.2 |
| 13 | 5.4 | 37.2 | 2.0 | 8.2 | 12.8 | 13 | 0.0 | 0.0 | 2.4 | 3.0 | 1.0 |
| 14 | 9.4 | 0.0 | 0.0 | 0.0 | 3.4 | 14 | 5.4 | 0.0 | 0.0 | 0.0 | 0.0 |
| 15 | 7.0 | 2.4 | 12.4 | 78.4 | 7.2 | 15 | 1.8 | 0.0 | 0.0 | 0.0 | 0.0 |
| 16 | 19.2 | 25.6 | 43.8 | 43.0 | 62.8 | 16 | 0.8 | 0.0 | 0.0 | 0.0 | 0.0 |
| 17 | 84.4 | 97.4 | 126.4 | 162.0 | 164.8 | 17 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 18 | 97.2 | 9.2 | 113.8 | 141.2 | 46.4 | 18 | 0.0 | 0.0 | 0.0 | 1.2 | 0.0 |
| 19 | 92.0 | 19.2 | 39.8 | 43.6 | 26.2 | 19 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 20 | 19.8 | 7.2 | 27.8 | 20.4 | 7.0 | 20 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 21 | 5.4 | 0.4 | 0.0 | 0.2 | 3.4 | 21 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 22 | 0.0 | 0.0 | 1.2 | 1.0 | 3.4 | 22 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 23 | 23.8 | 0.0 | 31.0 | 61.4 | 12.6 | 23 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 24 | 23.4 | 0.0 | 19.6 | 6.6 | 0.0 | 24 | 0.0 | 0.0 | 2.2 | 0.0 | 0.0 |
| 25 | 2.2 | 0.0 | 46.6 | 39.8 | 6.8 | 25 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 26 | 1.0 | 10.0 | 27.6 | 84.0 | 2.8 | 26 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 27 | 0.0 | 0.0 | 1.0 | 0.0 | 0.2 | 27 | 0.0 | 0.0 | 2.0 | 0.2 | 0.0 |
| 28 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 28 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 29 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 29 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 30 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 30 | 4.4 | 0.0 | 0.0 | 0.0 | 0.0 |
| 31 | 6.2 | 0.4 | 11.2 | 89.2 | 3.2 | 31 | 9.6 | 2.0 | 3.0 | 0.4 | 1.6 |
Notes:
Source: Thailand Meteorological Department Automatic Weather System.
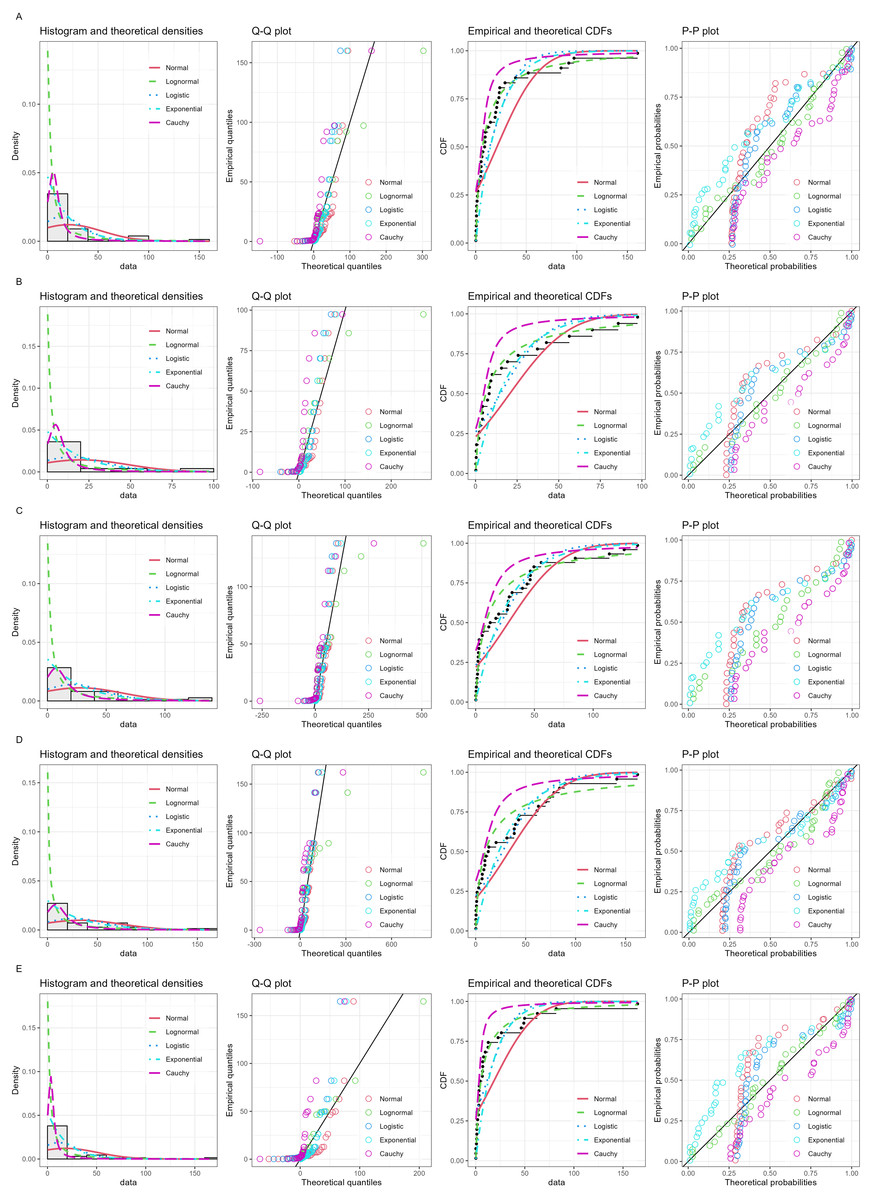
Figure 3: Histogram, normal Q-Q, CDF and P-P plots of nonzero precipitation records in five stations of southern Thailand: (A) Songkhla (B) Songkhla-Sadao (C) Yala (D) Narathiwat (E) Pattani.
{kind=link}
The results in Table 4 reveals that since variance was greater than the mean μi, quite large precipitation variations were required in the present study. For applying data of daily precipitation to measure the efficacy of the four methods, the 95% SCIs-based Bayesian, GPQ and PB approaches for all pairwise precipitation datasets from the five weather stations cover their point estimates (Table 5). In a agree with the simulation results for n1 = n2 = n3 = 50 and n4 = n5 = 100, the PB approach provided the best SCI performance for ratio of variances of several ZILN models. This can be interpreted as Narathiwat has the highest variation in precipitation, followed by Yala. These results are in line with the Asia Disaster Monitoring and Response System (Thailand, 2021), which reported that both areas were affected by flooding and landslides damaging 22,308 households in Narathiwat and 12,082 households in Yala during the time period covered by the data used in the study.
| Stations | Criterion | Models | ||||
|---|---|---|---|---|---|---|
| Normal | Lognormal | Logistic | Exponential | Cauchy | ||
| Songkhla | AIC | 387.611 | 305.171 | 373.337 | 317.644 | 345.549 |
| BIC | 390.938 | 308.498 | 376.664 | 319.308 | 348.876 | |
| Songkhla-Sadao district | AIC | 241.141 | 196.707 | 238.534 | 203.226 | 225.198 |
| BIC | 243.579 | 199.145 | 240.971 | 204.445 | 227.635 | |
| Yala | AIC | 373.538 | 313.718 | 368.171 | 322.168 | 365.426 |
| BIC | 376.760 | 316.940 | 371.393 | 323.779 | 368.648 | |
| Narathiwat | AIC | 362.209 | 310.600 | 359.299 | 317.455 | 358.947 |
| BIC | 365.320 | 313.711 | 362.410 | 319.010 | 362.058 | |
| Pattani | AIC | 328.067 | 242.474 | 313.959 | 260.584 | 273.318 |
| BIC | 331.060 | 245.467 | 316.952 | 262.080 | 276.311 | |
| Weather stations | i | ni0 | ni1 | (%) | |||
|---|---|---|---|---|---|---|---|
| Songkhla | 1 | 39 | 23 | 37.097 | 1.909 | 2.982 | 9.317 |
| Songkhla-Sadao district | 2 | 25 | 37 | 59.677 | 1.828 | 3.509 | 9.766 |
| Yala | 3 | 37 | 25 | 40.323 | 2.155 | 3.490 | 10.774 |
| Narathiwat | 4 | 35 | 27 | 43.548 | 2.253 | 4.238 | 12.411 |
| Pattani | 5 | 33 | 29 | 46.774 | 1.669 | 2.950 | 8.607 |
| Methods | Limits | All pairwise log-ratios of precipitation variabilities among weather stations | ||||
|---|---|---|---|---|---|---|
| Songkhla/ Songkhla-sadao | Songkhla/ Yala | Songkhla/ Narathiwat | Songkhla/ Pattani | Songkhla-sadao/Yala | ||
| −0.4489 | −1.4568 | −3.0939 | 0.71043 | −1.0079 | ||
| Bayesian SCIs -based PMB prior | Lower | −8.7881 | −9.796 | −11.4331 | −7.6287 | −9.3471 |
| Upper | 7.8903 | 6.8824 | 5.2452 | 9.0496 | 7.3313 | |
| Width | 16.6783 | 16.6783 | 16.6783 | 16.6783 | 16.6783 | |
| Bayesian SCIs -based RB prior | Lower | −9.4711 | −10.479 | −12.1161 | −8.3117 | −10.0301 |
| Upper | 8.5733 | 7.5654 | 5.9283 | 9.7326 | 8.0143 | |
| Width | 18.0444 | 18.0444 | 18.0444 | 18.0444 | 18.0444 | |
| SCI-based GPQ | Lower | −9.3037 | −9.2166 | −11.9695 | −6.6362 | −10.4292 |
| Upper | 8.4059 | 6.303 | 5.7816 | 8.0571 | 8.4134 | |
| Width | 17.7096 | 15.5196 | 17.7511 | 14.6932 | 18.8426 | |
| SCI-based PB | Lower | −7.4257 | −7.5709 | −10.0871 | −5.0781 | −8.4311 |
| Upper | 6.5279 | 4.6573 | 3.8992 | 6.4989 | 6.4153 | |
| Width | 13.9536 | 12.2281 | 13.9863 | 11.577 | 14.8464 | |
| Methods | Limits | Songkhla-sadao/ Narathiwat | Songkhla-sadao/ Pattani | Yala/ Narathiwat | Yala/ Pattani | Narathiwat/ Pattani |
| −2.645 | 1.1593 | −1.6371 | 2.1672 | 3.8043 | ||
| Bayesian SCIs -based PMB prior | Lower | −10.9842 | −7.1798 | −9.9763 | −6.1719 | −4.5348 |
| Upper | 5.6941 | 9.4985 | 6.702 | 10.5064 | 12.1435 | |
| Width | 16.6783 | 16.6783 | 16.6783 | 16.6783 | 16.6783 | |
| Bayesian SCIs -based RB prior | Lower | −11.6672 | −7.8629 | −10.6593 | −6.855 | −5.2178 |
| Upper | 6.3771 | 10.1815 | 7.385 | 11.1894 | 12.8266 | |
| Width | 18.0444 | 18.0444 | 18.0444 | 18.0444 | 18.0444 | |
| SCI-based GPQ | Lower | −13.0047 | −7.9247 | −11.078 | −5.8532 | −5.2999 |
| Upper | 7.7146 | 10.2433 | 7.8037 | 10.1876 | 12.9086 | |
| Width | 20.7193 | 18.168 | 18.8817 | 16.0408 | 18.2085 | |
| SCI-based PB | Lower | −10.8075 | −5.9981 | −9.0757 | −4.1522 | −3.369 |
| Upper | 5.5175 | 8.3168 | 5.8014 | 8.4866 | 10.9777 | |
| Width | 16.325 | 14.3149 | 14.8771 | 12.6388 | 14.3467 | |
Discussion
From the above numerical results, it can be seen that the SCIs based on PB and the Bayesian approach based on the PMB prior dealt with large variations in the data better than the other approaches. The PB-based SCI has some strong points for small sample sizes due to random samples being obtained via bootstrap resampling. Furthermore, the performance of the Bayesian SCI based on the PMB prior declined as the number of populations increased and the sample size decreased. Although, the GPQ method provided appropriate CRs, its AWs were wider than the other methods, possibly because the GPQ of di is limited for cases with unequal zero-inflated percentages. Since it has performed quite well for one population group especially (Wu & Hsieh, 2014; Maneerat, Niwitpong & Niwitpong, 2021a). Further research could be conducted to explore subjective or prior beliefs about parameters when using the Bayesian approach for parameter estimation
Conclusions
SCIs for the comparison of the variance ratios among several ZILN models were formulated by applying Bayesian approaches based on the PMB and RB priors, along with the GPQ and PB approaches. In practice, the daily precipitation data for each of the weather stations considered were overdispersed (i.e., the variance was greater than the mean) and zero-inflated (Table 4). Thus, the ZILN distribution is an appropriate model for estimating parameters in the construction of SCIs for multiple comparisons between their variances.
For three populations, all of the methods produced 95% SCIs for all pairwise comparisons among variances covering the true parameter. Meanwhile, the SCI constructed via the Bayesian approach based on the PMB prior maintained a good balance between LER and UER and provided the narrowest AWs except for small sample sizes. On the other hand, the PB-based SCI could handle extreme cases when the sample sizes were small with large variances. For five populations, the PB-based SCI performed the best overall, with the Bayesian approach based on the RB prior for small-to-large sample sizes and the GPQ approach for medium-to-large and large sample sizes providing acceptable results, and thus can be recommended as alternative SCIs.