
A Bayesian approach to construct confidence intervals for comparing the rainfall dispersion in Thailand
- Published
- Accepted
- Received
- Academic Editor
- Hugo Hidalgo
- Subject Areas
- Statistics, Computational Science, Natural Resource Management, Environmental Impacts
- Keywords
- Bayesian approach, MOVER, Delta-lognormal distribution, Natural rainfall, Ratio of Variances, Highest posterior density
- Copyright
- © 2020 Maneerat et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ) and either DOI or URL of the article must be cited.
- Cite this article
- 2020. A Bayesian approach to construct confidence intervals for comparing the rainfall dispersion in Thailand. PeerJ 8:e8502 https://doi.org/10.7717/peerj.8502
Abstract
Natural disasters such as drought and flooding are the consequence of severe rainfall fluctuation, and rainfall amount data often contain both zero and positive observations, thus making them fit a delta-lognormal distribution. By way of comparison, rainfall dispersion may not be similar in enclosed regions if the topography and the drainage basin are different, so it can be evaluated by the ratio of variances. To estimate this, credible intervals using the highest posterior density based on the normal-gamma prior (HPD-NG) and the method of variance estimates recovery (MOVER) for the ratio of delta-lognormal variances are proposed. Monte Carlo simulation was used to assess the performance of the proposed methods in terms of coverage probability and relative average length. The results of the study reveal that HPD-NG performed very well and was able to meet the requirements in various situations, even with a large difference between the proportions of zeros. However, MOVER is the recommended method for equal small sample sizes. Natural rainfall datasets for the northern and northeastern regions of Thailand are used to illustrate the practical use of the proposed credible intervals.
Introduction
Natural phenomena can often be random events in statistics, and natural rainfall is an important one because it is directly related to the quality of life, agriculture, economic growth, and industry, among others. Rice is the main export product from Thai agriculture, so natural rainfall is a crucial water resource for farmers. However, climate change has incurred prolonged droughts, thereby decreasing agricultural and fishery yields, and conversely, caused violent flooding and health-related issues in Thailand (Marks, 2011). Farmers who consume approximately 70% of the country’s water supply are at the forefront of these impacts due to changes in rainfall amount (Marks, 2011). Thus, extreme rainfall variation is one of the main consequences of climate change and can result in drought or flooding, and ineffective water management can exacerbate both situations (Duangdai & Likasiri, 2017).
Thailand is divided into five regions: northern, northeastern, central, eastern, and southern. The north is mountainous and contains the sources of several important rivers, including the Mekong Basin (a principal river system of Thailand). Nan is one of the provinces in the northern region faced with heavy rainfall for around two weeks which caused landslides and flooding during the rainy season (mid-May to mid-October) (Hariraksapitak, Sriring & Navaratnam, 2018). Nicely & Counselor (2018) reported that approximately 60% of the northeastern region’s arable land has been turned over to total rice cultivation. Meanwhile, 5–10% of precipitation above the normal level occurred during May–July 2018 in the northern and northeastern regions, as reported by the Thai Meteorological Department (Nicely & Counselor, 2018). These situations have led us to consider estimating the rainfall fluctuation between the northern and northeastern regions of Thailand in terms of their ratio of variances during July 2018. It is of major importance to estimate the dispersion in weekly rainfall amount between the northern and northeastern regions in Thailand for the benefit of key industries, and the information gained could help in realizing climate change awareness. The information could be advantageous for the Thai government and other related organizations to realize and plan for solving or reducing the risk of environmental issues if a large variation in rainfall is known in advance. The results from normality plots (Fig. 1), histograms (Fig. 2), and applying the Akaike information criterion (AIC) show that the weekly natural rainfall data for both regions fit delta-lognormal distributions. Note that the log-transformed data of the positive rainfall amounts fit a normal distribution which is symmetrical.
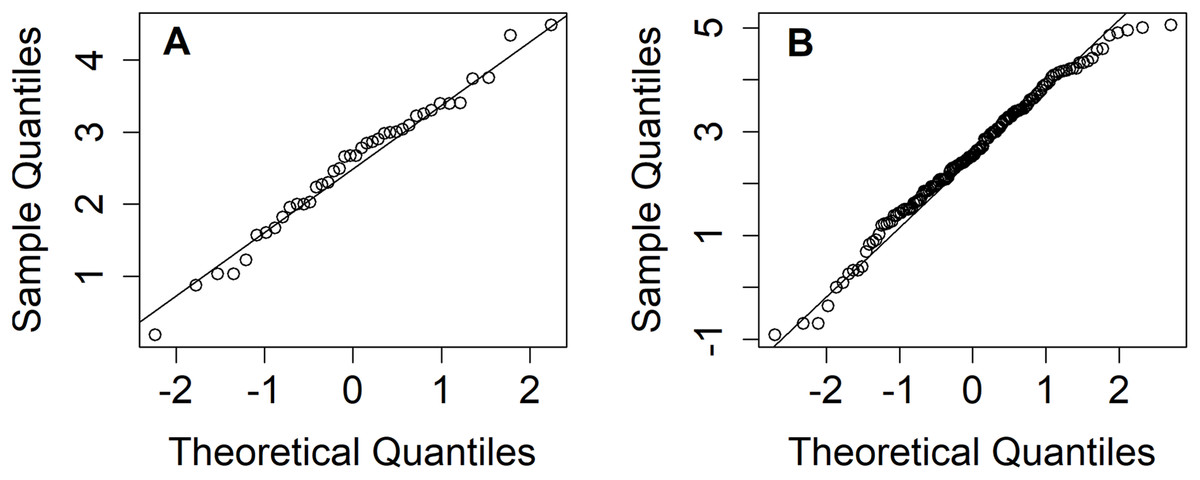
Figure 1: Q–Q plots of log-transformation of non-zero records in (A) northern (B) northeastern areas.
{kind=link}
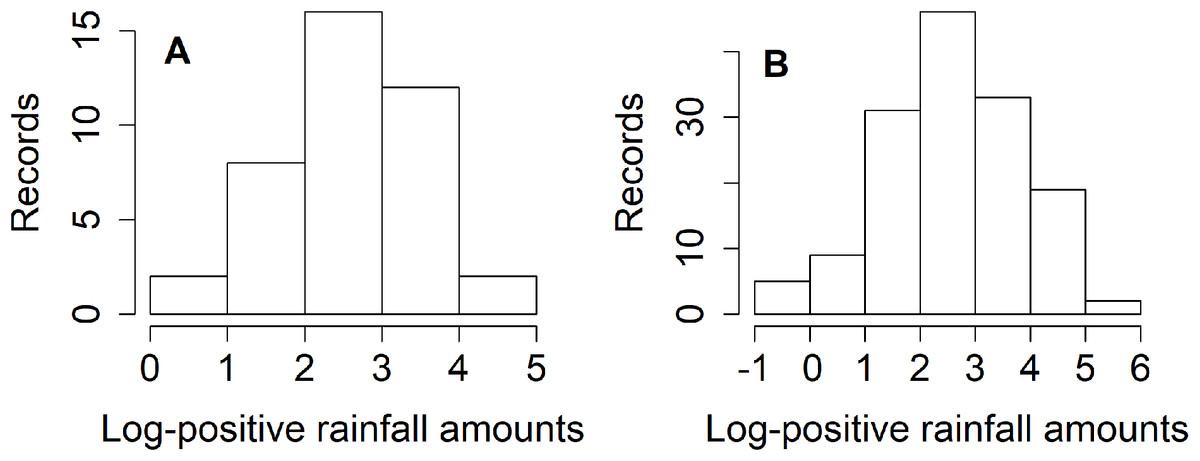
Figure 2: Histogram plots of log-transformation of weekly positive rainfall records in (A) northern (B) northeastern areas.
{kind=link}
Aitchison & Brown (1963) first introduced the delta-lognormal distribution for non-negative data containing zero values with the probability 0 < δ < 1; positive observations with the remainder of the probability 1 − δ follow a lognormal distribution and the zeros follow a binomial distribution with binomial proportion δ. The delta-lognormal distribution has been fitted for real-world examples in many research areas such as the environment (Owen & DeRouen, 1980; Hasan & Krishnamoorthy, 2018), fishery surveys (Pennington, 1983; Smith, 1988, 1990; Lo, Jacobson & Squire, 1992; Fletcher, 2008; Wu & Hsieh, 2014) and medicine (Zhou & Tu, 1999, 2000; Tian & Wu, 2006; Hasan & Krishnamoorthy, 2018).
In statistical inference, one of the parameters of interest is the variance (dispersion in environment) defined as the second central moment; the positive square root of the variance is called the standard deviation (Casella & Berger, 2002). To compare two independent populations, the ratio of their variances is the measurement of the variation between them with no difference resulting in a ratio equal to 1. Confidence intervals (CIs) have been applied to several distributions to estimate the variability in terms of variance and the ratio of variances. For example, Krishnamoorthy, Mathew & Ramachandran (2006) obtained CIs for lognormal variance based on the idea of the generalized confidence interval (GCI) which they applied to the variation in the air lead levels in 15 industrial facilities in a health hazard evaluation. Bebu & Mathew (2008) claimed that GCI was better than a modified signed log-likelihood ratio test for establishing CIs for the ratio of variances for bivariate lognormal distributions even when the sample sizes were small. Niwitpong (2017) showed that GCI performed well for the ratio of variances of lognormal distributions to solve the problems that occur when applying the traditional approach.
Casella & Berger (2002) argued that CIs can capture the parameter of interest better than point estimates. Although a few attempts have been conducted on CIs for the ratio of variances for some distributions, research on the delta-lognormal distribution has yet to be carried out. Clearly, there is a need for research that investigates and constructs CIs for the ratio of delta-lognormal variances using the highest posterior density based on normal-gamma prior (HPD-NG) and MOVER. These proposed CIs were compared with the existing HPD-based Jeffreys’ (HPD-Jef) and Jeffreys’ Rule (HPD-Rul) priors of Harvey & Van der Merwe (2012), GCI of Wu & Hsieh (2014) and fiducial GCI (FGCI) of Hasan & Krishnamoorthy (2018).
The organization of this paper is as follows. The concepts of all of the CIs for the ratio of variances in delta-lognormal distributions are elaborated in “Methods”. The simulation procedure and numerical results are reported in “Results.” In “Discussion,” the proposed methods are applied to real-world datasets to estimate the rainfall fluctuation between the northern and northeastern regions in Thailand. Last, we present a discussion and conclusions on the study outcomes.
Methods
Let Xij = (Xi1, Xi2, …, Xini); i = 1, 2 and j = 1, 2, …, ni be non-negative random samples draw from a delta-lognormal distribution with parameters μi, σ2i and δi, stand for Xij ∼ Δ(μi, σ2i, δi). For Xij = 0, the number of having zero ni(0) ∼ B(ni, δi) and ni = ni(0) + ni(1). For Xij > 0, Xij ∼ LN(μi, σ2i) where Yij = ln(Xij)∼ N(μi, σ2i). Aitchison & Brown (1963) defined the population variance of Xij as (1)
The maximum likelihood estimates of δi, μi and σ2i are , , and , respectively. From Eq. (1), the ratio in delta-lognormal variances is obtained as (2)
where ωi is log-transformed as . The methods for constructing CIs for θ are described as seen below.
GCI
On the ideas of GCI, the generalized pivotal quantity (GPQ) is necessary to satisfy the two requirements of Weerahandi (1993). The GPQ of δi based on VST was proposed by Wu & Hsieh (2014) as (3) where . The GPQs of μi and σ2i are (4) which are presented by Krishnamoorthy & Mathew (2003). These GPQs lead to obtain the GPQ of θ as (5) where . becomes the 100(1− ζ)%GCI for θ. Algorithm 1 shows the steps to compute GCI as seen above.
| (1) Generate Wi ∼ N(0, 1), Zi ∼ N(0, 1) and . |
| (2) Compute Rμi, , and Rδi. |
| (3) Compute Rln ωi. |
| (4) Compute Rθi. |
| (5) Repeat 1–4 a number of times (say, m = 2,500). |
| (6) For the 2,500 times, compute (100 − ζ)%GCI for θ. |
FGCI
The fiducial generalized pivotal quantity (FGPQ) was proved and defined by Hannig, Iyer & Patterson (2006). Hannig (2009) claimed that their generalized fiducial recipe has been developed as the GPQ concept, so their ideas are applied with generalized inference directly. Here Xij ∼ Δ(μi, σ2i, δi) is considered. Hasan & Krishnamoorthy (2018) showed the FGPQs of μi and σ2i as (6) (7) where Zi ∼ N(0, 1) and Ui ∼ χ2ni(1) − 1/(ni(1) − 1) are independent random variables. Also, the FGPQs of δi was developed as T1 − δi ∼ beta(ni(1) + 0.5, ni(0) + 0.5). By three FGPQs, the FGPQ of ln ωi is defined as , then the FGPQs of θ can be expressed as (8) which can establish the 100(1− ζ)%FGCI for θ that is ; Tθ(ζ) stands for (ζ)100th percentile of Tθ. Algorithm 2 details the computation of FGCI.
| (1) Generate Zi ∼ N(0, 1) and . |
| (2) Compute Tμi, , and T1 − δi. |
| (3) Compute Tln ωi. |
| (4) Compute Tθi. |
| (5) Repeat 1–4 a number of times (say, m = 2,500). |
| (6) For the 2,500 times, compute (100 − ζ)%FGCI for θ. |
MOVER interval
This interval is expanded from CIs for delta-lognormal mean of Hasan & Krishnamoorthy (2018) to the ratio of delta-lognormal variances. Given the individual CIs for the parameters of interest γ, the MOVER concept is used to establish a CI for a linear combination of parameters, proposed by Krishnamoorthy & Oral (2017). Let be a p-dimensional parameter vector. The estimate of γi is that are independent. The MOVER interval for is defined as (9) where if ci > 0, ui if and if ci > 0, li if . Moreover, (li, ui) stands for the CI for γi. Here we let (10)
Using from a sample, is obtained, and CIs for individual parameters , and are also constructed. To begin with , (100 − ζ)% CI-based Wilson was proposed by Wilson (1927), that is (11) where . The (100 − ζ)%CI for is developed from Zou, Taleban & Huo (2009), then (12) where and χ2ni(1) − 1 denoted as chi-square distribution with ni(1) − 1 degree of freedom. Next, the (100 − ζ)%CI for is proposed as (13) where
As mentioned above, the (100 − ζ)% MOVER interval for ln ωi can be written as (14) where
| (1) Generate Zi ∼ N(0, 1), Ti ∼ N(0, 1) and are independent. |
| (2) Compute , and . |
| (3) Compute CIln ωi and CIθ. |
| (4) Compute (100 − ζ)%MOVER for θ. |
Therefore, the (100 − ζ)% MOVER interval for θ is based on Donner & Zou (2012), given by (15) where
The following detail is used to compute the MOVER interval.
HPD credible interval
The HPD credible interval is a parameter estimate based on the posterior probability in Bayesian framework. Box & Tiao (1973) defined the HPD ideas consisting of two requirements: the set of value that contain 100(1 − ζ)% of the posterior distribution and the property that the density within the region is equal or greater than outside. The posterior density is unimodal and symmetric, the region based on their definition becomes to a equal-sided CI (ζ/2 and 1 − ζ/2 percentiles of the posterior density). This is clearly different between equal-sided CI and HPD credible interval if there is a highly skewed in the posterior density. Recently, HPDs based on beta and uniform priors were recommended to constructed for single mean and the difference between two delta-lognormal means proposed by Maneerat, Niwitpong & Niwitpong (2019). The HPD credible interval is then focused on our study. Recall that Xij > 0 be random variables from lognormal distribution with parameter ; Yij = ln Xij ∼ N(μi, σ2i). The Fisher information matrix of κ is . For Xij = 0, the number of zero values ni(0) be random sample of binomial distribution, denoted as B(ni,δi). The likelihood function of Xij is (16) which leads to obtain the Fisher information matrix of
Here θ = ln ω1 − ln ω2 so that the HPD credible intervals based on different priors for θ are described.
Jeffreys’ prior
The Jeffreys’ prior for ω is defined as (17) where and . The prior Eq. (17) is combined with its likelihood Eq. (16) to obtain the posterior distributions of each parameters σ2i, μi, and δi. Firstly, the posterior density of ω is using Bayes’ theorem (Casella & Berger, 2002), given by (18)
Obtain that (19) which is the posterior density of σ2|x, as inverted gamma distribution, denoted as IG(ai, bi); ai = ri/2 and ; ri = ni(1) − 1. Given σ2i and x, one obtains that (20)
This is the posterior density of μi|σ2i, x, as normal . For δi, its posterior was proved as which is the beta distribution with ci and di, denoted as beta(ci, di); ci = ni(0) + 1/2 and di = ni(1) + 1/2.
Jeffreys’ Rule prior
According to Harvey & Van der Merwe (2012), the difference between Jeffreys and Jeffreys’ Rule priors is the posterior densities of σ2i and δi, while Jeffreys’ Rule prior is defined as (21)
To obtain the joint posterior of ω denoted as P(ω|x)JR, the Jeffreys’ Rule prior Eq. (21) is combined with the likelihood Eq. (16). For σ2i, its posterior has been changed to inverted gamma distribution with shape parameter si/2 and scale parameter ; si = ni(1) + 1. Then, the posterior distribution of μi given σ2i and x is changed because it depends on the posterior density of σ2i. Likewise, the posterior of δi becomes P(δ|x)JR = beta(ni(0) + 1/2, ni(1) + 3/2). Their posterior distributions represent to estimate own parameter, meanwhile , P(μi|σ2i, xij)JR and P(δi|xij)JR are independent. As a result, HPD credible interval for θ is computed based on Jeffreys’ Rule prior. The steps for establishing HPD-intervals based on two priors are detailed as Algorithm 4.
| (1) Generate σ2*i denoted as the posterior distribution of σ2i based on priors: |
| • Jeffreys’ prior: ; ri = ni(1) − 1. |
| • Jeffreys’ Rule prior: ; si = ni(1) + 1. |
| • NG prior: σ2*i(NG) ∼ IG(σ2i|αi,ni(1), βi,ni(1)). |
| (2) Given σ2*i and x, generate μ*i depends on the following priors: |
| • Jeffreys’ prior: . |
| • Jeffreys’ Rule prior: . |
| • NG prior: . |
| (3) Generate δ*i, |
| • Jeffreys’ prior: δ*i(J) ∼ beta(ni(0) + 1/2,ni(1) + 1/2). |
| • Jeffreys’ Rule prior: δ*i(JR) ∼ beta(ni(0) + 1/2,ni(1) + 3/2). |
| • NG prior: δ*i(NG),ni(1) ∼ beta(ni(1) + di,ni(0) + di). |
| (4) Compute ω*i, |
| • Jeffreys’ prior: . |
| • Jeffreys’ Rule prior: . |
| • NG prior: . |
| (5) Compute θ* = ln ω*1 − ln ω*2 based on three priors. |
| (6) Repeat 1–5 a number of times (say, m = 2,500). |
| (7) For the 2500 times, compute (100 − ζ)%HPD interval for θ in each prior. |
Normal-gamma prior
DeGroot (1970) defined the conjugate families for random sample of normal distribution. This is a necessary to develop credible interval based on Bayesian approach for the delta-lognormal variance. Using Theorem 1 of the conjugate families for random sample of normal distribution (DeGroot, 1970), assume that (Y = ln Xij; i = 1, 2 j = 1, 2, …, ni(1)) be a random sample from normal distribution with the mean μ = (μ1, μ2) and precision λ = (λ1, λ2); λi = 1/σ2i where X ∼ LN(μ, λ). The normal-gamma prior of τ = (μ, λ)′ is defined the marginal distributions between normal μi|λi ∼ N(μ, [kiλi] − 1) and gamma λi ∼ G(αi, βi), given by (22)
The likelihood can be written as (23)
The posterior distribution of τ can be derived as (24)
This implied that where , , , and . From Eq. (22), the normal-gamma prior of τ is defined as (25) which is normal-gamma distribution, denoted as NG(μi, λi|μ, ki(0) = 0, αi(0) = −1/2, βi(0) = 0 so that its posterior of τ is derived from Eq. (24) that becomes (26)
This is NG(μi,ni(1), ki,ni(1), αi,ni(1), βi,ni(1)); , ki,ni(1) = ni(1), αi,ni(1) = (ni(1) − 1)/2 and . The marginal posterior of λi becomes (27) which is λi|y ∼ G(λi|αi,ni(1), βi,ni(1)). This can be implied that σ2i|y ∼ IG(σ2i|αi,ni(1), βi,ni(1)). Let and ai = λiρ i, then . Also, let . From Eq. (26), the marginal posterior of μi|y is also obtained as (28)
Then, μi|y ∼ tdf(μi|μi,ni(1),βi,ni(1)/[αi,ni(1)ki,ni(1)]) where df = 2αi,ni(1) = ni(1) − 1. For δi,ni(1) = 1 − δi, Jin, Thulin & Larsson (2017) have investigated and attempted to find the power-divergence (PD) interval for δi estimated by Bayesian credible interval-based beta(d,d) prior. For focusing on this study, the beta(d,d) prior of δi,ni(1) is given by (29) where ; zζ/2 be a random sample of standard normal distribution. It is combined with the likelihood function of δi,ni(1) such that its posterior of δi,ni(1) is then (30) which is beta distribution, denoted as beta(ni(1) + di,ni(0) + di). The posterior distributions of μi and σ2i based on NG prior and δi,ni(1) based on Jin, Thulin & Larsson (2017) are obtained, then HPD-NG credible interval for θ can be computed in Algorithm 4.
Results
The CIs proposed in this study are HPD-NG and MOVER. The former develops the NG prior to obtain the posterior density, while the latter is an extension of Hasan and Krishnamoorthy’s MOVER (Hasan & Krishnamoorthy, 2018). Both were compared with the existing CIs HPD-Jef and HPD-Rul of Harvey & Van der Merwe (2012), GCI of Wu & Hsieh (2014), and FGCI of Hasan & Krishnamoorthy (2018). Two simulation studies were conducted to show the aforementioned CI performances under equal and unequal sample sizes in different situations:
S1. The probability of additional zero δi is varied while μi = 3 and σ2i = 1.
S2. The mean μi and δi are varied while σ2i = 1.
S1 was designed and simulated to be consistent with the weekly rainfall datasets, as can be seen in the next section. The second one was constructed to indicate CI performance when both the mean μi and δi are changed, i.e. whether the numerical simulation is consistent with S1.
The coverage probability (CP) and relative average length (RAL, denoted as the ratio of the average lengths of a proposed CI to HPD-Rul) were used to assess the performances of the CIs using Monte Carlo simulations. For 5,000 simulation runs, GPQs and FGPQs were fixed at 2,500 at a nominal level of 0.95. In a comparison of the methods, the following criteria were used to judge the best-performing CI: a CP closer to or greater than the nominal level and the narrowest RAL of less than 1 and minimal. The steps of the simulation procedure are given in Algorithm 5.
| (1) Generate Xij ∼ Δ(μi, σ2i, δi); i = 1, 2 and j = 1, 2, …, ni. |
| (2) Compute ni(0), ni(1), , and . |
| (3) Construct CIs based on the methods as follows: |
| • GCI, FGCI and MOVER from Algorithms 1, 2 and 3, respectively. |
| • HPD-Jef, HPD-Rul and HPD-NG from Algorithm 4. |
| (4) Repeat 1–3, a number of times, (say, M = 5,000). All CIs are obtained. |
| (5) Compute CPs and RALs with all CIs. |
The findings are based on the simulation work as follows. For the ratio of variances, the numerical evaluation shows that for the method in the S1 scenario, MOVER provided good performance for a small difference between δi with equal small sample sizes (Table 1). Importantly, HPD-NG had good coverage (a CP greater than 0.95) and the shortest CIs for both equal and unequal medium sample sizes as well as a large difference in δi for unequal large sample sizes. Meanwhile, HPD-Rul’s performance satisfied the criteria for a small difference in δi and unequal large sample sizes. The results in Table 2 for case S2 indicate that for a small difference in δi, MOVER could meet the requirements for equal small sample sizes, while HPD-NG maintained the given target for both equal and unequal medium sample sizes, and unequal large sample sizes. Moreover, HPD-Rul performed well for a large difference in δi and unequal medium-to-large sample sizes. From the evidence of both situations, HPD-Jef gave the best CP in all cases even though its average lengths were mostly wider than HPD-NG. Meanwhile, GCI and FGCI performances provided average lengths that were broader than other methods in all situations.
| (n1,n2) | (δ1,δ2) | CP | RAL | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HPD-Jef | HPD-Rul | HPD-NG | GCI | FGCI | MOVER | HPD-Jef | HPD-Rul | HPD-NG | GCI | FGCI | MOVER | ||
| (15,15) | (0.1,0.1) | 99.8 | 99.7 | 99.8 | 99.7 | 99.6 | 94.4 | 1.095 | [*] | 1.152 | 1.109 | 1.108 | 0.796 |
| (0.1,0.2) | 99.8 | 99.7 | 99.8 | 99.5 | 99.5 | 94.7 | 1.104 | [*] | 1.179 | 1.122 | 1.120 | 0.819 | |
| (0.1,0.3) | 99.8 | 99.4 | 99.8 | 99.3 | 99.3 | 94.0 | 1.115 | [*] | 1.206 | 1.135 | 1.134 | 0.847 | |
| (0.1,0.4) | 99.8 | 99.4 | 99.9 | 99.4 | 99.4 | 94.3 | 1.137 | [*] | 1.273 | 1.166 | 1.166 | 0.934 | |
| (0.1,0.5) | 99.9 | 99.6 | 99.9 | 99.6 | 99.6 | 95.5 | 1.160 | [*] | 1.344 | 1.201 | 1.200 | 1.045 | |
| (0.2,0.1) | 99.8 | 99.6 | 99.8 | 99.5 | 99.5 | 93.5 | 1.105 | [*] | 1.179 | 1.121 | 1.120 | – | |
| (0.2,0.2) | 99.9 | 99.6 | 99.9 | 99.6 | 99.6 | 94.0 | 1.114 | [*] | 1.205 | 1.131 | 1.130 | 0.836 | |
| (0.2,0.3) | 99.7 | 99.4 | 99.8 | 99.3 | 99.3 | 94.8 | 1.122 | [*] | 1.228 | 1.139 | 1.139 | 0.856 | |
| (0.2,0.4) | 99.9 | 99.5 | 99.9 | 99.5 | 99.4 | 94.3 | 1.146 | [*] | 1.296 | 1.171 | 1.171 | 0.943 | |
| (0.2,0.5) | 99.8 | 99.3 | 99.9 | 99.3 | 99.4 | 94.5 | 1.170 | [*] | 1.373 | 1.209 | 1.208 | 1.072 | |
| (0.3,0.1) | 99.8 | 99.5 | 99.8 | 99.4 | 99.4 | 94.2 | 1.114 | [*] | 1.204 | 1.133 | 1.131 | 0.845 | |
| (0.3,0.2) | 99.7 | 99.6 | 99.8 | 99.5 | 99.5 | 94.5 | 1.123 | [*] | 1.230 | 1.142 | 1.141 | 0.861 | |
| (0.3,0.3) | 99.8 | 99.2 | 99.8 | 99.2 | 99.2 | 94.2 | 1.131 | [*] | 1.253 | 1.151 | 1.149 | 0.877 | |
| (0.3,0.4) | 99.8 | 99.5 | 99.9 | 99.3 | 99.3 | 95.2 | 1.153 | [*] | 1.320 | 1.179 | 1.178 | 0.967 | |
| (0.3,0.5) | 99.9 | 99.5 | 99.9 | 99.5 | 99.5 | 95.8 | 1.177 | [*] | 1.393 | 1.210 | 1.210 | 1.070 | |
| (50,50) | (0.1,0.1) | 97.3 | 97.2 | 95.5 | 96.9 | 97.0 | 91.2 | 1.019 | [*] | 0.935 | 1.027 | 1.026 | – |
| (0.1,0.2) | 97.6 | 97.2 | 95.4 | 97.2 | 97.2 | 90.7 | 1.021 | [*] | 0.936 | 1.029 | 1.028 | – | |
| (0.1,0.3) | 96.9 | 96.5 | 94.6 | 96.7 | 96.5 | 90.6 | 1.022 | [*] | 0.939 | 1.031 | 1.030 | – | |
| (0.1,0.4) | 97.2 | 96.7 | 94.8 | 96.5 | 96.7 | 89.9 | 1.024 | [*] | 0.944 | 1.034 | 1.034 | – | |
| (0.1,0.5) | 96.8 | 95.9 | 94.4 | 95.8 | 96.1 | 89.4 | 1.029 | [*] | 0.955 | 1.041 | 1.041 | – | |
| (0.2,0.1) | 97.2 | 96.6 | 94.9 | 96.6 | 96.6 | 90.5 | 1.020 | [*] | 0.936 | 1.028 | 1.027 | – | |
| (0.2,0.2) | 97.4 | 96.8 | 95.1 | 96.6 | 96.7 | 90.4 | 1.022 | [*] | 0.938 | 1.029 | 1.029 | – | |
| (0.2,0.3) | 96.4 | 96.1 | 94.1 | 95.8 | 95.9 | 89.2 | 1.023 | [*] | 0.941 | 1.032 | 1.032 | – | |
| (0.2,0.4) | 96.8 | 96.3 | 94.4 | 96.1 | 96.0 | 90.2 | 1.026 | [*] | 0.946 | 1.035 | 1.035 | – | |
| (0.2,0.5) | 96.8 | 96.5 | 95.1 | 96.4 | 96.5 | 90.1 | 1.030 | [*] | 0.956 | 1.041 | 1.041 | – | |
| (0.3,0.1) | 97.4 | 96.9 | 95.4 | 96.8 | 96.9 | 90.6 | 1.022 | [*] | 0.940 | 1.031 | 1.030 | – | |
| (0.3,0.2) | 96.9 | 96.5 | 94.5 | 96.5 | 96.3 | 88.5 | 1.024 | [*] | 0.942 | 1.032 | 1.032 | – | |
| (0.3,0.3) | 96.6 | 96.0 | 94.1 | 95.8 | 95.9 | 89.0 | 1.025 | [*] | 0.945 | 1.034 | 1.034 | – | |
| (0.3,0.4) | 97.1 | 96.6 | 95.2 | 96.8 | 96.7 | 89.9 | 1.027 | [*] | 0.950 | 1.036 | 1.035 | – | |
| (0.3,0.5) | 96.9 | 96.4 | 94.7 | 96.1 | 96.1 | 89.7 | 1.032 | [*] | 0.960 | 1.042 | 1.042 | – | |
| (30,50) | (0.1,0.1) | 98.1 | 97.8 | 96.8 | 97.7 | 97.8 | 90.8 | 1.030 | [*] | 0.964 | 1.042 | 1.042 | – |
| (0.1,0.2) | 98.3 | 97.9 | 96.7 | 97.8 | 97.7 | 90.6 | 1.030 | [*] | 0.966 | 1.043 | 1.042 | – | |
| (0.1,0.3) | 97.8 | 97.7 | 96.2 | 97.1 | 97.1 | 89.3 | 1.032 | [*] | 0.968 | 1.044 | 1.042 | – | |
| (0.1,0.4) | 97.7 | 97.4 | 96.0 | 97.1 | 97.1 | 90.1 | 1.033 | [*] | 0.972 | 1.043 | 1.042 | – | |
| (0.1,0.5) | 97.6 | 97.2 | 96.3 | 97.0 | 97.1 | 89.7 | 1.036 | [*] | 0.981 | 1.046 | 1.046 | – | |
| (0.2,0.1) | 98.0 | 97.7 | 96.6 | 97.4 | 97.5 | 90.9 | 1.033 | [*] | 0.971 | 1.047 | 1.046 | – | |
| (0.2,0.2) | 97.8 | 97.4 | 96.3 | 97.3 | 97.3 | 90.2 | 1.034 | [*] | 0.972 | 1.047 | 1.046 | – | |
| (0.2,0.3) | 97.9 | 97.4 | 96.4 | 97.2 | 97.2 | 89.9 | 1.034 | [*] | 0.974 | 1.046 | 1.046 | – | |
| (0.2,0.4) | 98.1 | 97.6 | 96.4 | 97.3 | 97.3 | 89.6 | 1.035 | [*] | 0.978 | 1.047 | 1.046 | – | |
| (0.2,0.5) | 97.6 | 97.5 | 96.2 | 97.0 | 96.9 | 89.5 | 1.039 | [*] | 0.987 | 1.050 | 1.049 | – | |
| (0.3,0.1) | 98.1 | 97.6 | 96.4 | 97.3 | 97.3 | 89.8 | 1.036 | [*] | 0.981 | 1.054 | 1.053 | – | |
| (0.3,0.2) | 97.7 | 97.1 | 96.0 | 96.7 | 96.9 | 89.6 | 1.037 | [*] | 0.981 | 1.053 | 1.053 | – | |
| (0.3,0.3) | 97.6 | 97.1 | 95.6 | 96.7 | 96.8 | 89.6 | 1.038 | [*] | 0.984 | 1.053 | 1.052 | – | |
| (0.3,0.4) | 97.4 | 97.0 | 95.8 | 96.7 | 96.7 | 88.8 | 1.039 | [*] | 0.988 | 1.053 | 1.052 | – | |
| (0.3,0.5) | 97.7 | 97.3 | 96.2 | 97.1 | 97.0 | 89.6 | 1.043 | [*] | 0.997 | 1.056 | 1.055 | – | |
| (50,100) | (0.1,0.1) | 96.7 | 96.4 | 93.9 | 96.2 | 96.3 | 91.7 | 1.016 | [*] | 0.922 | 1.026 | 1.026 | – |
| (0.1,0.2) | 96.6 | 96.2 | 94.0 | 96.0 | 96.2 | 91.4 | 1.016 | [*] | 0.921 | 1.025 | 1.025 | – | |
| (0.1,0.3) | 96.7 | 96.2 | 93.8 | 96.1 | 96.1 | 91.1 | 1.016 | [*] | 0.921 | 1.025 | 1.025 | – | |
| (0.1,0.4) | 96.7 | 96.6 | 94.2 | 96.3 | 96.4 | 91.3 | 1.016 | [*] | 0.921 | 1.025 | 1.025 | – | |
| (0.1,0.5) | 96.8 | 96.5 | 94.5 | 96.3 | 96.3 | 90.9 | 1.019 | [*] | 0.923 | 1.026 | 1.025 | – | |
| (0.2,0.1) | 96.7 | 96.4 | 94.1 | 96.1 | 96.3 | 91.1 | 1.017 | [*] | 0.923 | 1.028 | 1.028 | – | |
| (0.2,0.2) | 96.7 | 96.3 | 93.7 | 95.9 | 96.0 | 90.4 | 1.017 | [*] | 0.923 | 1.029 | 1.027 | – | |
| (0.2,0.3) | 96.4 | 96.1 | 93.9 | 96.0 | 95.9 | 90.5 | 1.017 | [*] | 0.922 | 1.028 | 1.027 | – | |
| (0.2,0.4) | 96.8 | 96.6 | 93.7 | 96.4 | 96.4 | 90.7 | 1.018 | [*] | 0.923 | 1.028 | 1.027 | – | |
| (0.2,0.5) | 96.4 | 96.1 | 93.7 | 96.1 | 96.1 | 90.2 | 1.018 | [*] | 0.924 | 1.028 | 1.027 | – | |
| (0.3,0.1) | 96.0 | 96.0 | 93.0 | 95.5 | 95.4 | 90.9 | 1.019 | [*] | 0.926 | 1.033 | 1.033 | – | |
| (0.3,0.2) | 96.0 | 95.7 | 93.0 | 95.3 | 95.4 | 90.2 | 1.019 | [*] | 0.926 | 1.032 | 1.031 | – | |
| (0.3,0.3) | 96.4 | 95.7 | 93.7 | 95.8 | 95.8 | 90.5 | 1.019 | [*] | 0.926 | 1.032 | 1.031 | – | |
| (0.3,0.4) | 96.4 | 95.7 | 93.4 | 95.9 | 95.9 | 90.6 | 1.020 | [*] | 0.926 | 1.031 | 1.031 | – | |
| (0.3,0.5) | 96.7 | 96.3 | 94.2 | 96.2 | 96.3 | 90.7 | 1.021 | [*] | 0.928 | 1.030 | 1.031 | – | |
Notes:
[*]: HPD-Rul satisfies the criteria.
Bold denotes the best-performing CI.
| (n1,n2) | (δ1,δ2) | (μ1,μ2) | CP | RAL | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HPD-Jef | HPD-Rul | HPD-NG | GCI | FGCI | MOVER | HPD-Jef | HPD-Rul | HPD-NG | GCI | FGCI | MOVER | |||
| (15,15) | (0.1,0.1) | (0,0) | 99.8 | 99.5 | 99.8 | 99.5 | 99.5 | 93.7 | 1.096 | [*] | 1.154 | 1.112 | 1.110 | 0.797 |
| (0,0.3) | 99.8 | 99.4 | 99.6 | 99.4 | 99.3 | 93.7 | 1.096 | [*] | 1.155 | 1.111 | 1.108 | 0.798 | ||
| (0,0.5) | 99.9 | 99.6 | 99.9 | 99.7 | 99.7 | 93.9 | 1.095 | [*] | 1.153 | 1.111 | 1.108 | 0.796 | ||
| (0,0.7) | 99.7 | 99.5 | 99.7 | 99.6 | 99.6 | 94.4 | 1.095 | [*] | 1.153 | 1.111 | 1.109 | 0.798 | ||
| (0,0.9) | 99.8 | 99.6 | 99.7 | 99.4 | 99.5 | 93.8 | 1.096 | [*] | 1.154 | 1.111 | 1.110 | 0.797 | ||
| (0.2,0.2) | (0,0) | 99.7 | 99.4 | 99.8 | 99.4 | 99.4 | 93.9 | 1.114 | [*] | 1.205 | 1.132 | 1.130 | 0.839 | |
| (0,0.3) | 99.9 | 99.6 | 99.9 | 99.6 | 99.7 | 94.6 | 1.113 | [*] | 1.205 | 1.130 | 1.129 | 0.835 | ||
| (0,0.5) | 99.9 | 99.5 | 99.8 | 99.5 | 99.6 | 94.5 | 1.115 | [*] | 1.206 | 1.131 | 1.129 | 0.835 | ||
| (0,0.7) | 99.8 | 99.7 | 99.9 | 99.6 | 99.5 | 94.6 | 1.114 | [*] | 1.205 | 1.132 | 1.130 | 0.838 | ||
| (0,0.9) | 99.8 | 99.6 | 99.9 | 99.5 | 99.6 | 94.5 | 1.114 | [*] | 1.205 | 1.131 | 1.130 | 0.836 | ||
| (0.4,0.4) | (0,0) | 99.7 | 99.2 | 99.9 | 99.2 | 99.3 | 94.6 | 1.174 | [*] | 1.382 | 1.200 | 1.199 | 1.038 | |
| (0,0.3) | 99.8 | 99.4 | 99.9 | 99.2 | 99.2 | 94.7 | 1.173 | [*] | 1.380 | 1.201 | 1.199 | 1.033 | ||
| (0,0.5) | 99.9 | 99.5 | 99.9 | 99.5 | 99.5 | 95.2 | 1.175 | [*] | 1.384 | 1.202 | 1.200 | 1.033 | ||
| (0,0.7) | 99.9 | 99.4 | 99.9 | 99.5 | 99.5 | 95.1 | 1.174 | [*] | 1.383 | 1.198 | 1.199 | 1.029 | ||
| (0,0.9) | 99.9 | 99.5 | 99.9 | 99.5 | 99.5 | 95.5 | 1.174 | [*] | 1.383 | 1.201 | 1.199 | 1.038 | ||
| (30,30) | (0.1,0.1) | (0,0) | 98.8 | 98.3 | 97.7 | 98.3 | 98.4 | 90.8 | 1.037 | [*] | 0.986 | 1.046 | 1.044 | – |
| (0,0.3) | 98.8 | 98.4 | 97.7 | 98.3 | 98.2 | 90.8 | 1.037 | [*] | 0.986 | 1.047 | 1.045 | – | ||
| (0,0.5) | 98.9 | 98.6 | 97.9 | 98.3 | 98.4 | 91.0 | 1.037 | [*] | 0.986 | 1.047 | 1.045 | – | ||
| (0,0.7) | 98.7 | 98.2 | 97.7 | 98.1 | 98.0 | 90.5 | 1.037 | [*] | 0.987 | 1.047 | 1.045 | – | ||
| (0,0.9) | 98.8 | 98.4 | 98.0 | 98.5 | 98.4 | 91.6 | 1.036 | [*] | 0.986 | 1.046 | 1.045 | – | ||
| (0.2,0.2) | (0,0) | 98.4 | 98.2 | 97.7 | 98.2 | 98.2 | 90.3 | 1.041 | [*] | 0.997 | 1.052 | 1.051 | – | |
| (0,0.3) | 98.4 | 98.2 | 97.6 | 98.1 | 98.0 | 90.3 | 1.041 | [*] | 0.997 | 1.052 | 1.051 | – | ||
| (0,0.5) | 98.2 | 97.8 | 97.3 | 97.7 | 97.6 | 90.0 | 1.042 | [*] | 0.997 | 1.052 | 1.050 | – | ||
| (0,0.7) | 98.4 | 98.0 | 97.5 | 97.7 | 97.8 | 89.9 | 1.040 | [*] | 0.998 | 1.051 | 1.051 | – | ||
| (0,0.9) | 98.1 | 98.0 | 97.4 | 97.7 | 97.8 | 89.9 | 1.041 | [*] | 0.998 | 1.051 | 1.051 | – | ||
| (0.4,0.4) | (0,0) | 98.1 | 97.8 | 97.3 | 97.4 | 97.3 | 89.6 | 1.058 | [*] | 1.042 | 1.070 | 1.071 | – | |
| (0,0.3) | 98.2 | 97.8 | 97.6 | 97.7 | 97.7 | 90.3 | 1.060 | [*] | 1.042 | 1.072 | 1.072 | – | ||
| (0,0.5) | 98.2 | 97.7 | 97.3 | 97.4 | 97.4 | 89.9 | 1.058 | [*] | 1.042 | 1.072 | 1.071 | – | ||
| (0,0.7) | 98.4 | 97.7 | 97.4 | 97.5 | 97.5 | 89.5 | 1.059 | [*] | 1.041 | 1.071 | 1.070 | – | ||
| (0,0.9) | 98.2 | 97.7 | 97.2 | 97.4 | 97.3 | 89.8 | 1.058 | [*] | 1.041 | 1.070 | 1.071 | – | ||
| (50,50) | (0.1,0.1) | (0,0) | 97.1 | 96.8 | 95.1 | 96.7 | 96.8 | 90.1 | 1.020 | [*] | 0.936 | 1.028 | 1.027 | – |
| (0,0.3) | 97.3 | 96.9 | 95.3 | 97.0 | 96.8 | 91.0 | 1.020 | [*] | 0.935 | 1.028 | 1.027 | – | ||
| (0,0.5) | 97.7 | 97.2 | 95.3 | 97.1 | 97.1 | 90.5 | 1.019 | [*] | 0.934 | 1.027 | 1.026 | – | ||
| (0,0.7) | 97.4 | 97.1 | 95.2 | 97.0 | 96.9 | 90.9 | 1.019 | [*] | 0.935 | 1.027 | 1.026 | – | ||
| (0,0.9) | 96.8 | 96.4 | 94.8 | 96.2 | 96.3 | 89.9 | 1.020 | [*] | 0.936 | 1.028 | 1.027 | – | ||
| (0.2,0.2) | (0,0) | 96.4 | 96.0 | 94.3 | 96.1 | 96.0 | 89.5 | 1.021 | [*] | 0.938 | 1.029 | 1.028 | – | |
| (0,0.3) | 97.1 | 96.7 | 94.6 | 96.5 | 96.6 | 89.8 | 1.022 | [*] | 0.938 | 1.031 | 1.030 | – | ||
| (0,0.5) | 96.8 | 96.4 | 94.4 | 96.2 | 96.2 | 89.8 | 1.022 | [*] | 0.938 | 1.030 | 1.029 | – | ||
| (0,0.7) | 96.9 | 96.5 | 94.5 | 96.3 | 96.3 | 90.3 | 1.023 | [*] | 0.938 | 1.030 | 1.029 | – | ||
| (0,0.9) | 96.8 | 96.4 | 94.5 | 96.2 | 96.2 | 89.9 | 1.022 | [*] | 0.937 | 1.029 | 1.029 | – | ||
| (0.4,0.4) | (0,0) | 96.6 | 96.3 | 94.4 | 96.0 | 95.9 | 89.1 | 1.029 | [*] | 0.954 | 1.038 | 1.038 | – | |
| (0,0.3) | 96.8 | 96.4 | 94.4 | 96.0 | 96.1 | 88.9 | 1.029 | [*] | 0.954 | 1.038 | 1.038 | – | ||
| (0,0.5) | 96.9 | 96.4 | 94.6 | 95.9 | 96.2 | 89.3 | 1.029 | [*] | 0.954 | 1.038 | 1.038 | – | ||
| (0,0.7) | 96.7 | 96.0 | 94.3 | 95.7 | 95.8 | 89.2 | 1.029 | [*] | 0.955 | 1.038 | 1.038 | – | ||
| (0,0.9) | 97.0 | 96.3 | 94.7 | 96.1 | 96.1 | 89.2 | 1.030 | [*] | 0.955 | 1.039 | 1.038 | – | ||
| (30,50) | (0.1,0.1) | (0,0) | 98.4 | 98.0 | 96.8 | 97.8 | 97.7 | 90.8 | 1.029 | [*] | 0.965 | 1.042 | 1.041 | – |
| (0,0.3) | 98.3 | 98.1 | 97.0 | 97.8 | 97.9 | 90.5 | 1.029 | [*] | 0.965 | 1.042 | 1.041 | – | ||
| (0,0.5) | 98.5 | 98.1 | 97.0 | 97.7 | 97.7 | 91.2 | 1.030 | [*] | 0.965 | 1.043 | 1.041 | – | ||
| (0,0.7) | 98.2 | 97.8 | 96.5 | 97.5 | 97.4 | 89.9 | 1.029 | [*] | 0.964 | 1.042 | 1.040 | – | ||
| (0,0.9) | 98.1 | 97.8 | 96.7 | 97.7 | 97.7 | 90.0 | 1.030 | [*] | 0.964 | 1.042 | 1.041 | – | ||
| (0.2,0.2) | (0,0) | 98.1 | 97.7 | 96.7 | 97.5 | 97.5 | 90.1 | 1.033 | [*] | 0.972 | 1.048 | 1.046 | – | |
| (0,0.3) | 97.8 | 97.5 | 96.3 | 97.3 | 97.3 | 90.2 | 1.033 | [*] | 0.972 | 1.047 | 1.046 | – | ||
| (0,0.5) | 98.1 | 97.8 | 96.8 | 97.4 | 97.4 | 90.5 | 1.033 | [*] | 0.972 | 1.047 | 1.046 | – | ||
| (0,0.7) | 98.1 | 97.6 | 96.3 | 97.3 | 97.3 | 90.1 | 1.033 | [*] | 0.971 | 1.046 | 1.045 | – | ||
| (0,0.9) | 97.8 | 97.2 | 96.0 | 97.0 | 97.0 | 89.6 | 1.034 | [*] | 0.972 | 1.047 | 1.047 | – | ||
| (0.4,0.4) | (0,0) | 97.4 | 97.1 | 96.3 | 96.7 | 96.9 | 89.6 | 1.046 | [*] | 1.003 | 1.063 | 1.062 | – | |
| (0,0.3) | 97.6 | 97.3 | 96.4 | 96.8 | 96.8 | 89.7 | 1.046 | [*] | 1.004 | 1.063 | 1.062 | – | ||
| (0,0.5) | 98.2 | 97.4 | 96.6 | 97.2 | 97.1 | 89.5 | 1.046 | [*] | 1.003 | 1.062 | 1.062 | – | ||
| (0,0.7) | 97.5 | 97.1 | 95.9 | 96.6 | 96.6 | 88.7 | 1.046 | [*] | 1.004 | 1.063 | 1.062 | – | ||
| (0,0.9) | 97.6 | 96.9 | 96.0 | 96.6 | 96.7 | 88.5 | 1.046 | [*] | 1.004 | 1.063 | 1.063 | – | ||
| (50,100) | (0.1,0.1) | (0,0) | 96.7 | 96.3 | 94.1 | 96.4 | 96.2 | 91.6 | 1.016 | [*] | 0.921 | 1.026 | 1.025 | – |
| (0,0.3) | 96.7 | 96.5 | 94.3 | 96.3 | 96.3 | 92.3 | 1.016 | [*] | 0.922 | 1.026 | 1.025 | – | ||
| (0,0.5) | 96.7 | 96.5 | 93.9 | 96.3 | 96.1 | 92.0 | 1.015 | [*] | 0.921 | 1.026 | 1.025 | – | ||
| (0,0.7) | 96.5 | 96.3 | 93.8 | 96.0 | 96.0 | 92.0 | 1.016 | [*] | 0.922 | 1.026 | 1.025 | – | ||
| (0,0.9) | 97.1 | 96.7 | 94.2 | 96.6 | 96.5 | 92.1 | 1.016 | [*] | 0.921 | 1.025 | 1.025 | – | ||
| (0.2,0.2) | (0,0) | 96.0 | 95.5 | 93.2 | 95.5 | 95.4 | 90.4 | 1.017 | [*] | 0.923 | 1.029 | 1.028 | – | |
| (0,0.3) | 96.7 | 96.5 | 94.0 | 96.5 | 96.4 | 91.3 | 1.017 | [*] | 0.922 | 1.029 | 1.028 | – | ||
| (0,0.5) | 96.3 | 95.9 | 93.5 | 95.8 | 95.7 | 90.8 | 1.018 | [*] | 0.923 | 1.029 | 1.028 | – | ||
| (0,0.7) | 96.6 | 96.3 | 93.8 | 96.1 | 96.1 | 91.0 | 1.016 | [*] | 0.923 | 1.028 | 1.027 | – | ||
| (0,0.9) | 96.7 | 96.1 | 93.7 | 96.2 | 96.2 | 91.2 | 1.018 | [*] | 0.923 | 1.029 | 1.028 | – | ||
| (0.4,0.4) | (0,0) | 96.1 | 95.5 | 93.2 | 95.4 | 95.4 | 89.5 | 1.023 | [*] | 0.932 | 1.035 | 1.035 | – | |
| (0,0.3) | 96.4 | 95.8 | 93.0 | 95.8 | 95.7 | 89.3 | 1.023 | [*] | 0.933 | 1.036 | 1.036 | – | ||
| (0,0.5) | 96.3 | 95.6 | 93.2 | 95.7 | 95.6 | 89.3 | 1.023 | [*] | 0.933 | 1.036 | 1.036 | – | ||
| (0,0.7) | 96.3 | 96.0 | 93.6 | 96.0 | 95.9 | 90.1 | 1.023 | [*] | 0.932 | 1.035 | 1.036 | – | ||
| (0,0.9) | 96.2 | 95.8 | 93.7 | 95.8 | 95.9 | 89.4 | 1.024 | [*] | 0.933 | 1.036 | 1.037 | – | ||
Notes:
[*]: HPD-Rul satisfies the criteria.
Bold denotes the best-performing CI.
An empirical application
Duangdai & Likasiri (2017) predicted the global temperature, and forest and seasonal rainfall amount in northern Thailand by various mathematical models. Their results indicate that during 1973–2008, the rainfall fluctuation during the rainy season was less than the summer rainfall, although the forest cover was higher in the summer than in the rainy season. Approximately 60% of the total arable land in the northeast has been turned over to rice cultivation (Nicely & Counselor, 2018). Importantly, both the northern and northeastern regions of Thailand are important agricultural areas where the planted rice is rain-fed and is the most valuable crop in the Lower Mekong Basin (Zhang et al., 2014). These findings led us to focus on the rainfall amounts in the northern and northeastern areas in Thailand, especially regarding rainfall variation in the rainy season. Importantly, a comparison of the rainfall in the northern and northeastern regions in terms of the ratio of variances was investigated and estimated with our proposed CIs. There were 272 substations in total for both regions to record rainfall measurements by the Thai Meteorological Center. The 272 rainfall observed values contained 40 of 62 (64.52%) and 145 of 210 (69.05%) positive records in the north (62 substations) and northeast (210 substations) areas during 2–8 July 2018, respectively. The remainder were zero observations for both sets.
To examine for normality, a Q–Q plot of the log-transformed positive rainfall amounts for the two areas are plotted in Fig. 1. Histograms also confirmed the fitted distributions of the northern and northeastern region rainfall records, as shown in Fig. 2. Moreover, Table 3 report the AIC results to check the fitted distribution of the positive rainfall observations for both areas. The results show that the positive rainfall for both had lognormal distributions, while the fact that the records contained zero values implies that both sets fit delta-lognormal distributions. The approximation of rainfall dispersion ratio between north and northeast areas is θ = −1.674 [ratio = exp(−1.674) = 0.187] where the variance (ω1, ω2) = (448.34, 2,390.93); the basic statistics are (n1, n2) = (62,210); ; and . From the results, the 95%CIs for exp (θ) given in Table 4 indicate that HPD-NG and MOVER were better for situation S1 [(μ1,μ2) = (3, 3); and (δ1,δ2) = (0.3,0.3)].
| Regions | AIC | ||||||
|---|---|---|---|---|---|---|---|
| Exponential | Weibull | Lognormal | Normal | t-distribution | Cauchy | Logistic | |
| Northern | 316.677 | 317.046 | 314.927 | 348.812 | 332.373 | 336.093 | 337.678 |
| Northeastern | 1,232.797 | 1,231.199 | 1,227.468 | 1,411.599 | 1,332.576 | 1,331.557 | 1,376.586 |
Note:
Bold denotes the lowest AIC.
| Methods | 95% CIs for exp (θ) | Length | |
|---|---|---|---|
| Lower | Upper | ||
| HPD-Jef | 0.0455 | 0.9255 | 0.8800 |
| HPD-Rul | 0.0477 | 0.9239 | 0.8762 |
| HPD-NG | 0.0546 | 0.7793 | 0.7247 |
| GCI | 0.0464 | 0.9860 | 0.9396 |
| FGCI | 0.0652 | 1.1484 | 1.0832 |
| MOVER | 0.0512 | 0.5896 | 0.5384 |
As mentioned previously, the results can be interpreted as the rainfall variability in the northern region being less than the northeastern one during 2–8 July 2018, which implies that growing rice in the northeastern region was probably more affected than in the northern region because the former’s rain variation was larger. It is possible that this information could influence approximately 60% of the total arable area in the northeast. Note that Nicely & Counselor (2018) estimated 70% of rice production during the marketing year 2018–2019 cultivated under desirable weather conditions. This analysis might provide useful information to the Royal Thai Government to carry out effective water management. Our findings made a few realizations about natural disasters due to climate change during the rainy season in the northern and northeastern Thailand as well. The results are also in agreement with the simulation study ones in Table 1.
Discussion
The HPD-NG was proposed for constructing confidence intervals for comparing the rainfall dispersion in north and northeast regions. How to select the prior in this situation is that we found the CP performance of HPD depend on the posterior densities of σ2 and δ in the previous study. To our knowledge, we believed that μ and σ2 might be suitable for random variables of the normal and gamma distributions, respectively. This becomes the normal-gamma prior of (μ,σ2). For δ, it was motivated by Jeffreys’ prior, while a beta distribution was also developed and recommended by Jin, Thulin & Larsson (2017) so that beta (d,d) becomes a prior of δ in this study.
The difference between HPD-Jef and HPD-Rul is the posterior densities of σ2 and δ, although it can be seen from the results of the simulation study that HPD-Rul’s outcomes were agreement with Harvey & Van der Merwe (2012) when focusing on the ratio of delta-lognormal means. This implies that both HPD performances are dependent on the posterior of σ2 and δ. For the proposed HPD-NG, its prior of τ = (μ,λ); λ = 1/σ2 is the inverse of the Jeffreys’ prior, leading us to obtain the posterior distributions of μ and σ2 derived from the NG prior under the assumption that the mean μ has a normal distribution and the precision λ has a gamma distribution. After that, the posterior of σ2 has a inverse-gamma distribution with its parameters (αi,ni(1),βi,ni(1)). Importantly, the parameter βi,ni(1) is different from the inverse-gamma based one on Jeffreys’ prior, resulting in a different posterior of μ as well. Likewise, the prior of δ was found and recommended by Jin, Thulin & Larsson (2017). For these reasons, the HPD-NG prior was developed to estimate the ratio between delta-lognormal variances. However, more research on this topic needs to be conduct to find an appropriate prior to obtain a better performance. Furthermore, MOVER could maintain its performance to satisfy the target criteria even with a small difference between the binomial proportions and small sample sizes. It is possible that an interval estimate for δ based on Wilson’s interval satisfies the criteria for small to moderate sample sizes, as confirmed by Donner & Zou (2011).
Conclusions
The purpose of this study was to develop CIs, namely HPD-NG and MOVER, for the ratio of delta-lognormal variances through Monte Carlo simulations. By way of comparison, both were examined to report their performance with the existing methods: HPD-Jef, HPD-Rul, GCI and FGCI. These proposed CIs were applied to estimate and compare the rainfall fluctuation between the northern and northeastern regions in Thailand in terms of the ratio of variances.
The findings of this study indicate that HPD-NG is the best and most recommended CI in situations S1 (with varied δ) for both equal and unequal medium sample sizes, and for a large difference between the binomial proportions for unequal large sample sizes. Both MOVER and HPD-Rul are the next best CIs recommended for a small difference between the binomial proportions with different sample sizes: MOVER for equal small sample sizes and HPD-Rul for unequal large sample sizes. For situation S2 where δ and μ are both varied, HPD-NG delivered the best performance for a small binomial proportion and both equal and unequal medium sample sizes as well as a small proportion of zeros for unequal large sample sizes. MOVER is also recommended for situations similar to situation S1, while HPD-Rul is recommended for a large proportion of zeros and unequal medium-to-large sample sizes. Although the CPs of HPD-Jef, GCI and FGCI results satisfied the criteria, their average lengths were wider than our proposed methods in all situations.
Note: In this paper, confidence intervals for the ratio variances of delta-lognormal are proposed, whereas, other submission proposed CIs for the difference between variances of delta-lognormal populations based on Herbert et al. (2011) and Krishnamoorthy, Lian & Mondal (2010). Although, the difference between them is that the former was considered to estimate the ratio of two delta-lognormal variances (ω1/ω2) using HPD-based normal gamma prior. The latter was presented HPDs based on other priors for the difference in delta-lognormal variances (ω1 − ω2) for large variational situations. According to Herbert et al. (2011) and Krishnamoorthy, Lian & Mondal (2010), the assessment of the range of distribution of (ω1 − ω2) can be estimated using CIs for (ω1 − ω2) such that it can be implied that there is the distributed range between (ω1 − ω2) and (ω1/ω2). Finally, both of random variables are used to check significantly difference in the two independent datasets. The next contrast between this submission and other one is the illustrated data that there are different dispersions and locations in each paper.