
Feature selection enhancement and feature space visualization for speech-based emotion recognition
- Published
- Accepted
- Received
- Academic Editor
- Othman Soufan
- Subject Areas
- Human-Computer Interaction, Artificial Intelligence, Data Mining and Machine Learning, Natural Language and Speech
- Keywords
- Feature selection, Feature space visualization, t-SNE graphs, SVM, Speech emotion recognition, Machine learning, Speaker-independent emotion recognition
- Copyright
- © 2022 Kanwal et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2022. Feature selection enhancement and feature space visualization for speech-based emotion recognition. PeerJ Computer Science 8:e1091 https://doi.org/10.7717/peerj-cs.1091
Abstract
Robust speech emotion recognition relies on the quality of the speech features. We present speech features enhancement strategy that improves speech emotion recognition. We used the INTERSPEECH 2010 challenge feature-set. We identified subsets from the features set and applied principle component analysis to the subsets. Finally, the features are fused horizontally. The resulting feature set is analyzed using t-distributed neighbour embeddings (t-SNE) before the application of features for emotion recognition. The method is compared with the state-of-the-art methods used in the literature. The empirical evidence is drawn using two well-known datasets: Berlin Emotional Speech Dataset (EMO-DB) and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) for two languages, German and English, respectively. Our method achieved an average recognition gain of 11.5% for six out of seven emotions for the EMO-DB dataset, and 13.8% for seven out of eight emotions for the RAVDESS dataset as compared to the baseline study.
Introduction
Speech is one of the most remarkable, natural, and immediate methods for individuals to impart their emotions (Akçay & Oğuz, 2020). The human voice reflects the emotional and psychological states of a person. The speech emotion recognition (SER) domain has been explored for more than two decades (Schuller, 2018). It is helpful in numerous applications that require human-machine interaction. SER is gaining attention in many fields like automatic speech processing, pattern recognition, artificial intelligence, and domains involving human-machine interaction (Lee & Narayanan, 2005). By recognizing speech emotions using artificial intelligence-based methods, the interaction between humans and machines can be made more natural and effective. SER is advantageous in specific areas like automatic SER systems could help reduce accident ratio by recognizing aggressive drivers and alerting other road users (Ji, Lan & Looney, 2006; Yang et al., 2017). In the health care field, SER systems could help physicians understand the actual emotional state (Harati et al., 2018). Automatic learning can be improved by recognizing learners’ emotions, alerting tutors, and suggesting changes to reduce negative emotions of boredom, frustration, and anxiety (Jithendran et al., 2020). The computer game industry may gain more natural interaction among game players and computers by exploiting audio emotion detection systems (Schuller, 2016). Hence, SER has significant value in improving lives in the digital era.
One of the challenging tasks in the design of a speech-based emotion recognition framework is the identification and extraction of features that proficiently describe diverse emotions and perform reliably (Zheng et al., 2019). Humans have the ability to recognize emotions using verbal and non-verbal cues. However, in the case of machines, a comprehensive set of features is required to perform emotion recognition tasks intelligently. Speech has a large range of features, however, not all of them play a significant role in distinguishing emotions (Özseven, 2019) and less important features need to be discarded by dimensionality reduction methods. One more thing which makes defining emotion boundaries even more difficult, is the presence of wide range of languages, accents, sentences, and speaking styles of the different speakers.
Further, there is no standardized feature set available in the literature and existing work in SER is based on the experimental studies so far (Akçay & Oğuz, 2020) and also, many of the existing SER systems are not as much accurate to be fully relied upon (Xu, Zhang & Khan, 2020). Among two broad categories of speech features: linguistic and paralinguistic, the later is more advantageous. The reason is paralinguistic features are helpful to recognize speech emotions irrespective of the language being spoken, the text being spoken and the accent being used (Hook et al., 2019). Their only dependence is on characteristics of speech signals such as tone, loudness, frequency, pitch, etc. In past, many researchers used paralinguistic attributes for SER, however, a universal set based on such cues has not established yet (El Ayadi, Kamel & Karray, 2011; Anagnostopoulos, Iliou & Giannoukos, 2015). Therefore, it is required to make improvements regarding the effective use of paralinguistic attributes for the SER. Out of various paralinguistic features, the most commonly used are prosodic, spectral, voice quality and Teager energy operator (TEO) (Akçay & Oğuz, 2020). Prosodic features portray the emotional value of speech (Tripathi & Rao, 2018) and are related to pitch, energy and, formant frequencies (Lee & Narayanan, 2005). Spectral features are based on the distribution of spectral energy throughout the speech range of frequency (Nwe, Foo & De Silva, 2003). Good examples of spectral features are Mel Frequency Cepstrum Coefficients (MFCC) and linear predictor features. Qualitative features are related to perceiving emotions by the quality of voice, e.g., voice level, voice pitch and temporal structure (Gobl & Chasaide, 2003). Teager Energy Operator (TEO) based features are related to vocal chord movement while speaking under stressful situations (Teager & Teager, 1990).
Some studies reported emotion recognition based on speech features combined with other modalities, for example, text (Lee & Lee, 2007), facial expressions (Nemati et al., 2019; Bellegarda, 2013) body signals, and outward appearances (Yu & Tapus, 2019; Ozkul et al., 2012) to fabricate multi-modal frameworks for emotion analysis. However in this work, we limit ourselves to emotion recognition explicitly from speech features only.
In this work, we use the features set of the INTERSPEECH 2010 challenge which is the combination of prosodic, spectral and energy-related features and have a large set of attributes, i.e., 1,582. Such a huge feature-space requires a good dimensionality reduction technique. One such technique most effectively used in speech research is principle component analysis (PCA) (Jolliffe & Cadima, 2016). The efficient use of PCA requires the removal of outliers and scaling the data (Sarkar, Saha & Agrawal, 2014). To apply PCA appropriately, we normalized the chosen feature set and discovered three subsets based on the types of speech features. The PCA is applied separately to each subset. We analyzed the finalized feature set thoroughly, by drawing t-SNE graphs for the two datasets. For classification, support vector machine (SVM) for One-Against-All is used. The results highlighted that appropriate selection of features and successful application of the feature selection method impacted the classification performance positively. The method achieved a decision-level correct classification rate of 71.08% for eight emotions using the RAVDESS dataset (Livingstone & Russo, 2018) and 82.48% for seven emotions using the EMO-DB dataset (Burkhardt et al., 2005). Furthermore, the proposed method outperformed the results of Yang et al. (2017), Venkataramanan & Rajamohan (2019), Tawari & Trivedi (2010).
Our contributions in this work are:
An improved speech emotion classification method using robust features.
An approach to apply features reduction technique on a subset of speech features.
An evaluation mechanism of the selected speech features using t-SNE visualization before applying a machine learning classifier.
The remainder of the article is composed as follows. “Literature review” provides a review of two key modules of speech-based emotion classification framework, i.e., speech features and classifiers. “Materials and methods” introduces the speech emotion datasets and assessment criteria utilized in this work. Evaluation results of the framework utilizing various databases and various situations are presented in “Experimental results and discussion”. Finally, “Conclusion” concludes the article.
Literature review
This section presents the previous work on speech-based emotion recognition with respect to selection of relevant speech features and machine learning methods used in SER systems.
Yang et al. (2017) opted for prosodic features mainly and used mutual information as a feature selection method to choose top-80 features for the recognition task. In Venkataramanan & Rajamohan (2019), few features such as MFCC, pitch, energy, and Mel-spectrogram were used, and the top-2 and top-3 accuracy of 84.13% and 91.38% respectively were achieved for the RAVDESS dataset. Fourier coefficients of the speech signal were extracted and applied on EMO-DB dataset in Wang et al. (2015), which came up with a recognition rate of 79.51%. Lugger & Yang (2007) used voice quality 85 and prosodic features in combination for emotion recognition. In Tripathi & Rao (2017), a speech-based emotion classification system was developed for the Bengali speech corpus. The classifiers used were ANN, KNN, SVMs, and naive Bayes. The maximum accuracy achieved was 89%. For robust emotion classification, an enhanced sparse representation classifier is proposed (Zhao, Zhang & Lei, 2014). The classifier performed better in both noisy and clean data in comparison to other existing classifiers. In Al Machot et al. (2011), a probability-based classifier, Bayesian quadratic discriminate was used to classify emotions. Classification accuracy of 86.67% on EMO-DB dataset was reported by reducing the calculation cost and using a small number of features. Another study reported an ensemble classification method for speech emotion classification on Thai speech corpus (Prasomphan & Doungwichain, 2018). The ensembled algorithms were SVM, KNN, and ANN to improve the accuracy. To make a comprehensive feature set, capable of performing well in all situations and supporting multiple languages, there is a need to include all the important speech emotion attributes. One such set of features available in the literature is INTERSPEECH 2010 paralinguistic challenge feature-set (Schuller et al., 2010). This feature-set is an extension of the INTERSPEECH 2009 paralinguistic emotion challenge feature-set (Schuller, Steidl & Batliner, 2009).
Materials and Methods
This section discusses the material and methods used in this research.
Data and preprocessing
The benchmark datasets used in this research are (EMO-DB) Burkhardt et al. (2005) and (RAVDESS) Livingstone & Russo (2018).
EMO-DB
The EMO-DB is an acted dataset of ten experts (five male and five female) kept in the German language. It comprises seven emotion classes: anger, boredom, fear, happiness, disgust, neutral, and sadness. There are numerous expressions of a similar speaker. Ten sentences, which are phonetically unbiased, are picked for dataset development. Out of these 10 sentences, five sentences are short (around 1.5 s length) and five are long sentences (roughly 4 s term). Every emotion class has an almost equivalent number of expressions to avoid the issue of under-sampling emotion class. There is a sum of 535 expressions in this dataset. The validity of the dataset is ensured by rejecting the samples having a recognition rate less than 80% in the subjective listening test. The metadata of the EMO-DB dataset is given in Table 1.
| Database | EMO-DB Burkhardt et al. (2005) |
|---|---|
| No. of speakers | 10 (five male, five female) |
| Language | German |
| Emotions | Anger, sadness, joy, fear boredom, disgust, neutral |
| No. of utterances | 535 |
| Style | Acted |
RAVDESS
RAVDESS is multi-modular database of emotional speech and song. There are 24 professional actors each uttering 104 unique intonations with emotions: happiness, sad, angry, fear, surprise, disgust, calm, and neutral. The RAVDESS dataset is rich and diverse and does not experience gender bias, which means it has an equal number of male and female utterances, comprises a wide range of emotions, and at various levels of emotional intensity. Each actor uses two different statements with two different emotional intensities; normal and strong emotions. The total number of utterances is 1,440. The information about the RAVDESS dataset is in Table 2.
| Database | RAVDESS Database Livingstone & Russo (2018) |
|---|---|
| No. of speakers | 24 (12 male, 12 female) |
| Language | English |
| Emotions | Anger, sadness, calm, surprise, happiness, fear disgust, neutral |
| No. of utterances | 1,440 |
| Style | Acted |
Preprocessing
The preprocessing step involved reading audio files, removing unvoiced segments, and framing the signal having 60 ms length.
Feature extraction
After preprocessing, we moved towards feature analysis which involved the extraction of useful features for speech emotion analysis. In this research, the OpenSMILE toolbox was used and the resulting feature-set was INTERSPEECH 2010 Challenge feature-set (Schuller et al., 2010). The reason for opting INTERSPEECH 2010 feature-set is because, it covers most of the features (namely, prosodic, spectral, and energy) effective for emotion recognition. The choice of initial features set is in line with the findings of Özseven & Düğenci (2018) which reported the effectiveness of these features for emotion recognition. INTERSPEECH 2010 feature-set consists of a total of 1,582 features. Upon a thorough analysis of the feature-set, we identified three subsets. The first subset consisted of 34 low-level descriptors (LLDs) with 34 corresponding delta co-efficients, having applied 21 functionals on each of it. This resulted in a subset of 1,428 features. The second subset was of 19 functionals applied to four pitch based LLDs with their corresponding four delta coefficients resulting in a total of 152 features. The third feature-set consisted only two features, which were pitch onset and duration.
Feature reduction technique
As the feature-set was huge, consisting of 1,582 features, we needed a good dimensionality reduction technique. For feature reduction in SER, some of the commonly used methods are forward feature selection (FFS), backward feature selection (BFS) (Pao et al., 2005), principle component analysis (PCA) and linear discriminant analysis (LDA) (Haq, Jackson & Edge, 2008; Özseven, Düğenci & Durmuşoğlu, 2018). Among these the most commonly used and applied in many studies is PCA (Chen et al., 2012; Scherer et al., 2015; Patel et al., 2011). PCA includes finding the eigenvalues and eigenvectors of the available covariance matrix and choosing the necessary number of eigenvectors comparing to the biggest eigenvalues to create a transformed matrix. We have fed the openSMILE INTERSPEECH 2010 feature-set of 1,582 features to the PCA and selected the top-100 features which we used for the classification task.
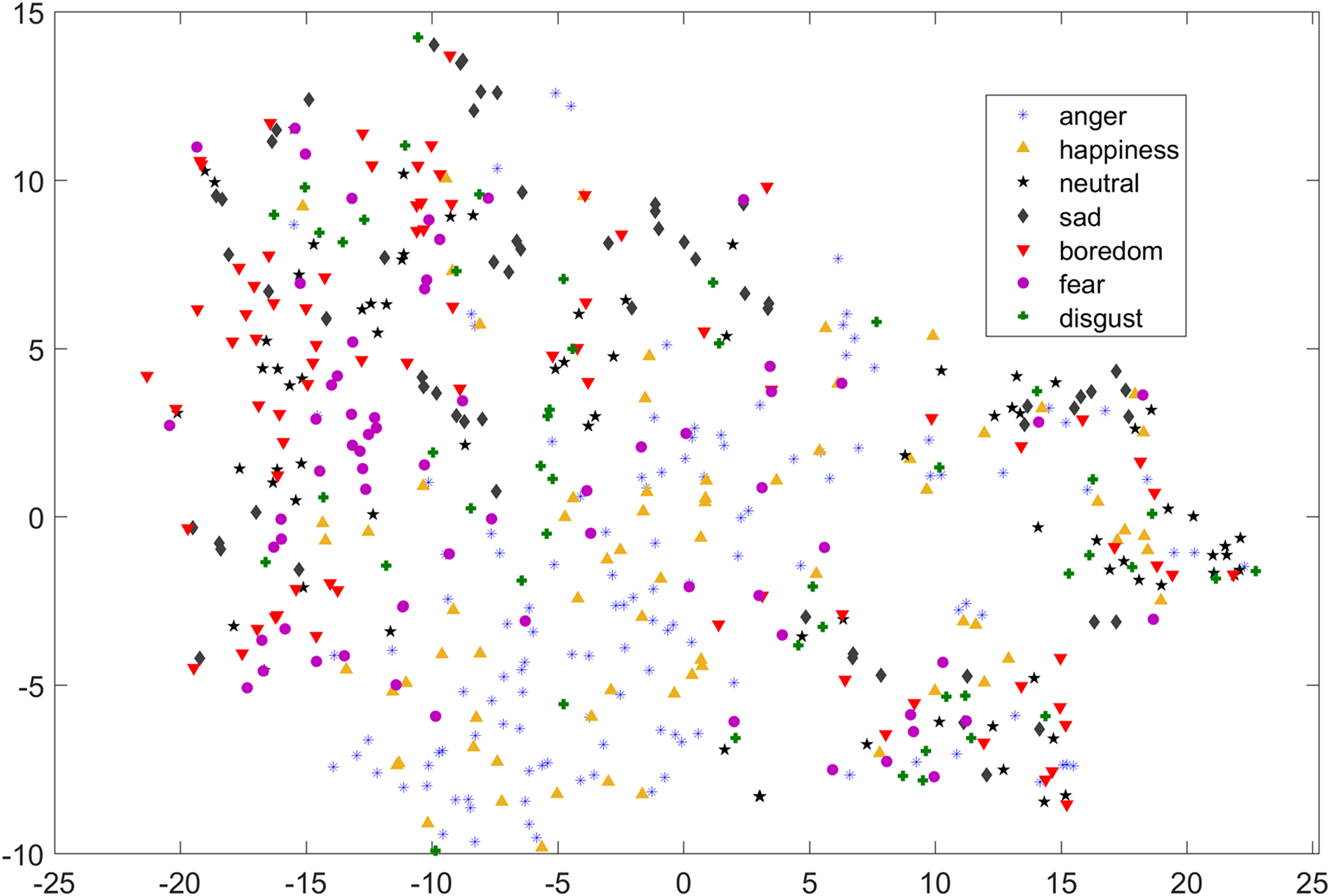
In Figs. 1 and 2, although we can see some clusters, however, most of the emotions are evenly distributed.
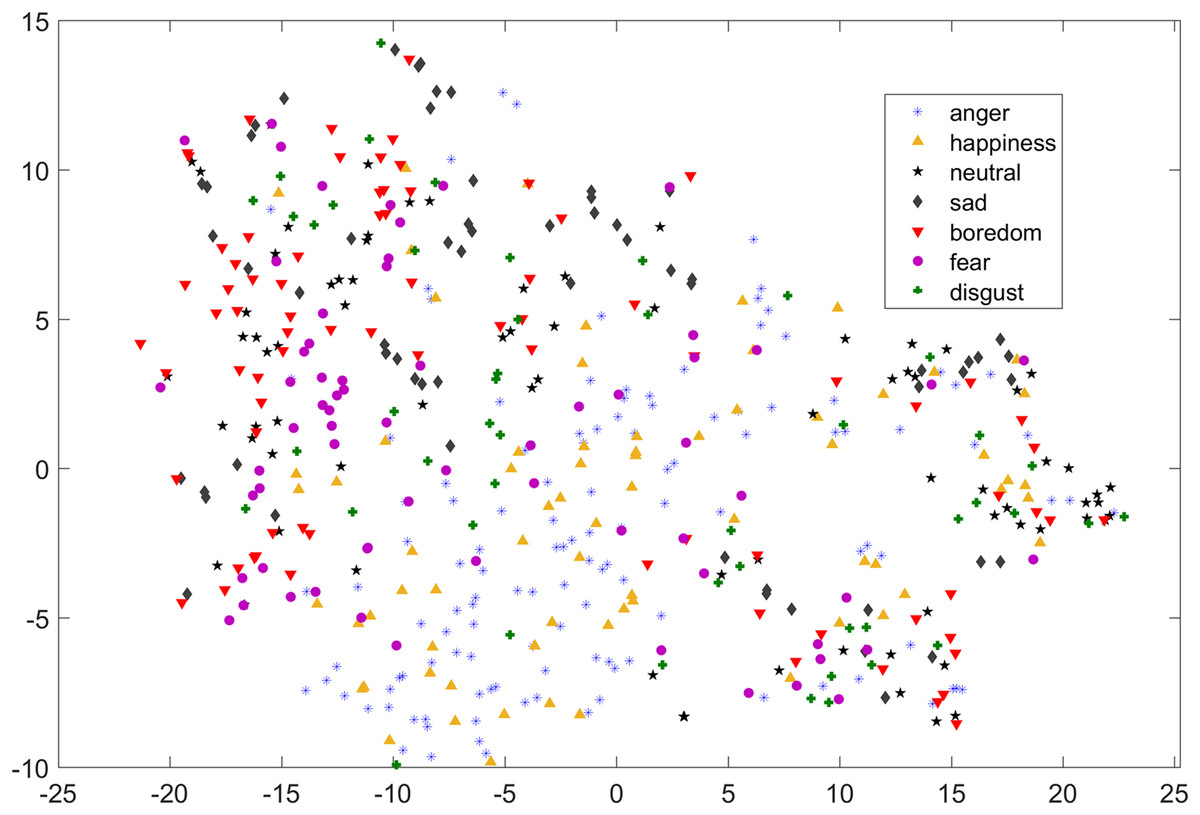
Figure 1: Two dimensional t-SNE graph of features used in Yang et al. (2017) for EMO-DB dataset.
{kind=link}
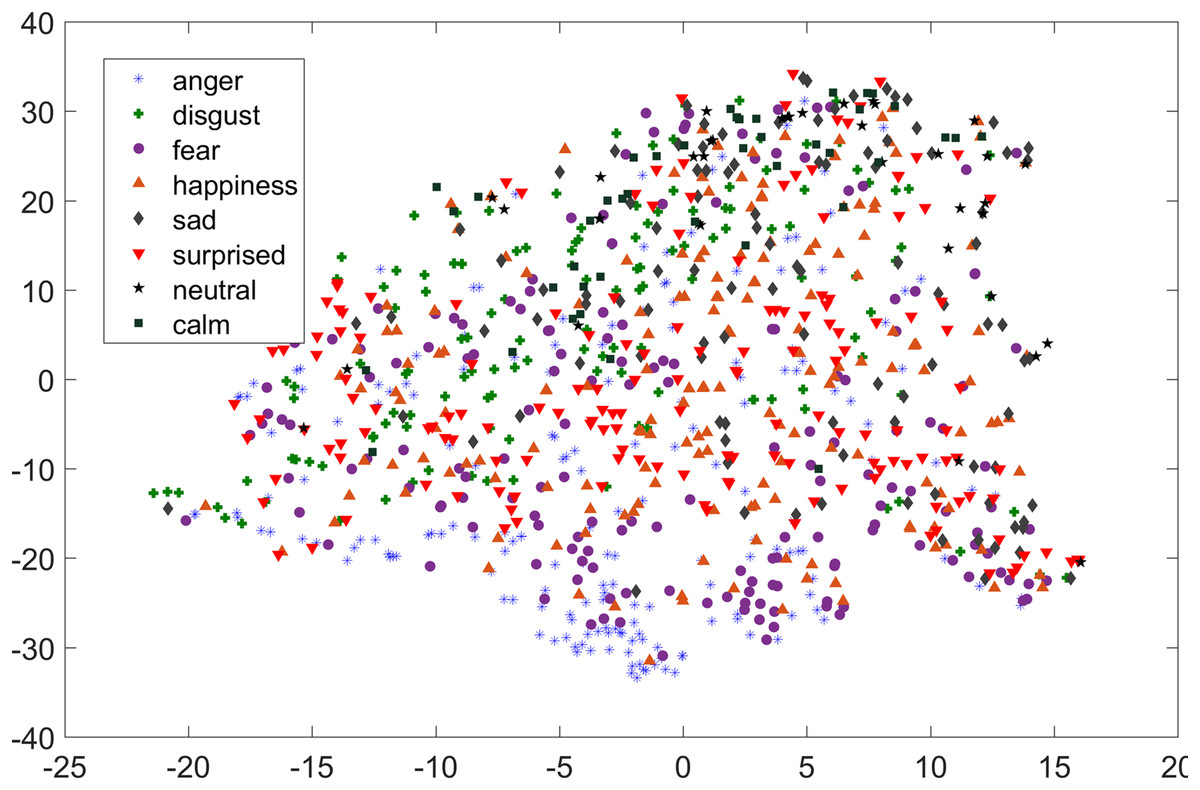
Figure 2: Two dimensional t-SNE graph of features used in Yang et al. (2017) for RAVDESS dataset.
{kind=link}
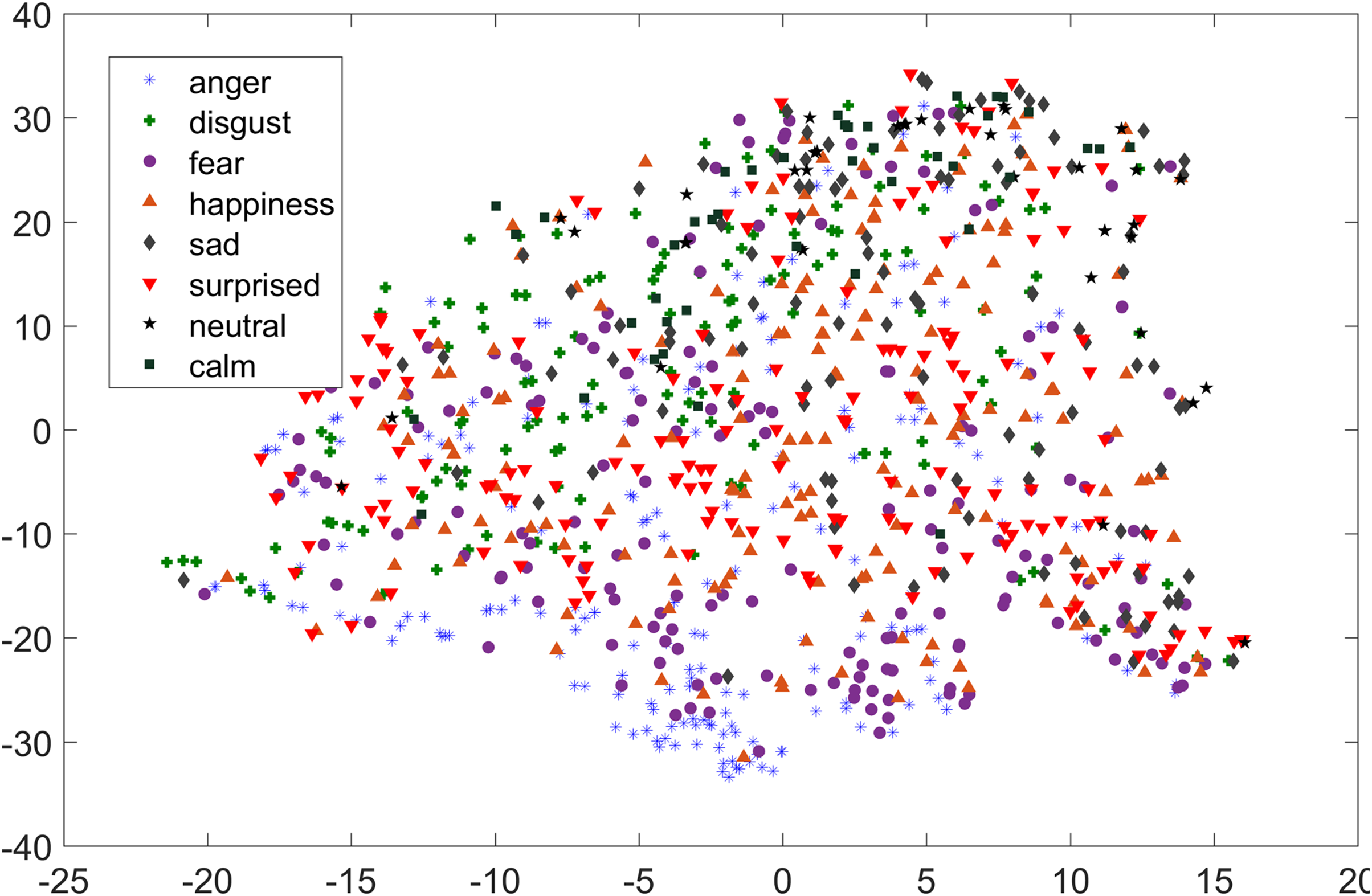
As compared to feature-set utilized by Yang et al. (2017), when we used INTERSPEECH 2010 challenge feature-set and applied PCA for features reduction, a clearer representation of clusters could be seen. In Fig. 3 for the EMO-DB dataset, emotion categories of sad, neutral, and boredom were distributed in relatively compact clusters in the feature-space such that high classification accuracy was anticipated. It is also noticeable from Fig. 3, that the data points for emotions such as happiness and anger were overlapping with each other giving a chance of misclassifying, however, overall classification of happiness and anger was not going to degrade due to being clustered at one side of feature-space. Likewise, two-dimensional representation of t-SNE of RAVDESS dataset is shown in Fig. 4. After using INTERSPEECH 2010 feature-set, there was a compact representation of clusters of anger, sadness, calm, and fear. Based on these observations, it was expected that overall classification accuracy for emotion classes would greatly improve.
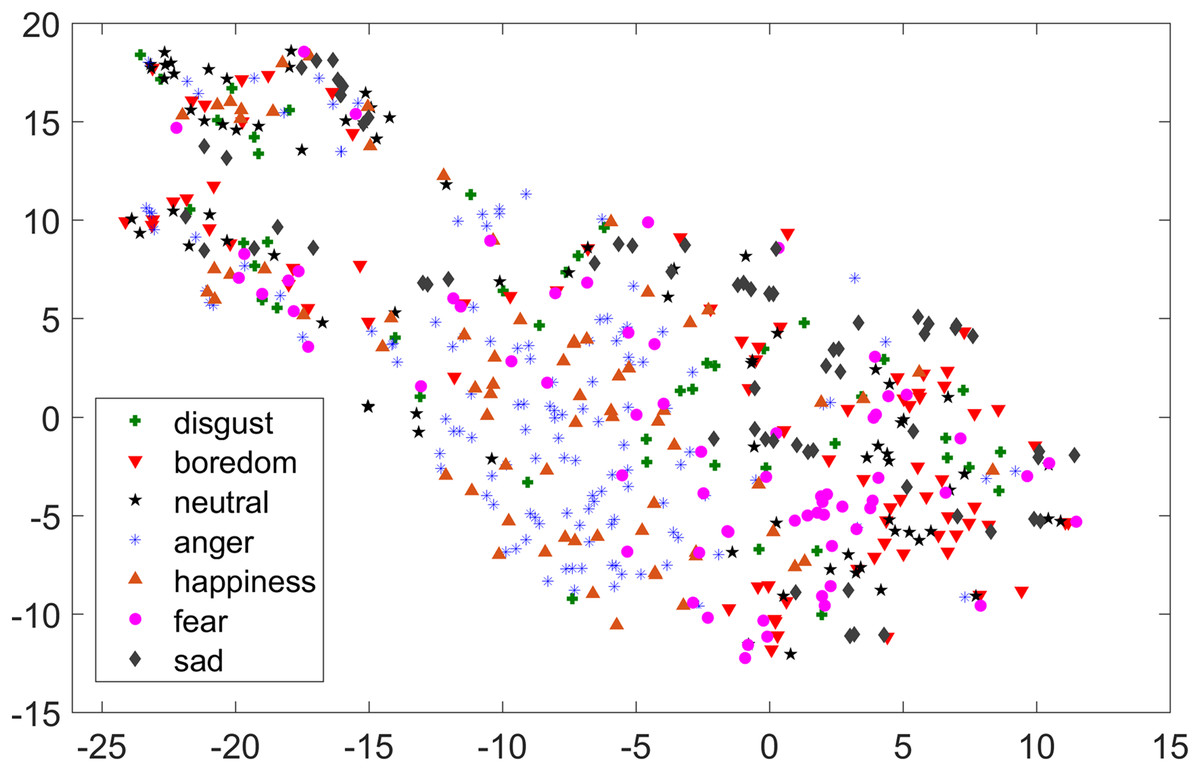
Figure 3: Two-dimensional t-SNE graphs of INTERSPEECH 2010 feature-set after applying PCA for feature reduction on EMO-DB dataset.
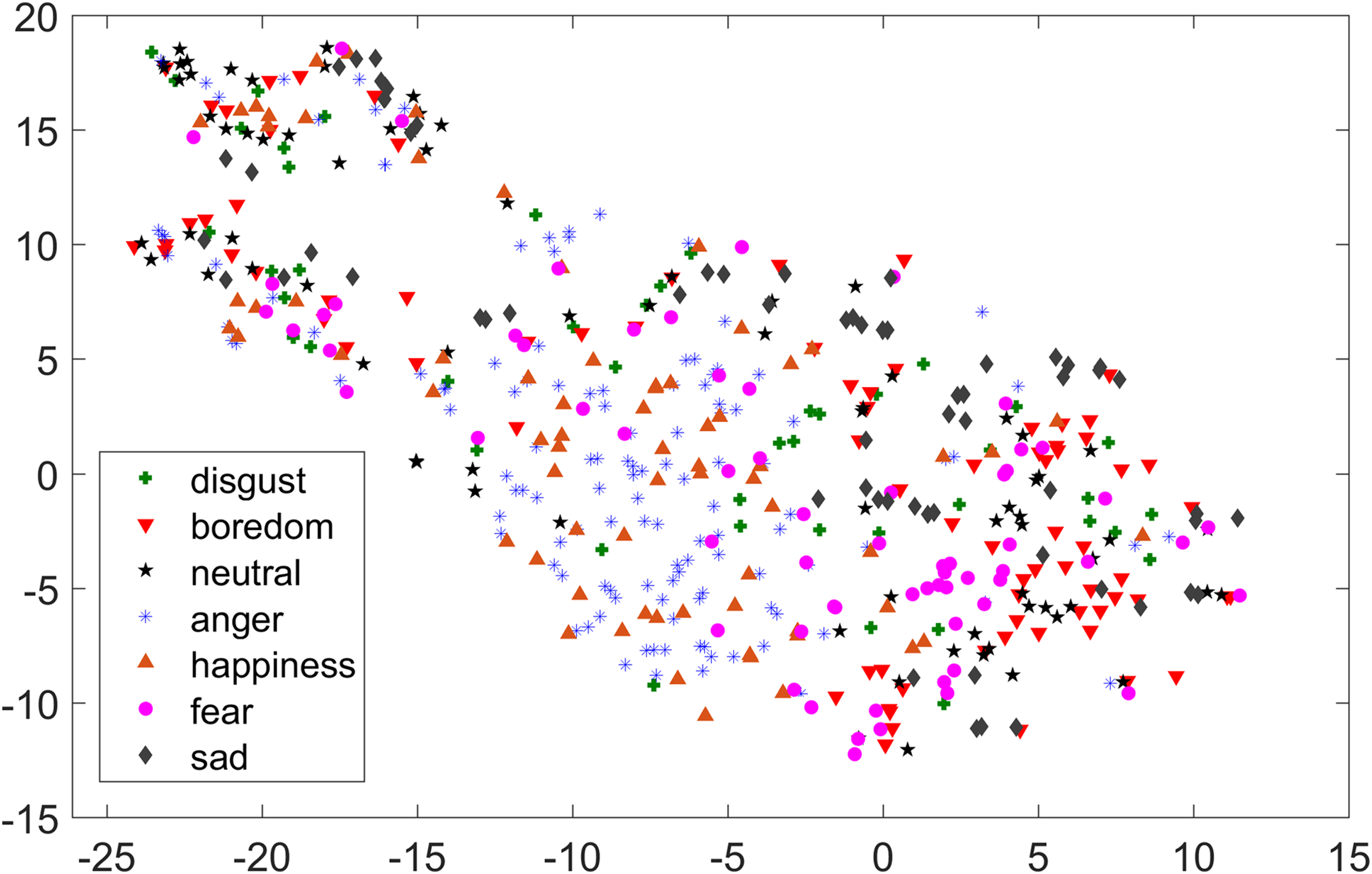{kind=link}
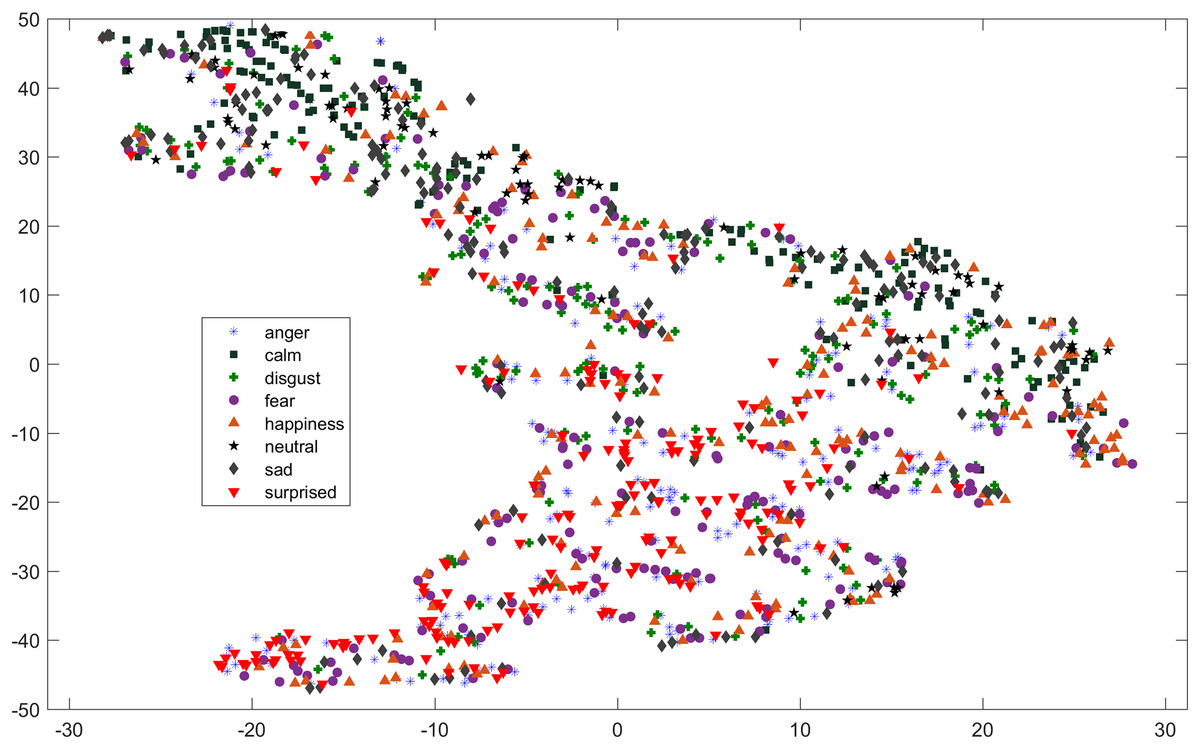
Figure 4: Two dimensional t-SNE graphs on RAVDESS dataset.
Two dimensional t-SNE graphs of features after using INTERSPEECH 2010 feature-set and applying PCA for feature reduction on RAVDESS dataset.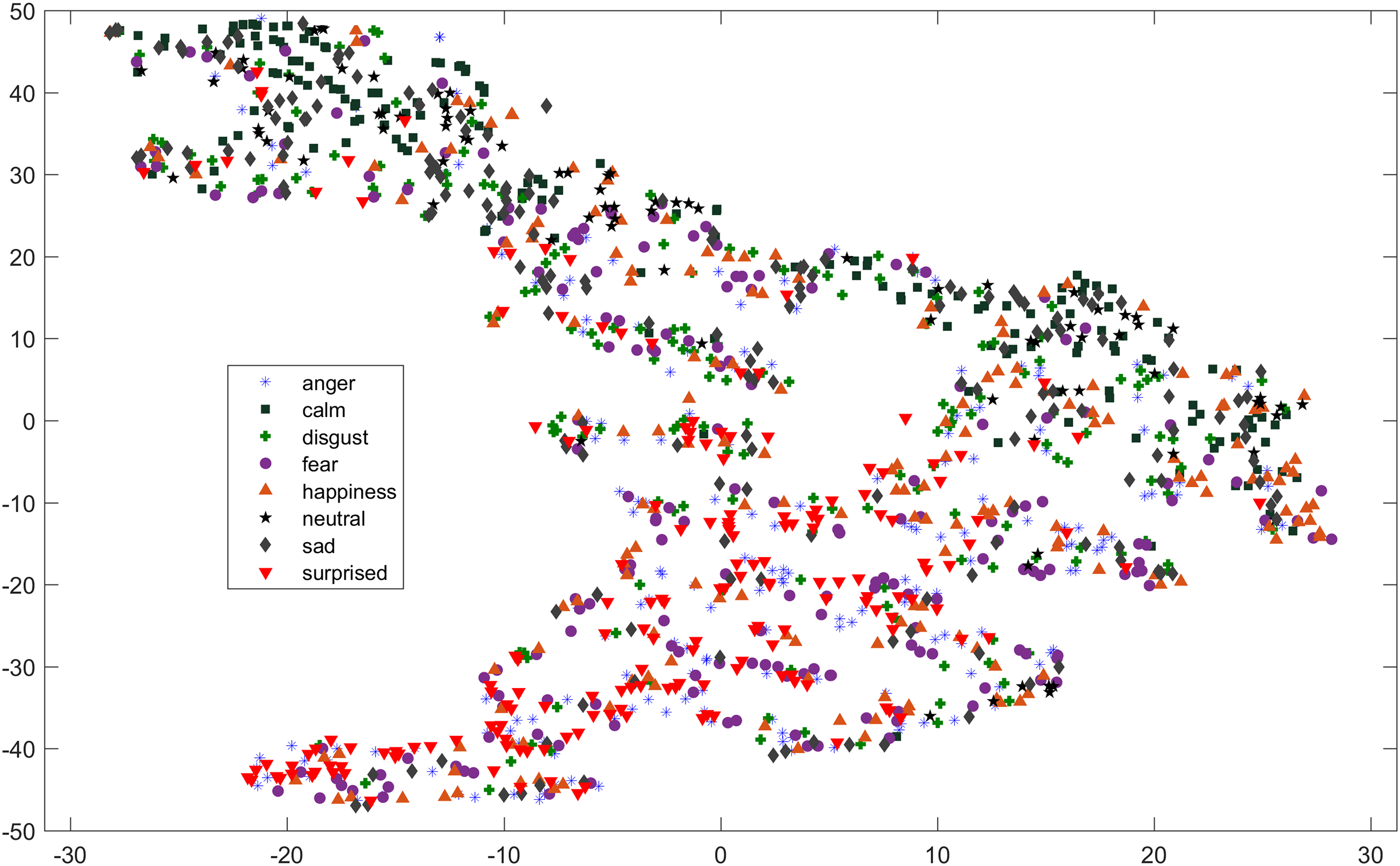{kind=link}
Computational setup
To compare the performance of selected features, the process is divided into two phases: training and testing. The One-Against-All SVM classifier was trained and validated with its respective parameters to obtain the optimal model for 70% of total samples. In the testing phase, the remaining 30% of the samples were used to test the model. The entire framework covering preprocessing, feature selection, and model representation is visualized in Fig. 5.
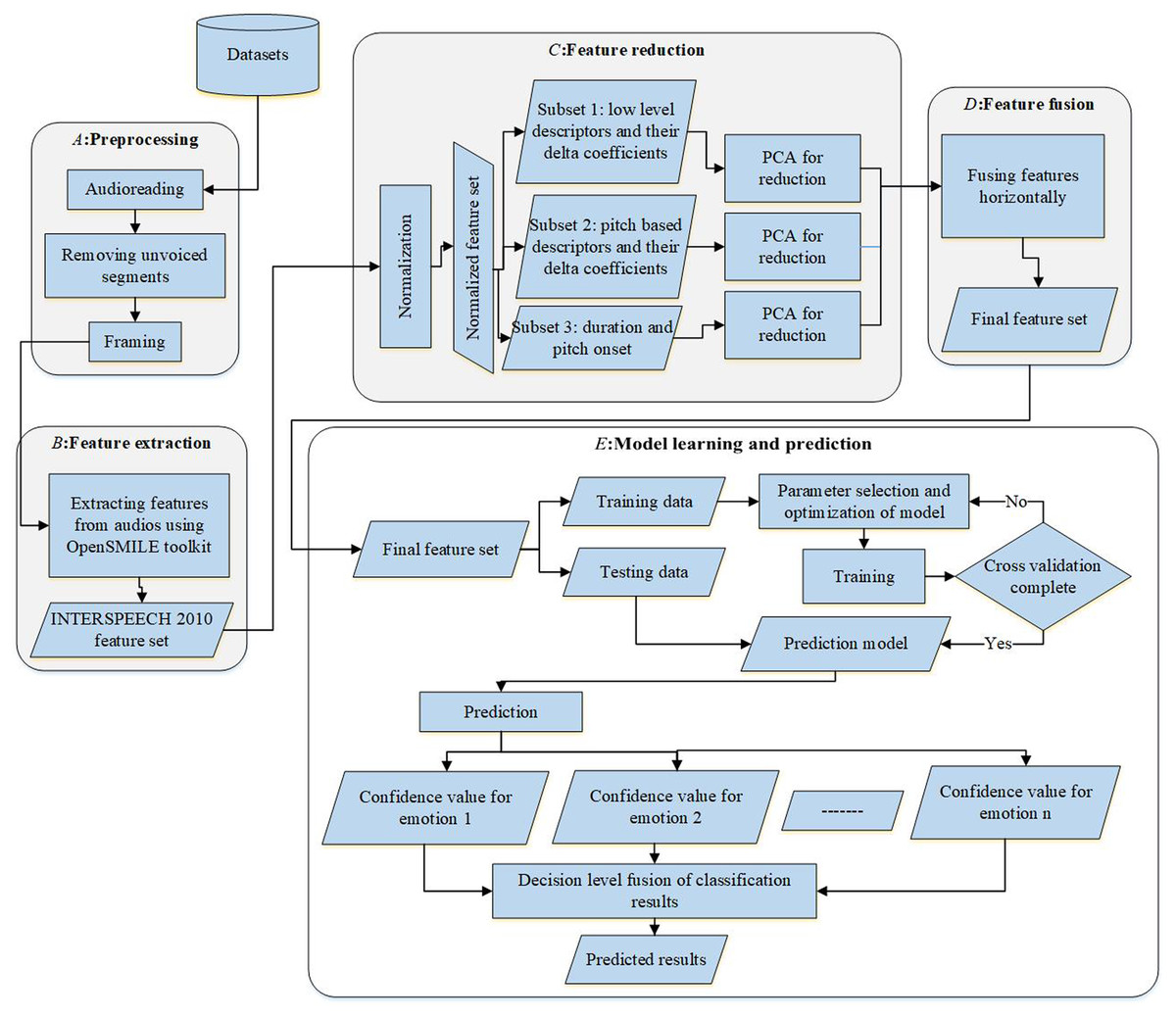
Figure 5: The computational model.
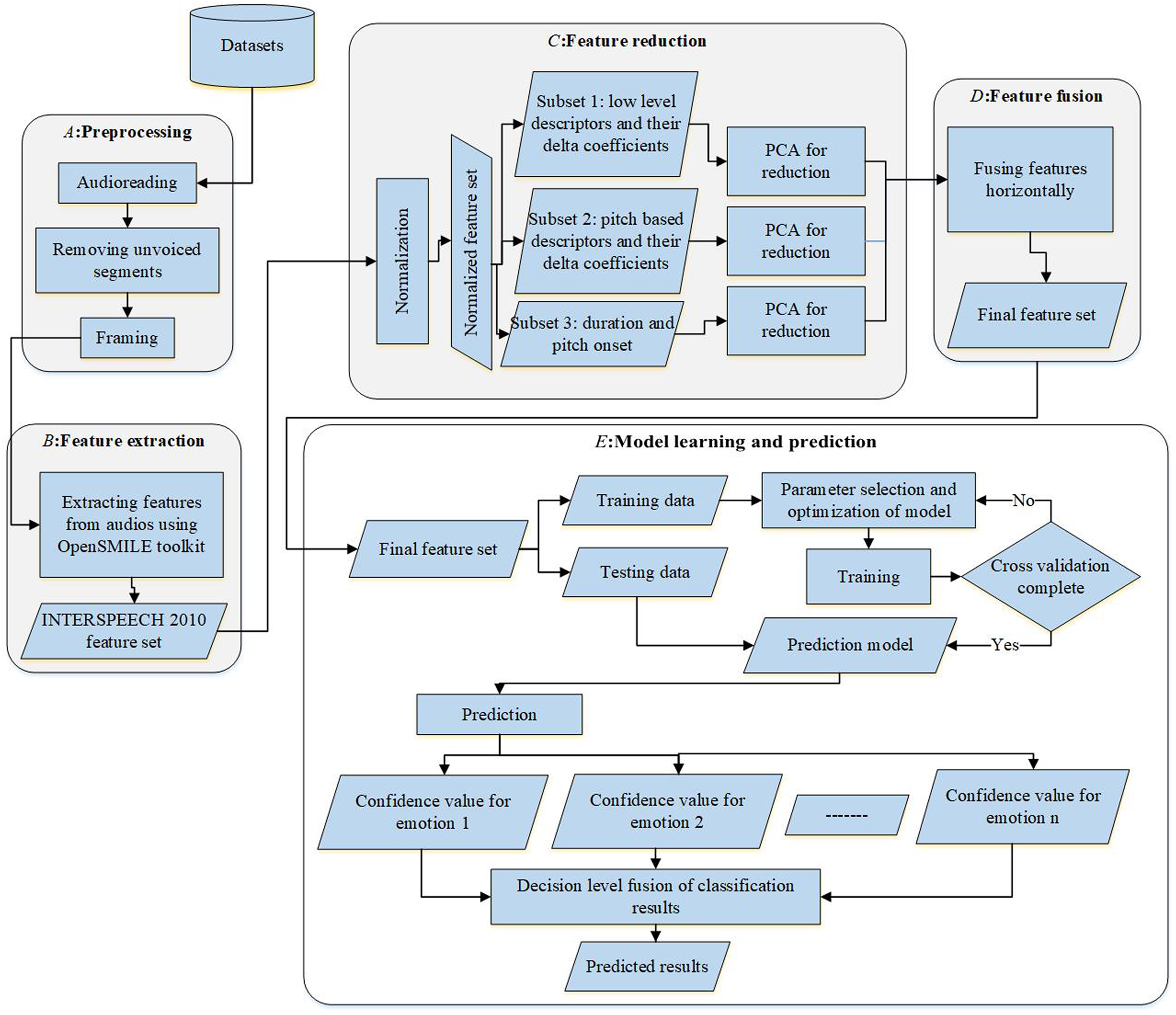{kind=link}
Experimental results and discussion
Performance evaluation scenarios
To evaluate the framework, along with metrics of accuracy and recall, two new metrics top-2 accuracy and top-3 accuracy are also introduced. Top-2 accuracy is the accuracy when the true class matches with any one of the two most probable classes predicted by the model and top-3 accuracy is the accuracy when the true class matches with any one of three most probable classes predicted by the model. The terminology used for evaluation is as follows:
The ratio of unclassified samples over all samples in the test set is known as the rejection rate. Average classification performance for all emotions after fusion is taken as decision-level-classification-rate. It is defined in Eq. (1).
(1) where denotes the number of true positive utterances of emotion class m1 to mn where n is the number of emotion classes and N is the total number of utterances.
To evaluate the emotion classification performance of each individual emotion, the metric we are using is decision level recall rate for emotion mi. Mathematically it is written as given in Eq. (2).
(2) where and denote the decision level true positive and true negative utterances for emotion mi, respectively.
Emotion classification performance
For analyzing the performance of our feature driven One-Against-All SVM based emotion classification method, the comparison with the state-of-the-art is performed. After that the performance improvement of the proposed method for general test and gender dependent test is presented. The baseline methods considered for comparison are Yang et al. (2017), and Venkataramanan & Rajamohan (2019). A summary of key features is shown in Table 3. In the later sections, we provide decision level emotion classification recall, top-2 accuracy and top-3 accuracy depending on which metric is provided by the reference method.
| Method | Dataset | Classifier | Features | Feature fusion | Feature selection |
|---|---|---|---|---|---|
| Our extended method | RAVDESS | SVM | INTERSPEECH 2010 (prosodic, spectral energy) | Yes | Yes |
| EMO-DB | |||||
| Venkataramanan & Rajamohan (2019) | RAVDESS | 2D CNN | Pure audio, log mel-spectrogram | No | No |
| Yang et al. (2017) | LDC | SVM | Prosodic features | No | Yes |
Performance comparison for general test
In general test performance comparison, the data samples from EMO-DB and RAVDESS datasets were used through seven-fold cross validation mechanism. In each round, one-seventh of the samples are kept for test. At the end, results are averaged over seven-folds.
The work of Yang et al. (2017) used LDC (Linguistic Data Consortium) dataset. The LDC Emotional Prosody Speech and Transcripts database is English database simulated by professional actors. The utterances consist of dates and numbers. Due to unavailability of LDC dataset freely, we employed the most frequently used freely available EMO-DB dataset (Burkhardt et al., 2005) and RAVDESS dataset Livingstone & Russo (2018) in this research. We reproduced the results of Yang et al. (2017) by using both datasets and reported the comparisons.
Comparison of average recall
The decision level average recall for each emotion of the two datasets for our method is compared with Yang et al. (2017) in Figs. 6 and 7.
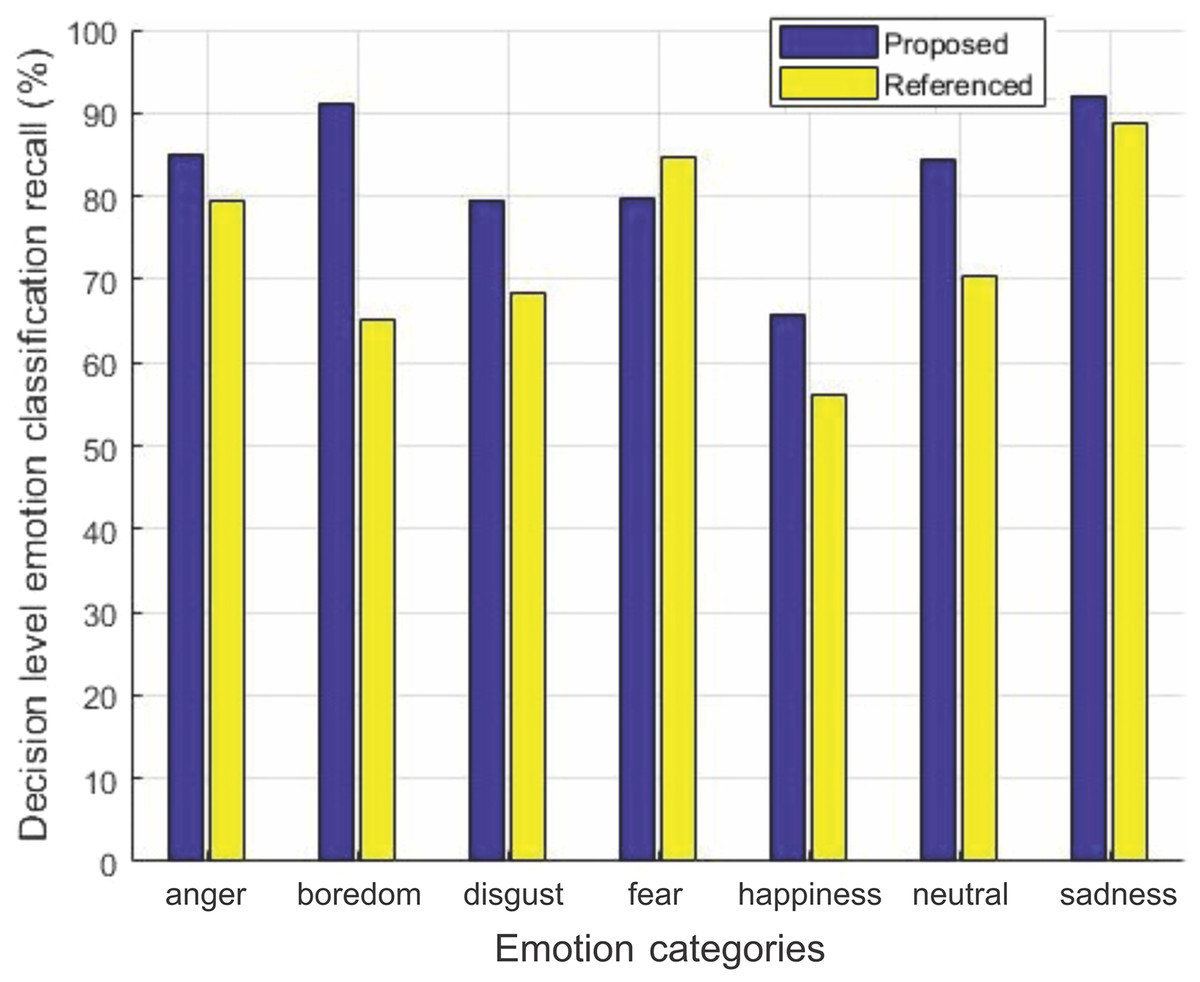
Figure 6: Decision-level emotion classification recall using EMO-DB dataset.
Decision-level emotion classification recall for each individual emotion for our method without rejecting any samples and the method in Yang et al. (2017), using EMO-DB dataset.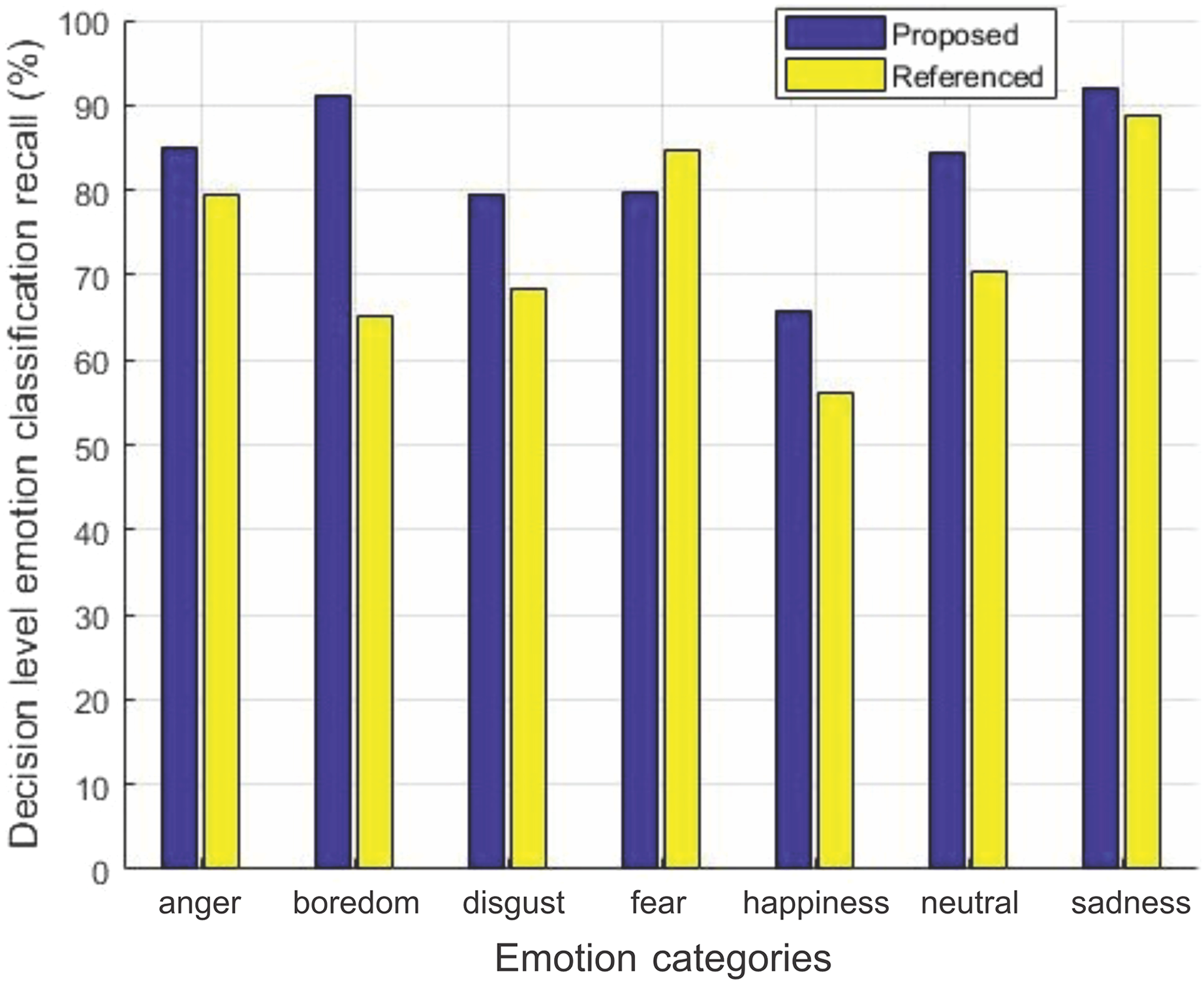{kind=link}
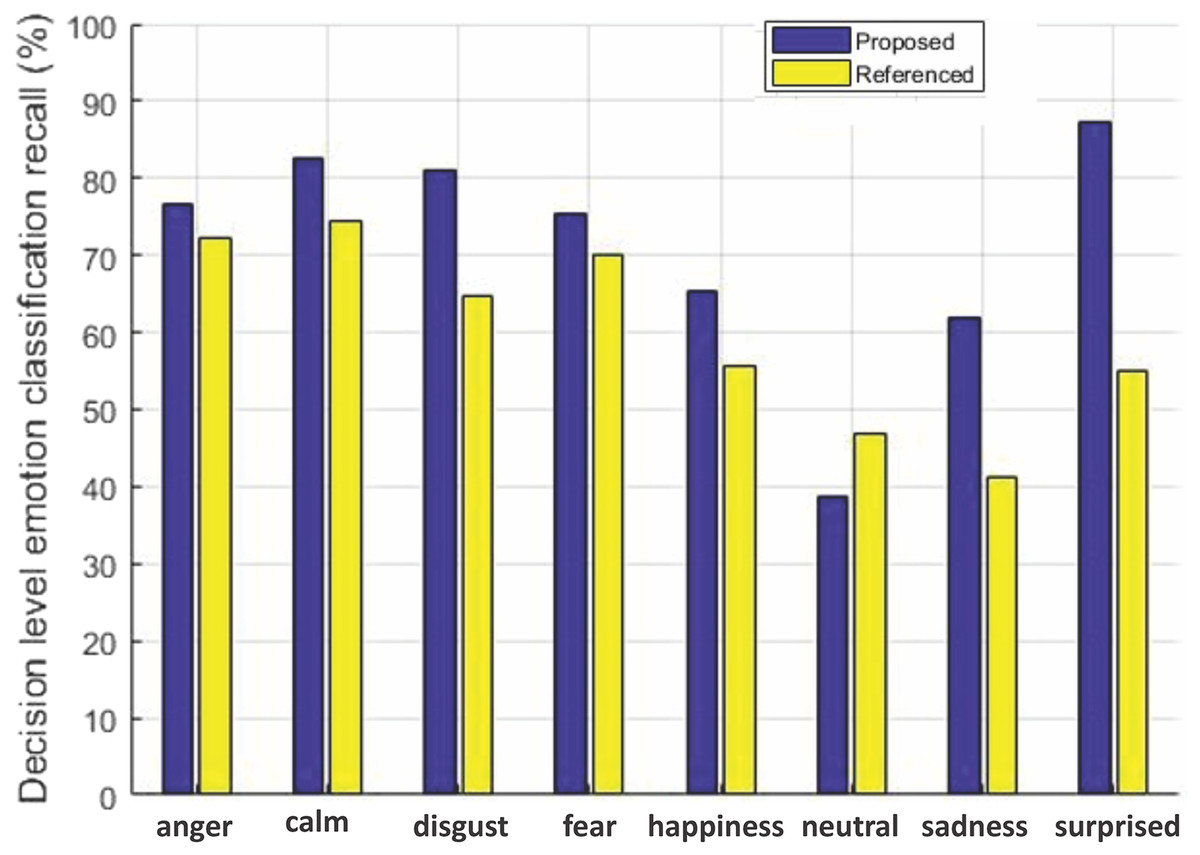
Figure 7: Decision-level emotion classification recall using RAVDESS dataset.
Decision-level emotion classification recall for each individual emotion for our method without rejecting any samples and the method in Yang et al. (2017), using RAVDESS dataset.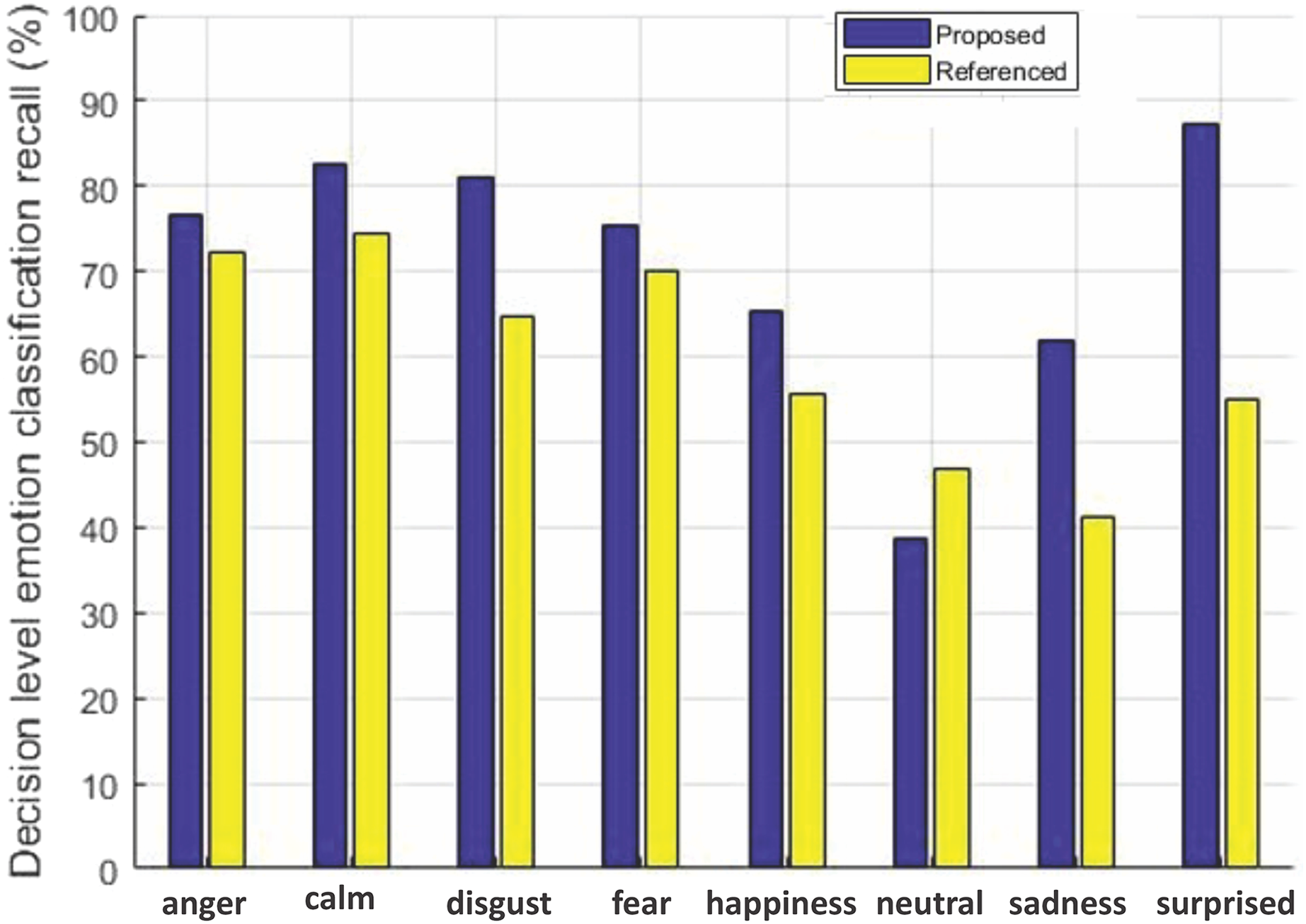{kind=link}
We can see from Fig. 6 that our method outperforms the baseline method in Yang et al. (2017) for six out of seven emotions using EMO-DB dataset. In the same way performance gain for seven out of eight emotions in case of RAVDESS dataset is achieved shown in Fig. 7. The average recall values for data samples of EMO-DB and RAVDESS datasets through seven rounds of cross validation and five upsampling are also given in Table 4.
| Dataset | Emotion | Yang et al. (2017) | Our method |
|---|---|---|---|
| EMO-DB | Disgust | 68.3673 | 79.5918 |
| Anger | 79.4903 | 84.9206 | |
| Happiness | 56.2337 | 65.7142 | |
| Fear | 84.6031 | 79.6825 | |
| Sadness | 92.0634 | ||
| Neutral | 70.3463 | 84.4155 | |
| Boredom | 65.1515 | 91.0173 | |
| RAVDESS | Disgust | 64.6593 | |
| Anger | 72.3356 | ||
| Happiness | 55.7183 | ||
| Fear | 70.1058 | ||
| Sadness | 41.0866 | ||
| Neutral | 38.6446 | ||
| Calm | 74.4523 | ||
| Surprised | 54.9450 |
Here in Table 4, the performance gain in terms of percentage is given. Our feature selection mechanism improved the recall rate for most of the emotions on both datasets as shown by highlighting the entries in bold.
Performance comparison using thresholding fusion
Here in this section, we are doing a comparison using a thresholding fusion mechanism. Thresholding fusion mechanism is an extension of the normal classification method (Vapnik, 1998). Here it is possible to output the class label only when it has a confidence score greater than certain threshold, otherwise it is rejected. In practice, such type of classification enhancement is needed when we are only concerned with samples having the high accuracy. For example, if a psychologist wanted to know when a patient, having some psychological disorder, at certain times feels emotionally high, thresholding fusion mechanism can be used.
General test comparison
Figures 8 and 9 show the decision-level correct classification rate when samples are rejected by gauging the confidence score.
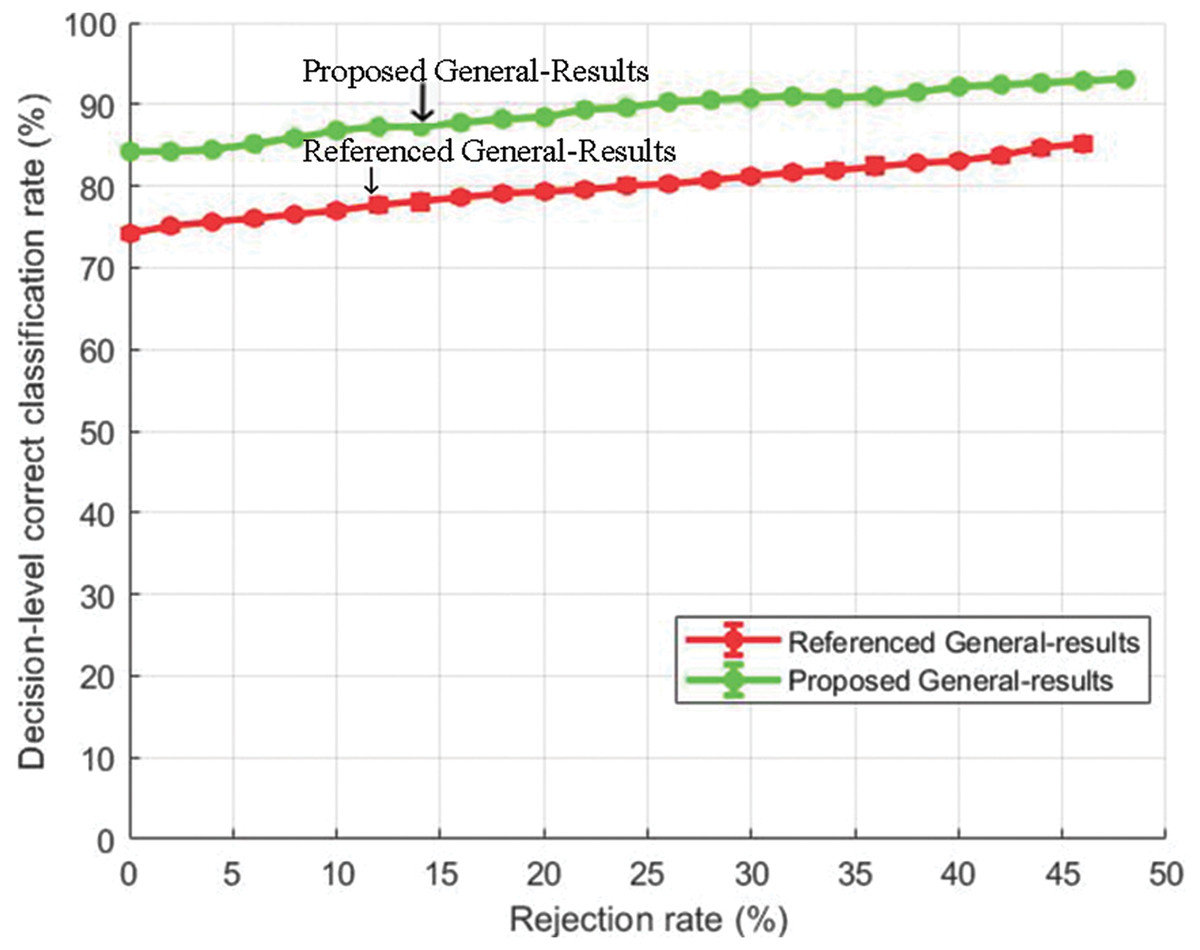
Figure 8: Decision-level correct classification rate vs rejection rate for general test of our method and the method of Yang et al. (2017) using EMO-DB dataset.
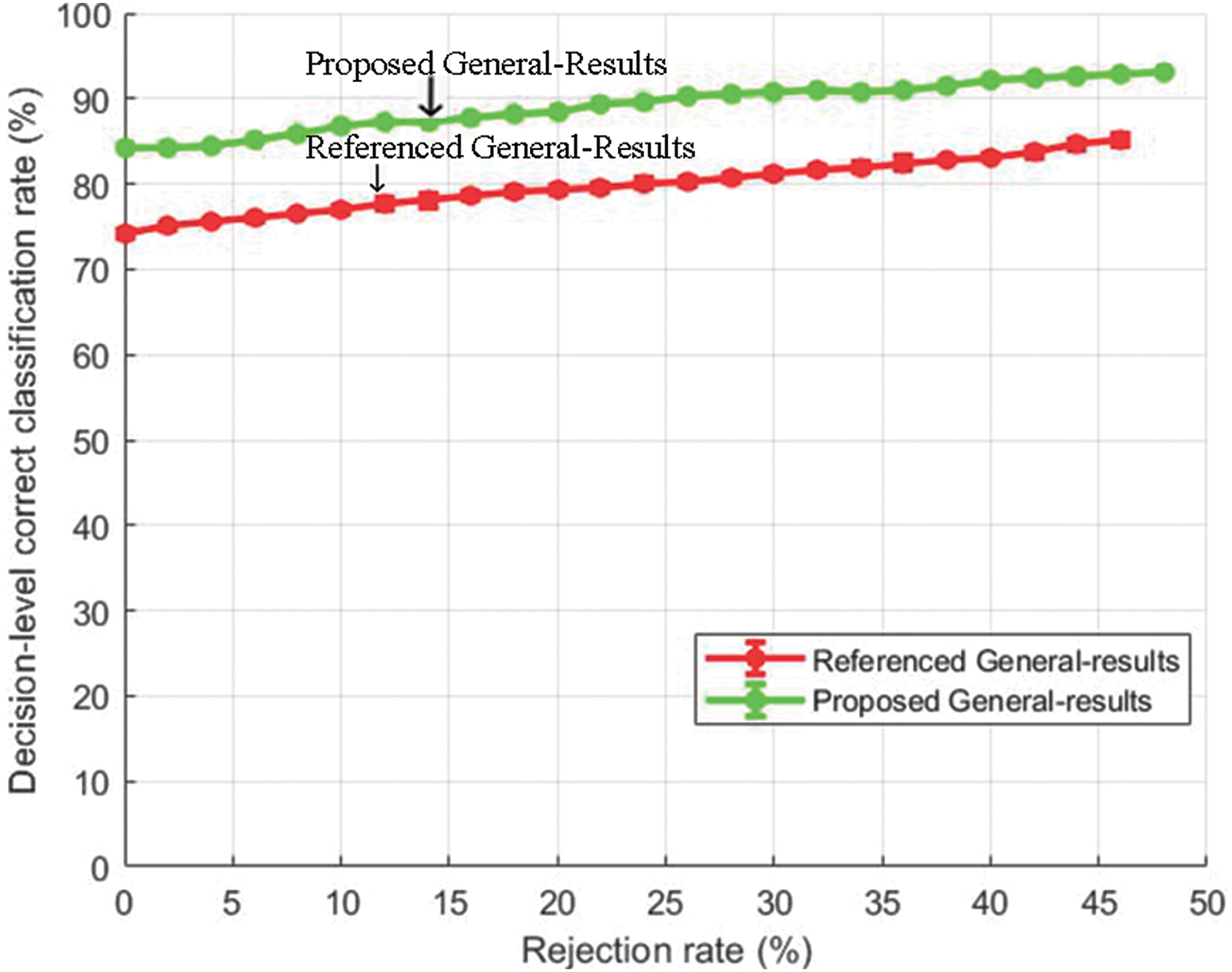{kind=link}
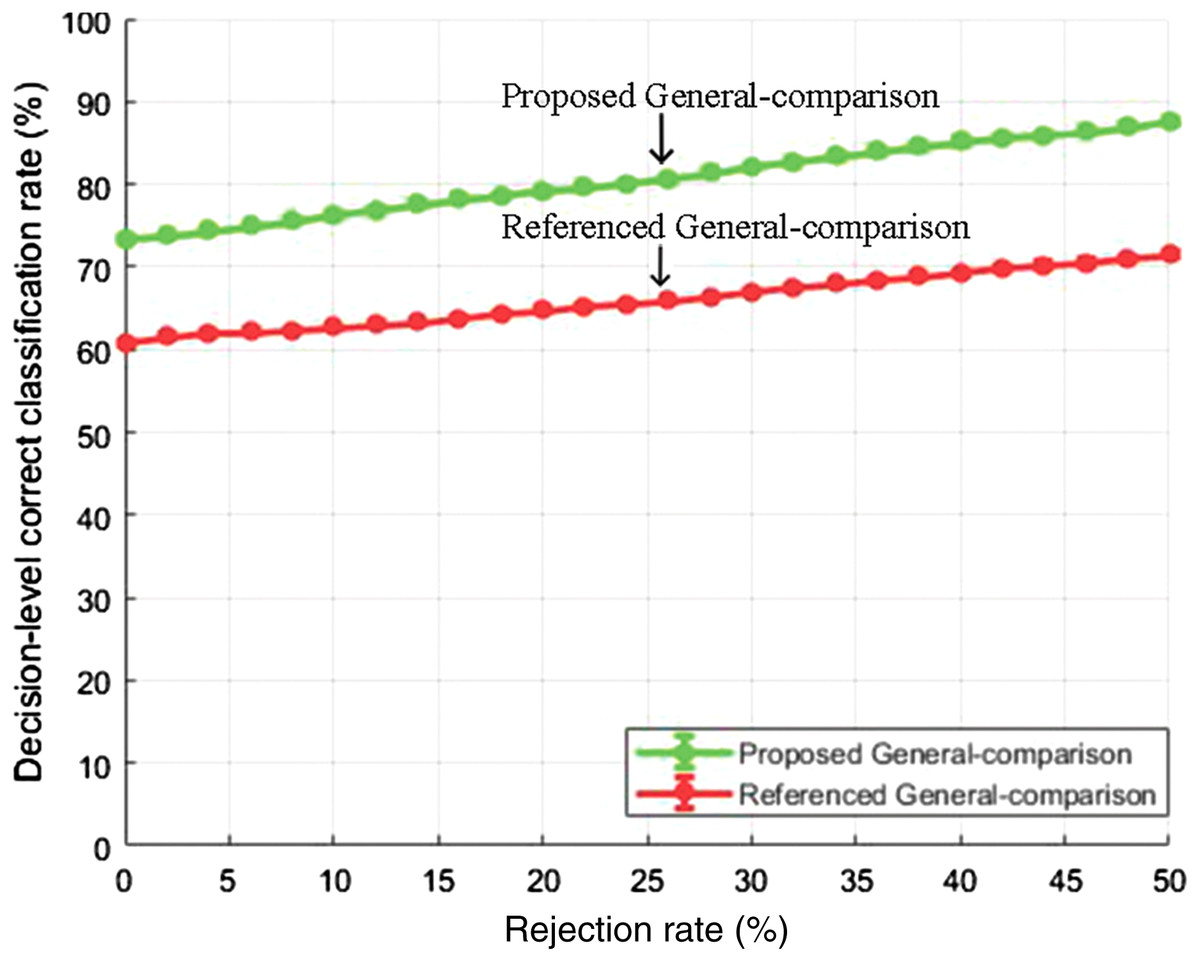
Figure 9: Decision-level correct classification rate vs rejection rate for general test of our method and the method in Yang et al. (2017) using RAVDESS dataset.
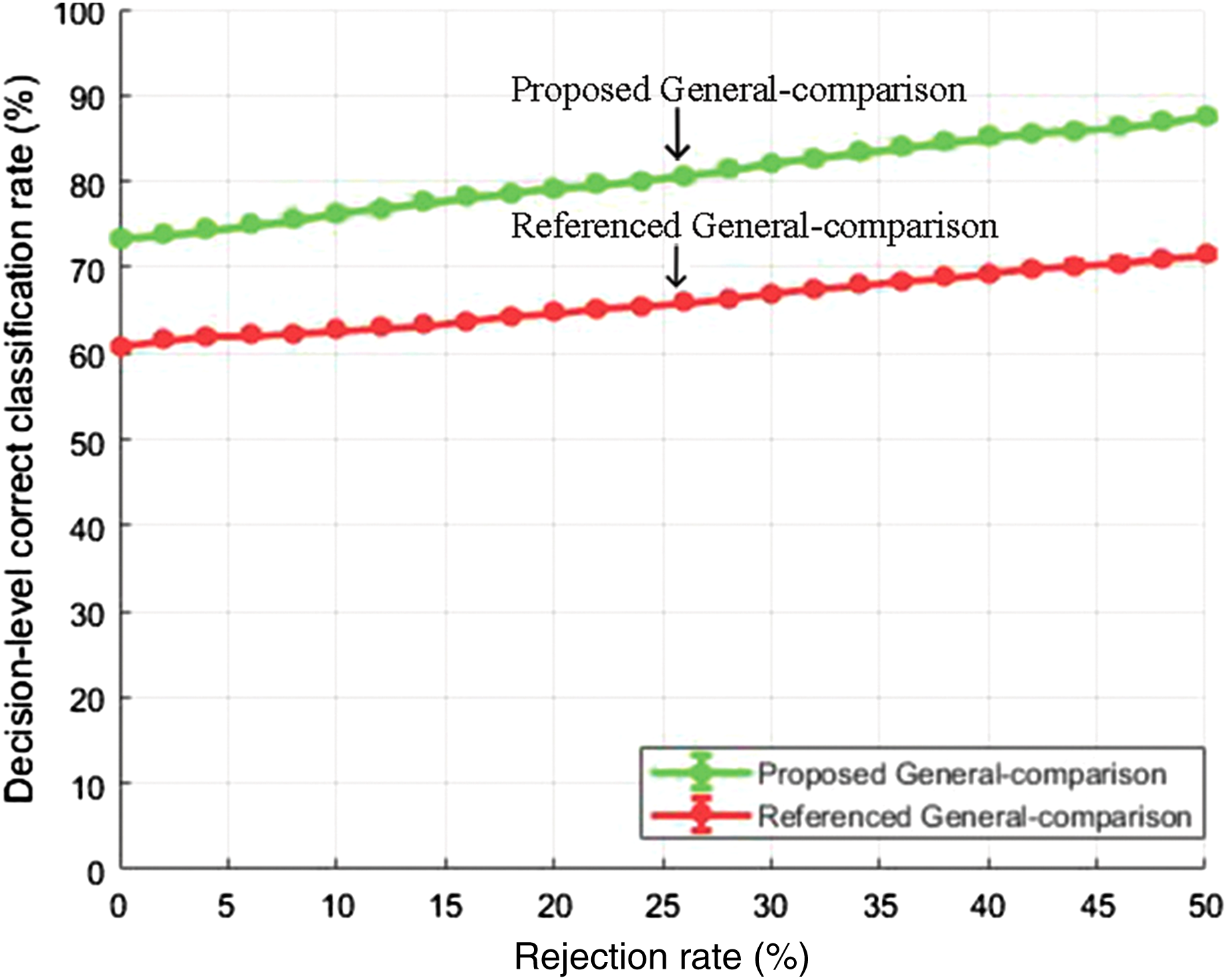{kind=link}
It can be seen that by rejecting about 50% of the samples, we are able to gain above 90% accuracy rate. The performance gain as compared to the baseline study is given in Figs. 8 and 9 for EMO-DB and RAVDESS datasets respectively. This scheme of gaining a high accuracy rate at the cost of rejecting samples could be beneficial in situations where high accuracy for precise samples is required as compared to including all samples with low accuracy.
Gender-dependent comparison
Decision level correct classification rate for gender-dependent tests for male and female speakers are shown in Figs. 10 and 11 respectively.
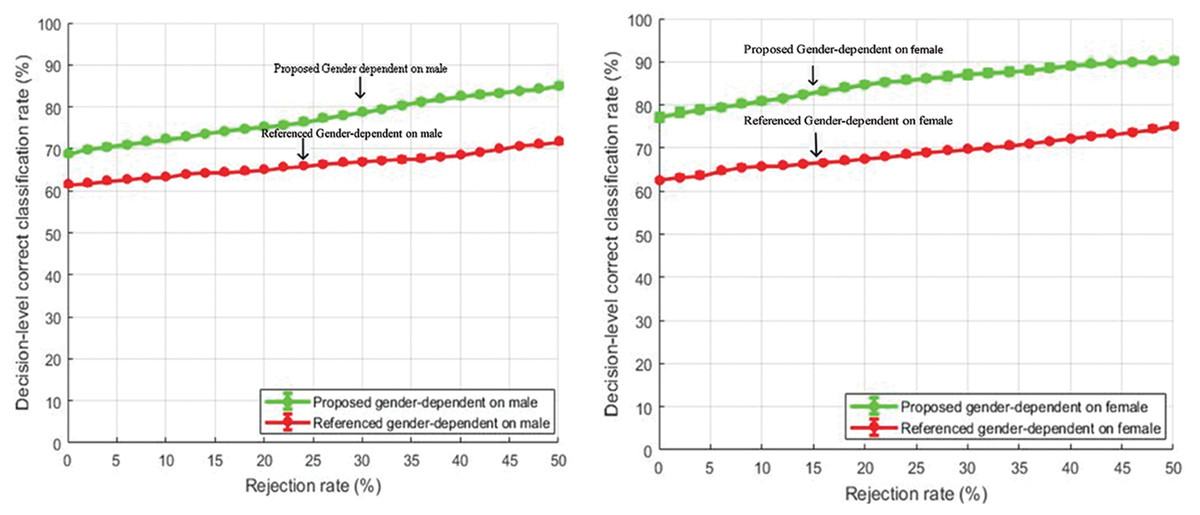
Figure 10: Comparison of decision-level correct classification rate against rejection rate for gender dependent test on EMO-DB.
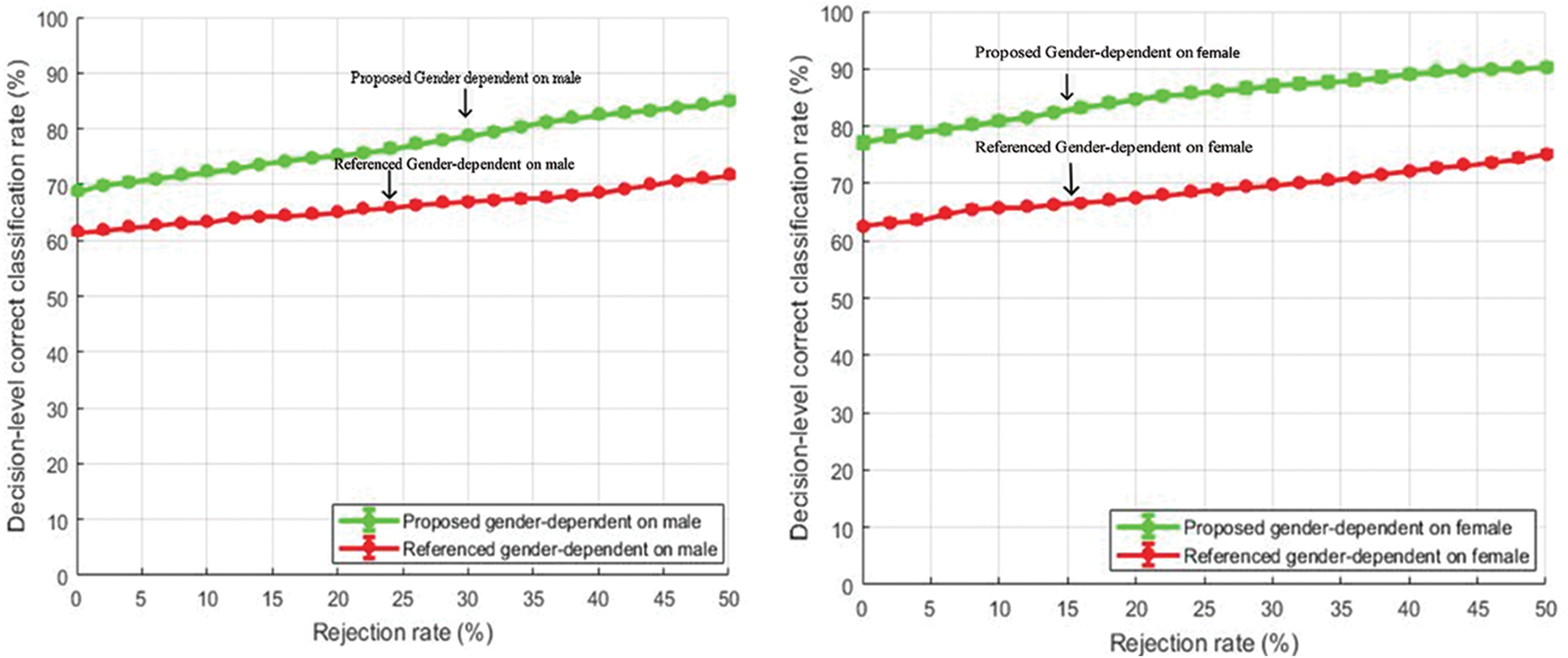{kind=link}
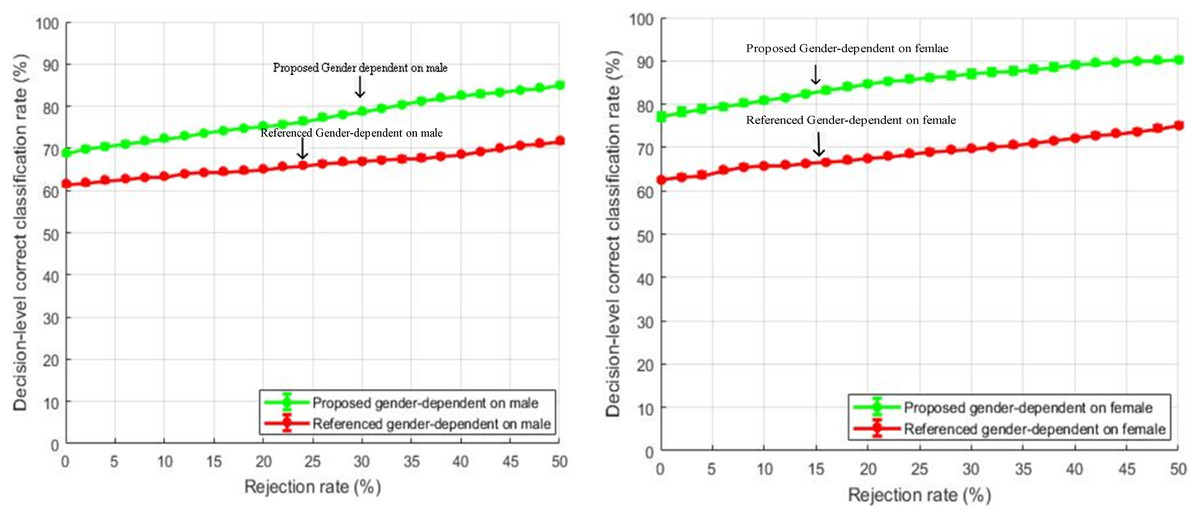
Figure 11: Comparison of decision-level correct classification rate against rejection rate for gender dependent test of our method with the baseline study using RAVDESS dataset with speaker normalization, feature selection, and over-sampled training sets.
{kind=link}
The features selected for gender-specific tests were based on male and female utterances and were not the same as the general tests. The performance gain of about 10% is achieved by rejecting 50% of the total samples. Our feature enhancements worked well and outperformed the baseline study of Yang et al. (2017). Further, it is also observed from Figs. 10 and 11 that the emotion classification rate for female speakers was high as compared to male speakers. One of the reasons could be that female speakers are more accurate in decoding emotions as compared to males (Lausen & Schacht, 2018). The same observation is also seen in the study of Yang et al. (2017).
State-of-the-art comparison
In Table 5, top-2 and top-3 accuracy of our method for RAVDESS is compared with the one reported in Venkataramanan & Rajamohan (2019). Even though, Venkataramanan & Rajamohan (2019) used a neural network model, the top-2 accuracy for our method improved from 84.13% to 87.86% having the performance gain of 3.73%, The performance gain of 1.51% was achieved for top-3 which is still higher then the baseline method. The top-2 and top-3 accuracy measures for the EMO-DB dataset are also given in Table 5. The gender-dependent accuracy score achieved on EMO-DB dataset is also compared with the results reported in Tawari & Trivedi (2010). The accuracy results averaged for both male and female speakers in our work are 85.47%, whereas 84% in the work by Tawari & Trivedi (2010). The bold values in Table 5 indicate the effectiveness of using appropriately tuned features along with classifier.
| Dataset | Metric | Venkataramanan & Rajamohan (2019) | Tawari & Trivedi (2010) | Proposed extensions |
|---|---|---|---|---|
| RAVDESS | Top-2 accuracy | 84.13 | ||
| Top-3 accuracy | 91.38 | |||
| EMO-DB | Top-2 accuracy | |||
| Top-3 accuracy | ||||
| Unweighted accuracy (gender-wise) | 84 |
Conclusion
In this article, we presented a strategy to improve the performance of speech emotion recognition frameworks. We used a feature selection strategy based on INTERSPEECH 2010 challenge feature-set with PCA. Here we reanalyzed and extended the existing model of multiclass SVM with thresholding fusion for speech-based emotion classification. Our in-depth analysis of feature-space through t-SNE showed that selected features represent most of the emotion-related information. The datasets used for evaluation were EMO-DB and RAVDESS having emotions of anger, calm, disgust, fear, happiness, sad, surprise, and neutral. We used PCA, where subsets of features were fed separately and finally fused to reduce the features from 1,582 to 100. We used the One-Against-All SVM model for emotion classification. The performance of feature-driven SER method was compared with the baseline methods. The experimental results demonstrate the effectiveness of the selected features as the method improved the performance of speech emotion recognition. In future, it is anticipated that further investigation of various features will bring additional improvement to the recognition accuracy.
Supplemental Information
Matlab code for EMO-DB dataset.
Matlab code with features of interspeech 2010.