
Scaling laws for Haralick texture features of linear gradients
- Published
- Accepted
- Received
- Academic Editor
- Xiangjie Kong
- Subject Areas
- Computer Vision, Data Mining and Machine Learning, Data Science, Visual Analytics
- Keywords
- Texture classification, Image analysis, Gray Level Co-occurrence Matrix, Haralick features, Scaling laws
- Copyright
- © 2025 Oprisan and Oprisan
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Scaling laws for Haralick texture features of linear gradients. PeerJ Computer Science 11:e2856 https://doi.org/10.7717/peerj-cs.2856
Abstract
This study presents a novel analytical framework for understanding the relationship between the image gradients and the symmetries of the Gray Level Co-occurrence Matrix (GLCM). Analytical expression for four key features–sum average (SA), sum variance (SV), difference variance (DV), and entropy–were derived to capture their dependence on image’s gray-level quantization (Ng), the gradient magnitude (∇), and the displacement vector (d) through the corresponding GLCM. Scaling laws obtained from the exact analytical dependencies of Haralick features on Ng, ∇ and |d| show that SA and DV scale linearly with Ng, SV scales quadratically, and entropy follows a logarithmic trend. The scaling laws allow a consistent derivation of normalization factors that make Haralick features independent of the quantization scheme Ng. Numerical simulations using synthetic one-dimensional gradients validated our theoretical predictions. This theoretical framework establishes a foundation for consistent derivation of analytic expressions and scaling laws for Haralick features. Such an approach would streamline texture analysis across datasets and imaging modalities, enhancing the portability and interpretability of Haralick features in machine learning and medical imaging applications.
Introduction
Researching image texture presents a fundamental challenge: it requires a universally accepted definition. Texture can be perceived through tactile means Manjunath & Ma (1996) and optical methods (Tuceryan & Jain, 1999). Humans recognize texture in images (Papathomas, Kashi & Gorea, 1997; Aviram & Rotman, 2000; Jagadeesh & Gardner, 2022), distinguishing it by attributes such as coarseness and roughness. The human visual system relies on local contrast ratios and intensity differences, rather than absolute pixel intensity values, to interpret image patterns, such as intensity gradients (Werner, 1935; Land & McCann, 1971; Attneave, 1954; Barten, 1999). In non-human primates, neurons selectively respond to surface luminance gradients and utilize linear shading gradients to infer three-dimensional (3D) structure (Hanazawa & Komatsu, 2001). While previous experimental findings established that the primate visual cortex prioritizes luminance gradients over absolute luminosity as a key visual feature for pattern classification (Correani, Scott-Samuel & Leonards, 2006; Keil, 2007), more recent research has demonstrated that image gradients also facilitate the neural encoding of 3D representations of textured objects (Gomez & Neumann, 2016).
Furthermore, MRI studies in humans have shown that luminance gradients along the vertical axis of an image elicit stronger neural responses in scene-selective brain regions compared to horizontal gradients (Cheng, Chen & Dilks, 2023). This directional selectivity suggests that the human brain assigns different levels of importance to intensity gradients depending on their orientation within natural scenes. Experimental evidence also suggests that vertical intensity gradients are processed by distinct neural pathways in the early visual cortex than those used for gradients in other orientations (Vaziri et al., 2014).
Computer applications have leveraged human visual perception by incorporating gradients as fundamental visual features to enhance the informational content of images. For instance, geographic information system (GIS) tools utilize color gradients to represent variations in elevation and population density (DeMers, 2008). In image processing, gradients serve as essential components for various tasks, including edge detection (Canny, 1986), to correct different lighting or camera properties (Marchand, 2007), and distinguishing between digital camera images and scanned images (Mettripun & Amornraksa, 2014). Additionally, reducing gradient magnitudes at transitions within mosaic images helps create visually cohesive scenes, which human observers perceive as single, unified images (Perez, Gangnet & Blake, 2003).
Natural-scene images depict nature-made objects, such as landscapes, animals, and plants. At the initial stage of an image processing pipeline, basic image enhancement tasks must make assumptions about the image through interpolation methods like smoothing and filtering or model fitting techniques such as Bayesian inference. Although prior knowledge is essential for image processing, it can also introduces bias by favoring expected outcomes. Spectral priors do not directly encode information about an image’s specific properties but instead influence its histogram (the spectrum). Many image features, including color and texture, can be derived from image gradients or spectral priors, as they exhibit remarkable invariance across images (Long & Purves, 2003; Tward, 2021; Dresp-Langley & Reeves, 2024). Each pixel in a gradient image contains two values corresponding to the gradient components at that location. The gradient distribution represents these values’ histogram or probability distribution across all pixels or multiple images. This study focused on one-dimensional gradients in two-dimensional images to explore how Haralick statistical features relate to image gradients. Significant discrepancies exist between human and machine vision in classifying the same textures (Tamura, Mori & Yamawaki, 1978). Efforts to enhance machine-based texture recognition have included detailed models of human visual perception of luminance differences (Chan, Golub & Mulet, 1970; Miao & Shaohui, 2017) and techniques that focus on grouping similar image regions (Rosenfeld & Kak, 1982) or analyzing semi-repetitive pixel arrangements in natural scenes (Pratt, 1978, 2006).
Computer vision and “big data” efficient algorithms driven by machine learning (ML) and Artificial Intelligence (AI) rapidly expanded into the medical imaging field in healthcare. Despite its significance, over 97% of recorded medical images remain unused due to inadequate feature extraction and classification methods (Murphy, 2019). With the emergence of ML and AIs, several automated systems for medical image analysis have been developed. These include tools for bone age estimation (Kim et al., 2017), detection of pulmonary tuberculosis and lung nodules (Hwang et al., 2018; Singh et al., 2018), and AI-based lobe segmentation in CT images (Fischer et al., 2020). Texture analysis is crucial in such applications, including diagnosing microcalcifications in breast tissue (Karahaliou et al., 2007) and detecting cancer from ultrasound images of various organs (Faust et al., 2018).
Texture analysis has been applied to improve the quality of life for individuals with visual impairments. For example, it has enhanced handwriting digit identification accuracy (Sanchez Sanchez et al., 2024) and improved the performance of classification algorithm (Alshehri et al., 2024). In nondestructive material testing, texture analysis helps characterize changes in microstructure caused by mechanical, thermal, and operational stresses. By analyzing microstructural features, researchers gain a deeper understanding of bulk material properties and their macroscopic mechanical behavior. Microstructure texture classification has been widely used in metallurgical studies, based on second-order statistical features such as Haralick features (Haralick, Shanmugam & Dinstein, 1973; Haralick, 1979). Applications include identifying constituent metallurgical phases in steel microstructures (Naik, Sajid & Kiran, 2019), assessing surface hardening during cooling (Fuchs, 2005), detecting phase transitions in two-phase steel systems (Liu, 2014), and analyzing the effects of tempering parameters on steel microstructure (Dutta et al., 2014). Additionally, texture analysis has been utilized to quantify corrosion in steam piping systems (Fajardo et al., 2022). In soft condensed matter, texture classification has been used for identifying phase transitions in polymers and liquid crystals (Pieprzyk et al., 2022; Sastry et al., 2012) and measuring shear modulus, failure temperature, and zero shear viscosity, in polymeric colloids (Xu et al., 2024).
Texture-based image analysis often utilizes advanced statistical methods, such as discriminative binary and ternary pattern features (Midya et al., 2017), wavelet-based techniques (Wan & Zhou, 2010; Karahaliou et al., 2007), and matrix-based approaches such as gray-level run length (Raghesh Krishnan & Sudhakar, 2013), autocovariance (Huang, Lin & Chen, 2005), and spatial gray-level dependence matrices (Kyriacou et al., 1997; Pavlopoulos et al., 2000).
One widely used approach to texture analysis is the Gray Level Co-occurrence Matrix (GLCM), a statistical method that captures spatial relationships between pixel intensities (Oprisan & Oprisan, 2023). GLCM, which belongs to second-order statistical methods (Humeau-Heurtier, 2019), quantifies occurrences of pixel pairs that exhibit specific spatial relationships. Haralick, Shanmugam & Dinstein (1973), Haralick (1979) identified 14 texture features derived from GLCM; however, many have been critiqued for redundancy (Conners & Harlow, 1980) and computational complexity. Advanced methods, including higher-order statistics and fractal dimensions (Pavlopoulos et al., 2000; Kyriacou et al., 1997), have further enriched the field but remain limited in practical application due to high computational demands.
The primary objective of this study is to derive analytical expressions for the GLCM and its related features, in order to better understand how they depend on gray-level quantization ( ), image gradient magnitude ( ), and displacement vector ( ). The secondary objective is to use these newly derived expressions, particularly those from the GLCM of linear gradients, to establish scaling laws that govern the dependence of Haralick features on , , and . These scaling laws will help determine the asymptotic behavior of Haralick features and identify data-driven normalization factors, ensuring that results remain independent of the image quantization scheme. Previous studies primarily relied on empirical methods to estimate normalization factors that could make Haralick features invariant to the number of gray levels ( ). For instance, Clausi (2002) proposed normalizing gray-level intensities by the total number of gray levels in the GLCM, but applied this only to two features—inverse difference and inverse difference moment. Similarly, Shafiq-ul Hassan et al. (2017, 2018) aimed to enhance the reproducibility of MRI-based Haralick features across different voxel volumes and scanner models (Philips, Siemens, and GE models). However, their empirical approach identified only two reproducible GLCM-based features, and they noted that “for some features, their relationship with gray levels appeared to be random, therefore, no normalizing factor could be identified” (Shafiq-ul Hassan et al., 2017). Lofstedt et al. (2019) also investigated methods to reduce the sensitivity of Haralick features to image size, noise levels, and different quantization schemes. Their approach involved normalizing each gray level by and additional empirical normalization factors, effectively transforming the GLCM into an equivalent normalized Riemann sum. While this normalization improved consistency for many texture features, it did not work universally, although “most of the modified texture features quickly approach a limit.” This study introduces a systematic methodology for deriving scaling laws that explain how Haralick features evolve with changes in the number of gray levels ( ). By establishing these scaling laws analytically, we aim to provide a more rigorous foundation for normalization strategies, reducing the reliance on empirical estimations.
This study demonstrates the derivation methodology for feature dependencies on , , and for four Haralick features: sum average (SA), sum variance (SV), difference average (DA), and entropy. We chose these four Haralick features because they have received significantly less attention than those based directly on calculating various moments of the GLCM. Examples include Second Angular Moment or Energy (over 19,300 publications in Google Scholar), Contrast (22,500 publications), Correlation (21,000 publications), Sum of Squares Variance (20,100 publications), Inverse Difference Moment or Local Homogeneity (16,000 publications), and Entropy (19,100 publications) (Haralick, Shanmugam & Dinstein, 1973). The remaining Haralick features are used significantly less often because they depend on marginal probabilities derived from the GLCM and require extra computational steps. For instance, SA (3,080 publications), the SV (2,720 publications), and the difference variance (2,600 publications) are cited at about one order of magnitude lower than the previous category. Consequently, their meanings are more complex to grasp. We have included entropy in this study for two reasons: to demonstrate how a logarithmic moment of GLCM is estimated and, more importantly, to illustrate that the derived marginal probabilities used for evaluating SA and sum difference can immediately apply to calculating sum entropy and difference entropy features. By advancing the theoretical understanding of these features, this work aims to enhance the applicability of Haralick features in machine learning and AI-driven texture analysis.
The manuscript is structured as follows. The Methods “The Gray Level Co-occurrence Matrix (GLCM)” defines the meaning and notation for the GLCM. Figure 1 shows a reference frame attached to the upper left corner of the image and the offset vector between the reference (shaded) pixel and its set of neighbours. Descriptions of the x-direction , y-direction , sum , and difference marginal distributions are provided in “Marginal Distributions Associated with the GLCM”. A visual aid is included to help elucidate the meaning of the marginal distributions in Fig. 2. The numerical procedure used for generating synthetic images is detailed in “Synthetic Gradient Images”. The Results section begins with a two-dimensional gradient map for a periodic vertical gradient of length in “Two-dimensional (2D) Gradient Maps”, supporting the transition to the GLCM matrix by wrapping around the 2D map in “Wrap Around the 2D Gradient Map to get the GLCM”. Utilizing GLCM symmetry for periodic linear gradients enables us to estimate the number of nonzero GLCM entries for a given gradient in “On the Number of Nonzero GLCM Entries for a Linear Gradient”, which is necessary for calculating the marginal distribution of gray level differences (Marginal distribution of gray level differences for linear gradients), the marginal distribution of gray level sums (Marginal distribution of gray level sums for linear gradients). The numerical procedure used for comparing analytic predictions against numerically computed Haralick features for synthetic one-dimensional gradients is detailed in “Analytic Scaling Laws for Haralick Features of Linear Gradients. Comparison with Numerical Results”. The subsequent subsections of the Results section apply the findings to derive analytic expressions and scaling laws for sum average, sum variance, difference average, and entropy dependence on and . Side-by-side comparison of analytical and numerical findings are summarized in the Discussion and Conclusions section.
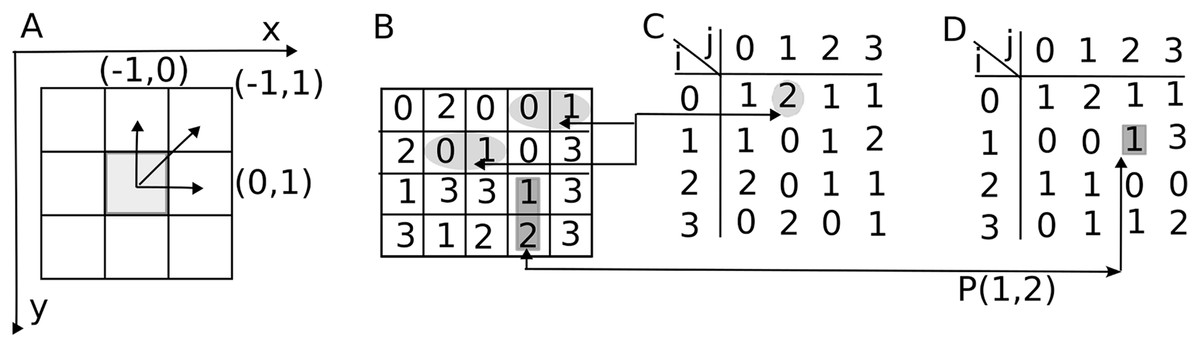
Figure 1: Gray Level Co-occurrence Matrix (GLCM) displacement vectors.
(A) By convention, the -direction runs horizontally to the right and -direction vertically downward with the image’s origin at the upper left corner. Pixel offsets are given by the displacement vector . (B) In a non-periodic 2-bit image, there are horizontal pairs of pixels at a displacement and vertical pairs of pixels at a displacement . (C) The GLCM for unit horizontal displacement has non-zero entries for a 2-bit depth image. For example, the two horizontal pairs 0-1 highlighted with elliptic shades in panel B give the GLCM entry . (D) The GLCM for unit vertical displacement has 15 non-zero entries. For example, the vertical pairs 1-2 indicated with rectangular shades in panel B yield the GLCM entry .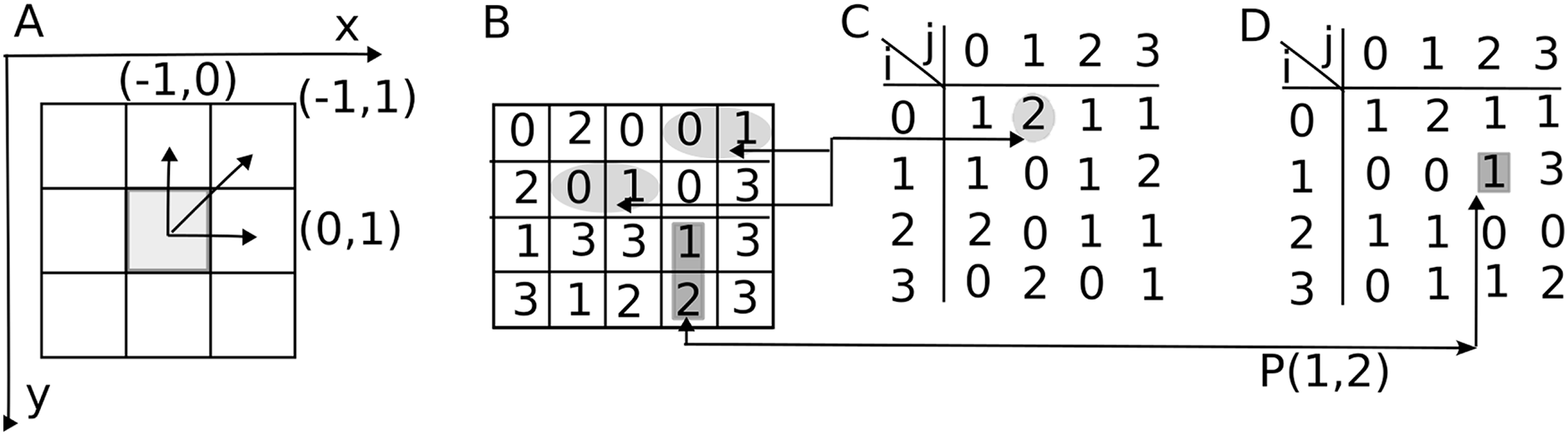{kind=link}

Figure 2: Marginal probability distributions from the GLCM.
(A) The probability of finding a gray level intensity along the horizontal -direction in the image is and along vertical direction is . (B) The probability of finding a gray level difference of units is . It is determined by summing elements parallel to the primary diagonal at a distance of units above and below the GLCM along the corresponding dashed lines. By summing GLCM elements parallel to its secondary diagonal, one obtains .{kind=link}
Methods
The Gray Level Co-occurrence Matrix
A grayscale image is a two-dimensional matrix that stores gray-level intensities (see Fig. 1A). The bit depth of an image determines the number of gray levels. For instance, an 8-bit image has gray levels. By convention, a gray level of zero, , represents black, while corresponds to white. Intermediate intensities represent various shades of gray. Figure 1A shows the upper left corner reference frame attached to an image with x-direction pointing horizontally to the right and the y-direction vertically downward. Each square in Fig. 1A represents an image pixel. Arrows from the central highlighted pixel indicate the offset vectors to its neighbors. The increment represents the image row offset and represents the image column offset.
Figure 1B illustrates a rectangular image with a 2-bit depth ( ). For the same image, as shown in Fig. 1B, each displacement vector defines a corresponding GLCM. For instance, a unit displacement along horizontal direction produces Fig. 1C. Indeed, there are two pairs of pixels with the starting point gray level and endpoint intensity level separated by one pixel displacement along the horizontal direction. The array coordinates (1,4)-(1,5) and (2,2)-(2,3) are marked with elliptical shaded area and connected by the two horizontal lines extending from panel B image to the corresponding GLCM entry in panel C. Similarly, there is only one pair of pixels in the Fig. 1B image with the starting point gray level and endpoint intensity level separated by one pixel displacement along the vertical direction. The array coordinates (3,4)-(4,4) are marked with rectangular shaded area and connected horizontally by a line extending from panel B image to the corresponding GLCM entry in panel D. The unnormalized GLCM counts the number of occurrences of the (reference) gray level at a distance specified by the displacement vector from the (target) gray level (Haralick, Shanmugam & Dinstein, 1973):
(1) where # denotes the number of elements in the set, the coordinates of the reference gray level are , and the coordinates of the neighbor (target) pixel with gray level are .
In the GLCM Eq. (1), the first index represents the intensity of the reference point, or the starting point of the displacement vector , while the second index corresponds to the intensity of the endpoint of the displacement vector. For instance, an offset indicates that the row index (in the -direction) remains unchanged since , and the column index (in the - or horizontal direction across the image) increases by one unit .
For simplicity, Fig. 1 only counts the pairs for gray levels one pixel apart along the horizontal (Fig. 1C) and vertical (Fig. 1D) directions, respectively. For example, only one pair of gray level intensities 1-0 is counted between the spatial coordinates (2,3) and (2,4) in Fig. 1B, which is shown as in Fig. 1C GLCM. As a result, the Fig. 1B GLCM is not symmetric. In the original definition of the GLCM provided by Haralick (Haralick, Shanmugam & Dinstein, 1973), symmetry allows both and pairings to be counted as instances where the pixel value 1 is separated by the distance vector from the pixel value 2. Mathematically this is achieved by adding to the GLCMs in Figs. 1C and 1D their corresponding transposed arrays. In line with Haralick’s definition, our implementation and all the results presented in this study used a symmetric GLCM matrix definition.
The number of possible pairs in the image typically normalizes the GLCM. For instance, in an image, there are horizontal pairs and vertical pairs. In the example depicted in Fig. 1, since the image has pixels, the GLCM normalization factors are and . The corresponding normalized GLCM values in Fig. 1C are, for example, , and for Fig. 1D, they are . The unnormalized GLCM is indicated with capital letters such as , while its normalized version is denoted as :
(2)
The normalized GLCM indicates the likelihood of finding gray level at a displacement from the current location of the reference pixel with gray level in an image. It adheres to the normalization condition . More than half of the original 14 Haralick features rely on an additional step that involves computing marginal probability distributions from .
The GLCM is a natural measure of image gradients, quantifying the change in light intensity from the reference intensity to the target intensity along the displacement vector . Since Haralick features are scalar measures defined by the two-point histogram represented by the GLCM, they also inherently measure light intensity gradients present in images.
Marginal distributions associated with the GLCM
Only three of the original Haralick features (Haralick, Shanmugam & Dinstein, 1973; Haralick, 1979) use the normalized GLCM as defined in Eq. (2). All the other use one of the four marginal probability distributions derived from . To simplify the notation, one dropped the subscript from the normalized GLCM . The -direction marginal probability distribution can be obtained by summing along the rows of the GLCM :
as shown in Fig. 2A. For example, is the sum of all row elements with an intensity at the reference point (see Fig. 1A), regardless of the intensity of its endpoint determined by the displacement vector. Therefore, gives the probability of finding gray level in the image. The mean and variance of the GLCM along the marginal distribution are and
The -direction marginal probability distribution can be obtained by summing the columns of the GLCM :
For example, is the sum of all column elements with an endpoint intensity , regardless of the intensity of the reference (starting) point. These marginal probabilities are illustrated in Fig. 2, along the horizontal dashed lines representing the GLCM line summation for and along the vertical dashed lines representing the GLCM column summation of to obtain , respectively.
The marginal distribution of gray level differences between the reference pixel intensity and the endpoint intensity determined by the displacement vector is:
(3) where is Kronecker’s symbol. For example, represents the sum of all primary diagonal elements of the GLCM, as these elements exhibit no gray level differences between the reference point and the endpoint of the vector , as illustrated in Fig. 2B. Similarly, the sum of the elements along the first line parallel to and above the primary diagonal reflects a gray level difference of units between the reference gray level and the endpoint gray level of the GLCM, which defines . The sum of GLCM entries along the first line parallel and above the primary diagonal in Fig. 2B correspond to the fraction of with . The sum of GLCM entries along the first line parallel and below the primary diagonal in Fig. 2B correspond to the fraction of with . Since the definition of gray level differences marginal distribution in Eq. (3) counts absolute differences , the two partial sums must also be added (see the symbol) to produce .
The marginal distribution of gray level sums between the reference pixel intensity and the endpoint neighbor intensity is:
(4)
To prevent overcrowding in Fig. 2B, we only showed the , which signifies the sum of the GLCM elements along its secondary diagonal with , i.e., . Other values for correspond to summation along lines parallel to the secondary diagonal in Fig. 2B.
Synthetic gradient images
While the GLCM method described in “Methods” applies to any image, this study specifically focuses on computer-generated (synthetic) images with one-dimensional vertical gradients. This focus is motivated by the fact that image gradients are highly invariant across images (Long & Purves, 2003; Tward, 2021; Dresp-Langley & Reeves, 2024).
Image gradients have long been used as statistical (or spectral) priors for estimating image features (Gong & Sbalzarini, 2014, 2016). A gradient image , is derived from the first-order spatial differences of the original image, , such that (McCann & Pollard, 2008; Sevcenco & Agathoklis, 2021). The gradient image retains the same dimensions as the original but stores the x- and y-direction gradient values at each pixel.
Gradient spectral priors have been extensively applied in various image processing tasks, including denoising and deblurring (Chen, Yang & Wu, 2010), image restoration (Cho et al., 2012), range compression (Fattal, Lischinski & Werman, 2002), shadow removal (Finlayson, Hordley & Drew, 2002), and image compositing (Levin et al., 2004; Perez, Gangnet & Blake, 2003). Notably, deblurring in the gradient domain is often more computationally efficient than operating on raw pixel values (Cho & Lee, 2009; Shan, Jia & Agarwala, 2008; Wang & Cheng, 2016).
Traditionally, images are decomposed into 2D orthogonal gradient maps assuming that x- and y-direction gradients are statistically independent. One of the first studies to explore potential correlations between these gradient distributions in natural scene images found “weakly negatively correlated in the training dataset (from edges in the images)” (Gong & Sbalzarini, 2016). Consistent with these findings, recent algorithms for image denoising and deblurring (Zheng et al., 2022; Zhangying et al., 2024), range compression (Yan, Sun & Davis, 2024), or pattern classification (Wang et al., 2025) continue to treat orthogonal gradients as independent and their spectral priors as uncorrelated. Based on this well-supported assumption, our study focuses exclusively on a vertical gradient for calculating Haralick texture features.
Figure 3A shows a -bit depth grayscale image with dimensions , featuring a vertical, linearly increasing, periodic intensity gradient of gray level per pixel. The array that represents the image is given by where . Since image intensities do not depend on the matrix index, the image appears as horizontal stripes with linearly increasing intensity (Fig. 3A). Furthermore, the vertical gradients are periodic, i.e., the intensity pattern repeats after reaching the maximum number of gray levels . In other words, the vertical coordinate and pixel intensity are connected through . The modulo (“mod”) operation along the vertical spatial indices ensures the gradient repeats periodically after pixels. In Fig. 3A example, the gray levels increase linearly from zero to with a step of gray level per pixel. The arrow next to the gradient in Fig. 3A indicates the gradient’s direction. Similarly, Fig. 3E shows a synthetically generated image with a vertical, linearly increasing, and periodic gradient gray levels per pixel. The grayscale images from Fig. 3A and Fig. 3E are numerically represented in Fig. 3B and Fig. 3F, respectively. The horizontal arrows between panels A and B indicate that the constant intensity line of pixels is represented numerically by the corresponding integer values with black mapped to 0. Following the procedure described above, we generated square synthetic images of pixels containing periodic linear gradient patterns, as illustrated in Fig. 3. Our analysis focuses on three key variables:
-
(1)
The number of gray levels in the image ( ),
-
(2)
The intensity of the image gradients ( ) in gray levels per pixel, and
-
(3)
The displacement vector ( ) in pixels, which determines the GLCM matrix used to compute the Haralick features.
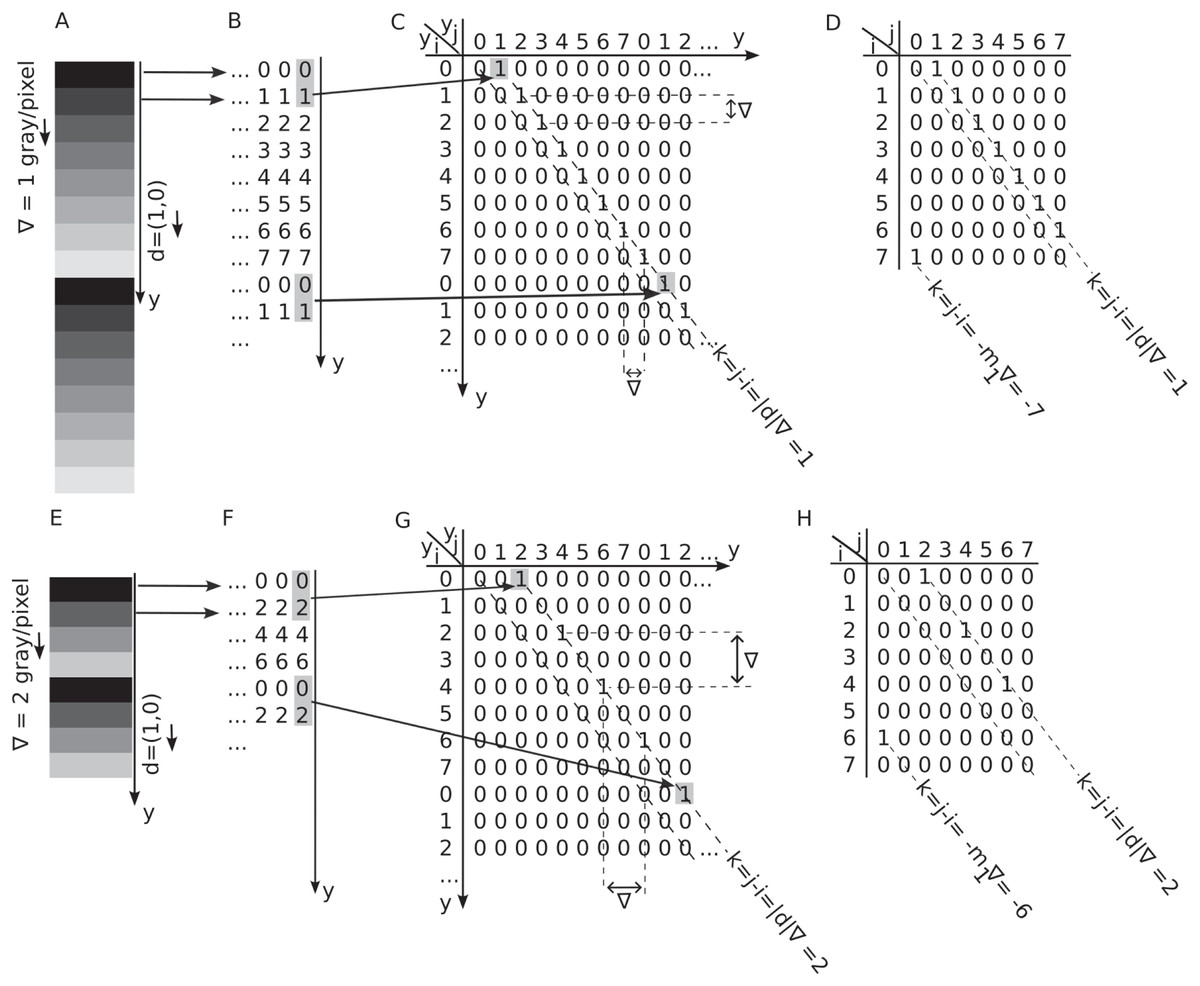
Figure 3: Periodic and linear vertical gradients and their GLCM.
(A and E) Horizontal stripes of constant intensity with a periodic vertical gradient of (panel A) and (panel 2) gray levels per pixel in a -bit depth grayscale image. Each horizontal line is one pixel wide. (B and F) Numerical representation of the grayscale image with values ranging from zero to (C and G) The two-dimensional (2D) gradient map of the periodic gray level gradient displays nonzero entries at the coordinates , which are spaced by the distance and maintain the absolute coordinates of pixels along the gradient. The first non-zero entry occurs at , with all nonzero entries separated by distances of both vertically and horizontally. (D and H) The shaded gray levels and at a vertical distance of one pixel in panel B determine the GLCM entry . The GLCM can be obtained by wrapping around the 2D gradient map by modulo in both array dimensions.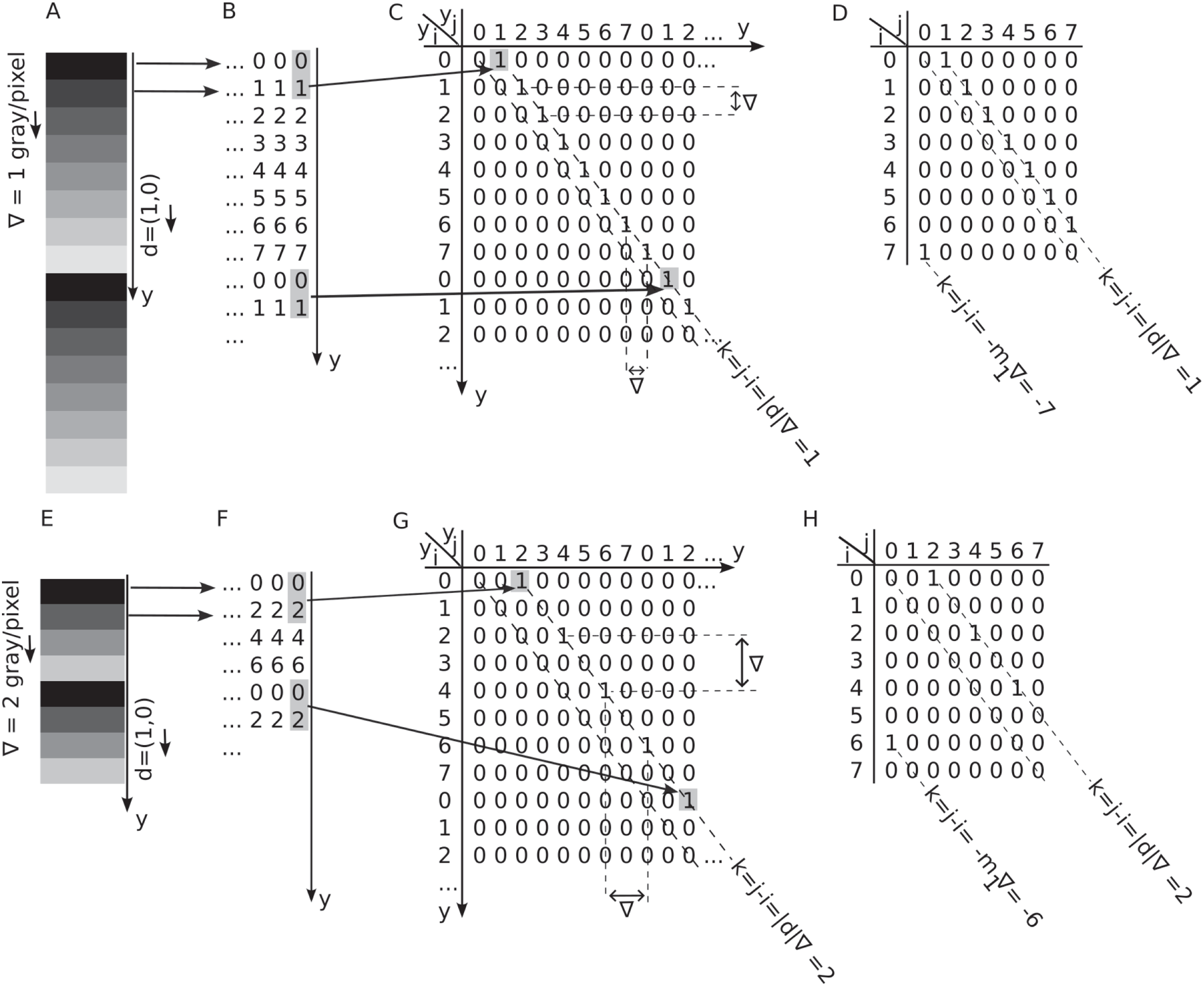{kind=link}
We created images with a bit depth (b) ranging from 4 to 8, corresponding to . These values represent a broad and realistic range for evaluating how Haralick features depend on (see Figs. 4 and 5). For each bit depth we generated synthetic images with gradient intensities ( ) ranging from 1 to 8. However, to reduce visual clutter, only odd values are displayed in Figs. 4 and 5. Finally, for each combination of bit depth ( ) and gradient intensity , we computed GLCMs for vertical displacement vectors .
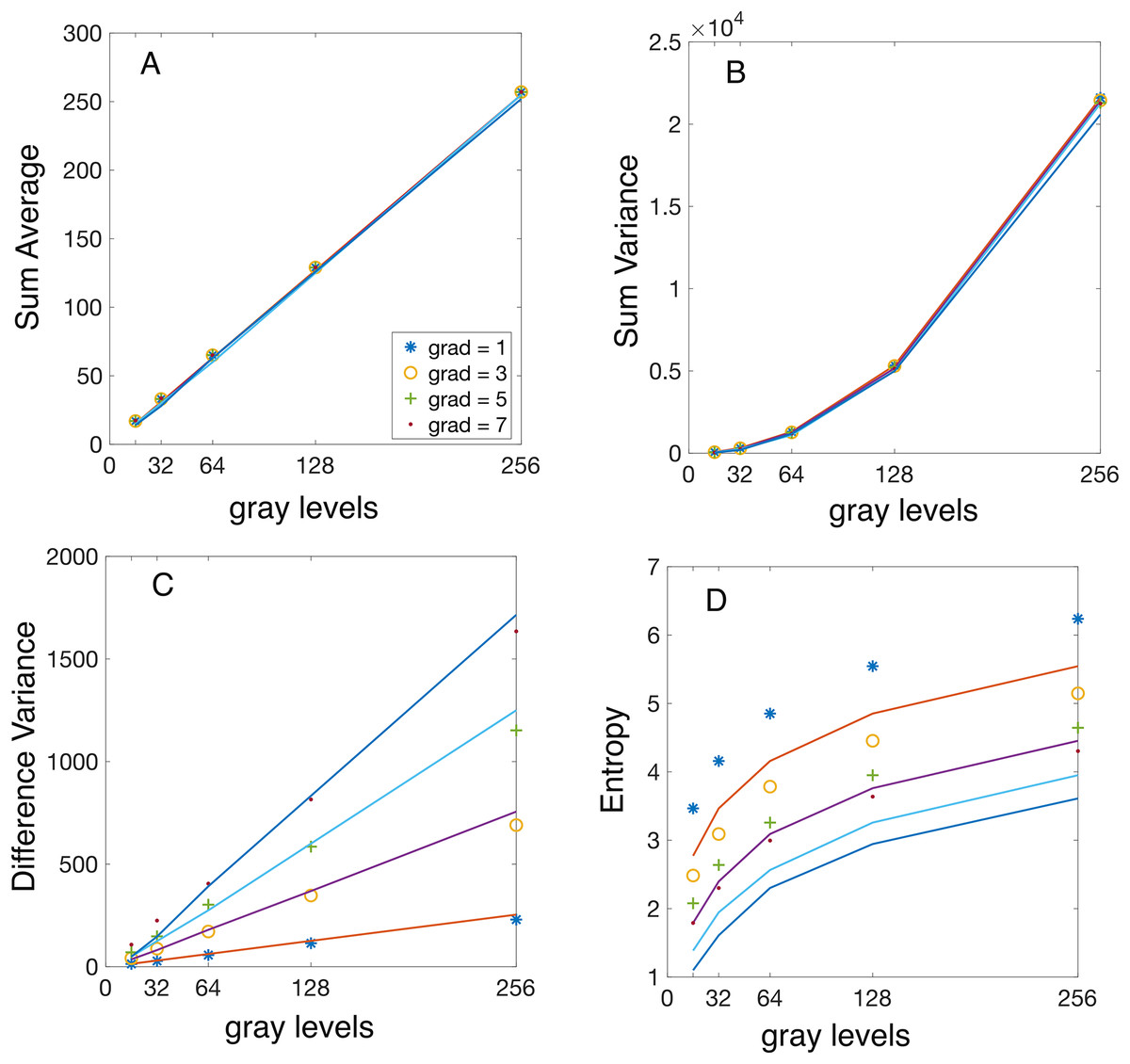
Figure 4: Analytical vs numerically calculated features scaling with image bit depth.
Synthetic linear gradient images were used with gray levels. The GLCMs were numerically evaluated for a fixed integer vertical displacement pixels and variable linear gradients of gray level per pixel (symbol “ ”), gray levels per pixel (symbol “o”), gray levels per pixel (symbol “+”), and gray levels per pixel (symbol “.”). All Haralick features were computed numerically using Matlab’s function. The continuous lines represent the analytically predicted scaling laws for the corresponding features. (A) The numerically computed sum average (SA) feature increases linearly with and is independent of the magnitude of the displacement vector and the gradient. (B) The numerically computed sum variance (SV) feature exhibits a quadratic dependence on the magnitude of the displacement vector and is independent of the magnitude of the displacement vector and the gradient, as predicted by Eq. (13). (C) The numerically computed difference variance (DV) scales linearly with the image bit depth and the slope increases linearly with the image gradient intensity , as predicted by Eq. (15). (D) The experimental values of entropy show the predicted logarithmic trend, but they are consistently and slightly shifted in comparison to the theoretical prediction from Eq. (20). The reason is that the numerically computed Entropy feature uses with a small constant to prevent logarithm divergence for sparse GLCM with many .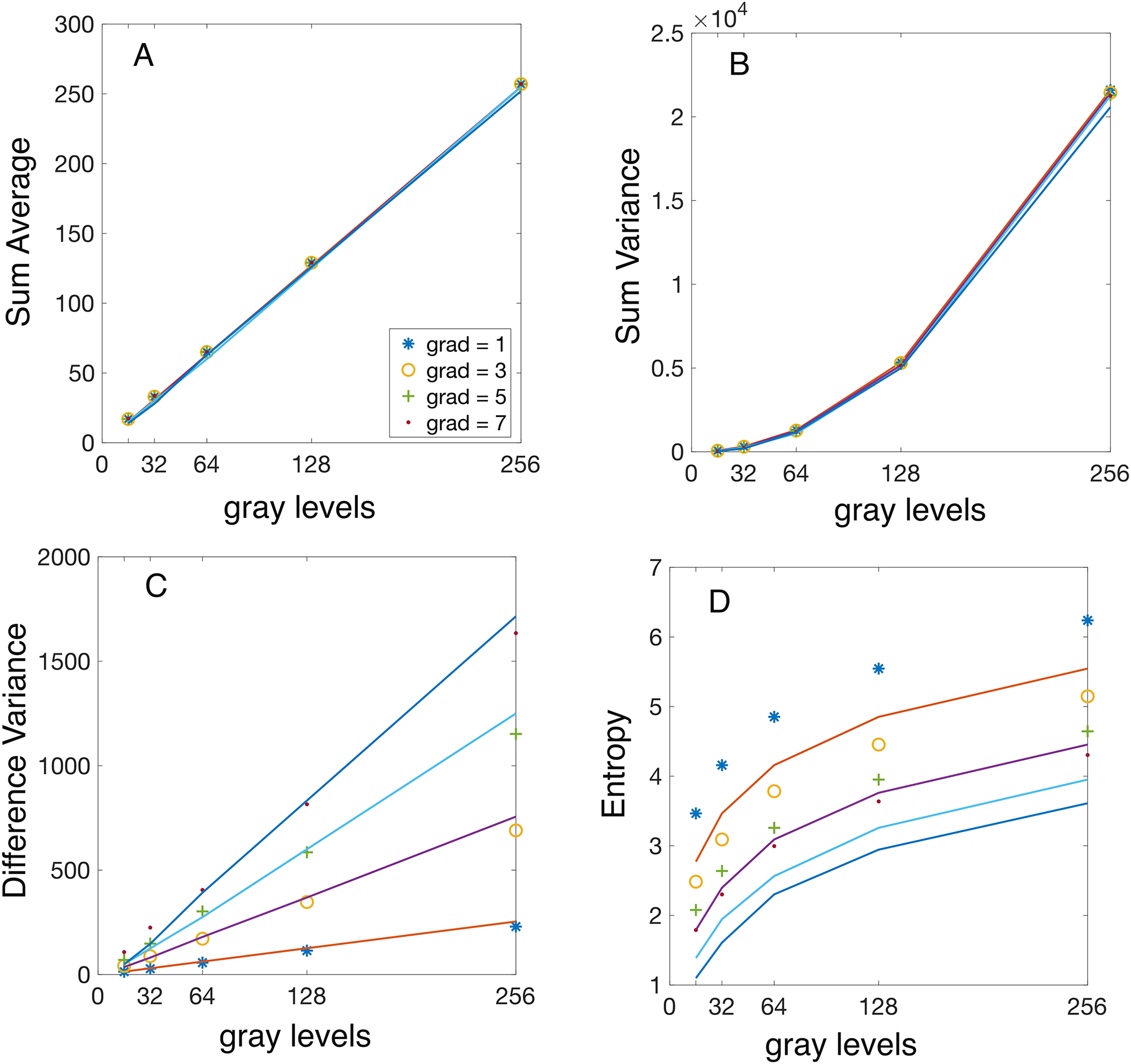{kind=link}
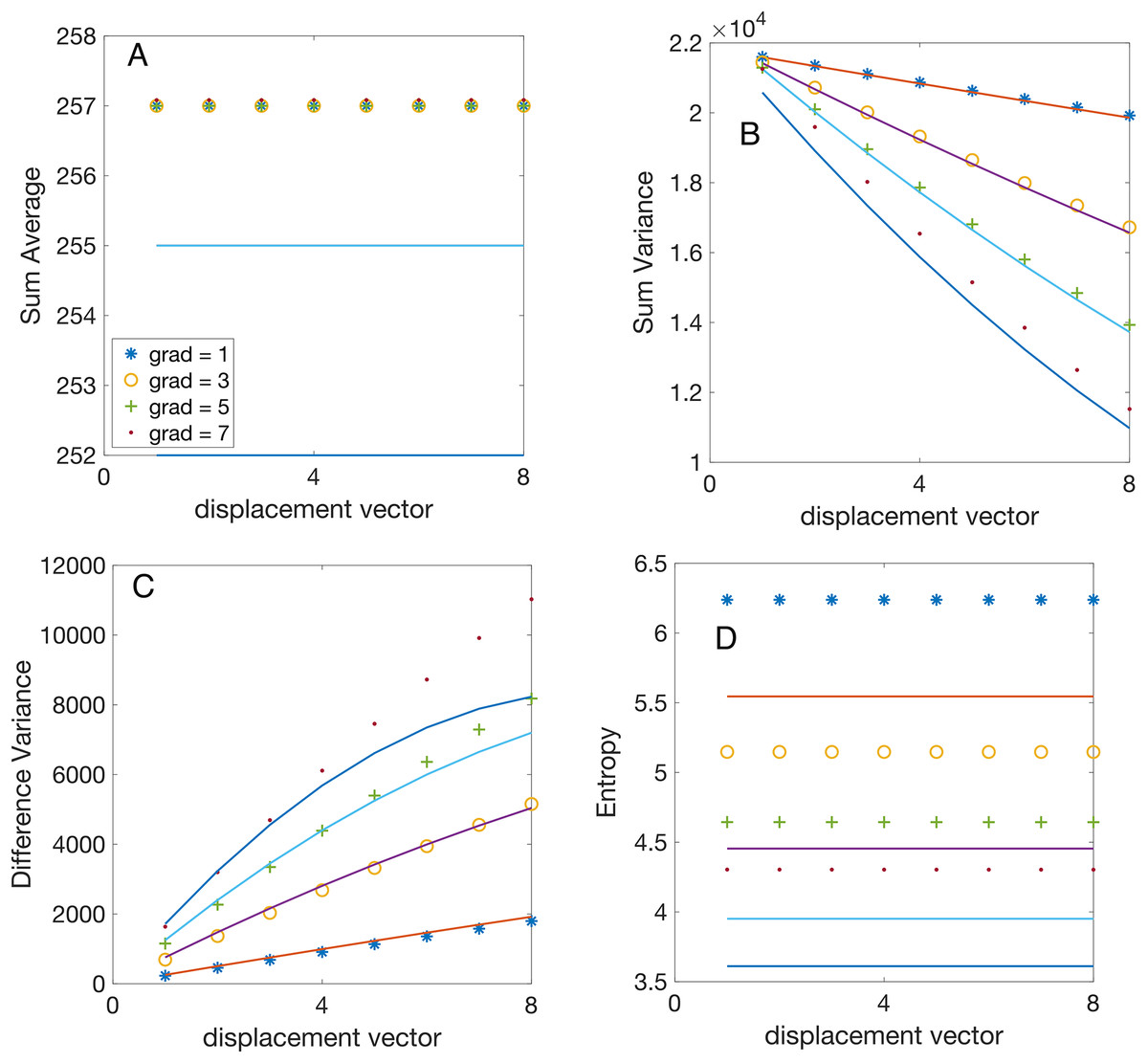
Figure 5: Analytical vs numerically calculated features scaling with displacement vector magnitude.
All synthetic gradient images were 8-bit depth. The GLCMs were numerically evaluated for vertical displacements pixels and linear gradients gray level per pixel (symbol “ ”), gray levels per pixel (symbol “o”), gray levels per pixel (symbol “+”), and gray levels per pixel (symbol “.”). All features were numerically computed using Matlab’s function . The continuous lines illustrate the analytically predicted scaling laws for the corresponding features. (A) The numerically computed sum average (SA) feature remains independent of the magnitude of the displacement vector and exhibits negligible gradient dependence due to the integer part function, as elaborated in the text. (B) The numerically computed sum variance (SV) feature scales linearly with the magnitude of the displacement vector, with a slope proportional to the gradient, as predicted by Eq. (13). (C) The numerically computed difference variance (DV) scales linearly with the magnitude of the displacement vector and the slope is proportional to the gradient, as predicted by Eq. (16). (D) The experimental values of entropy are independent of the magnitude of the displacement vector and increase with the gradient, as expected from Eq. (20). The slight systematic difference between the computed and predicted values is due to the actual entropy feature calculation using with a small constant to prevent logarithm divergence for sparse GLCM with many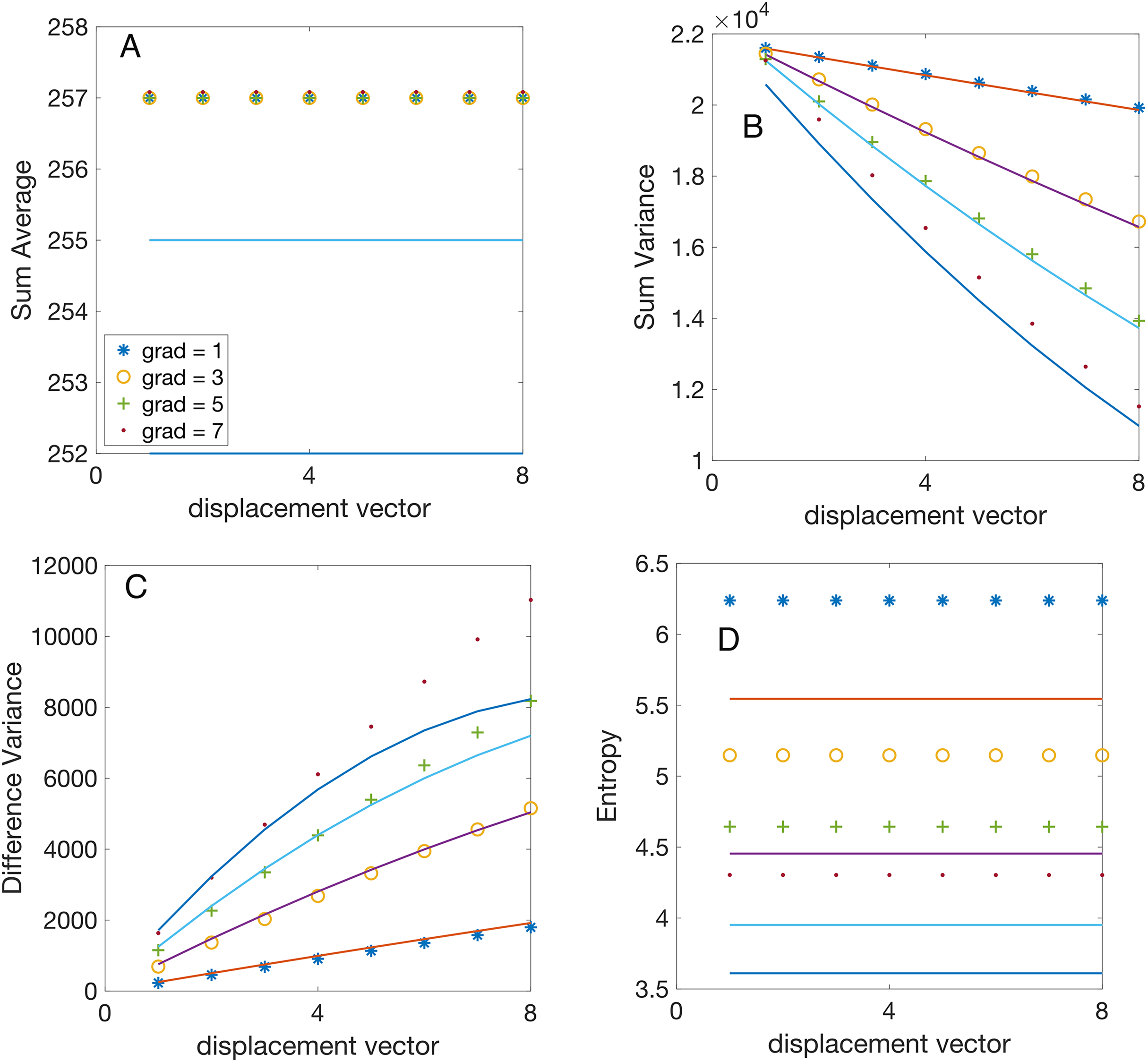{kind=link}
Results
Interpreting GLCM and Haralick features is difficult because they contain second-order statistical information about image pixels. To calculate Haralick features, one employs images with a single periodic and linear gradient to understand the relationship between image gradients and GLCM symmetries.
Two-dimensional gradient maps
To count the pairs of pixels with a starting gray level and an endpoint gray level separated by a distance pixels, one can create a two-dimensional (2D) gradient map such that its entry is 1 if and zero otherwise as shown in Fig. 3C. Here, is the dot product and ensures that one considers the relative orientation of the gradient to the displacement vector . From Figs. 3B and 3F, one notices that the gray level intensity at spatial coordinate is always with . The pixel intensity at a vertical coordinate , which is a distance from , is . As a result, the 2D maps in Figs. 3C and 3G are one-to-one correspondences between pixel location and its corresponding gray level intensity . One notices in Fig. 3C with gray level per pixel and Fig. 3G with gray level per pixel that the vertical and horizontal distance between any non-zero entries of the 2D gradient map is . These displacements are marked in Fig. 3C and Fig. 3G, respectively. Additionally, one can observe from the 2D gradient maps in Figs. 3C and 3G that all nonzero entries are aligned with the primary diagonal of the 2D gradient map at a distance of from it. The distance of the gradient pattern from the primary diagonal of the 2D gradient maps is determined by the first gray level intensity, i.e., , which is always paired with the gray label for any displacement vector and gradient intensity . Finally, all nonzero entries in the 2D gradient maps shown in Figs. 3C and 3G obey the condition shown with dashed line parallel to the principal axis diagonal. The principal diagonal elements are always zero because they correspond to a uniform image with no intensity changes from pixel to pixel.
Wrap around the 2D gradient map to get the GLCM
While illuminating, representing a periodic linear gradient of length using a sparse 2D gradient maps, as shown in Figs. 3C and 3G, is not efficient. As a result, the GLCM removes the extra spatial information about pixel coordinates retained by the 2D gradient map and only counts the co-occurrence of gray level intensities and at a relative distance , as illustrated in Figs. 3D and 3H. Consequently, for a specific displacement vector , the GLCM is an matrix that solely counts the co-occurrence of gray levels and at a relative distance from each other, irrespective of their absolute spatial coordinates and . Because the absolute coordinates of the pixel intensity pair and are no longer recorded, the GLCM is not a one-to-one mapping of the original gradient (unlike the 2D gradient map). For instance, in Fig. 3C, the pixel intensities and are located at a distance , and they are represented in the 2D gradient map by a value of “1” at spatial coordinates , as shown in Figs. 3A and 3B. However, the GLCM represents the same pair as an entry at as it remaps all 2D gradient map entries from Figs. 3C and 3G using a modulo operation. For example, the spatial coordinates from Fig. 3C are mapped modulo to GLCM coordinates , which correspond to gray levels in GLCM. Although the GLCM array can no longer be mapped back to the original image, it retains essential second-order spatial correlations of gray level intensities.
On the number of nonzero GLCM entries for a linear gradient
For any linear gradient , the starting point of the GLCM has an index from the set , where is the number of non-zero GLCM entries shown in Figs. 3D and 3H, i.e.:
(5)
In the above formula, denotes the integer part. Each endpoint index of the GLCM is also expressed as . This relationship indicates that the increment of endpoint indices in the GLCM, represented by , is equivalent to that of the starting point indices, denoted as , meaning that , as illustrated by the horizontal and vertical double arrows in Fig. 3C for and in Fig. 3G for . For example, in Fig. 3D and gray level per pixel along with Eq. (5) determines how many non-zero GLMC entries result from sampling the gray levels of the image, i.e., . Similarly, for Fig. 3H with gray levels per pixel in conjunction with Eq. (5), it yields .
One can notice that Fig. 3 displays the GLCMs for positive gradients and positive displacement vectors, such as . Reversing the direction of the gradient would merely shift all non-zero entries in the two-dimensional representation shown in Figs. 3C and 3G below the primary diagonal at a distance .
Marginal distribution of gray level differences for linear gradients
The marginal probability distribution , defined by Eq. (3) and visually represented in Fig. 2B, accounts for the sum of GLCM entries with specified gray level differences . As observed in Figs. 3D and 3H, the lines parallel to the primary diagonal of the GLCM convey information about image gradients and represent the lines of constant gray level differences . For example, the GLCM primary diagonal entries have zero gray level differences, i.e., Consequently, the sum of the primary diagonal elements, i.e., , is a zero gradient line because the gray level differences, i.e., the difference between the gray level value of the start (reference) point and the endpoint gray level intensity at along the displacement vector , is . Figure 3D illustrates that the GLCM of a gradient gray level per pixel along the vertical unit displacement vector contains all entries (except one) aligned along a parallel line with the primary diagonal at gray level differences . The sole exception is the GLCM entry at the discontinuity between the first period and the subsequent gradient repeats (see Fig. 3A and Fig. 3E). For example, the first period of the gradient in Fig. 3E and Fig. 3F ends with a gray level of in an image with gray levels and a gradient intensity Therefore, its pair must have an intensity , which is mapped modulo to . It corresponds to (remember that the wrapping around of GLCM in gray level spaces is done modulo because the gray level indices start at zero while the spatial coordinates wrap around with modulo operation because they begin at index 1). Since accounting for another period of the same gradient increases all nonzero entries of GLCM by one unit, from this point forward, one only calculates the GLCM for a single period of the gradient. To compute Haralick’s features, one uses the symmetry of the GLCM induced by periodic linear gradients such as those shown in Fig. 3.
One can observe from Fig. 3 that the nonzero GLCM entries parallel to the primary diagonal for a given gray level difference begin at a distance of from the first GLCM entry . The line of constant gray level differences (dotted line parallel to the primary diagonal of the GLCM in Figs. 3D and 3H) starts at and ends at , where is the number of GLCM entries along the gray level differences line with , which is:
(6)
In the example depicted in Figs. 3A–3D, the GLCM for a unit vertical displacement in an image exhibiting a linear gradient of gray level per pixel and gray levels has a total of nonzero entries (from Eq. (5)), of which (see Eq. (6)) along the line of constant gray level differences . This line starts at and ends at . Similarly, for the example shown in Figs. 3E–3H, gray levels per pixel and , one gets a total number of GLMC entries of (from Eq. (5)), of which (see Eq. (6)) along the line of constant gray level differences that starts at and end at .
The GLCM always has exactly nonzero entries according to Eq. (5), of which, according to Eq. (6), are on the constant gray level differences line . The remaining nonzero GLCM entries have the endpoint coordinate always beginning at zero due to the wrapping around modulo in the gray level intensity space:
(7)
Such GLCM entries are , , and so on. One notices that all these new GLCM entries align along the line of constant gray level differences , as shown in Figs. 3D and 3H. To summarize, the (unnormalized) marginal distribution of gray level differences for linear gradients represents the frequency of various combinations of pixel intensities that yield a specific absolute difference value :
(8)
Marginal distribution of gray level sums for linear gradients
The previous section demonstrated that linear gradients are naturally represented by non-zero entries parallel to the primary diagonal of the GLCM. Thus, the marginal distribution of gray level difference arises naturally from GLCM symmetry. Other Haralick features require calculating the marginal distribution for a given sum of gray level intensity , where One can utilize the GLCM symmetries caused by linear gradients and the corresponding marginal distribution where to streamline the calculation of the other marginal distribution . Indeed, from , the nonzero endpoint gray level intensity are where . Therefore, the elements of the marginal distribution are with . Similarly, the second line of constant gray level differences is where and , which determines the marginal distribution with . In summary, the (un-normalized) marginal distribution of gray level sums for linear gradients indicates the frequency of various combinations of pixel intensities that total a specific value :
(9)
Analytic scaling laws for Haralick features of linear gradients Comparison with numerical results
The previous subsection includes all the elements needed to estimate analytically any Haralick feature. In the following subsections, we derive analytical formulas for SA, SV, difference variance (DV), and Entropy based on the GLCMs symmetries derived in the previous subsections. Anticipating the results from the following subsections, the analytic scaling laws for Haralick features take the general form
where the scaling exponents and are derived from the GLCM symmetries as we will prove below.
To validate our theoretically predicted scaling laws for Haralick features, we performed numerical calculations using synthetic (computer-generated) gradient images. The predictions are represented by continuous lines in Figs. 4 and 5. At the same time, the corresponding numerical simulation results—based on the synthetic images described in “Synthetic Gradient Images”—are shown as discrete points with different symbols, as indicated in the figure legends.
To reduce plot clutter in Figs. 4 and 5, we present results only for odd intensity gradient values of gray levels per pixels. In Fig. 4 the displacement vector magnitude was fixed at , while the number of gray levels varied as . Conversely, in Fig. 5 the bit depth was set to bits ( ), while the vertical displacement vector magnitude varied as For each synthetic image with a given bit depth and gradient intensity , we computed the GLCMs for each vertical displacement vector using Matlab’s function. For instance, the GLCM shown in Fig. 1C was obtained using (img,‘Offset’,[0 1], ‘NumLevels’, 4, ‘GrayLimits’, [], ‘Symmetric’,false). Additionally, when calculating all Haralick features, we consistently set the ‘Symmetric’ flag in graycomatrix() to true. Subsequently, we computed Haralick features from GLCMs using Matlab function .
For a single period of a linear gradient (see Fig. 3) all nonzero entries of the GLCM given by Eq. (5) have equal weight and are only aligned to two parallel lines to the primary diagonal as in Figs. 3D and 3H.
Sum average
The SA indicates the uniformity of intensity values across the image texture. A higher SA value represents an even distribution of intensity sums between neighboring pixels. SA is defined as:
(10)
A high SA implies that most pixel pairs have similar intensity sums, indicating a relatively uniform texture. A low SA suggests more significant variation in intensity sums between neighboring pixels, signifying a more textured appearance. From Eq. (10) with Eq. (9)
(11)
To simplify the calculation of above, we separated the contributions of the GLCM entries that are parallel to its primary diagonal at a distance of from those on the line where . Each of the two terms in Eq. (11) is an arithmetic series with the sum . For in Eq. (11) one uses and for one substitute and .
The first observation is that the theoretically predicted SA value given by Eq. (11) is independent of the gradient intensity (see the continuous lines in Fig. 4A) and the displacement vector (see the continuous lines in Fig. 5A) as summarized also in Table 1. Numerically computed Haralick feature SA confirms that its values are independent of gray level intensity gradients and increases linearly with the number of gray levels as shown in Fig. 4A. The exact formula in Eq. (11), which involves the discontinuous integer part function , is challenging to work with; however, by dropping the integer part operation, one finds a continuous approximate value . This approximation demonstrates that scales linearly with (see the continuous lines Fig. 4A, which is also confirmed numerically by the linear increase of Haralick features with the number of gray levels shown in Fig. 4A. The second observation is that, numerical simulations shown in Fig. 5A confirm our theoretical prediction based on Eq. (11) that SA feature is independent of the displacement vector magnitude . One notices, a slight error in approximating with . For example, a gray level image and a gradient gray levels per pixel gives , which is slightly less than the simplified approximation , but the error is under 0.4%. Even for gradients as large as gray levels per pixel, the error of approximating with is below 1%. This slight disagreement between the theoretical predicted SA value from Eq. (11) and the numerically computed values is emphasized in Fig. 5A. One can conclude that the gradient slightly decreases the SA value , but the correction is negligible for small gradients gray levels per pixel. This fact is marked by the general attribute “independent” with an asterisk in Table 1.
| Sum average | Linear | Independent | Independent* |
| Sum variance | Quadratic | Linear | Linear |
| Difference variance | Linear | Linear | Linear |
| Entropy | Logarithmic | Independent | Independent* |
Note:
The asterisk mark next to “independent” attribute means the respective feature very slightly decreases with , and this effect can be neglected for gray levels per pixel.
Sum variance
The sum variance feature is defined as follows:
(12) and can be analytically estimated for GLCM of linear gradients using the same strategy described above when deriving explicit analytical expression for SA in Eq. (11).
(13)
To accurately predict the scaling law of SV features from the exact formula given by Eq. (13), one could eliminate the integer part function from the definition of and utilize an approximate estimate:
(14)
The discrepancy between the true (Eq. (13)) and the approximate estimate is minor but can reach several percentage points. For example, the largerst error occurs for , , and , which is approximately 3.33%.
Based on Eq. (14), one notice that SV scales quadratically with . Indeed, the second term in Eq. (14), which is linear in , is always smaller than the first term, quadratic in if . This condition is fulfilled because the product pixels times gray levels per pixel is the number of gray levels variation across an image, which cannot be larger than . Numerical simulations confirmed our analytical prediction of a quadratic scaling law for with , as shown in Fig. 4B. One also notices from Fig. 4B that for fixed displacement vector magnitude , numerical values of SV are independent of gradient intensity as predicted analytically by Eq. (14).
For an image with a fixed number of gray levels and gradient gray levels per pixel, the second term in Eq. (14) dominated SV’s dependence on . This is because , which reduces to . This was shown above to be true for all images. Furthermore, the second term in Eq. (14) is also larger than the fourth term because even for the smallest possible displacement vector with . As a result, the linear term is the primary influence in the scaling law of , which aligns with our numerical simulations shown in Fig. 5B. As noticed from Fig. 5B, for a fixed displacement vector magnitude , SV linearly changes with the gradient intensity as predicted analytically (see also Table 1).
Difference variance
The definition of difference variance is:
(15) where the DA is given by . The evaluation of DA is straightforward and follows from Eq. (8) since all GLCM entries are equal weight:
As a result, the DA reduces to
(16)
To infer the asymptotic scaling law exponents from the exact formula of DS given by Eq. (16), one drops the integer part function from and uses an approximate formula , which suggests the scaling law
The theoretically predicted linear scaling with is confirmed by numerical simulations shown in Fig. 4C, for a fixed pixel and slopes that increase linearly with the gradient intensity .
The scaling of experimental with the displacement vector exhibits a linear dependence with a slope proportional to the gradient . Additionally, the plot of the theoretical prediction from Eq. (16) shows some deviation from linearity for large gradients. This is expected because neglects the contribution of the term compared to . However, the contribution of the neglected term increases quadratically with the gradient and could become significant for images with large gradients (see Table 1).
Entropy
The Haralick features discussed thus far are derived from different moments of the marginal distribution of either the difference intensity (see Eq. (8)) or the sum intensity (see Eq. (9)). In contrast, entropy employs a logarithmic scale to compute features from the GLCM. The definition of the entropy feature is:
(17)
Entropy reaches its maximum value when a probability distribution is uniform (entirely random texture) and its minimum value of 0 when all grayscale values in the image are the same. If the entropy is defined using the base-2 logarithm , then is measured in bits. While we only examined the entropy feature , employing the marginal distributions of pixel intensity sums from Eq. (9) along with the detailed calculation examples for the SA and SV features, one can easily deduce the scaling law of SE defined by:
(18)
Similarly, by using the marginal distribution of pixel intensity difference from Eq. (8) and the detailed calculation examples provided for the DA feature, one can easily derive the scaling law of DE defined by:
(19)
Calculating entropy is straightforward because all GLCM entries carry equal weight, leading to:
(20)
As seen from the numerical simulation results presented in Fig. 4D, the theoretical scaling law derived from Eq. (20) captures the general logarithmic trend of the entropy. However, it slightly underestimates it (see Table 1). Numerical simulations illustrated in Fig. 5D confirm that Entropy feature is independent of the magnitude of the displacement vector, as predicted by Eq. (20), and also slightly underestimates the actual values. The discrepancy arises from an offset constant used in estimating the entropy from images where was employed instead of to prevent the entropy singularity for sparse GLCM.
Discussions and conclusion
Haralick’s features are widely used in data dimensionality reduction and ML algorithms for image processing in a wide range of practical applications such as MRI (Brynolfsson et al., 2017) and CT scan image processing (Cao et al., 2022; Chen et al., 2021; Park et al., 2020; Shafiq-ul Hassan et al., 2017, 2018; Tharmaseelan et al., 2022), cancer detection (Faust et al., 2018; Cook et al., 2013; Permuth et al., 2016; Soufi, Arimura & Nagami, 2018), liver disease (Acharya et al., 2012, 2016; Raghesh Krishnan & Sudhakar, 2013) and mammographic masses classification (Midya et al., 2017), colon lesions (Song et al., 2014), prostatic devices for disable people (Alshehri et al., 2024), detection of violent crowd (Lloyd et al., 2017), image forensic (Kumar, Pandey & Mishra, 2024), malware detection (Ahmed, Hammad & Jamil, 2024; Karanja, Masupe & Jeffrey, 2020), human face detection (Jun, Choi & Kim, 2013), computer network intrusion detection (Baldini, Hernandez Ramos & Amerini, 2021). However, their interpretation poses challenges since they are second-order statistics that depend in a complicated and nonlinear manner on image characteristics such as the number of gray level quantization and and the intensity of image gradients and the selected displacement vector between adjacent pixels through the image. This study focused on extracting meaningful analytic expressions and deriving asymptotic scaling laws from Haralick’s features for synthetic images containing only linear gradients. We focused on linear gradients for several reasons: (a) The human visual system efficiently decomposes and analyzes natural scenes using orthogonal gradients (Jagadeesh & Gardner, 2022; Barten, 1999; Bracci & Op de Beeck, 2023; Cheng, Chen & Dilks, 2023; Henderson, Tarr & Wehbe, 2023), (b) Efficient computer vision algorithms leverage gradient spectral priors to extract image features (Gong & Sbalzarini, 2016; Zheng et al., 2022), (c) In 2D natural scene images, orthogonal gradients are uncorrelated (Gong & Sbalzarini, 2016), and (d) The entries of the GLCM serve as natural measures of image gradients. For instance, is the gradient intensity in a given image along the displacement vector . We demonstrated that the GLCM for any linear gradient has nonzero entries solely along the two lines parallel to its principal axis diagonal shown in Fig. 3. We found that for any GLCM associated with an image gradient, the total number of entries is given by Eq. (5). The two lines parallel to the primary diagonal in Fig. 3 represent the gray level differences: (1) , with entries (see Eq. (6)) and (2) , with entries (see Eq. (7)). Due to the GLCM symmetry for linear gradients, we derived explicit analytical expressions for the marginal probabilities and that are used to compute some of Haralick’s features. To our knowledge, this is the only study that derived explicit mathematical expressions of Haralick’s features in terms of the number of gray level quantization , the magnitude of the linear gradient present in the image, and the displacement vector used for calculating the GLCM of the image.
We found that the analytic formula for the SA in Eq. (10) scales linearly with the number of gray levels in the image and is independent of both the image gradient and displacement vector . The numerically estimated dependence of on shown in Fig. 4A confirms the theoretical predictions. Similarly, numerical simulations confirm that is independent of the magnitude image gradient and the vertical displacement vector as shown in Fig. 5A.
The theoretical formula for the SV in Eq. (12) shows the asymptotic scaling law as . As predicted theoretically, SV increases quadratically with , which was confirmed numerically (see Fig. 4B). The analytically predicted SV increases linearly with , which was numerically confirmed in Fig. 5B, which shows that the slope of the SV vs increases proportional to the gradient intensity .
We also predicted analytically that the DV features given by Eq. (16) has a scaling law . Our numerical simulations confirmed that SD increases linearly with , with a slope that itself increases linearly with the image gradient , as shown in Fig. 4C. For a fixed , the SV increases linearly with the magnitude of the displacement vector ( ), with a slope proportional to (see Fig. 5C).
As we predicted theoretically, the entropy scales logarithmically with and and is independent of , i.e., .
We provided a detailed derivation of exact analytic formulas and asymptotic scaling laws for the four Haralick features associated with vertical image gradients.
Since natural scenes can be decomposed into orthogonal and uncorrelated gradients (Gong & Sbalzarini, 2016), our derivations can be extended to a multidimensional gradient-based Haralick feature space. In our synthetic images, we introduced a single gradient along the vertical direction ( ) while setting the horizontal gradient to zero ( ) as shown in Fig. 3. This design simplified the identification of general GLCM symmetries induced by the gradient, as described in “Methods”. However, our derived formulas remain valid because, even in natural scenes, orthogonal image gradients are uncorrelated.
To generalize our findings, the scalar gradient must be replaced with the gradient vector for 2D images. The analytical formulas we derived for Haralick’s features can be used to estimate image gradients from measured features. Another application involves deriving consistent normalization factors for Haralick features. Comparing the values of Haralick features across datasets from different scanners with varying resolutions is challenging and different empirical normalizations algorithms achieved only limited success (Clausi, 2002; Lofstedt et al., 2019; Shafiq-ul Hassan et al., 2017, 2018). Thus, identifying suitable normalization factors that render Haralick features invariant to the number of gray levels or the quantization scheme is crucial among other fields in radionics.
We demonstrated that the SA feature in Eq. (10) should be normalized by to ensure asymptotic independence from the quantization scheme. This normalization allows for the consistent comparison of the Haralick SA feature across images obtained at different resolutions and with various imaging devices. Similarly, we analytically proved that the SV feature in Eq. (12) should be normalized by to achieve invariance to the image quantization scheme. Unlike empirical trial-and-error approaches, our normalization factors are rigorously derived based on the symmetries of the GLCM, ensuring mathematical consistency and robustness.
Supplemental Information
The main Matlab file used for computing the Haralick features.
This generates the figures from the paper. All for loops run through the data set values and produce the discrete points shown on the paper.
The Haralick function f6 required by the main Matalb file.
The file generates the values for Haralick features that will generate the figures from the paper. All for loops run through the data set values and produce the discrete points shown on the paper.
The Haralick function f10 required by the main MATLAB file.
The file generates the values for Haralick features that will create the figures from the paper. All for loops run through the data set values and produce the discrete points shown on the paper.
The Haralick function f9 required by the main MATLAB file.
The file generates the values for Haralick features that will create the figures from the paper. All for loops run through the data set values and produce the discrete points shown on the paper.
The Haralick function f7 required by the main MATLAB file.
The file generates the values for Haralick features that will create the figures from the paper. All for loops run through the data set values and produce the discrete points shown on the paper.