
Refining medical large language models: key insights from instruction tuning
- Published
- Accepted
- Received
- Academic Editor
- Shibiao Wan
- Subject Areas
- Bioinformatics, Artificial Intelligence, Computational Linguistics, Data Mining and Machine Learning, Data Science
- Keywords
- Large language model, Natural language processing, Medical LLM, Instruction fine tuning, Clinical applications, NLP tasks, Dataset curation, Instruction tuning
- Copyright
- © 2025 Alqahtani et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Refining medical large language models: key insights from instruction tuning. PeerJ Computer Science 11:e3216 https://doi.org/10.7717/peerj-cs.3216
Abstract
This literature review introduces a comprehensive summary of the most recent scholarly work on instruction-tuning strategies for medical large language models (Med-LLMs). It begins by reviewing three fundamental approaches to creating an instruction dataset: human-crafted datasets, synthesized datasets generated by LLMs, and datasets that incorporate Retrieval-Augmented Generation (RAG). This article explores the role of medical instruction datasets by reviewing thirteen different medical models, evaluating their effectiveness across multiple clinical tasks, and examining how their utilization can improve outcomes in the medical domain. This research discusses key insights for optimizing instruction-based fine-tuning of language models. It analyzes the effectiveness of the phased instruction method and the benefits of integrating mixed-prompt techniques. Additionally, it assesses the effect of choosing an appropriate backbone model before fine-tuning. Furthermore, it demonstrates how the selection of words when crafting instructions influences a model’s performance. The survey emphasizes that carefully curated instructional data, coupled with well-crafted strategies, can greatly enhance the potential of Med-LLMs in real-world healthcare applications. Nevertheless, several challenges must be addressed to ensure the safe, ethical, and effective deployment of Med-LLMs. This article outlines future research directions, including mitigating racial and gender biases, leveraging external knowledge sources, and reinforcing privacy through robust anonymization of patient information and regulatory adherence (e.g., Health Insurance Portability and Accountability Act (HIPAA)). Addressing these challenges will pave the way for reliable, safe, and ethical artificial intelligence (AI)-driven healthcare applications.
Introduction
The application of large language models (LLMs) in the medical domain has received considerable attention (Nazi & Peng, 2024) for their potential to enhance various medical tasks, such as clinical decision-making (He et al., 2023), question-answering (Li et al., 2023) and summarization (Mishra et al., 2014). Several Medical LLMs (Med-LLMs) have been introduced in recent years, which demonstrate exceptional performance across a wide variety of Natural Language Processing (NLP) tasks. Some of these notable models are Medical Pathways Language Model (Med-PaLM) (Singhal et al., 2023), GatorTron (Yang et al., 2022), ClinicalBidirectional Encoder Representations from Transformers (BERT) (Alsentzer et al., 2019), ClinicalT5 (Lu, Dou & Nguyen, 2022), and PubMedBERT (Gu et al., 2022), which are specifically designed to process and understand healthcare and clinical data for automation, enhancement, and streamlining of various aspects of healthcare.
Medical language is generally known for its difficulty, including complex diagnosis terms, medication names, and treatment phrases that require careful interpretation (Yuan et al., 2023). Thus, one solution is to develop a model capable of understanding doctors’ intent and generating outputs that align with their needs. Accuracy is essential in medical models, where misalignment between model outputs and what the doctor wants to say is unacceptable (Yuan et al., 2023). Non-instructed LLMs often fail to meet these demands, and therefore, they may produce responses that may be inaccurate, harmful, or misaligned with user expectations (Wang et al., 2023c, 2023b). Because of this limitation, researchers have started exploring new methods to make models better understand and respond to what people actually want and need (Ouyang et al., 2022).
Instruction fine-tuning is a critical process for alignment of Med-LLMs with specific medical tasks. Figure 1 illustrates the conceptual framework for this process that details the steps from data curation and preprocessing to fine-tuning and hyperparameter optimization. This structured approach ensures that Med-LLMs achieve high accuracy and reliability in diverse clinical scenarios. Having a model that responds in ways that truly match what people need and expect is important to closing the gap between what these language models can do and what humans actually need from them (Zhang et al., 2023a). Instruction tuning is one of these alignment techniques that involves fine-tuning LLMs on datasets containing specific task instructions paired with corresponding responses (Ouyang et al., 2022). Instruction tuning aims to guide models in following human-written instructions to perform tasks effectively and generalize to new, unseen scenarios (Ouyang et al., 2022). In the field of healthcare, datasets are tailored to reflect diverse clinical applications, which include patient-doctor communication, diagnosis assistance, report summarization, and patient discharge instructions (Li et al., 2023). This process enables models to closely align with real-world medical scenarios (Zhang et al., 2023a).
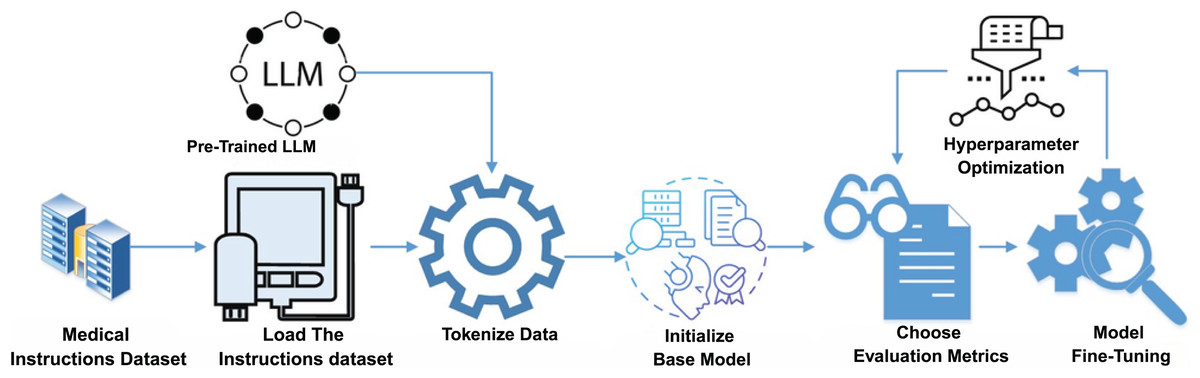
Figure 1: Conceptual framework of instruction fine-tuning for Med-LLMs.
{kind=link}
Instruction tuning faces several key challenges despite its demonstrated effectiveness:
-
1.
Balancing datasets in terms of data quantity and quality remains a critical challenge for optimizing model performance (Zhao et al., 2024; Zhou et al., 2023).
-
2.
The selection of the base model significantly impacts the overall performance of the fine-tuned model (Gudibande et al., 2023).
-
3.
Instruction-tuned models often poorly comprehend complex medical scenarios and therefore produce responses that reflect surface-level patterns rather than true representation. This sensitivity to phrasing can lead to varying outputs due to slight perturbations in wording, even when the intended meaning remains unchanged (Arroyo et al., 2024).
Recent studies are increasingly focused on adopting LLMs for healthcare, including advancements in pre-training models (He et al., 2023), applications (Yang et al., 2023; Liu et al., 2024a), and medical-specific algorithms (Liu et al., 2024a). This survey highlights state-of-the-art methodologies to emphasize instruction tuning as a cornerstone for aligning LLMs with complex medical environments. Specifically, the survey explores the use of instruction datasets, medical datasets, and optimization techniques that enhance Med-LLMs performance. Figure 2 provides a high-level overview of the key components and strategies involved in instruction tuning for Med-LLMs. These strategies include dataset curation methodologies, medical datasets tailored for instruction tuning, models designed for medical tasks, and optimization techniques that improve model alignment with the healthcare domain.
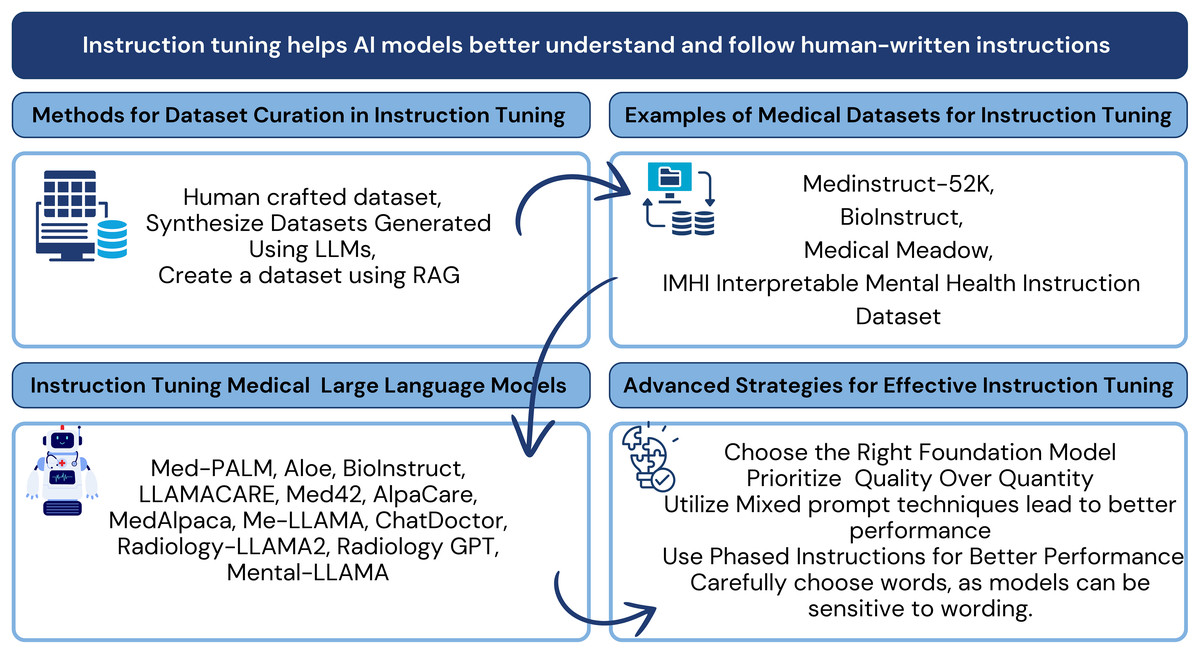
Figure 2: Conceptual framework for instruction tuning in medical LLMs: connecting dataset curation methods, medical instruction datasets, tuned models, and optimization strategies examined in this review.
{kind=link}
Methods
A systematic search was conducted using Google Scholar and PubMed to evaluate the latest advancements in instruction tuning for medical large language models (Med-LLMs). The review identifies key trends in dataset curation, optimization techniques, and the effectiveness of instruction tuning across clinical NLP tasks. The initial research was carried out by the first author and subsequently refined by the second author.
This review was conducted without prior preregistration, as the requirement for scoping reviews was not recognized at the beginning of this study. However, we committed to established scoping review guidelines to maintain transparency and methodology. In future reviews, we will incorporate preregistration to align with best practices.
The inclusion criteria for the selected articles were structured based on the Population, Intervention, Comparator, and Outcome (PICO) (Schardt et al., 2007) framework to ensure a systematic and consistent selection process. Additionally, this article adheres to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) extension for the literature review (Tricco et al., 2018).
Search strategy and relevant studies
A systematic search was performed using multiple databases, including PubMed, IEEE Xplore, ACM Digital Library, Scopus, Web of Science, and Google Scholar, to identify relevant studies. These databases were selected based on their relevance to medical informatics, artificial intelligence, and computational linguistics. The selection process followed predefined inclusion and exclusion criteria to ensure comprehensive and unbiased selections. Studies were selected if they exclusively used instruction tuning for large language models in the medical domain. Instruction tuning (IT) emerged as a significant advancement in LLM, started in 2022. It is marked by the introduction of InstructGPT (Wei et al., 2022). Our literature review explores the intersection of this technology with medical domain from 2022–2024. The researcher investigated articles over several months, ensuring the inclusion of cutting-edge research from July 4th, 2024, to December 31st, 2024. We limit the search to English-language articles only.
The search queries included combinations of the following keywords: “Medical Large Language Models” “Instruction Tuning in the medical domain” “Fine-Tuning LLMs for Clinical Applications” The complete search strings used across databases included: —**PubMed**: (“Medical Large Language Models” OR “Clinical LLM” OR “Healthcare Language Models”) AND (“Instruction Tuning” OR “Fine-tuning” OR “Instruction Following”)—**Google Scholar**: “Medical LLM instruction tuning” OR “Clinical language model fine-tuning”—**Additional terms**: “Med-LLM”, “Clinical NLP”, “Healthcare AI instruction datasets”.
Inclusion and exclusion criteria
The inclusion criteria were: (1) studies focusing on instruction-tuned medical LLMs. (2) Research published in peer-reviewed journals or preprints with significant citations. (3) Articles evaluating instruction datasets for medical NLP applications. (4) Studies that report quantitative performance metrics. (5) Publication dates range from 2022–2024. (6) Articles with qualitative evaluation. (7) Studies were limited to text-based input and output generation. The exclusion criteria include: (1) non-medical LLM applications. (2) Studies without a clear evaluation of instruction tuning. (3) Non-English studies. (4) Studies with other forms of text generation, such as image, video, or audio-based generation, and vice versa.
Study screening
Mendeley Reference Manager managed the article collections and helped to detect duplicate articles. All articles’ titles and abstracts were examined for the initial inclusion phase. In the second phase, we reviewed the full text and the methods part of all articles to ensure that all included articles have two key criteria: relevance to the medical domain and instruction tuning methods.
Data extraction and synthesis
For each selected article, the following details were reviewed and systematically categorized, including: (1) each article’s main objectives and contributions to instruction tuning for Medical LLMs. (2) Existing instructed datasets used to fine-tune Med-LLMs, including a review of models and their characteristics, sources of datasets, dataset size, and their various NLP and clinical tasks. (3) Extract the promoting techniques and the training techniques.
Search result
Our literature review identified thirteen instruction-tuned models in the medical domain, all of which focused on NLP-based clinical tasks and their potential applications. All the included studies pertain to the medical domain, covering various branches such as radiology, mental health, and general medical applications, and involve instruction-based fine-tuning to optimize model performance.
Figure 3 provides a visual overview of the key components and strategies involved, including dataset curation methodologies, commonly used medical datasets, fine-tuning techniques, and optimization strategies specifically adapted to healthcare contexts.
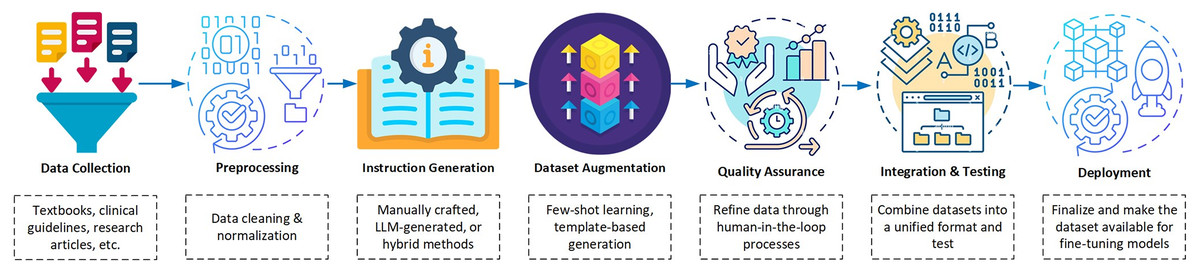
Figure 3: Key components and strategies in instruction tuning of medical LLMs, such as dataset curation methodologies, medical datasets, fine-tuning techniques, and optimization strategies tailored for healthcare.
{kind=link}
Instruction datasets curation techniques
The effectiveness of instruction tuning fundamentally depends on dataset curation. High-quality datasets require clear and explicit instructions that guide the model in performing the desired NLP task. Unlike traditional training datasets that simply pair inputs with their outputs or questions with answers, instruction-tuned datasets provide detailed guidance for each input to generate the desired output. They provide step-by-step guidelines for task completion. Through such explicit guidance, these datasets improve model alignment with human expectations by enhancing performance across diverse and complex tasks. This section explores three primary approaches to dataset curation: human-crafted datasets, synthesized datasets generated using LLMs, and hybrid datasets created through Retrieval-Augmented Generation (RAG) combined with LLMs. Each technique presents distinguished features, challenges, and applications (Ouyang et al., 2022).
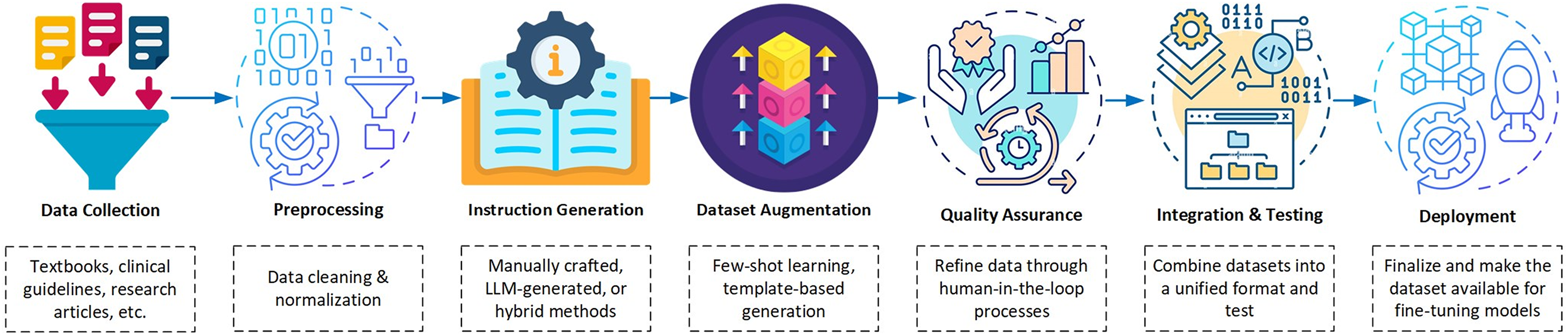
In the development phase of dataset curation for instruction tuning, a systematic pipeline is essential to ensure quality and relevance. Figure 4 illustrates the dataset curation pipeline that highlights the key steps from data collection to deployment. These steps include intermediate processes such as augmentation and quality assurance that ensure the creation of robust datasets tailored for medical applications. This workflow enables dataset curation to support instruction tuning in a structured and efficient manner. It emphasizes critical elements such as data augmentation for diversity and quality assurance for reliability by making it a cornerstone for developing high-quality datasets for medical applications.
Figure 4: Block diagram illustrating the dataset pipeline for instruction tuning Med-LLMs.
{kind=link}
Human-crafted dataset
In the category of human-crafted datasets, manually curated datasets are reformatted in such a form to make them suitable for instruction tuning training. This approach simply depends on experts to format the dataset: input, output, and their corresponding output (Si et al., 2023). This dataset format enables the model to follow human instructions, which improves its alignment with doctors’ preferences. Again, such datasets are written with expert oversight without the support of popular LLMs (Wu et al., 2022). Although this approach is resource-intensive, these datasets offer unparalleled alignment with clinical standards by using iterative refinement techniques like Human-In-The-Loop (HITL) (Mosqueira-Rey et al., 2023).
Similarly, human annotators can be hired and their role is to correct only the unclear outputs generated by the model. The process starts with estimating the confidence level for each output and proceeds to find the examples with the lowest confidence scores. These usually have the most uncertain predictions. These low-confidence outputs are flagged for annotator review, where they refine these specific cases. This targeted method, called uncertainty sampling in active learning, optimizes annotation. It focuses human efforts not on the whole dataset but on the most unclear examples (Kirsch, van Amersfoort & Gal, 2019).
Synthesize datasets generated using LLMs
Synthetic dataset approaches depend on the power of LLMs for generating the instructions, instead of manual curation. For example, GPT-4 (OpenAI et al., 2023) offers a valuable tool for creating instructions or augmenting existing ones (Brown et al., 2020; Ouyang et al., 2022). For instance, MedInstruct-52k demonstrates the capability of LLMs to augment existing datasets. The researchers create a variety of instructions and wide-ranging NLP tasks by using GPT-4 only. This approach requires an initialization seed, which helps reliably augment existing datasets (Lavita, 2023).
In the same way, template-based datasets can be used too. This method uses predefined templates to format the dataset. It provides a systematic template for formulating instructions, inputs, and expected outputs. The approach ensures consistency for the whole expected output. It is a valuable method in domains where high precision is important (Zhang et al., 2023b). By using a fixed format, template-based generation reduces errors and enhances clarity. However, this approach carries a problem, which is a possible mismatch with human needs. A major reason behind mismatches arises when templates fail to capture some details and domain variations (Syriani, Luhunu & Sahraoui, 2018; Kale & Rastogi, 2020). Continuous iterative refinement stands as a solution to capture all possible formats (Kale & Rastogi, 2020).
Dataset generation using RAG and LLMs
The RAG technique (Sung, Lee & Tsai, 2024) gathers the strengths of both retrieving relevant information from relevant databases and generating required information using LLM in order to build an instructional dataset. RAG mainly works through two building blocks: a retriever and a generator. First, the retriever block identifies and extracts the most relevant documents from external databases. The importance of the retrieval block is that it gives the groundwork for the generation phase, ensuring that the generated content is contextually relevant. The retrieved information is then fed into an LLM to generate precise outputs, which can be utilized as custom instructions. For instance, Fig. 5 shows the integration of RAG with Mistral-7B, to generate an instructional dataset (Sung, Lee & Tsai, 2024).
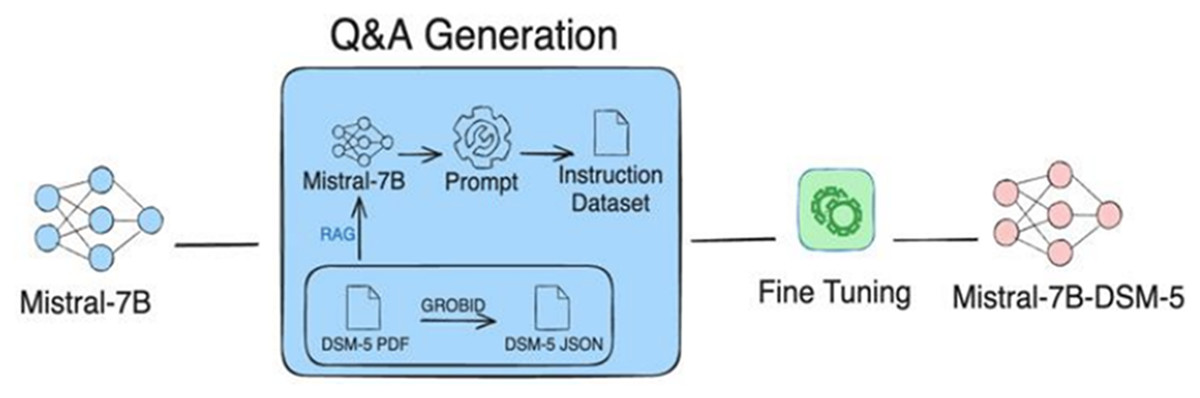
Figure 5: Illustration of instructions-tuned dataset generation process using RAG approach.
The process integrates Mistral-7B with RAG to retrieve data from DSM-5 documents to be used for fine-tuning the model. Figure adapted from Sung, Lee & Tsai (2024).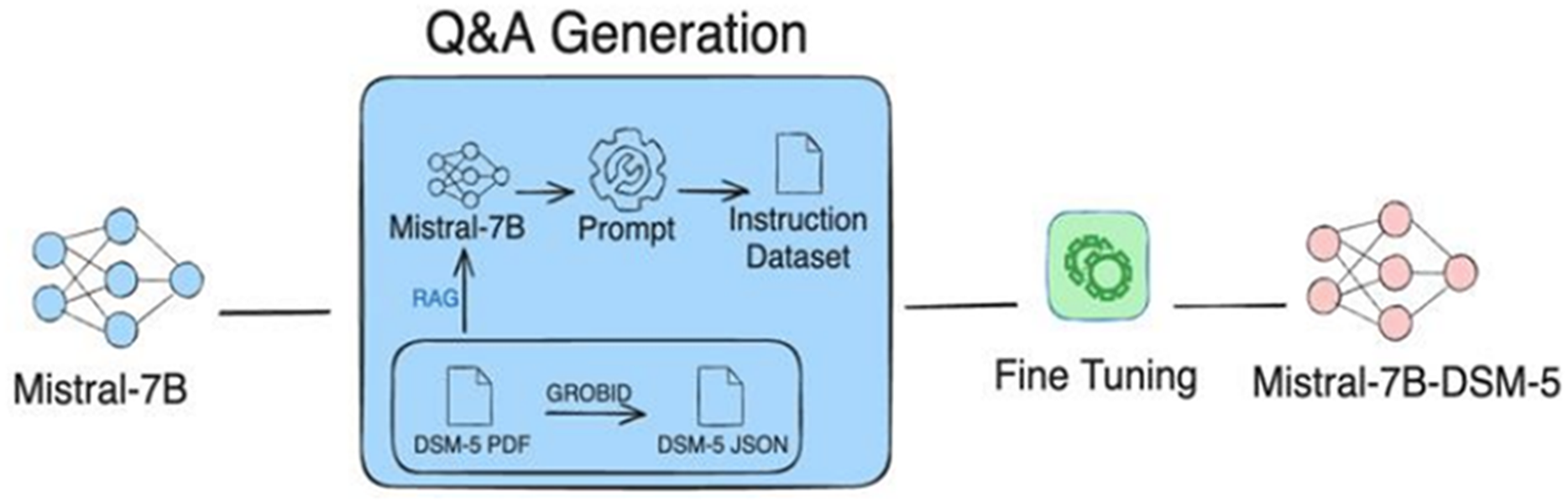{kind=link}
In comparison with other methods, RAG offers greater efficiency and scalability by minimizing noisy data. Despite its effectiveness, RAG heavily depends on the quality of the external databases, which must be reliable and comprehensive. Therefore, ensuring the accuracy and reliability of the databases is a major challenge (Sung, Lee & Tsai, 2024). However, RAG demonstrates its capabilities by efficiently generating customized, domain-specific datasets. RAG approach particularly excels in sophisticated fields like healthcare where specialized knowledge is crucial (Sung, Lee & Tsai, 2024). The approaches to dataset generation—such as human-crafted, LLM-synthesized, and hybrid RAG-LLM—each offer distinct advantages and limitations. Table 1 provides a comparative overview of these dataset curation techniques, highlighting their respective strengths and weaknesses. The subsequent section explores various medical instruction datasets that have been used to fine-tune Med-LLMs, thereby enhancing their performance across diverse clinical tasks.
| Approach | Merits | Demerits | Best-fit scenarios |
|---|---|---|---|
| Human-crafted dataset | High precision and alignment with human intent; iterative refinement through human-in-the-loop (HITL) methods and uncertainty sampling enhances quality. | Resource-intensive and time-consuming; requires significant domain expertise. | Suitable for high-stakes tasks such as clinical decision-making, patient discharge instructions, and scenarios demanding expert validation. |
| LLM-synthesized dataset | Scalable and automated; enables rapid data augmentation and generation using LLMs. | May lack alignment with nuanced human preferences; template-driven outputs can be repetitive or incomplete. | Useful for exploratory tasks, early-stage model training, and expanding datasets for general medical applications. |
| RAG-LLM hybrid dataset | Generates domain-specific, contextually relevant examples; reduces noise by grounding with high-quality external sources. | Heavily dependent on the reliability and quality of retrieved source documents. | Best suited for specialized domains such as rare disease modeling, mental health (e.g., DSM-5), and dynamic fields requiring continual updates. |
Medical instruction datasets
Instruction datasets play a fundamental role in fine-tuning Med-LLMs in order to address the multiple requirements of healthcare applications. These datasets target specific medical areas, including United States Medical Licensing Examination (USMLE) exam questions, clinical diagnostics, symptom extraction, and patient interaction summaries. Below are instances of the most prominent medical instructional datasets utilized in research, each one designed to prompt the capabilities of LLMs in healthcare.
MedInstruct-52k instruction dataset
The MedInstruct-52k dataset (Taori et al., 2023b) is a large-scale, instruction-tuned dataset designed to fine-tune LLM in the medical domain. It consists of 52,000 medical tasks. Each instance in the dataset is comprised of instructions paired with corresponding input and output data. These tasks reflect different clinical tasks, including patient diagnosis, treatment plans, clinical summarization, and conversation-like question-answering. The MedInstruct-52k dataset (Taori et al., 2023b) collects its data from reliable medical materials, including books, articles, clinical guidelines, electronic health records (EHRs), question banks, public datasets, and expert input. It is created using a combination of automated generation and manual expert curation. Models such as AlpaCare (Zhang et al., 2023c), Aloe model (Gururajan et al., 2024), and Medical Large Language Model Meta AI (Me-LLaMA) model (Xie et al., 2025) use MedInstruct-52k dataset for fine-tuning. The following subsections are further details of how those models adopt the MedInstruct-52k dataset.
AlpaCare instruction dataset
The AlpaCare model (Taori et al., 2023b) utilizes the MedInstruct-52k dataset. Before the fine-tuning process, the dataset is augmented with an initialization seed of 167 instructions written by experts. These seeds cover various dimensions, including difficulty levels, task types, perspective views, and medical topics. Fine-tuning AlpaCare with this specialized dataset enhances the model’s capability to effectively handle different difficulty levels. This fine-tuning methodology optimizes the model’s responses to complex medical scenarios and boosts its ability to generalize.
Aloe instruction dataset
The Aloe model (Gururajan et al., 2024), fine-tuned using the MedInstruct-52k dataset (Taori et al., 2023b), but does not depend exclusively on this dataset. Instead, it integrates additional datasets from both medical and general domains. By maintaining an 8:1 ratio of medical to general domain data. This integration is necessary to avoid catastrophic forgetting, a problem that occurs in the fine-tuning process where previously learned information is lost or faded (Luo et al., 2023; Gururajan et al., 2024). In detail, the dataset is developed by incorporating a variety of specialized medical datasets and general ones and formatting them using Mixtral-7B. It deploys both single-turn and multi-turn question-answer templates. The goal of using those multiple templates is to ensure that the model is exposed to diverse input formats. The final dataset comprises 750,257 instances, each containing a question and its corresponding answer (Taori et al., 2023b).
ME-LLAMA instruction dataset
The Me-LLaMA model (Xie et al., 2025) uses a primarily biomedical instructed dataset collected from biomedical research, patient records, and medical guidelines. Also, it incorporates MedInstruct-52k dataset (Taori et al., 2023b). The dataset is composed of biomedical literature, clinical notes, and general-domain content in a ratio of 15:1:4. This instructed dataset leverages a wide range of medical tasks based on the provided instructions. For example, it supports summaries for patient records.
BioInstruct instruction dataset
The BioInstruct dataset (https://github.com/bio-nlp/BioInstruct; Tran et al., 2023) is a large-scale synthesized instructed dataset specialized in the biomedical domain. The BioInstruct dataset started with just 80 handwritten seeds that covered key medical instructions. Then, GPT-4 (OpenAI et al., 2023) was used to expand the dataset. It is built to fine-tune LLMs and help the model follow instructions. Examples include clinical diagnosis, treatment recommendation, symptom analysis, and patient-doctor conversation summarization. The dataset consists of 25,005 instances; each instance has well-defined instructions associated with input and a corresponding output. It also includes metadata for each instance to deliver enriched context and specific details about the task.
IMHI interpretable mental health instruction dataset
The Interpretable Mental Health Instruction (IMHI) dataset (Yang et al., 2024) is a unique dataset instructed to improve the understandability of mental conditions. It comprises 105,000 reformatted data collected from 10 real-world conversations on social platforms, including Reddit, Twitter, and SMS texts. Platforms where people may share their thoughts and explain their struggles. This dataset provides interpretative analysis for specified mental health conditions such as depression, stress, anxiety, post-traumatic stress disorder (PTSD), and suicidal thoughts. It supports assorted mental health tasks, including symptom detection, causal factor identification, and risk factor analysis. The IMHI dataset aims to equip trained models with the ability to detect mental health conditions, whereas also generates high-quality explanations for these conditions. Figure 6 illustrates the components of IMHI dataset, including task-specific instructions, expert-crafted examples, and queries associated with the target posts. This structure ensures the dataset is well-suited for fine-tuning of the model in clinical and mental health domains. Table 2 presents a range of instruction datasets that have been developed to support both clinical and NLP tasks. Each dataset employs distinct models and methodologies tailored to specific medical applications.

Figure 6: Illustration of a structured instructional dataset curated for mental health research (Yang et al., 2024).
{kind=link}
| Ref | Year | Model | Entries | Clinical tasks | NLP tasks | Technique |
|---|---|---|---|---|---|---|
| MedInstruct-52k | 2024 | Aloe, AlpaCare, Me-LLaMA | 52,000 | Medical questions, USMLE MCQs, diagnostics, clinical info extraction, summarization, note generation, decision-making | QA, IE, NLI, text gen., summarization, rewriting, multi-hop reasoning | Semi-automated using GPT-4/ChatGPT. Rouge-L filtering. 214k instruction dataset. Complex reasoning focus (CDSS). |
| BioInstruct | 2024 | BioInstruct | 25,005 | Biomedical QA, diagnostics, treatment planning, medication extraction, coreference resolution, conversation summarization | QA, IE, NLI, text generation | Self-Instruct with GPT-4. Few-shot prompting. Optimized for clinical extraction and coreference resolution. |
| Medical Meadow | 2023 | MedAlpaca | 160,000 | Clinical questions, diagnostics, info extraction, report summarization, radiology, USMLE MCQs, clinical notes | QA, IE, NLI, NER, RE, summarization, text gen. | Synthetic data via GPT-3.5-Turbo. Rephrases existing Q&As. Clinical report summarization. |
| IMHI | 2024 | MentaLLaMA | 105,000 | Symptom detection, mental health condition identification, psychological risk factor identification | IE, NLI, classification, text gen., summarization | ChatGPT generates explanations from few-shot examples. Mental health interpretation focus. |
MedInstruct-52k (Gururajan et al., 2024; Zhang et al., 2023c; Xie et al., 2025) is specifically designed for tasks involving deep reasoning and multi-hop diagnostics. This dataset excels in decision-making scenarios, which makes it highly suitable for assisting clinical decision support systems (CDSS). It focuses on directing medical language models to solve complex diagnostics with higher performance.
BioInstruct (Tran et al., 2023) is particularly effective in tasks that involve conversation-summarization. It is derived from doctor-patient conversations. These conversations contain medical information, such as symptoms, and then draw a structured summary. This enables the models to extract medical information for further analysis or present it in a more readable form. These capabilities make it very important to speed up documentation workflows.
Medical Meadow (Han et al., 2023) is optimal for documentation tasks, including reporting and summarization. Thus, it can be used to create a model for the automatic generation of clinical documentation. The automation aims to reduce the administrative burden on clinicians and enhance workflow efficiency, which will give them more time for patient care.
The IMHI dataset (Yang et al., 2024) provides a well-crafted dataset for mental health applications. It focuses on some tasks, such as symptom detection and risk identification. It aims to provide outputs in a more explainable form since all data is derived from real social platform posts. This dataset is particularly effective for models that aim to improve diagnostic support and patient monitoring in mental health scenarios. These datasets form the foundation for training robust Med-LLMs, enabling them to excel in a variety of medical tasks. These models provide solutions to critical problems in clinical processes and decision-making by using the advantages of each dataset. The key models that were refined using these datasets and the ones that use different datasets to accomplish comparable goals will be discussed in the section that follows.
Foundation transformer models in medical NLP
Instruction-tuned medical large language models (Med-LLMs) like Med-PaLM and Me-LLaMA are impressive, but they build on earlier transformer models designed specifically for medical tasks. These foundational models showed why medical data needs special handling and set the stage for today’s advanced Med-LLMs. Below, we examine three foundational models in medical domain:
BioBERT, marked a significant milestone as the first adaptation of BERT for biomedical texts (Lee et al., 2019). It was trained on PubMed abstracts and PubMed Central (PMC) full-text articles, and it demonstrated that domain-specific training enhances performance in biomedical NLP tasks. For instance, it achieved F1-scores of 89.7% on the National Center for Biotechnology Information (NCBI)-disease and 92.9% on the BC5CDR-chemical dataset in a named entity recognition task (Lee et al., 2019). Its success highlighted the need to adopt medical terminology in order to handle medical domain tasks. It directly influenced the design of all successors models.
ClinicalBERT extended BioBERT work using clinical notes from the Medical Information Mart for Intensive Care III (MIMIC-III) dataset of diverse patient records (Alsentzer et al., 2019). It demonstrated improved performance in tasks such as clinical text classification and medical concept extraction, enhancing the ability to process real-world patient data. For example, ClinicalBERT improved hospital readmission predictions (Alsentzer et al., 2019).
PubMedBERT went all-in on medical literature, training from scratch on PubMed abstracts and PMC articles instead of adapting a general model (Gu et al., 2021). This paid off with strong results, like 87.4% accuracy on Medical Natural Language Inference (MedNLI) (a medical reasoning task) and a 91.1% F1-score for linking chemicals and proteins in ChemProt (Gu et al., 2021). PubMedBERT showed that medical terms and writing styles work best with models built just for them.
BioBERT, ClinicalBERT, and PubMedBERT demonstrated the importance of tailoring models to medical data, providing a strong foundation for instruction-tuned Med-LLMs. These early models are optimized for specific tasks, such as named entity recognition and text classification, making them highly effective for precise applications in clinical settings. By contrast, instruction-tuned models, as an example, Med-PaLM and Me-LLaMA, are working on complex tasks, including responding to detailed medical queries and executing multi-step instructions, thereby supporting advanced clinical reasoning (Singhal et al., 2023; Xie et al., 2025). While foundational models remain highly effective at specific tasks, such as named entity recognition or text classification, instruction-tuned models have expanded these capabilities and provide more flexibility. They enable more advanced applications that require reasoning. These new models do not replace the earlier ones; instead, they complement them.
Medical instruction fine-tuning models
Instruction-tuning has emerged as a transformative approach in the development of LLMs, especially within specialized domains like healthcare. Fine-tuning the LLM models with carefully curated instruction datasets enables this technique to perform a wide range of domain-specific tasks with higher precision and better alignment with human intent. In the healthcare domain, such instruction-tuned models have demonstrated significant advancements to support clinical decisions, summarize notes, and assist diagnoses. This section reviews several notable medical instruction-tuned models with focusing on their features, limitations, and distinguishing contributions to the domain.
The Med-PaLM model
The Med-PaLM (Singhal et al., 2023) is a medical model that builds on top of the PaLM model. It is designed to excel in medical QA tasks because researchers trained it using real medical exam questions, such as MultiMedQA and some other medical datasets. The researchers combine several approaches to boost the model’s responses, including instruction-tuning, few-shot prompting, and self-consistency. Additionally, they use a chain-of-thought (CoT) approach for reasoning to ask the model to think step by step before generating the answer. The Med-PaLM shows a remarkable improvement in handling medical questions. It achieves 17% improvement when tested by existing QA benchmarks, including the MedQA (United States Medical Licensing Examination (USMLE)) medical exam dataset, PubMedGPT, and BioGPT. The instructions play a valuable role in sharpening the model’s ability to understand the provided questions. It guarantees consistent, relevant, and accurate answers, making it an excellent model for medical QA tasks.
The Aloe model
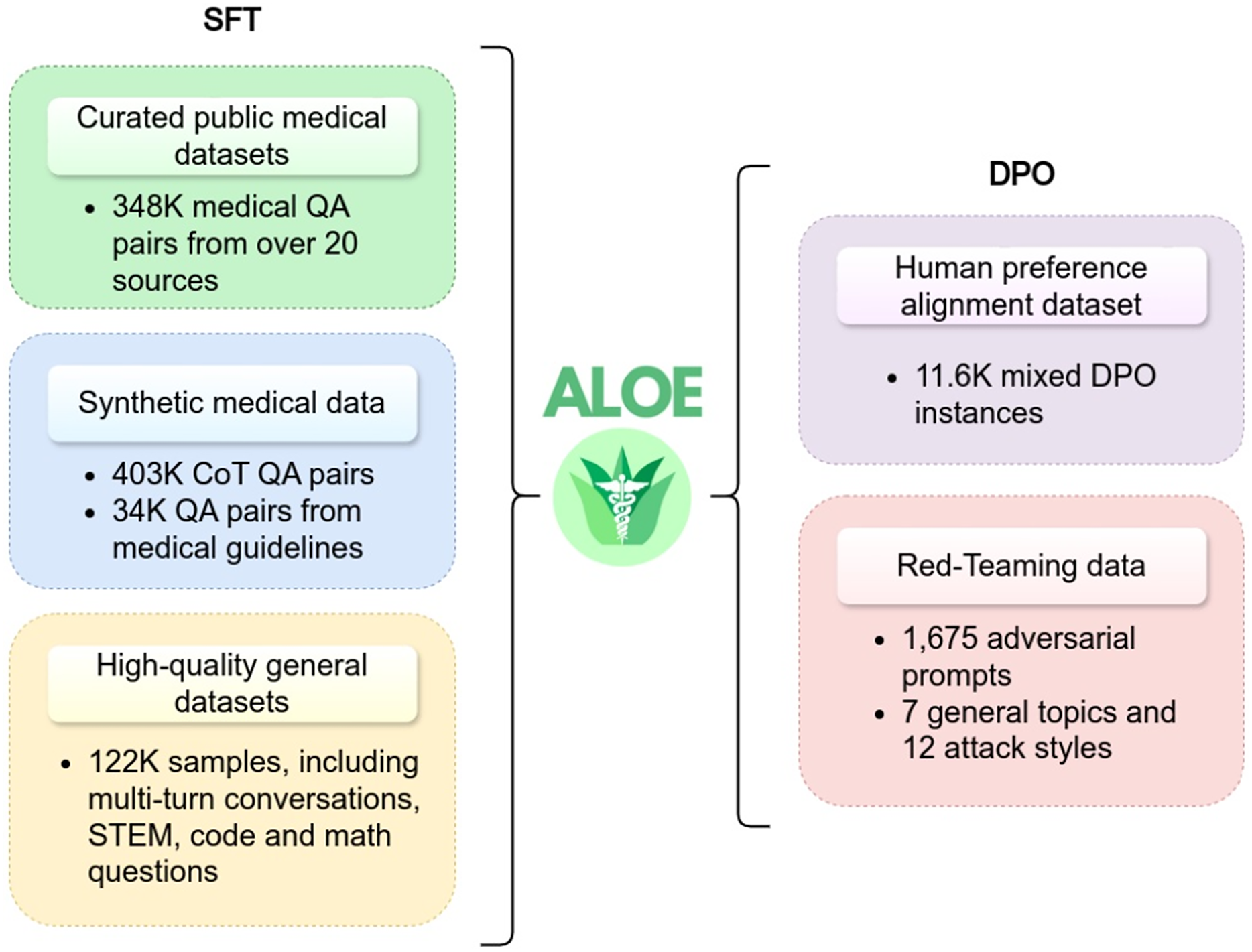
The Aloe model family (Gururajan et al., 2024) has introduced two open-source instruction fine-tuned models: LLaMA3-Aloe-8B-Alpha and Mistral-Aloe-7B. These models are developed by fine-tuning LLaMA and Mistral using a combination of specialized healthcare datasets and general instruction datasets. The healthcare datasets used for this purpose include MedQA, MedMCQA, PubMedQA, BioASQ, and MedQuAD. This blend ensures that the models are optimized for both medical and general-domain tasks. The Aloe models employ three key techniques during the fine-tuning process: instruction tuning, synthetic data generation, and CoT prompting. These techniques altogether upgrade the capabilities of the model in medical tasks, such as question answering, where accuracy and contextual understanding are important. Additionally, the Aloe model adopts supervised fine-tuning to better align with domain-specific requirements. In model evaluation, LLaMA3-Aloe-8B-Alpha demonstrated a 7% performance improvement over Meditron-70B (Chen et al., 2023b), which is a specialized open-source healthcare model. This underscores the effectiveness of instruction tuning in enhancing model performance compared to models that are exclusively trained on specialized healthcare data. Figure 7 provides an illustration of the instructional fine-tuning process, which is implemented during the training phase of the Aloe model.
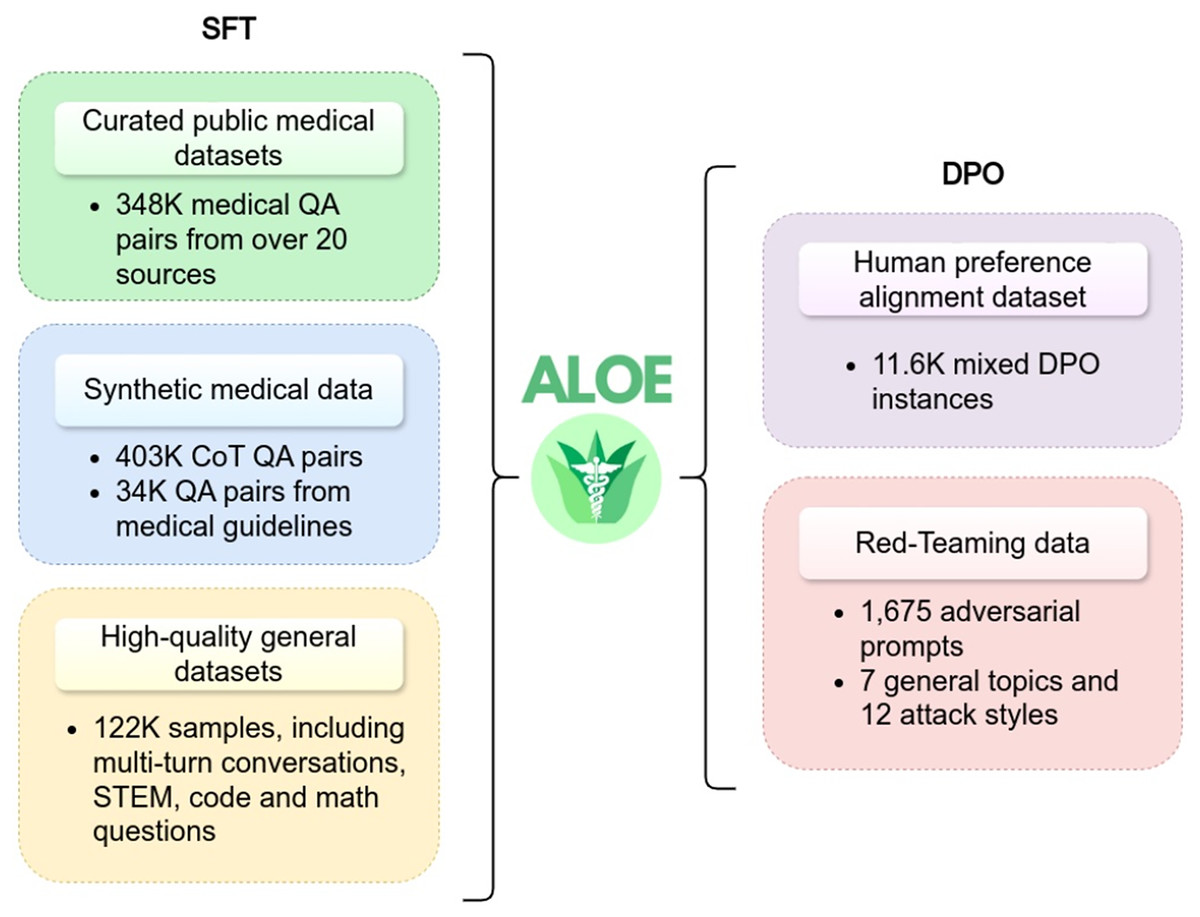
Figure 7: Instructional fine-tuning process of Aloe model, demonstrating the integration of supervised fine-tuning and direct preference optimization (Gururajan et al., 2024).
{kind=link}
BioInstruct model
The BioInstruct model (Tran et al., 2023) is an instruction-tuned Med-LLM based on the BioInstruct dataset, a specialized instruction dataset in the biomedical domain. The dataset is generated using GPT-4 (OpenAI et al., 2023) to provide diverse task-specific instructions. The model utilizes LLaMA-7B and LLaMA-13B as the backbone for training (Touvron et al., 2023) and uses Low-Rank Adaptation (LoRA) (Hu et al., 2021) for parameter-efficient fine-tuning, which allows for effective adaptation without extensive computational overhead. The BioInstruct model is designed for tasks such as QA, information retrieval, and free-text generation. Instruction tuning significantly improves the task’s performance by gaining higher accuracies of 84.29% in QA tasks and 75.63% in extractive tasks compared to non-instruction-tuned models (Tran et al., 2023). Likewise, the free-text generation task is evaluated by GPT-4 in terms of faithfulness, completeness, correctness, and coherence. The model achieves substantial performance gains across generative tasks, as demonstrated by benchmarks like Conv2note and Doctor-Patient QA, thereby proving its effectiveness in generating documentation (Tran et al., 2023). The integration of instruction tuning and parameter-efficient techniques like LoRA highlights the effective approach followed by the BioInstruct model (Tran et al., 2023).
LLaMACare model
The LLaMACare model (Li, Wang & Yu, 2024) ran instruction tuning on LLaMA-2 (Touvron et al., 2023), which comes in two variants: LLaMACare-7B-Clinical and LLaMACare-13B-Clinical. Those models utilize the MIMIC-III medical dataset (Johnson et al., 2016). Generating discharge instructions based on discharge notes and classification tasks is the main core task of this model. The dataset is formatted by hiring experts to annotate the dataset at first, and then a GPT-4 (OpenAI et al., 2023) is utilized to self-construct the dataset. Later, this dataset was fed to LLaMA-2 with clear instructions to use step-by-step reasoning before outputting solutions (Li, Wang & Yu, 2024). LLaMACare studies the effectiveness gained from instructions through ablation experiments comparing instructed vs non-instructed models. These experiments clearly demonstrate the role of instructions in the tuning process. After being trained with specific instructions, LLaMACare is able to generate outputs that align with and meet the needs of healthcare professionals (Li, Wang & Yu, 2024).
Med42 model
The Med42 model (Christophe et al., 2024) is another LLaMA-2 (Touvron et al., 2023) instructed model. Although Med42, captures many NLP tasks, but it gives more attention to QA tasks. It intentionally adopts specialized medical datasets, such as MedQA, HeadQA, and USMLE. These datasets enable the model to excel in QA of all types. The model evaluation demonstrates its effectiveness in handling simple to complex clinical questions by providing an accuracy of 72% on USMLE dataset as an example. The research studies the performance of full-parameter tuning and Parameter-Efficient Fine-Tuning (PEFT) when trained with the instructed dataset (Christophe et al., 2024). Furthermore, the findings of this research demonstrate that Parameter-Efficient Fine-Tuning achieves comparable performance to full-parameter tuning in several scenarios. It proves that instruction fine-tuning can effectively improve task-specific performance while using fewer computational resources (Christophe et al., 2024).
AlpaCare model
The AlpaCare (Zhang et al., 2023c) is an instructed fine-tuned model that uses MedInstruct-52k, an instructed dataset, and is based on LLaMA (Touvron et al., 2023). Experts create 167 instructions designed to handle a wide range of NLP tasks. After that, GPT-4 (OpenAI et al., 2023) and ChatGPT (Brown et al., 2020) augment seed instructions to generate more instructions. The final dataset was validated several times with real-world clinical use tasks. AlpaCare is designed for tasks such as medical text generation, information extraction, and inquiry response (e.g., QA). The evaluation of the model performance in QA tasks only achieves an average score of 40.6% on several benchmark datasets (Zhang et al., 2023c). Additionally, the research examines how the model performs compared to others using a similar approach when tested with free-form instructions. AlpaCare records an improvement of 38.1% over other models. These results illustrate the importance of prioritizing the quality and the diversity of the created instructed dataset, which would directly affect the model’s robustness (Zhang et al., 2023c).
MedAlpaca model
The MedAlpaca model (Han et al., 2023) is an open-source model designed for medical applications. It is trained on a big Medical Meadow dataset that consists of over 160,000 entries curated from diverse sources such as medical flashcards, Stack Exchange, and WikiDoc. The dataset is reformatted into an instruction-following structure to fine-tune LLaMA (Touvron et al., 2023), which enables them to adopt the medical domain and medical tasks. Their approach is to design a model that has the ability to perform well in two tasks: generating educational scenarios for training purposes and answering medical questions. The model’s performance proves its ability to pass medical exams, which demonstrates its understanding of any given question. It is worth noting that some medical questions are in the form of free-text scenarios about patients. The research’s main goal is to assist medical students. The results highlight its potential as a reliable tool for medical education.
Me-LLaMA model
The Me-LLaMA model (Xie et al., 2025) is a med-LLM constructed using instruction tuning, continual pre-training, and few-shot prompting. In the first phase, the model is pre-trained on 129 billion tokens from medical datasets such as MIMIC-III (Johnson et al., 2016), MIMIC-IV (Johnson et al., 2023), Medical Information Mart for Intensive Care-Chest X-Ray (MIMIC-CXR) (Johnson et al., 2019), PubMed Central, and PubMed Abstracts. In order to prevent catastrophic forgetting, the model has used RedPajama to balance general and domain-specific knowledge. In the second phase, the model is further fine-tuned using 214,595 examples from datasets like HealthCareMagic, Icliniq, MedInstruct, MedIQA, and MedicationQA. These datasets enhance task generalization for medical tasks such as summarization, classification, and question-answering. Me-LLaMA is available in full-parameter (13B and 70B) and parameter-efficient LoRA-based versions (13B-chat and 70B-chat) (Hu et al., 2021; Xie et al., 2025). These variants are designed to optimize performance while reducing computational requirements. Figure 8 illustrates the development stages of the model: continual pre-training, instruction fine-tuning, task-specific fine-tuning, and evaluation. This research presents comprehensive findings demonstrating the effectiveness of their methodology, which combines continual pre-training and instruction fine-tuning. The results reveal that the integrated approach yields better results than the one with only single components, demonstrating the contribution of each component (Xie et al., 2025).
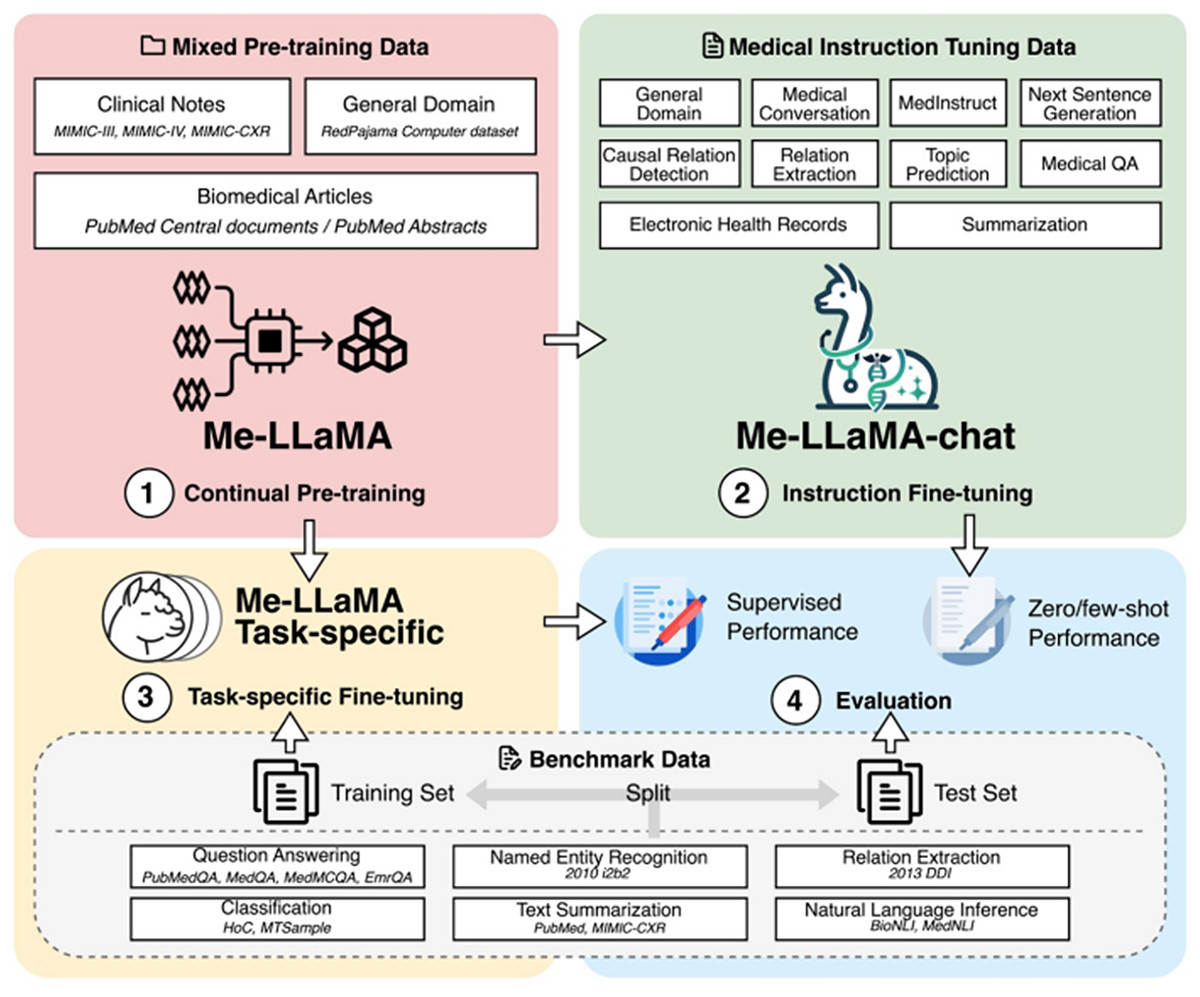
Figure 8: Demonstration of continued pre-training of LLaMA2 models in combination of pre-training instructional datasets (Xie et al., 2025).
{kind=link}
ChatDoctor model
The ChatDoctor model (Li et al., 2023) is a Med-LLM based on a LLaMA-7B based (Touvron et al., 2023), which is tailored to medical dialogue. It leverages the HealthCareMagic-100k dataset (Li et al., 2023), which contains 100,000 patient-doctor conversations. This conversation format prompts the model to follow the dialogue’s flow as instructions do. The main task is to create a chatbot with reliable information. This research’s primary contribution is to study how the model performs when connected to an external offline database to ensure the accuracy and relevance of all responses. This knowledge repository includes up-to-date medical information from various sources, such as the MedlinePlus database, which covers diseases, symptoms, medications, and other medical information. The model demonstrates strong performance in handling questions and inferring correct responses, whether the questions are about symptoms, treatments, or other medical topics. In conclusion, the research illustrates how the model may respond when connected to a valid external database (Li et al., 2023).
Radiology-LLaMA2 model
The Radiology-LLaMA2 (Liu et al., 2023) is an instruction fine-tuned model designed explicitly for radiology reporting tasks. It is based on LLaMA-2 (Touvron et al., 2023) and is fine-tuned using an instruction dataset derived from MIMIC-CXR (Johnson et al., 2019). The MIMIC-CXR dataset (Johnson et al., 2019) focuses on radiology reports. To prepare the dataset for training, each instance of radiology reports aligns with its corresponding interpretations to build an instructional dataset. The primary task in this research is to generate an interpretation (output) from the given radiology report (input) using specific instructions. Experts are brought in to evaluate the model based on three key criteria: how concise, coherent, and relevant its outputs are to the input reports. In addition, the model is tested on the MIMIC-CXR (Johnson et al., 2019) and OpenI datasets, where it achieves ROUGE-L scores of 0.4427 and 0.4087, respectively, when using ChatGPT-4.
Overall, this study demonstrates the potential effectiveness of building a model that interprets radiology reports and highlights promising directions for future research.
Radiology-GPT model
The Radiology-GPT model (Liu et al., 2024b) is an instruction fine-tuned designed for radiology report generation. Unlike the Radiology-LLaMA2 model, it is based on the Alpaca-7B (Taori et al., 2023a) and employs LoRA (Hu et al., 2021) for parameter-efficient fine-tuning. Its instruction dataset is derived from MIMIC-CXR (Johnson et al., 2019) aligning findings and impressions with corresponding output instructions of radiology-specific tasks. Expert radiologists ‘evaluation of the model was based on understandability, conciseness, relevance, and clinical utility. The model demonstrates performance comparable to ChatGPT-4’ surpasses LLaMA-7B (Touvron et al., 2023) and Dolly-12B (Databricks, 2023) and establishes its effectiveness in radiology tasks. These results highlight the potential of Radiology-GPT as a domain-specific alternative to general-purpose LLMs and generate accurate and clinically useful radiology reports.
SciFive model
The SciFive model (Phan et al., 2021) is a text-to-text transformer based on the T5 architecture (Raffel et al., 2020). This model is fine-tuned through an instructed dataset derived from NCBI Disease, BC5CDR, CHEMPROT, MedNLI, and BioASQ. These datasets are designed to support various NLP tasks, including question-answering, named entity recognition (NER), information extraction, and inference. These variations enable SciFive to perform effectively in multiple biomedical tasks.
MentaLLaMA model
The MentaLLaMA model (Yang et al., 2024) is an LLM model based on LLAMA-2 designed to predict a mental health condition from given non-formal or non-academic text. It is fine-tuned using the IMHI dataset, comprising 105,000 instances from 10 social platforms. This dataset supports eight mental health conditions and is designed to predict binary classification to detect depression or stress, as well as multi-class classification of other mental health conditions. The dataset also generates human-understandable reasoning behind classification decisions. MentaLLaMA is available in two versions: MentaLLaMA-chat-7B and MentaLLaMA-chat-13B. The model demonstrates superior performance compared to ChatGPT and other baseline models and excels in correctness, consistency, and explanation generation. These features make MentaLLaMA a valuable tool for mental health assessment.
Models for low-resource healthcare settings
Some Med-LLM initiatives are now explicitly designed to address low-resource healthcare settings. Some recent efforts show exciting steps forward in training these models to handle some challenges, such as limited computational infrastructure, linguistic diversity, and scarcity of large-scale medical datasets. In the following subsection, we present a selected low-resource medical models that adopt instruction tuning as a core method.
The L2M3 model (Gulati et al., 2024) represents recent efforts to adapt instruction-tuned large language models for low-resource healthcare environments. It specifically targets community health workers (CHWs) in low- and middle-income countries (LMICs), addressing healthcare workforce shortages in underserved regions. The model is a great example of how Med-LLMs can make a difference in poorer countries, where language gaps and a scarcity of healthcare providers (Ahmed et al., 2022; WHO, 2016).
L2M3 employs a novel combination of instruction-tuned language model and machine translation. One of its goals is to enable multilingual medical interactions across languages such as English, Hindi, Telugu, Arabic, and Swahili. It is trained on a large-scale, open-source medical dataset with nearly a billion words from doctor-patient chats and health guides. It is a deliberately open-source architecture with cost-effective deployment on limited hardware resources to fit poor countries’ needs. It demonstrates how instruction tuning can help create an affordable, accessible, and culturally appropriate medical tool. It supports healthcare scalability in a resource-constrained environment, contributing to the global goal of improving health equity (Gulati et al., 2024).
Summary of reviewed models
For question-and-answer tasks, models such as Med-PaLM (Singhal et al., 2023), BioInstruct (Tran et al., 2023), Aloe (Gururajan et al., 2024), Me-LLaMA (Xie et al., 2025), AlpaCare (Zhang et al., 2023c), and Med42 (Christophe et al., 2024) rely on high-quality datasets such as MedQA, PubMedQA, and MedMCQA. These models employ specialized instructed fine-tuning techniques to enhance comprehension of the given questions and deliver accurate responses which showcasing exceptional performance in the medical QA. Each reviewed model deploys unique methodologies alongside specialized instructions. For example, Med-PaLM (Singhal et al., 2023) excels in the medical QA task by using big QA datasets and advanced self-consistency techniques. AlpaCare (Zhang et al., 2023c) proves notable performance on free-text questions through instruction-tuning with a highly crafted instruction dataset, MedInstruct-52k. Me-LLaMA (Xie et al., 2025), on the other hand, integrates both instruction-tuning and continual pre-training, which boosts and enhances its performance. Other models use instructed fine-tuning as a core method, such as Radiology-GPT and Radiology-LLaMA2, which address the same problem of generating reports, while MentaLLaMA focuses on mental health domains. Table 3 provides a comparative overview of the models by highlighting their base architectures, their dataset sources, target tasks, and fine-tuning techniques. These models exemplify the versatility and effectiveness of instructional fine-tuning in the advancement of domain-specific LLMs. Despite their achievements, further refinement of fine-tuning strategies is essential to unlock their full potential. The next section explores advanced optimization techniques to enhance model performance and adaptability.
| Domain | Model name | Base model | Parameters | Training dataset | Tasks | Tuning strategy | Prompt engineering | Evaluation datasets | Performance metrics |
|---|---|---|---|---|---|---|---|---|---|
| General medical practice | |||||||||
| General medical practice | MED-PaLM (Singhal et al., 2023) | PaLM | 540B | MultiMedQA, general large-scale datasets | QA models | Instruction tuning (Flan) | Few-shot, CoT, self-consistency, instruction prompt tuning | MultiMedQA benchmark (MedQA, MedMCQA, PubMedQA, MMLU, LiveQA, MedicationQA, HealthSearchQA) | Accuracy (67.6% MedQA); human evaluation (LiveQA, MedicationQA, HealthSearchQA) |
| General medical practice | Aloe model (Gururajan et al., 2024) | LLaMA-3 Mistral | – | Medical, general dataset, synthetic data generation, ethical alignment | QA models | Not reported | SC-CoT, MedPrompt | MedMCQA, MedQA (USMLE), PubMedQA, MMLU (Medical), CareQA, OpenMedQA | Accuracy (MedMCQA: 69.14%, MedQA: 64.47%, PubMedQA: 71.01%, MMLU: 80.20%, CareQA: 79.92%); Human evaluation (OpenMedQA) |
| General medical practice | Me-LLaMA (Xie et al., 2025) | LLaMA 2 | 13B/70B | Instruction tuning, continual pre-training dataset | QA, multi-task | Instruction tuning (implied) | Zero-shot and few-shot prompts | MedQA, MedMCQA, PubMedQA, EmrQA, 2010 i2b2, 2013 DDI, HoC, MTSample, BioNLI, MedNLI, PubMed, MIMIC-CXR, NEJM CPCs | Accuracy (MedQA: 62.3%, MedMCQA: 64.3%, PubMedQA: 81.4%, EmrQA: 91.7%); Macro-F1 (i2b2: 86.9%, DDI: 80.3%, HoC: 89.1%, MTSample: 93.5%, BioNLI: 87.4%, MedNLI: 87.3%); ROUGE-L (PubMed: 46.5, MIMIC-CXR: 34.2), BERTScore (PubMed: 0.896, MIMIC-CXR: 0.877); Top-1 Accuracy (NEJM CPCs: 74.3%) |
| General medical practice | AlpaCare (Zhang et al., 2023c) | LLaMA-1/2 | 13B | MedInstruct-52k, ICliniq | QA models | Instruction tuning (Templates + Filtering) | Automatically generated templates, Rouge-L filtering | MedQA, HeadQA, PubMedQA, MedMCQA, MeQSum, AlpacaFarm, MMLU, BBH, TruthfulQA | Accuracy (MedQA: 35.5%, HeadQA: 30.4%, PubMedQA: 74.8%, MedMCQA: 33.5%), ROUGE-L (MeQSum: 29.0%), human evaluation |
| General medical practice | Med42 (Christophe et al., 2024) | LLaMA 2 | 7B/70B | Medical QA dataset, general domain | QA models | Full and parameter-efficient tuning | Structured templates, few-shot prompting | USMLE, MedQA, PubMedQA, MedMCQA, HeadQA, Anatomy, Professional medicine | Accuracy (USMLE: 72.0%, MedQA: 61.5%, PubMedQA: 76.8%, MedMCQA: 60.9%) |
| General medical practice | MedAlpaca (Han et al., 2023) | Alpaca | 7B/13B | Medical flashcards, forums, WikiDoc, CORD-19, MedQA, PubMed, MIMIC-III/IV | Clinical text generation | Not reported | Not reported | USMLE Step 1, Step 2, Step 3 self-assessment datasets | Accuracy (Step 1: 47.3%, Step 2: 47.7%, Step 3: 60.2%) |
| Specialized domains | |||||||||
| Specialized domains | MentaLLaMA (Yang et al., 2024) | LLaMA | 7B/13B | Mental health | Binary mental health detection, Multi-class detection | Instruction tuning (Few-shot, template-based) | Few-shot, instruction, template-based | IMHI benchmark (DR, Dreaddit, CLP, SWMH, T-SID, SAD, CAMS, IRF, MultiWD) | Prediction correctness (state-of-the-art on 7/10 test sets); explanation quality (comparable to ChatGPT); generalizability (outperforms ChatGPT on unseen tasks) |
| Specialized domains | LLaMACare (Li, Wang & Yu, 2024) | LLaMA 2 chat | 7B | MIMIC-III, auto-generated instructions | Clinical text generation | Instruction tuning (Self-instruct) | Few-shot, multi-template prompting | Discharge summaries, clinical outcome prediction datasets | ROUGE-L (27.2), BLEU-4 (18.8); AUROC improvements of 2–5 points |
| Specialized domains | Radiology-LLaMA2 (Liu et al., 2023) | LLaMA 2 | 7B | MIMIC-CXR, OpenI | Radiology reporting | Instruction tuning | Zero/Few-shot learning | MIMIC-CXR, OpenI | ROUGE-1 (MIMIC-CXR: 0.4834, OpenI: 0.4185) |
| Specialized domains | Radiology-GPT (Liu et al., 2024b) | Alpaca-7B | 7B | MIMIC-CXR | Radiology reporting | Instruction tuning | Not reported | MIMIC-CXR, OpenI | Human evaluation (Understandability, Coherence, Relevance, Conciseness, Clinical utility) |
| Biomedical research | |||||||||
| Biomedical research | BioInstruct (Tran et al., 2023) | LLaMA 1/2 | 7B/13B | BioInstruct, BioNLP datasets, Conv2note, ICliniq | QA models | Instruction tuning (Self-instruct) | Few-shot prompting | BioASQ, PubMedQA, NER datasets, RE datasets, Summarization datasets | Accuracy (QA: +17.3%), F1-score (IE: +5.7%), GPT-4 evaluation score (GEN: +96%) |
| Biomedical research | SciFive (Phan et al., 2021) | T5 | 220–770M | C4, PubMed, PMC, NCBI Disease, BC5CDR, CHEMPROT, MedNLI, BioASQ | NER, relationship extraction, biomedical QA | Not reported | Not reported | NCBI disease, BC5CDR, BC4CHEMD, BC2GM, JNLPBA, Species-800, ChemProt, DDI, MedNLI, HoC | F1-score (NCBI disease: 89.39%, BC5CDR chemical: 94.76%, ChemProt: 88.95%, DDI: 83.67%); accuracy (MedNLI: 86.57%); F1 (HoC: 86.08%) |
| Patient communication | |||||||||
| Patient communication | ChatDoctor (Li et al., 2023) | LLaMA | 7B | HealthCareMagic-100k, patient-doctor conversations | Dialogue-based models | LoRA | Reasoning prompts | iCliniq real-world patient-doctor conversations | Accuracy (91.25%), BERTScore (improved precision, recall, F1) |
Taxonomy framework for medical instruction tuning
This literature review establishes a taxonomy for categorizing instruction-tuned medical LLMs by application domains. The taxonomy organizes models into four primary categories based on their clinical use cases. General Medical Practice models handle broad medical knowledge and multi-specialty applications. Specialized models combine specific medical fields like mental health and radiology. Biomedical Research models focus on medical literature. Patient Communication models enable direct patient interaction. Table 3 presents this categorical organization with comprehensive technical details, including data used, tuning techniques, prompt methods, and performance metrics. This table makes it easy to compare models.
Limitations in evaluation methodologies and reproducibility challenges
Medical large language models (Med-LLMs) have made exciting strides, but when we look closely at how they are tested, we see serious gaps. These gaps make it hard to trust, compare, or apply the results in real-world healthcare. Below, we break down the main issues and suggest ways to improve.
Inconsistent testing methods
Testing Med-LLMs is all over the place. For example, Med-PaLM scored 67.6% on the MedQA benchmark using a few example prompts with step-by-step reasoning and a method to double-check its answers (Singhal et al., 2023). Meanwhile, Me-LLaMA got 62.3% on the same test but used a mix of approaches without that double-checking (Xie et al., 2025). Other models vary too: AlpaCare uses auto-generated templates (Zhang et al., 2023c), while ChatDoctor relies on reasoning prompts (Li et al., 2023). These differences make it tough to know if one model is truly better or if the test setup is skewing results.
Another problem is how test data is handled. Some models, like AlpaCare with its MedInstruct-52k dataset (Zhang et al., 2023c) or BioInstruct (Tran et al., 2023), do not clearly prove that their test questions were not seen during training. Models like Me-LLaMA, which continue training on medical texts (Xie et al., 2025), might accidentally include test data in their training, raising the risk of overfitting to benchmark questions.
Limited benchmarks and overfitting risks
Most studies keep testing Med-LLMs on the same three benchmarks: MedQA, MedMCQA, and PubMedQA. Table 3 shows nearly every model reports scores on these datasets. But this narrow focus is a problem. These tests, especially MedQA, rely on multiple-choice questions, which do not fully test the deep reasoning doctors need in real-world clinics.
MedQA shows up in almost every study, yet it has clear flaws. GatorTron researchers noted it only has about 12,000 questions and does not always match current medical practice. MetaMedLLM warns that models are being tweaked just to ace MedQA, not to develop true medical thinking (Zhang et al., 2024). Some studies, like Med-PaLM (Singhal et al., 2023) and Med42 (Christophe et al., 2024), admit that multiple-choice tests fall short of real clinical challenges. But many others—Aloe (Gururajan et al., 2024), Me-LLaMA (Xie et al., 2025), BioInstruct (Tran et al., 2023), and ChatDoctor (Li et al., 2023)—share high MedQA scores without mentioning these limitations or the risk of overfitting, where models get good at these tests but struggle elsewhere.
We need broader, more realistic tests that reflect actual medical work to ensure models are useful in hospitals, not just good at passing a few exams.
Reproducibility challenges
It is not easy to recreate the results of many studies because they often skip writing important details. For example, articles might not explain how they crafted their prompts, which examples they used, or how they adjusted model settings such as decoding temperature. For instance, BioInstruct claims a “17.3% improvement” in answering questions (Tran et al., 2023), but details about the prompt structure are missing. Another example: MentaLLaMA claims to outperform other models on “7 out of 10” test sets (Yang et al., 2024), yet provides only a high-level description of its prompt design, without full details on example selection. Without this level of detail, it is difficult for other researchers to verify results or reproduce the work.
Strategies optimizing instruction fine-tuning
Optimizing instruction fine-tuning for Med-LLMs requires a multifaceted approach. Research is being focused on exploring strategies to enhance model performance by balancing data volume with instruction quality, implementing phased training and mixed prompting to improve adaptability, prioritizing strong base models while mitigating the risks of imitation, and addressing bias to ensure reliable outputs. This section delves into established and emerging techniques that contribute to more robust and efficient Med-LLM development.
Long is more for alignment
Achieving high performance in instruction-tuned models has traditionally relied on meticulously curated datasets (Zhao et al., 2024). However, Zhao et al. (2024) introduced a hypothesis that challenges this notion, suggesting that fine-tuning models using only long, detailed instructions from existing datasets can yield results comparable to state-of-the-art methods like Less Is More for Alignment (LIMA) (Zhou et al., 2023) and AlpaGasus (Chen et al., 2023a). The Alpaca-1k-longest model (Zhao et al., 2024) has been fine-tuned using a dataset composed of 1,000 instruction-response pairs, carefully chosen based on their length. These entries, sourced from the Alpaca-52k (Taori et al., 2023b) and Evol-Instruct-70k (Zeng et al., 2024) datasets, represent the longest and most detailed examples. Despite the significant reduction in dataset size, this approach proves that a smaller set of highly informative examples can offer a more efficient and cost-effective solution without sacrificing model quality (Zhao et al., 2024).
Less is more for alignment
Many current approaches rely on large-scale datasets to fine-tune models for specific tasks (Bommasani et al., 2021). Nevertheless, Zhou et al. (2023) state that small datasets with high-quality data can be as effective, overcoming the challenge of relying on large-scale datasets for instructional fine-tuning. Researchers prove the claim by fine-tuning the LIMA model with a small dataset of only 1,000 instances, which is carefully curated instruction-response pairs. These instances were sourced from multiple platforms such as Stack Exchange, WikiHow, and Reddit. The primary contribution is to maintain an exceptional quality of the dataset. This experiment shows that strong performance can be achieved through a high-quality dataset without the need for extensive data collection efforts (Zhou et al., 2023).
Enhancing base models instead of imitation
A proprietary model consistently surpasses open-source models, showing the ongoing performance gap between the two (Zhou et al., 2023; Zhao et al., 2024). To bridge this gap, imitating a proprietary model by fine-tuning open-source with several outputs of a more advanced proprietary model enables the weaker model to “learn” from the stronger one (Gudibande et al., 2023). Gudibande et al. (2023) argues that imitation models are effective at replicating the superficial style and fluency of proprietary models, but they fail to resolve advanced challenges. Such that, those models may fail to provide robust solutions for complex problems. This article (Gudibande et al., 2023) stresses the importance of starting with a strong base model, emphasizing the need to focus on the foundational quality rather than relying on imitation.
How far can camels go?
Instructional datasets improve the performance of any given models, whether open-source or proprietary (Wang et al., 2023a). However, this raises a research question: whether using a single dataset or a combination of datasets would deliver optimal performance across several NLP tasks. The researcher (Wang et al., 2023a) demonstrates that models fine-tuned on single specialized domain datasets tend to excel in specific tasks but struggle to generalize. In contrast, combining datasets improves overall performance but fails to achieve top results in any single specific domain. As a result, no individual dataset consistently excels in all tasks.
Scaling instruction-finetuned language models
Many current approaches to LLM development focus on scaling model size or increasing pretraining data to improve performance (Brown et al., 2020). The study by Chung et al. (2022) proves that scaling instruction tuning by increasing the number of tasks and incorporating chain-of-thoughts (CoT) data significantly boosts model performance. Despite these gains, a critical question remains: how much scaling is enough? When the number of tasks increases from a small number (e.g., nine tasks) to a larger set (e.g., 282 tasks), there is a substantial performance gain. This is because the model is exposed to more diverse tasks, allowing it to learn from a wider range of instructions. However, beyond 282 tasks, adding more tasks (up to 1,836 in the study) still improves performance, but the improvement becomes minor. Chung et al. (2022) recommend prioritizing the selection of a diverse and meaningful set of tasks to optimize model performance rather than simply increasing the number of tasks to ensure more effective fine-tuning.
Long-tail tasks
The dataset’s imbalanced task distribution in an instructional dataset is characterized by a predominant representation of short-response tasks, leading to a significant underrepresentation of extended dialogues and complex, long-tail tasks (Longpre et al., 2023; Wang et al., 2022). This skewed distribution limits the model’s capabilities to capture complex tasks. The study by Wang et al. (2022) illustrates the critical importance of incorporating a broader range of task types, including both short and extended responses. This approach facilitates the creation of models capable of managing a broader spectrum of interactions and producing more nuanced outputs, extending beyond simple short answers.
Mixed prompt training
Earlier studies trained models on single prompt settings, either zero-shot or few-shot prompts, but not both (Sanh et al., 2022; Wang et al., 2022). The study (Longpre et al., 2023) investigates the role of mixing different prompt strategies, such as zero-shot, few-shot, and CoT, for a single specific task. The finding proves that a mixture of prompt approaches leads to better model performance. In their study (Longpre et al., 2023), the baseline performance of models trained only with single prompt types (zero-shot or few-shot) was compared against models trained with mixed prompt settings using ablation studies where they systematically removed components of the mixed prompt training setup (e.g., few-shot templates, CoT prompts) to measure their individual contributions. Longpre et al. (2023) recommend adopting mixed prompt training as a core strategy for instruction tuning, as it increases the model’s capability to manage varied prompts.
Sensitive to instruction phrasings
Arroyo et al. (2024) highlight the problem of disparities in the model outputs because of instruction phrasing. LLMs exhibit distinct variations in performance when presented with instructions that are phrased differently but convey the same semantic meaning. In their article, Arroyo et al. (2024) thoroughly evaluated open-source medical models on a range of classification and extraction tasks using prompts specifically crafted by medical professionals. Their article illustrates that minor alterations in wording significantly affect the outputs of medical LLMs. This work examines LLaMA2-7B and Asclepius-7B when prompted with specific phrases. At first, the researchers use the terms ‘white’ or ‘non-white’ and analyze the outputs. The result shows quite different responses based on those terms. This study may reflect potential racial biases in the training data. Likewise, when analyzing gender-based responses, the researchers found concerning differences in accuracy. Experiments reveal that using the term ‘female’ in a given task often leads to less accurate results compared to identical queries using ‘male.’ This disparity suggests underlying issues in how these models process gender-specific information. This article provides a recommendation to address biases and racial discrimination to ensure any model’s reliability across diverse demographic groups (Arroyo et al., 2024). This sensitivity to phrasing shows the potential risks of deploying such models in healthcare systems (Arroyo et al., 2024).
Phased instruction fine-tuning
Phased Instruction Fine-Tuning (Phased IFT) (Pang et al., 2024) addresses limitations in the traditional One-off Instruction Fine-Tuning (Ouyang et al., 2022) by introducing a structured training process aimed at improving large language models’ ability to follow instructions (Pang et al., 2024). The core issue with One-off IFT is that it treats all instructions as equally difficult, leading to inefficient learning, especially with more complex instructions. This lack of a phased approach prevents gradual improvement in the model’s ability to align with user intent. Therefore, phased IFT (Pang et al., 2024) addresses this by assessing instruction difficulty using GPT-4 (Arroyo et al., 2024), then segmenting the dataset into subsets ordered by increasing complexity. Phased IFT (Pang et al., 2024) introduces the Progressive Alignment Hypothesis, which proposes that models require gradual training to align with human intent effectively. Experimental results show that Phased IFT significantly outperforms One-off IFT across multiple benchmarks (Pang et al., 2024). In summary, phased IFT enhances instruction-following performance by implementing a gradual, phase-based training process that handles different task levels (Pang et al., 2024).
Emotional awareness in medical instruction tuning
Emotional awareness is defined as the ability of an intelligent model to detect and interpret emotional vocabularies in human communication to enhance the model’s responses (Picard, 1997). In healthcare contexts, emotional awareness enables Med-LLMs to better align with patient needs, especially in emotionally sensitive interactions such as the mental health domain.
An emotion-aware method can be integrated to enhance mental health counseling sessions. Rasool et al. study a method that highlights the need to optimize Med-LLMs through emotion-aware instruction tuning. It demonstrates how incorporating emotional intelligence can transform basic clinical responses into more empathetic, contextually appropriate patient text generation. This method improves patient communication by recognizing emotional distress signals and generating culturally appropriate responses that respect patients’ diverse backgrounds, beliefs, languages, and values. These capabilities mark a significant step toward more humanistic medical LLMs (Rasool et al., 2024).
Opportunities and limitations
Recent advancements in instruction fine-tuning of LLMs have highlighted a range of strategies that collectively improve the performance of Med-LLMs. One approach underscores the benefits of either using long, detailed instructions or smaller, high-quality datasets to achieve significant performance gains. Another approach emphasizes the importance of building upon robust base models rather than relying on the imitation of proprietary models. In addition, scaling the number of tasks and incorporating mixed prompting strategies have both been shown to substantially enhance the model’s alignment with human intent and improve overall effectiveness. In medical settings, models’ sensitivity to instruction phrases has shown the risk of bias, calling for more rigorous methods to ensure fairness. Finally, Phased Instruction Fine-Tuning approaches introduce a phase and incremental training process that determines varying levels of complexity, which provides better alignment with human intent compared to traditional one-off methods. While these optimization strategies have collectively pushed the performance envelope of Med-LLMs, there are some broader challenges that must be addressed to fully unlock the potential of these models. Researchers should prioritize mitigating bias in output. Patient’s privacy and safety are equally critical to the practical deployment of Med-LLMs. Addressing these challenges will allow this field to move closer to realizing the goal of reliable, equitable, and impactful LLM solutions in healthcare.
Key challenges and future directions
This section outlines a number of key topics that require further study building on the knowledge acquired from our evaluation of instruction tuning for Med-LLMs. These guidelines provide specific recommendations to improve Med-LLMs functionality and ethical basis while also reflecting growing emphasis on safety, interoperability, and equity in healthcare applications. A visual summary of the key challenges, their proposed solutions, and relative priorities is presented in Fig. 9 to provide an overview of the interconnected nature of these issues.
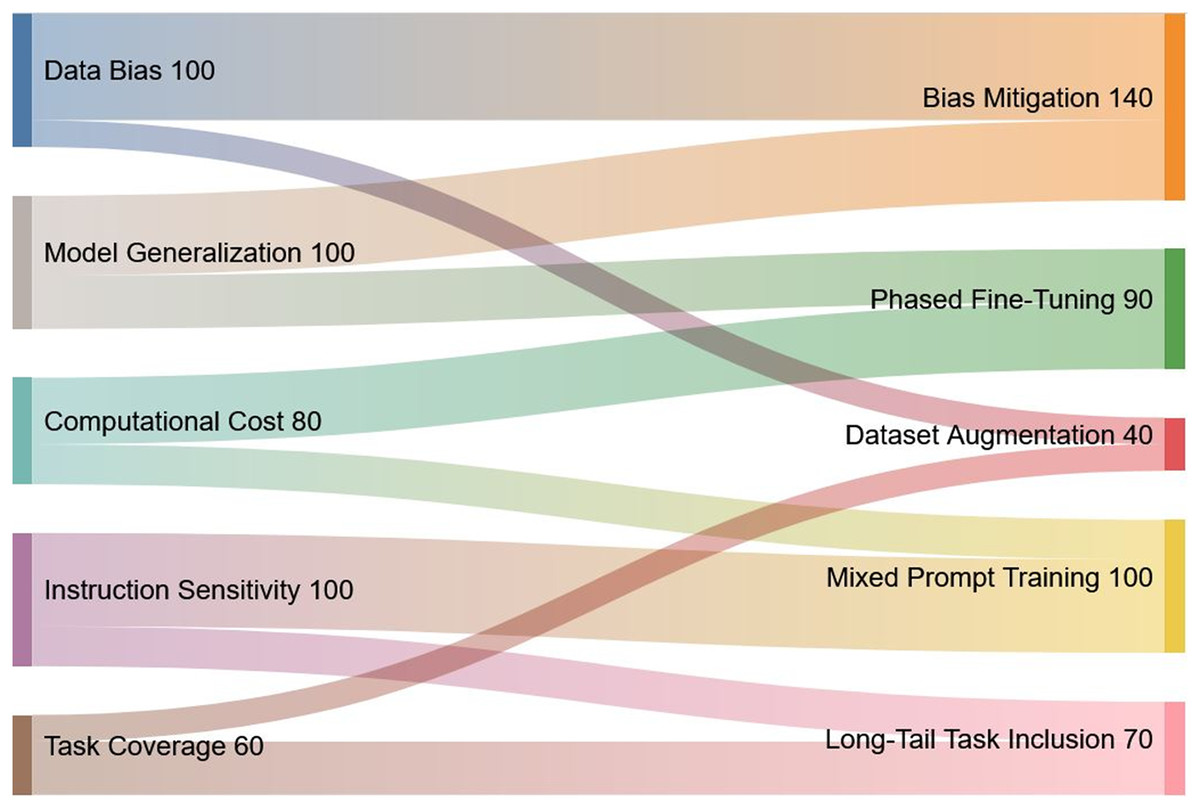
Figure 9: Visual representation of key challenges in Med-LLMs and their proposed solutions.
The Sankey diagram highlights the interconnection between identified challenges (left) and corresponding solutions (right), along with their relative priorities. The width of the flows corresponds to the significance of each challenge and solution.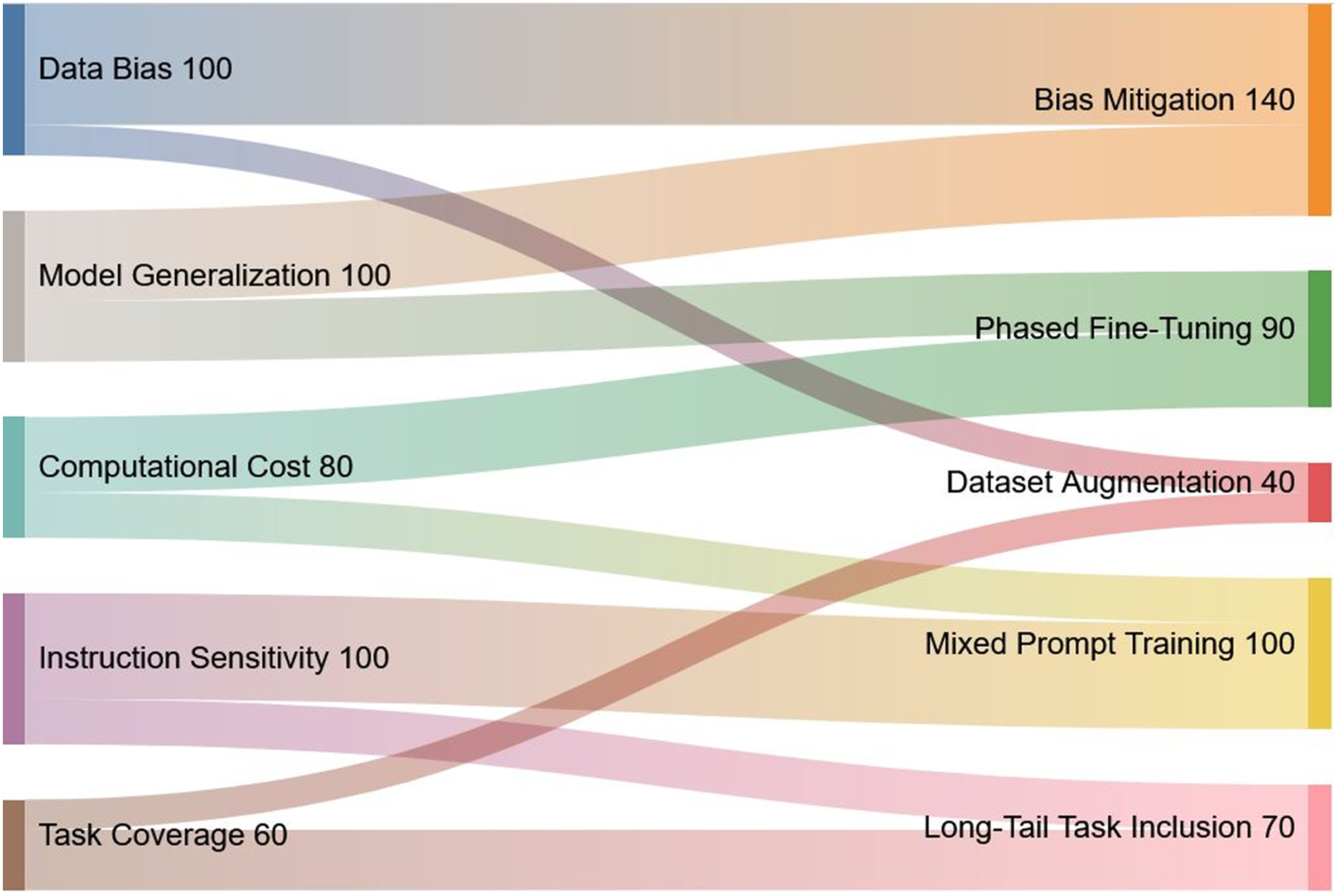{kind=link}
Bias and hallucination mitigation in medical LLMs
Med-LLMs have persistent biases and the generation of hallucinations’ outputs. Those two limitations pose substantial risks in medical contexts and require targeted mitigation strategies to ensure safe and equitable deployment. Med-LLMs may exhibit racial, gender, and demographic biases, which arise from imbalances in datasets and biomedical literature that underrepresent or inaccurately depict certain populations (Poulain, Fayyaz & Beheshti, 2024). For example, studies have shown that medical models may underestimate pain severity in non-white patients or recommend differential treatment based on gender type (Poulain, Fayyaz & Beheshti, 2024; Arroyo et al., 2024). Such biases can hold in healthcare delivery and reduce the trust of the generated output. Studies of eight LLMs found that medical fine-tuning did not reduce bias, with Hispanic women receiving different pain medication recommendations than other groups (Poulain, Fayyaz & Beheshti, 2024). Notably, both general-purpose models (e.g., GPT-4 (OpenAI et al., 2023)) and specialized medical models showed similar bias patterns. These findings demonstrate that neither increasing model size nor instruction tuning on medical data guarantees reduced bias, and may in fact amplify existing demographic biases in clinical recommendations (Poulain, Fayyaz & Beheshti, 2024; Ji et al., 2023).
Med-LLMs generate plausible and convincing output, but not always accurate, which presents another critical challenge. A model such as Med-PaLM has identified instances of fluent but factually incorrect responses, including unsafe medication combinations and outdated treatment plans. These errors, if undetected, could lead to serious safety issues (Singhal et al., 2023; Ji et al., 2023). To tackle bias and false medical facts in Med-LLMs, we can use trusted sources to guide their answers. Incorporating verified medical databases to models, including UMLS, SNOMED CT, or RxNorm, keeps outputs updated with current medical standards (Bodenreider, 2004). Implementing an automated verification method that can compare outputs against reliable references can effectively detect biases and inaccuracies. Similarity-based methods, for instance, can flag deviations from trusted sources, enabling real-time correction (Honovich et al., 2022). Another important approach is to maintain healthcare professionals’ oversight as part of a human-in-the-loop framework, which is essential for ensuring clinical accuracy and relevance. Human validation helps identify subtle biases or hallucinations that automated systems may overlook, especially in complex clinical scenarios (Ji et al., 2023; Mittelstadt, 2019). Equitable evaluation of Med-LLM performance across diverse demographic groups, linguistic contexts, and clinical scenarios is critical to ensure fairness. This includes conducting rigorous testing on underrepresented patient groups to discover potential problems in any model performance (Mehrabi et al., 2021; Mittelstadt, 2019). The successful integration of these strategies relies on close collaboration between computer science researchers and clinical experts to refine Med-LLMs for real-world use. By combining external knowledge grounding, automated verification, human oversight, and equitable testing, the field can move closer to developing Med-LLMs that deliver accurate results.
Instruction complexity, confidence, and alignment challenges in Med-LLMs
Med-LLMs currently face alignment problems, which means the model does not always produce outputs that match what the user needs (Singhal et al., 2023). These models are too sensitive to how questions are written. Small changes in phrases can alter their answers (Arroyo et al., 2024). This inconsistency creates a problem and an untrusted model for clinical use.
Med-LLMs also struggle with tough medical tasks that need careful, step-by-step reasoning. They can answer basic medical scenarios but struggle with multi-step diagnostic processes (Liévin et al., 2022; Nori et al., 2023). Singhal et al. showed that model accuracy drops significantly on solving complex patient cases compared to simple ones (Singhal et al., 2023). Such limitations reduce the practical usage of Med-LLMs in assisting doctors with their decision-making in sophisticated cases.
Another concern is miscalibrated confidence. Med-LLMs often sound highly confident even when their answers are incorrect. Such models can sound certain in their responses, while they are wrong or less certain. Overconfidence is a major problem when doctors need to trust the model responses (Jiang et al., 2021; Xiong et al., 2024; Kadavath et al., 2022). This poses a challenge, where clinicians must be able to recognize when the model is uncertain.
To address these fundamental challenges, researchers have proposed several approaches. Future research should focus on making language models more accurate and reliable. Researchers could develop enhanced methods to improve factual consistency and reduce hallucinations by strengthening output verification against reliable sources and refining training protocols for knowledge claims. Future work should also improve confidence calibration, which is the ability of models to accurately match their expressed confidence with their actual accuracy, and this will be essential for clinical applications where practitioners need reliable uncertainty indicators (Xiong et al., 2024).
Larger models get easily confused by extra information in questions. This means we need better ways to help models justify their confidence. One method, known as linguistic confidence, encourages models to explicitly explain their confidence in words rather than relying solely on raw probability scores (Mielke et al., 2022; Xiong et al., 2024). Another method, consistency-based estimation, measures confidence by evaluating the degree of similarity between responses generated from repeated identical prompts; inconsistent responses indicate the model is likely hallucinating (Manakul, Liusie & Gales, 2023; Lin, Trivedi & Sun, 2023). Integrating multiple methods can also help improve how well models estimate their confidence (Xiong et al., 2024; Shrivastava, Liang & Kumar, 2023).
Artificial intelligence (AI) agents offer a potential strategy to help mitigate some of these problems. Agents are autonomous intermediaries that can interact with users and models, such as between doctors and Med-LLMs (Wilk et al., 2016). They can confirm the model’s responses against medical knowledge bases and help identify potential errors. Agents can also adapt prompt engineering, which is the process of structuring questions to get better responses, based on what doctors need (Liu et al., 2024a).
These approaches represent important steps toward making Med-LLMs more reliable and trustworthy in clinical practice. The focus must be on practical integration and continuous learning from healthcare professionals. Addressing these challenges is critical as healthcare systems increasingly adopt AI technologies for clinical decision support.
Implementing strong guardrails for privacy and safety
Guardrails protect patients and prevent misuse of medical AI systems. These safety measures stop unauthorized access to patient records and ensure Med-LLMs work properly (Dong et al., 2024; Gangavarapu, 2024). Our analysis found privacy problems in several models. ChatDoctor uses actual conversations between patients and doctors (Li et al., 2023). MentaLLaMA trains on mental health posts from social media (Yang et al., 2024). Both approaches create data privacy risks that require stronger protection measures.
To safeguard patient data, it is important to formulate robust protection strategies through layers of anonymization, role-based access controls, and incorporation of effective methods like differential privacy (Ji, Lipton & Elkan, 2023), k-anonymity (Sweeney, 2002), and l-diversity (Machanavajjhala et al., 2007). These methods go beyond standard de-identification seen in datasets like MIMIC-III/IV (Xie et al., 2025) and these steps help lower the chance of someone guessing a patient’s identity (Dyda et al., 2021; Ziller et al., 2021).
Comprehensive guardrails combine regulatory compliance with technical privacy protections. Health Insurance Portability and Accountability Act’s (HIPAA’s) basic requirements for encryption, access controls, audit logging, and authentication (U.S. Congress, 1996; Momentum, 2024) form the regulatory base, which must be enhanced with advanced privacy methods like differential privacy and k-anonymity that provide mathematical privacy protection. Some medical fields need their own protections. For example, mental health models need tighter privacy rules (Momentum, 2024).
Guardrails can automatically spot dangerous queries and alert human supervisors, making AI safer even when we can’t see how it works (Momentum, 2024). These safety steps work together to make Med-LLMs safe, ethical, and legal to use in hospitals.
Broadening healthcare AI access: multilingual models and global deployment
To ensure that Med-LLMs work in real-world hospital settings, we need to measure several metrics such as diagnostic accuracy, patient satisfaction, and how models help doctors in their work (Singhal et al., 2023). We need to engage experts in medicine, AI, ethics, and policy to develop guidelines that keep these models safe and useful. The aim is to create medical models that are safe and meet high ethical standards (Mittelstadt, 2019). Working closely with regulatory bodies ensures adherence to up-to-date medical guidelines and promotes transparency, accountability, and explainability in AI-driven healthcare (Dong et al., 2024).
Equally important for establishing global standards and ethical frameworks is the development of cross-lingual models tailored to communities that do not speak English. Most current Med-LLMs are trained mainly on English data, which makes them less helpful for people who speak other languages, creating significant gaps for non-English speaking populations.
A recent study, “Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries,” shows that models such as GPT-3.5 and MedAlpaca struggle with medical questions in Spanish, Chinese, or Hindi. Their answers are 18% less correct, 29% less steady, and 13% less trustworthy than in English (Jin et al., 2024; Qin et al., 2025). This performance degradation is expected, as current models are not trained on sufficient medical data in non-English languages. To make these models fair and useful worldwide, it is essential to train these models on more linguistically and culturally diverse medical corpora (Qin et al., 2025). A solution to this problem is demonstrated by the Apollo project. This project was developed based on ApolloCorpora, a 2.5-billion-token multilingual medical corpus covering six languages (English, Chinese, Hindi, Spanish, French, and Arabic). It used medical texts from local sources, including doctor-patient dialogues specific to each language and culture. The Apollo model, instruction-tuned on this multilingual corpus, demonstrates that native-language training significantly outperforms translation-based approaches. This approach provides good evidence that instruction tuning with linguistically and culturally grounded native-language data offers a viable path toward effective worldwide healthcare deployment (Wang et al., 2024).
Conclusion
This literature review demonstrated that instruction tuning which encompassed curated datasets held substantial promise for advancing medical language models in real-world clinical tasks. Crafting well-designed instruction datasets was the core of instructional tuning. Several medical models such as Med-PaLM showed the significant effect of adopting such methodology. This research examined several ways to optimize and craft instruction datasets. For example, leveraging ‘long, detailed instructions’ or ‘small yet high-quality datasets.’ Also, one of the ways was to use phased and mixed-prompt approaches to enhance model adaptability and user alignment. Additionally, the research pointed out the importance of selecting the most appropriate words in creating the instructions. Findings in this research demonstrated how instruction tuning has revolutionized the integration of LLM capabilities with healthcare needs. Encouraged the healthcare community to recognize med-LLms as valuable tools that could enhance clinical decision support and patient care delivery.