
Comparative analysis of machine translation for Hindi-Dogri text using rule-based, statistical, and neural approaches
- Published
- Accepted
- Received
- Academic Editor
- Othman Soufan
- Subject Areas
- Algorithms and Analysis of Algorithms, Artificial Intelligence, Natural Language and Speech, Text Mining, Neural Networks
- Keywords
- Machine translation, Hindi-Dogri language pair, Low-resourced languages, Neural machine translation (NMT), Statistical machine translation (SMT), Rule-based machine translation (RBMT)
- Copyright
- © 2025 Kumar et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Comparative analysis of machine translation for Hindi-Dogri text using rule-based, statistical, and neural approaches. PeerJ Computer Science 11:e3218 https://doi.org/10.7717/peerj-cs.3218
Abstract
Machine translation has made significant progress in several Indian languages; however, some, known as computationally low-resourced languages, have seen very little work in this field. The Dogri language, which is listed in the 8th Schedule of the Indian Constitution, is one such language. The authors have developed a machine translation system for the Hindi-Dogri language pair in the fixed news domain using three approaches: rule-based machine translation (developed using linguistic rules), statistical machine translation (built using the Moses toolkit), and neural machine translation (developed using neural networks). A comparison of all three approaches is presented in this article. The article also discusses various research challenges identified in each approach used for machine translation. A corpus of approximately 0.1 million sentences in the news domain was used to train the corpus-based statistical machine translation (SMT) and neural machine translation (NMT) models. The authors also addressed whether NMT produces results equivalent to or better than those of SMT and rule-based machine translation (RBMT). To ensure a comprehensive evaluation, the outputs of all systems were evaluated using two approaches: manual evaluation by language experts and automatic evaluation using standard metrics—Bilingual Evaluation Understudy (BLEU), TER (Translation Edit Rate), METEOR (Metric for Evaluation of Translation with Explicit Ordering), and WER (Word Error Rate). Although RBMT achieved the highest overall scores in both automatic and manual evaluations, expert analysis revealed that translations produced by NMT and SMT exhibited less ambiguity. The study concludes that the performance of SMT and NMT systems are likely to improve further with the availability of larger bilingual parallel corpora.
Introduction
The technological advancements have enabled digitization in every sphere of life, yet there remains a digital divide due to the language barrier. Every person, regardless of gender, age, or geographical domain, needs access to various kinds of information and applications available for use to make daily tasks easier and time-saving. The Government of India has launched several digital initiatives to provide access to information in regional languages. However, there is still much to be done for low-resourced languages like Dogri. As a result, a large portion of the non-English-speaking population remains dependent on manual sources of information as their primary option. It has been observed that no government website in the state currently offers content in Dogri, despite it being declared an official language of the state in September 2020 (Government of India, 2020). One of the hindrances in making content available in local languages is the manual effort required to convert the content into Dogri. This highlights the need for developing state-of-the-art (SOTA) automated machine translation systems. Such systems not only speed up the process but are also cost-effective. It can aid in the translation of various documents such as manuals, newspapers, academic content, literature, and other necessary content in less time and in a cost-effective manner. With intent to develop a state-of-the-art (SOTA) machine translation system (MTS) for the Hindi-Dogri language pair, the authors have worked on the three major approaches of machine translations: a system based on a rule-based approach, statistical MTS and a system based on deep learning models. Machine translation (MT) is a method that uses computer software to translate source language text (such as Hindi) to a target language (such as Dogri) while preserving the original meaning of the source language. Translation poses significant challenges for both human translators and machine translation systems, as it requires proper syntax and semantic knowledge of both languages, but MT has emerged over the past 10 years as a useful tool (Singh, Kumar & Chana, 2021) for breaking down barriers to communication in natural language processing. MT methods are generally divided into two categories: rule-based and corpus-based approaches. Rule-based methods dominated the field from the inception of MT until the 1990s (Garje et al., 2016; Dubey, 2019). Rule-based machine translation (RBMT) systems rely on bilingual dictionaries and manually crafted rules to translate source text to target text. In this study, the authors employed the direct approach of rule-based machine translation, which is one of the three main RBMT approaches, alongside the indirect and interlingua methods. The direct approach, also known as the first generation of machine translation, relies on large dictionaries and word-by-word translation with simple grammatical adjustments. It is designed for specific language pairs, particularly closely related ones, making development easier due to shared grammar and vocabulary. However, this approach is limited to bilingual, unidirectional translation and struggles with ambiguous source texts.
With the emergence of bilingual corpora, corpus-based approaches became the dominant approach to convert text from one language to another after the 2000s. Three corpus-based MT approaches are commonly used: example-based machine translation (EBMT), statistical machine translation (SMT), and neural machine translation (NMT). EBMT, established in the mid-1980s, operates by retrieving similar sentence pairs from a bilingual corpus to translate source texts (Turcato & Popowich, 2023). If similar sentence pairs can be retrieved, EBMT algorithms produce high-quality translations. However, EBMT approaches have low translation coverage because bilingual corpora cannot include all the linguistic phenomena of the language pairings.
In 1990, Brown et al. (1990) introduced the concept of statistical machine translation, where machines learn translation patterns from the corpus, removing the need for human experts to manually define rules. By 1993, this concept was formalized into five progressively complex models now known as the IBM alignment models by Brown et al. (1993). These models established a probabilistic foundation for word alignment and translation, marking a major advancement in the development of machine translation systems.
To conclude, the field of machine translation has undergone considerable development throughout the years, progressing through three major approaches: beginning with rule-based methods (Garje et al., 2016; Dubey, 2019), moving toward statistical machine translation (SMT) (Brown et al., 1990), and ultimately transitioning to neural machine translation (NMT) (Bahdanau, Cho & Bengio, 2014; Mahata et al., 2018).
In this study, the authors have employed all three approaches for translating Hindi text into Dogri text and analyzed the performance using automatic metrics such as Bilingual Evaluation Understudy (BLEU), Translation Edit Rate (TER), Metric for Evaluation of Translation with Explicit Ordering (METEOR), and Word Error Rate (WER), as well as through manual assessment focusing on adequacy, fluency, and ambiguity. This article is organized into several sections: it begins with an overview of the methodology adopted for developing Hindi-to-Dogri MT systems using RBMTS, SMT, and NMT. This is followed by a description of the datasets used, the experimental setup, and the evaluation criteria. Subsequent sections present the analysis of each MT approach, a comparative analysis of the results, and finally, the conclusions drawn from the study.
Brief about the languages under study
Hindi
Hindi is one of the two official languages of India. Apart from India, the majority of people in Nepal speak Hindi. It is also a protected language in South Africa and the third official court language in the UAE. It is the fourth most spoken language in the world (Wikipedia, 2024b).
Dogri
Dogri language is spoken by more than 5 million people in northern India (particularly in Jammu & Kashmir, Himachal Pradesh, and some parts of Punjab) and parts of Pakistan as a Pahari language (Wikipedia, 2024a). Dogri got the status of an official language of the Union Territory of Jammu and Kashmir by the Jammu and Kashmir Reorganization Act 2019. Dogri got added to the 8th Schedule of the Indian constitution by 92nd amendment in 2003 and came into effect on Jan 8, 2024. Devanagari script is used for writing both Hindi and Dogri languages (Gupta, 2004) from left to right; however, a few characteristics that distinguish Dogri from Hindi are discussed below:
-
Phonetic differences:
Some consonants produce different sounds in Dogri compared to Hindi, as illustrated in Table 1.
-
Tone and meaning:
In Dogri, a change in the tone of a word can completely alter its meaning. The apostrophe comma (’) is used to represent tone changes, and its placement affects the meaning of words, as shown in Table 2.
-
Non-usage of certain Hindi Symbols:
In Dogri, the Hindi symbols Chandrabindu (◌ँ) and Visarga (◌ः) are not used.
-
Use of specific letters:
In Dogri, the letters
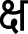 , ष, ऋ, and
, ष, ऋ, and 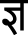 are used exclusively for the transliteration of Sanskrit words.
are used exclusively for the transliteration of Sanskrit words. -
Indication of extra-long vowels:
Extra-long vowels are indicated using the sign (ऽ). For example, चनाऽ (canā′)–election,
 (bhā′)–marriage, and
(bhā′)–marriage, and 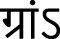 (grāṃ′) – village.
(grāṃ′) – village. -
Triple consonants:
In Dogri, some words exhibit the triple use of consonants, such as ननान (nanāna)–sister-in-law,
 (laggaga)–in use,
(laggaga)–in use,  (mannannā)–to agree,
(mannannā)–to agree, 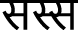 (sassa)–mother-in-law, and
(sassa)–mother-in-law, and  (babba)–father.
(babba)–father. -
Nasalization as a phoneme:
In Dogri, nasalization (◌˜) functions as a distinct phoneme. The following examples show how nasalization changes the meaning of words: तां (tāṃ)–so, ता (tā)–heat; बांग (bāṃga)–the crowing of a cock, and बाग (bāga)–garden.
| Hindi phoneme |
Dogri phoneme |
Use case (Hindi word) |
Dogri pronunciation |
English meaning |
|---|---|---|---|---|
| घ (gha) | क (ka) | घर (ghara) | कर (kara) | House |
| झ (jha) | च (ca) | झंडा (jhaṃṭā) | चंडा (caṭā) | Flag |
| ढ (ṭha) | ट (ṭa) | ढाबा (ṭābā), | टाबा (ṭābā) | Roadside eatery |
| ध (dha) | त (ta) | धन (dhana) | तन (tana) | Wealth |
| Dogri word |
English meaning |
Same Dogri word with tone change |
English meaning |
|---|---|---|---|
| कुन (kuna) | Insect | कु’न (ku’na) | Who |
ख (khalla) (khalla) |
Skin | ख′ (kha’lla) |
Down |
| फड़ (phaṭa) | Catch | फ’ड़ (pha’ṭa) | Boasting |
Methodology
The methodology adopted in this study follows a structured framework comprising four key components to ensure a comprehensive evaluation of Hindi-to-Dogri machine translation systems. First, linguistic resources were collected and prepared, including a rule-based lexicon and a Hindi–Dogri bilingual parallel corpus used for training and evaluating SMT and NMT models. Second, three machine translation approaches: RBMTS, SMT, and NMT were developed and implemented to facilitate a comparative study. Third, the outputs of each model were evaluated using both automatic evaluation metrics (BLEU, TER, METEOR, and WER) and expert human linguist evaluation based on standard qualitative measures: adequacy, fluency, and ambiguity. Finally, a comparative analysis was conducted to assess the performance of each model using the combined results from automated and manual evaluations, highlighting their respective strengths and limitations.
Rule-based machine translation system (RBMTS)
A direct approach of a rule-based machine translation system for Hindi text to Dogri text was developed by creating bilingual dictionaries and a collection of linguistic rules for Hindi and Dogri languages. The grammatical structure of the Hindi language text is transferred into the Dogri language text using these intricate rules. The system’s main components include pre-processing (tokenization, normalization, replacing the collocation and proper nouns), lexicon lookup, ambiguity resolution, inflectional analysis followed by the handling of the special cases like Kar, Raha and Laga. Figure 1 depicts the architecture of the system. The system aims to accurately translate Hindi text to Dogri text by upholding the integrity of both languages’ grammatical rules. By utilizing these components, the system is able to effectively handle various linguistic complexities and nuances present in the texts.
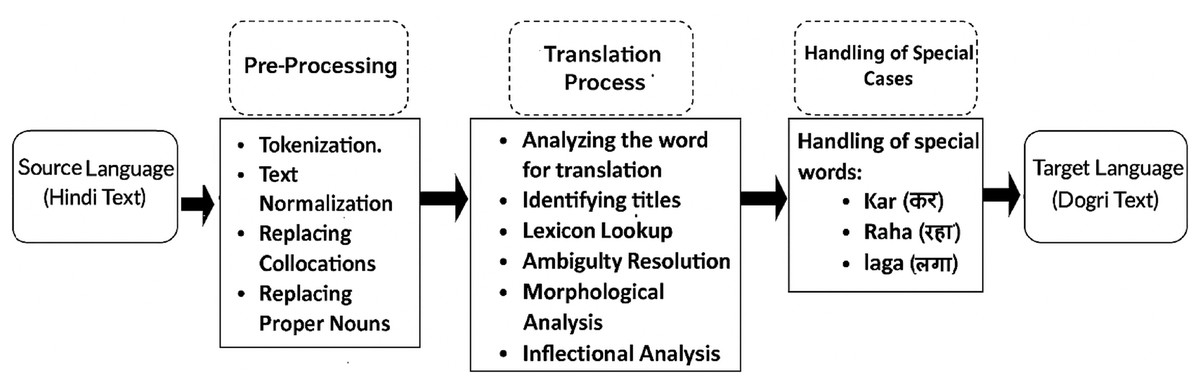
Figure 1: Architecture of rule-based machine translation system.
{kind=link}
Dataset used for RBMTS
A dataset of 22,900 words and phrases was collected under different categories, such as the creation of a Hindi-to-Dogri dictionary, collection of collocation phrases, collection of named entities, and standard words. Dataset details are provided in Table 3 for the development of the rule-based Hindi to Dogri machine translation system.
| S. no | Category | Total word/phrases | Meaning |
|---|---|---|---|
| 1 | Dictionary (Hindi to Dogri) | 18,524 | Each Hindi word is matched with its equivalent Dogri word. |
| 2 | Collocation phrases | 1,834 | Hindi phrases that must be translated as a single unit, not word-by-word. |
| 3 | Named entities | 2,130 | For identification and translation of proper nouns. |
| 4 | Standard words | 412 | Single standard words representing multiple synonyms. |
Dataset for corpus-based MT approaches
The dataset consists of 100,000 Hindi–Dogri parallel sentence pairs, each containing fewer than 80 words. The same corpus is used to train both SMT and three different NMT models, providing a true comparison of the two approaches. The dataset used in the study is collected from a variety of sources, including local and national Hindi newspapers, journals, and news portals, to build the corpus. In addition, the authors employed OCR techniques to digitize the Dogri Hindi Conversation Book  , a resource published by the Central Hindi Directorate. This book contains common conversational phrases in both Hindi and Dogri (Central Hindi Directorate of the Government of India, 2018). Additionally, the authors have gathered various Hindi words and sentences related to collocations, dictionary entries, popular names, and standard vocabulary, and had them translated into Dogri text. The following steps outline the approach adopted by the authors to develop a bilingual Hindi-Dogri parallel corpus:
, a resource published by the Central Hindi Directorate. This book contains common conversational phrases in both Hindi and Dogri (Central Hindi Directorate of the Government of India, 2018). Additionally, the authors have gathered various Hindi words and sentences related to collocations, dictionary entries, popular names, and standard vocabulary, and had them translated into Dogri text. The following steps outline the approach adopted by the authors to develop a bilingual Hindi-Dogri parallel corpus:
-
i.
Table 4 lists the multiple sources from which the Hindi text was collected.
-
ii.
A rule-based machine translation system (RBMTS) created by Preeti (2013) was used to convert the gathered Hindi text into Dogri.
-
iii.
The translated Dogri text was then examined and checked by qualified Dogri linguists to fix any mistakes or inaccuracies brought by the machine translation.
-
iv.
Finally, text alignment was carried out by segmenting the paragraphs into individual sentences and arranging the Hindi and Dogri sentences in a parallel format.
| Source text (Hindi) |
English meaning |
RBMTS translated Dogri text (Incorrect) |
English meaning |
Accurate Dogri text |
|---|---|---|---|---|
 अमेिरका अमेिरका(uttara amerikā) |
North America |
जवाब अमेिरका (Javāb amerikā) |
Answer America |
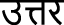 अमेिरका अमेिरका(uttar amerikā) |
| आम आदमी (āma ādamī) |
Common man |
अंब आदमी (Aanba ādamī) |
Mango man | आम आदमी (ām ādamī) |
| िवजय कुमार (vijaya kumāra) |
Vijay Kumar |
 कुमार (Jitta kumāra) कुमार (Jitta kumāra) |
Jitta Kumar | िवजय कुमार (vijaya kumāra) |
The original work for dataset creation was published in the research article (Kumar, Rakhra & Dubey, 2022). To conduct a comparative analysis of all machine translation approaches, 100 randomly selected Hindi sentences from various sources were used to test the RBMTS, SMT, and three NMT models. Table 5 provides statistics on the corpus that is used for training, validation and testing for the corpus-based approaches. The final version of the bilingual corpus has been publicly released to the research community and is accessible through the GitHub repository referenced in Kumar (2024).
| Hindi word |
English meaning |
RBMTS translated (Dogri Text) |
Possible Dogri translations depending on context |
English meaning |
|---|---|---|---|---|
| से (Se) | From | कोला (kolā) | कोला (kolā) | From |
| थमां (thamāan) | By | |||
 (uppara) (uppara) |
Above | |||
| जेहे (jehe) | Such | |||
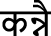 (kannai) (kannai) |
To whom | |||
| चा (chā) | In | |||
| दा (dā) | Of | |||
| शा (shā) | Should | |||
| िदया (Diyā) | Given | ओड़ेआ (odeā) | ओड़ेआ (odeā) | Given |
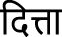 (dittā) (dittā) |
Given | |||
| कीता (kītā) | Done | |||
| की (Kī) | Of | कीती (kītī) | कीती (kītī) | Done |
| आसेआां (āseāān) | There are | |||
| दी (dī) | Of |
Preprocessing of corpus
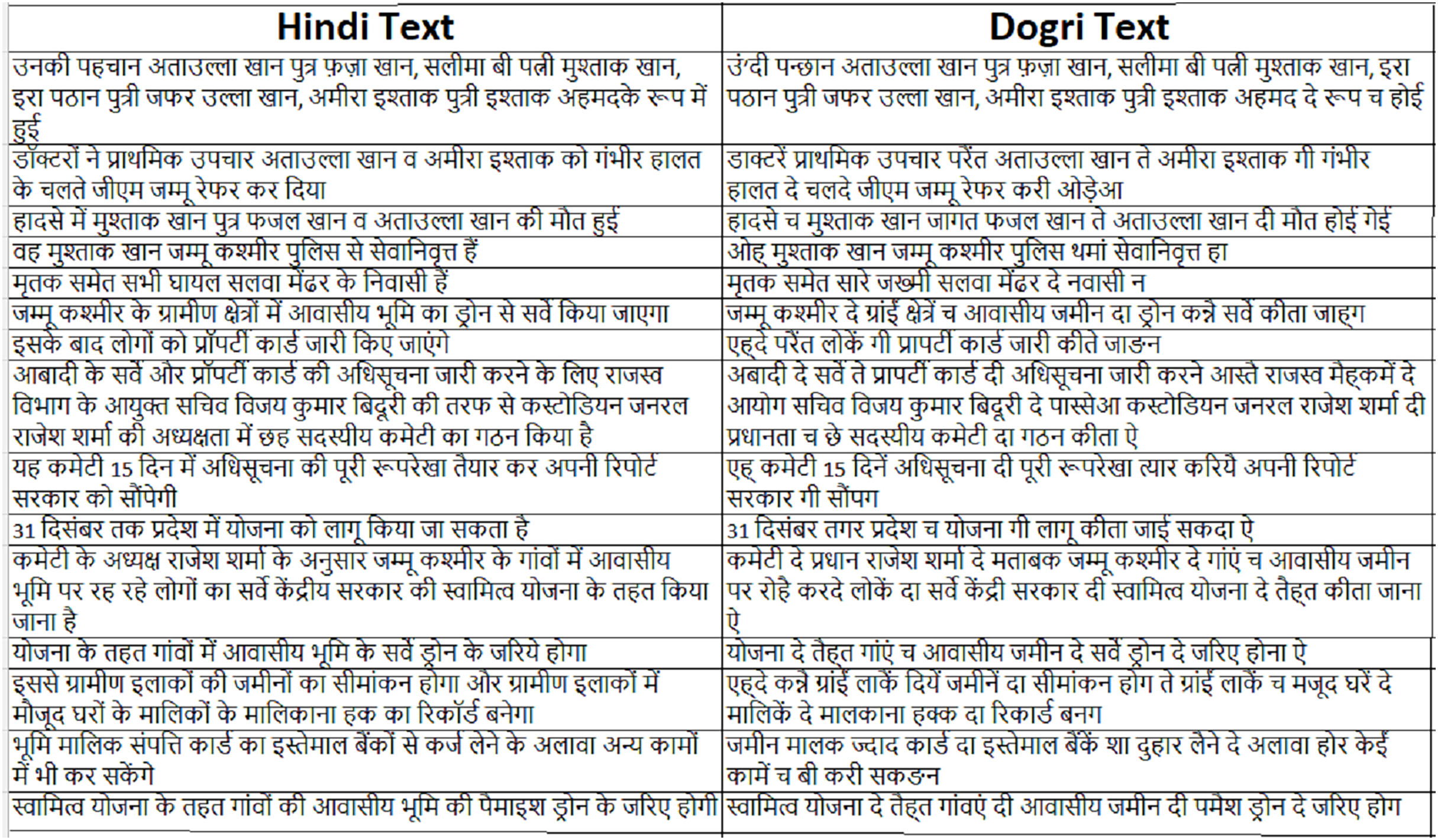
Preprocessing plays a critical role in the development of high-quality MT systems, particularly when dealing with linguistically diverse language pairs such as Hindi and Dogri. Proper preprocessing not only enhances the quality and consistency of the corpus but also improves the learning efficiency of both SMT and NMT models. A sample of the final Hindi–Dogri parallel corpus is presented in Fig. 2.
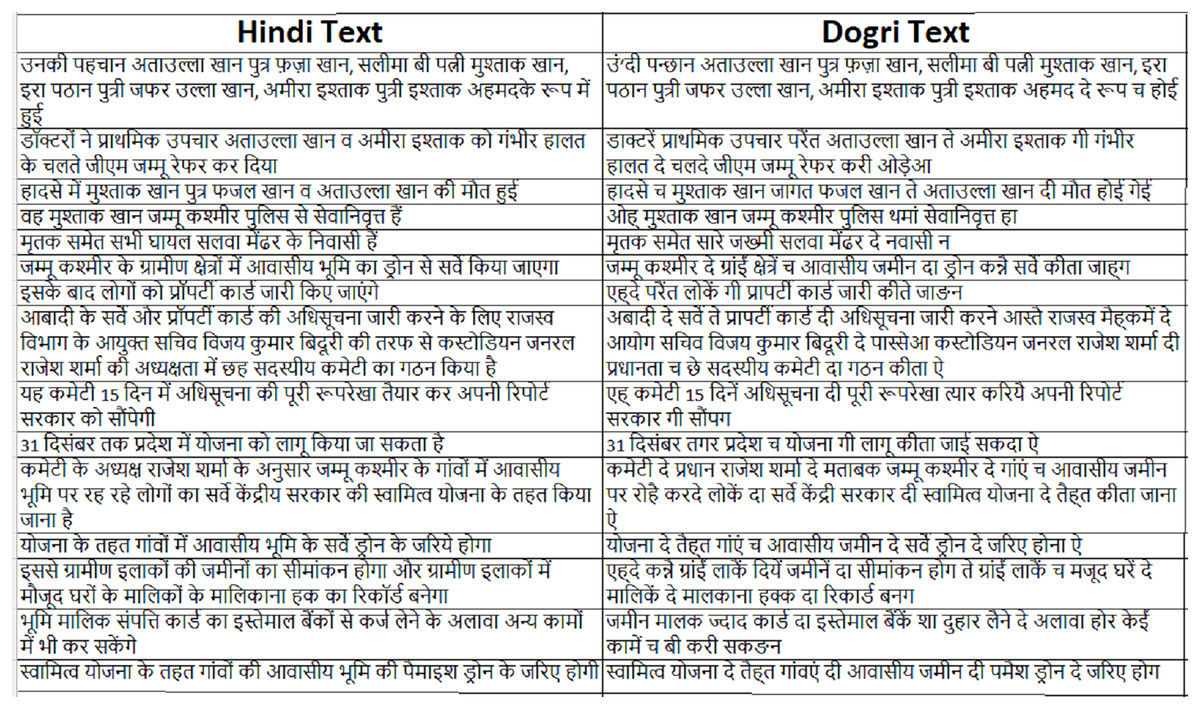
Figure 2: Sample of bilingual Hindi to Dogri parallel corpus.
{kind=link}
In this study, the preprocessing pipeline consisted of several systematic steps designed to clean and standardize the bilingual corpus are:
Sentence length filtering: Sentences exceeding 80 words in either Hindi or Dogri were removed to eliminate overly long and complex sentence structures that could negatively affect model training.
Noise removal: Special characters, duplicated words, incomplete tokens, and extraneous punctuation marks were removed using regular expressions.
Symbol and HTML tag removal: Any residual HTML tags and unwanted symbols (like., &, %, @, $) were eliminated to prevent noise during training.
Normalization of numerals: Devanagari numerals (०, १, २, …, ९) were replaced with corresponding numerals (0, 1, 2, …, 9) for consistency across the corpus.
Bracketed text elimination: Any content enclosed within parentheses (), curly braces {}, or square brackets [] was removed to ensure clean sentence structures.
Manual review and alignment: After automated cleaning, both the Hindi and Dogri text files were manually reviewed. Sentence pairs were verified and aligned to ensure parallelism and semantic equivalence.
Statistical machine translation system
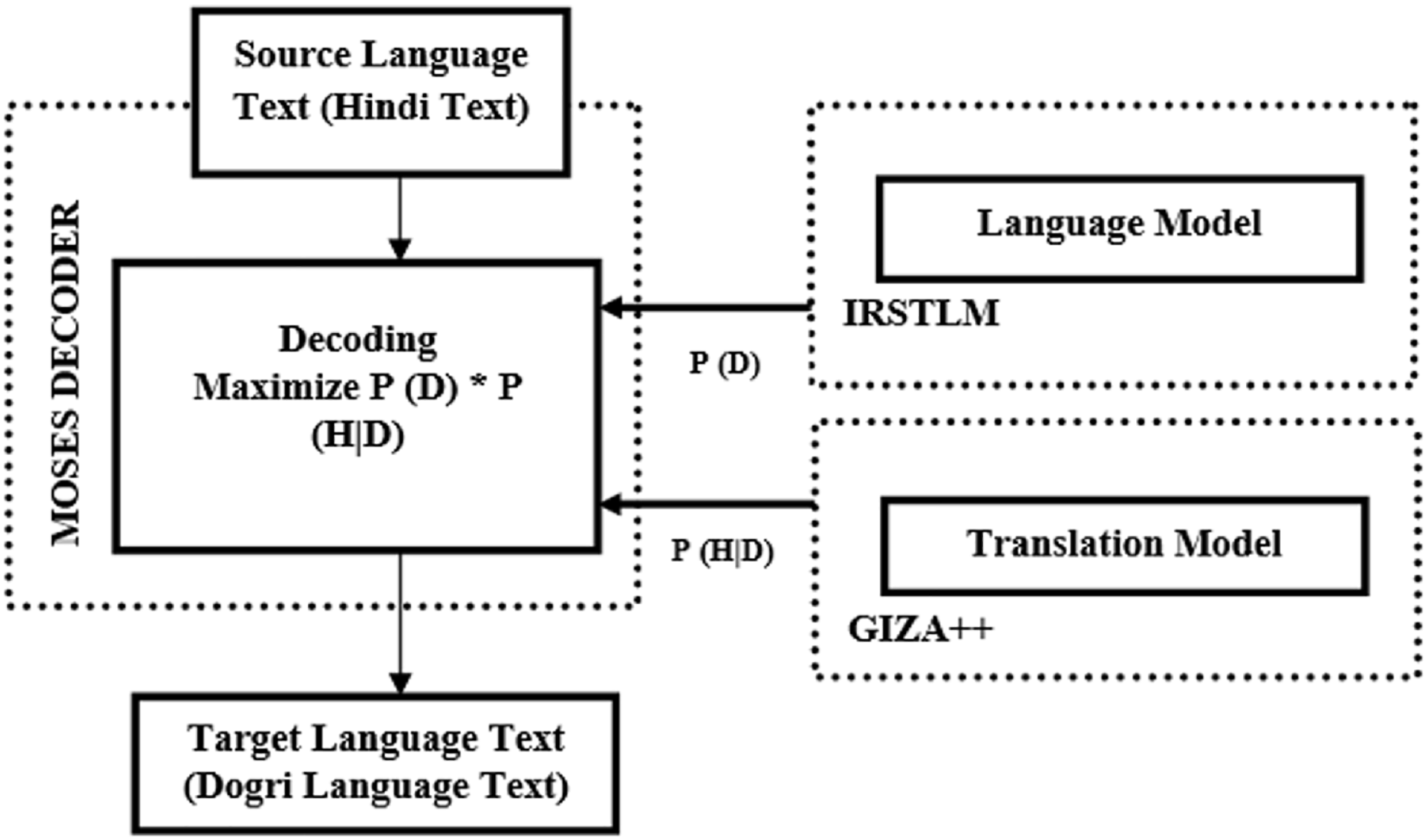
In 1990, Brown et al. (1990) introduced the SMT model for machine translation. Building on this foundation, the authors developed an SMT model specifically for Hindi-to-Dogri translation using the Moses toolkit. The Moses toolkit by Koehn et al. (2007) trains the translation model using aligned text of both Hindi and Dogri languages. Once the training is complete, the decoder uses beam search to translate the source text to target language text. The beam search algorithm selects the translation with the highest probability. Figure 3 illustrates the architecture of the Hindi-to-Dogri SMT system. SMT analyzes bilingual text corpora to create translation rules, with translation accuracy depending on the quality and size of the bilingual corpora.
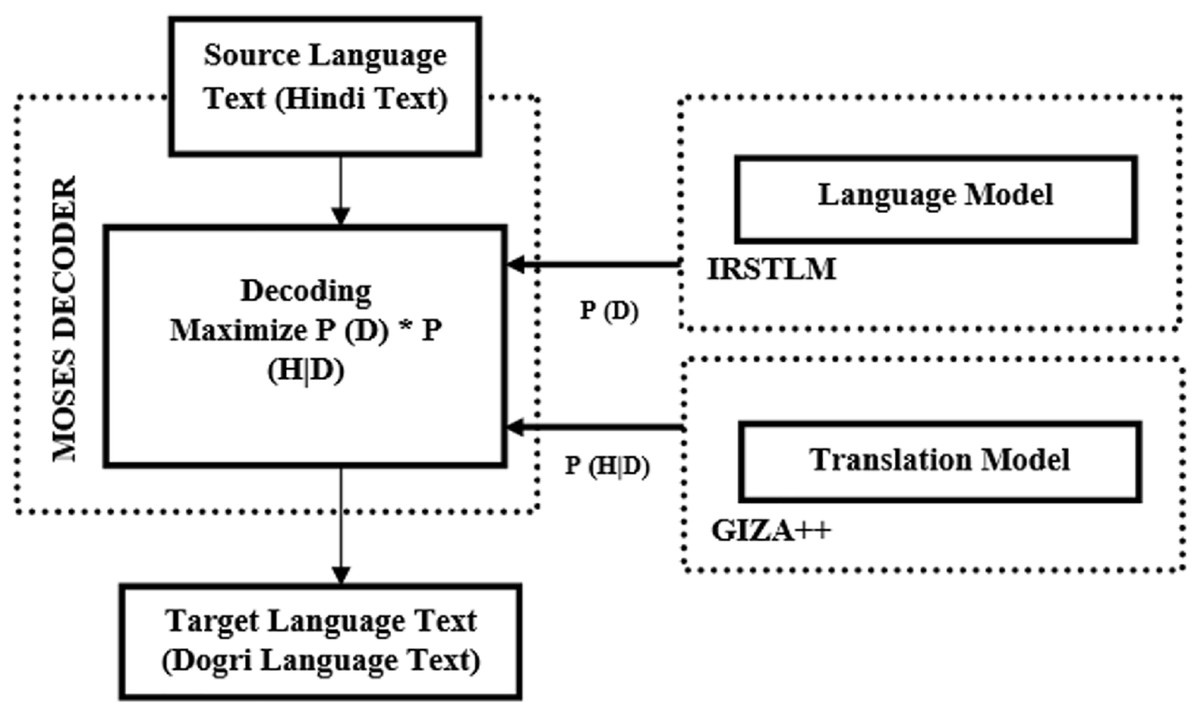
Figure 3: Architecture of Hindi to Dogri SMT system.
{kind=link}
Neural machine translation system
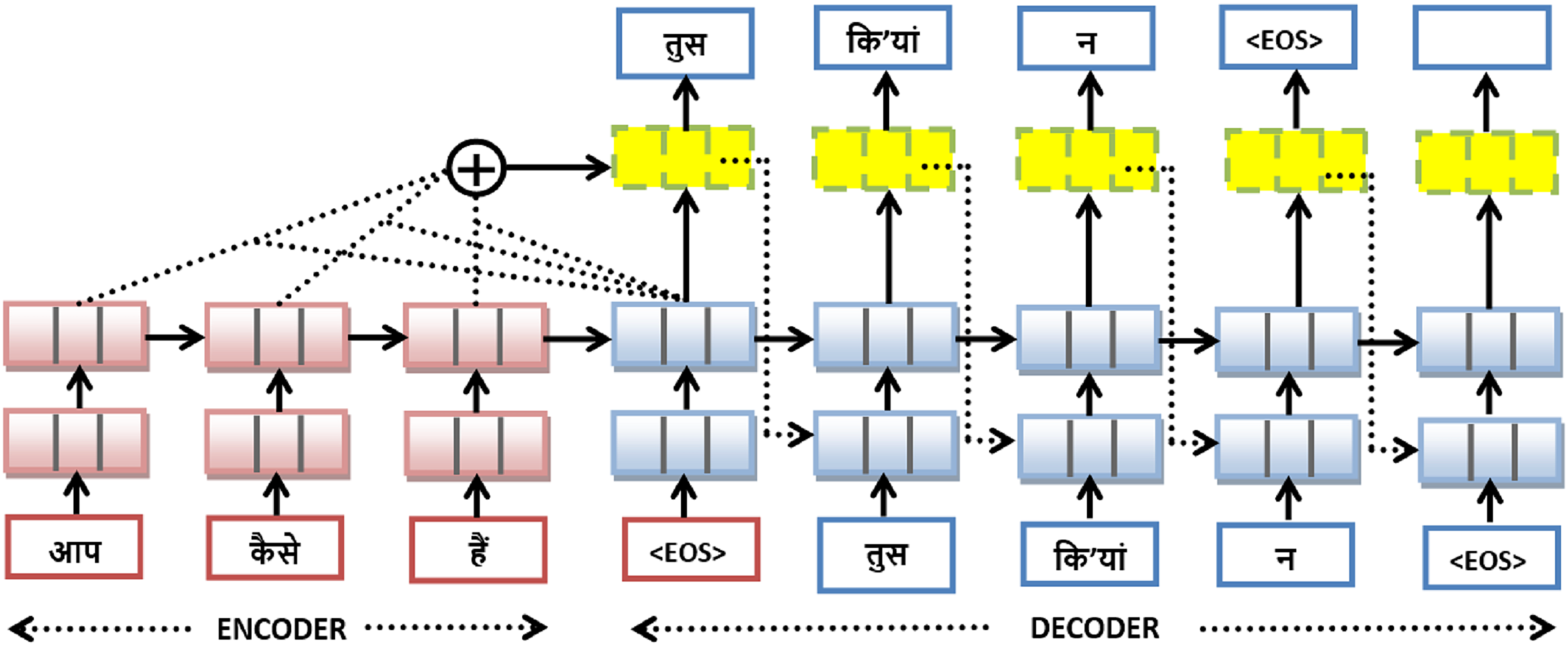
With the rapid progress of deep learning in domains such as speech recognition and computer vision, researchers began incorporating these techniques into machine translation systems (Bahdanau, Cho & Bengio, 2014). Today, the focus has shifted toward more advanced approaches like deep learning-based MTS, which are yielding better results (Young et al., 2018). In this study, three deep learning models have been implemented, all based on encoder–decoder architectures with attention mechanisms. Figure 4 serves as a reference to demonstrate the general mechanism of neural machine translation, which the implemented models also follow. On the left side, the encoder (in red) comprises sequential RNN cells—likely LSTM or GRU—that process the input Hindi sentence word-by-word: आप (you), कैसे (how), and हैं (are). On the right, the decoder (in blue) generates the Dogri translation: तुस (you), िकंयां (how), न (are), followed by the end-of-sequence token <EOS>. The yellow blocks above the decoder represent attention layers that dynamically compute context vectors by weighting the encoder outputs. These vectors are aggregated at each decoding step (illustrated by the circle with a “+” symbol) to guide the decoder in producing accurate translations. By training on large parallel corpora and leveraging modern deep-learning frameworks, the model automatically learns which aspects of the input sequence are most informative at each step of output generation, eliminating the need for hand-crafted features and improving both fluency and accuracy.
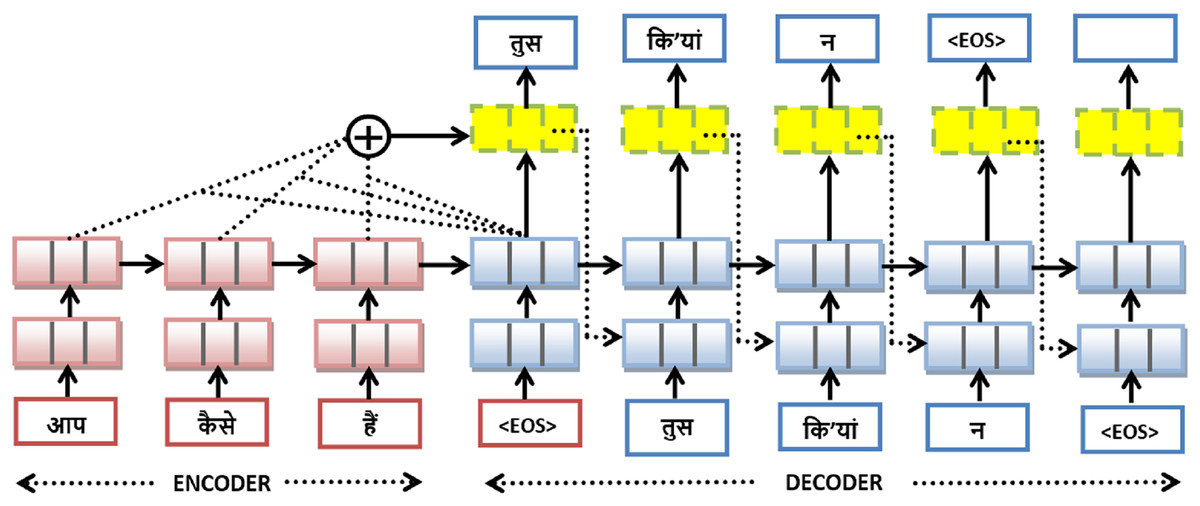
Figure 4: Attention-based encoder-decoder architecture for Hindi to Dogri translation.
{kind=link}
Training setup for NMT models
Three different NMT models were developed using the Open-NMT (Klein et al., 2017) toolkit, and are referred as recurrent neural network (RNN), bidirectional recurrent neural network with a batch size of 32 (BRNN-32) and bidirectional recurrent neural network with a batch size of 64 (BRNN-64) in this study. The recurrent neural network (RNN) model used a unidirectional LSTM for both encoder and decoder with four layers each, 500 hidden units, an embedding size of 500, a dropout rate of 0.1, learning rate of 1.0, and a batch size of 16. The BRNN-32 model employed a bidirectional LSTM encoder and unidirectional LSTM decoder, with six layers each, 500 hidden units, embedding size of 500, a dropout rate of 0.3, learning rate of 1.0, and a batch size of 32. Similarly, the BRNN-64 model maintained the same architecture as BRNN-32 but increased the batch size to 64. All models were trained for 50 epochs using the SGD optimizer with default gradient clipping of 5 and early stopping set to 4.
All three NMT models were trained on a high-performance workstation running Ubuntu 20.04 LTS. GPU acceleration was provided by an NVIDIA RTX A4000 with 16 GB of VRAM, using NVIDIA driver version 560.35.03 and CUDA version 12.6. The software environment was based on Python and utilized the OpenNMT-py framework, which is built on top of PyTorch and optimized for CUDA-enabled GPU acceleration. The dataset is split into training and validation sets in a ratio of 80:20, with 80% of the dataset used for training, 10% for validation and 10% for testing.
Results and findings
This section analyzes the performance of each MT system and presents key findings, concluding with a comparative analysis of translation results.
Analysis of the RBMT system
The current rule-based machine translation system relies on a lexicon lookup dictionary containing approximately 22,900 words and phrases. Because of this limited size, many Hindi words and phrases remain untranslated and are directly carried over into the output in Dogri text without any change. This reduces the accuracy of the final output when translating proper nouns, collocations and named entities. Regarding Hindi’s polysemous words, such as ‘से’ (se), ‘और’ (aur), िदया (diyā), की (kee), etc., where the exact translation depends on the context of the discussions, the system generates output with ambiguity. Table 6 shows the output of RBMTS, where the system does not recognize named entities, resulting in incorrect Dogri translations. Table 7 displays a collection of polysemous words that can take multiple forms depending on the context of the discussion, resulting in ambiguous translation.
| Hindi text sources | No. of sentences | References | Hindi tokens |
Dogri tokens |
|---|---|---|---|---|
Conversation book on Dogri to Hindi (डोगरी –  ) ) |
1,802 | http://www.chdpublication.education.gov.in/ebook/b104/html5forpc.html?page=0 | 9,226 | 9,056 |
| Hindi-language online newspapers (such as Amar Ujala, Dainik Jagran, BBC Hindi, Dainik Bhaskar and Hindustan Newspaper) | 20,000 | https://www.amarujala.com/jammu-and-kashmir | 99,905 | 101,139 |
| 20,000 | https://www.jagran.com/ | 94,914 | 100,232 | |
| 20,000 | https://www.bbc.com/hindi | 92,257 | 93,456 | |
| 20,000 | https://www.bhaskar.com/ | 93,949 | 96,011 | |
| 20,000 | https://www.livehindustan.com/ | 94,836 | 96,114 | |
| Dogri name, Hindi collocation, dictionary and standard words | Collected as much as possible Hindi, Dogri words that falls under the category of collocations, dictionary words, popular names and other standard words used both in Hindi as well as Dogri. | 24,999 | 26,739 | |
| Total | 101,802 | 510,086 | 522,747 | |
| Dataset division | Hindi to Dogri text (Sources) |
Total no. of Hindi-Dogri parallel sentences | Hindi words |
Unique Hindi words | Dogri words |
Unique Dogri words |
|---|---|---|---|---|---|---|
| Total Corpus used for training, validation and testing of SMT and NMT models | The corpus collected from various sources like news papers, books, Standard words, Hindi to Dogri dictionary, Dogri names etc. | 100,000 | 771,930 | 67,332 | 777,401 | 66,184 |
| Training Corpus | 80% of the total Corpus | |||||
| Testing Corpus | 10% of the total Corpus | |||||
| Validation Corpus | 10% of the total Corpus | |||||
| Dataset (Corpus) for comparative analysis of RBMTS, SMT, and NMT performance | Picked random sentences from News portals | 100 | 1,741 | 156 | 1,742 | 158 |
The following paragraph presents the translation of Hindi text into Dogri text using RBMT. It contains several incorrect translations of named entities, collocations, and polysemous words. The text marked with strikethrough indicates the incorrect translations produced by the system, while the bold text represents the expected translations. The transliteration of Hindi and Dogri words was carried out using the online transliteration tool available at Devnagri (2021).
Hindi text (Input)

(Paryaṭan vibhāg ke nideshak ṭaॉ. Vivekānanda rāya ne somavār ko basohalī kṣhetra ke paryaṭan sthaloan kā daurā kar kuchh jarūrī dishā nirdesh jārī kie haian।unahone sāth mean ām logoan ke sāth mulāक़āt kī।is daurān unake sāth ṭīṭīsī adhyakṣha prashāanta kishora, sīo rohit saradānā, sahāyak nideshak vijaya sharmā, bīṭīsī adhyakṣha suṣhamā jamavāl aur paryaṭan vibhāg ke anya adhikārī maujūd rahe।naī yojanāoan par vichār vimarsha kiyā।ṭīṭīsī adhyakṣha ne nideshak se ilākoan ko paryaṭan kī dṛuṣhṭi se vikasit karane ke lie projekṭa banāne ko kahā।is mandir kī chāradīvārī karīb ek sāl se kṣhatigrasta hai।isake alāvā, unhoanne ṭūrijma risepshan seanṭar kī imārat kā bhī jāyajā liyā।aanta mean pṛuthvī shaॉ ne sabhī ko svatantratā divas kī agrim shubhakāmanāean dīan।jahāan tīn nadiyāan gangā, yamunā aur bhūmigat sarasvatī kā vilaya hotā hai।).
Dogri text output (translated using RBMTS)

Analysis of the SMT system
Developing and maintaining rules in a rule-based approach is time-consuming, and transferring them across different domains or languages is a complex task. As a result, scaling rule-based systems for open-domain or multilingual translation is challenging. The SMT model was trained with a parallel corpus of approximately 0.1 million sentences, as shown in Table 5. The translation results are generally quite accurate and fluent, barring the translation of rare or unknown words. The system is producing UNK for words which are not part of the training corpus. The system managed ambiguity more effectively than RBMTS. The following section, ‘Comparative analysis of translation results’, supports this observation, showing that the ambiguity score for the SMT model is higher than that of RBMTS.
Analysis of the NMT system
SMT methods can significantly enhance translation quality; however, they rely on log-linear models that incorporate several manually constructed components, such as the translation model, language model, and reordering model. This often leads to substantial reordering challenges, particularly in distant language pairs. NMT systems are built on neural networks, where each neuron mathematically processes input data. During training, the network is fed bilingual Hindi–Dogri parallel text corpora and adjusts neuron weights based on translation errors. These systems continuously fine-tune themselves, resulting in progressively better performance. Compared to SMT, NMT proves to be more reliable—especially for low-resource languages—due to its superior ability to account for context and generate more natural, human-like translations. This observation is supported by the results summarized in the following section: Comparative Analysis of Translation Results.
Comparative analysis of translation results
Recent research has documented the differences between various MT systems with respect to the output quality and error types. Some researchers have used automatic evaluation metrics such as TER (Snover et al., 2006) and BLEU (Papineni et al., 2002) metrics and others have assessed MT systems based on adequacy and fluency through human evaluations of the translation output (Koehn & Monz, 2006; Callison-Burch, Osborne & Koehn, 2006; Lavie & Agarwal, 2007; White, O’connell & O’mara, 1994). A few studies have also combined human evaluation methods with automatic evaluation metrics (AEMs) to provide a more comprehensive analysis (Jia, Carl & Wang, 2019). In the present study, the results of all three MT approaches were evaluated using dual framework: expert linguist assessments of adequacy, fluency, and ambiguity, and automated metrics including BLEU, TER, METEOR, and WER. For ambiguity evaluation, the expert linguists employed a custom technique focused specifically on lexical disambiguation. They assessed whether the system correctly interpreted and translated polysemous Hindi words such as: ‘से’ (sē), which can mean ‘by’ or ‘with’ (instrumental); ‘और’ (aur), meaning either ‘and’ (conjunctive) or ‘more’ (comparative); ‘िदया’ (diyā), which may function as a verb (‘gave’) or a noun (‘light’); and ‘की’ (kī), which can indicate possession (‘of’, genitive) or act as an auxiliary/past-tense marker (‘did’), among others. As shown in Table 7, these words can have multiple meanings depending on context, making them particularly challenging for machine translation systems. Ambiguity scores were assigned based on the system’s ability to accurately translate such context-sensitive polysemous words.
Automatic evaluation using standard metrics
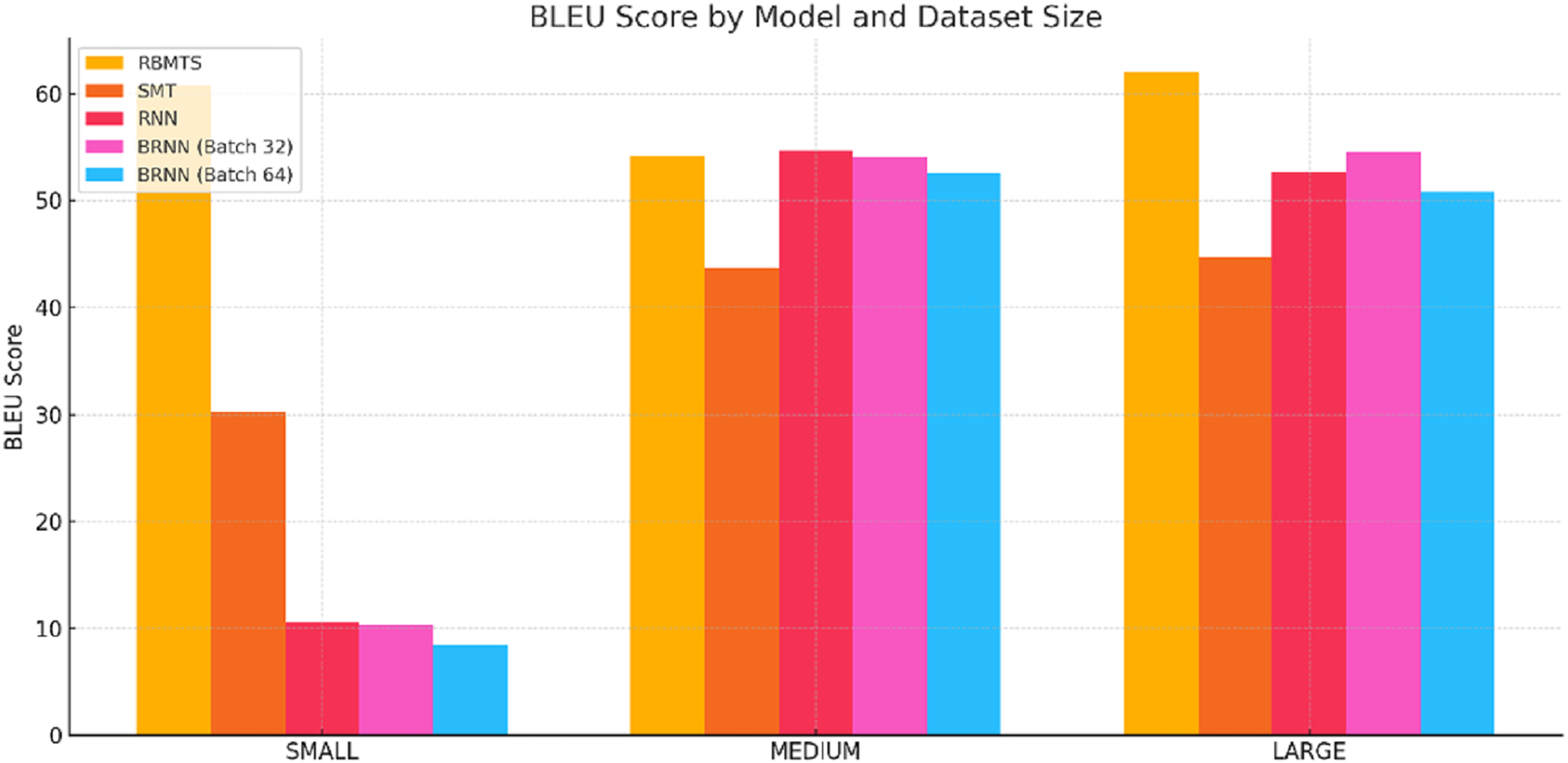
The test dataset was divided into three subsets based on sentence length: SMALL (sentences with fewer than si words), MEDIUM (sentences containing six to 14 words), and LARGE (sentences with 15 or more words). This segmentation aimed to evaluate how sentence length influences translation performance across different models, including rule-based, SMT, and NMT systems. The performance of the Hindi-to-Dogri machine translation systems was quantitatively evaluated using four widely adopted metrics: BLEU, TER, METEOR, and WER. The comparison includes RBMTS, SMT, and various neural machine translation (NMT) models—RNN and bi-directional RNNs (BRNNs) with two batch sizes i.e., 32 and 64. The results revealed significant variations in performance across these subsets as shown in the Table 8. Figures 5–8 present a comparative analysis of the Hindi-to-Dogri translation models based on BLEU, TER, METEOR, and WER scores across small, medium, and large sentence categories.
| Dataset size | Model | BLEU | TER | METEOR | WER |
|---|---|---|---|---|---|
| Small | RBMTS | 60.78 | 20.61 | 49.42 | 15.81 |
| SMT | 30.29 | 69.03 | 20.58 | 71.24 | |
| RNN | 10.59 | 81.13 | 9.06 | 88.16 | |
| BRNN (Batch 32) | 10.27 | 79.72 | 10.02 | 87.56 | |
| BRNN (Batch 64) | 8.45 | 84.97 | 7.3 | 92.07 | |
| Medium | RBMTS | 54.17 | 32.42 | 68.38 | 32.4 |
| SMT | 43.65 | 43.01 | 68.32 | 40.33 | |
| RNN | 54.73 | 27.06 | 73.78 | 26.5 | |
| BRNN (Batch 32) | 53.99 | 27.45 | 73.75 | 26.99 | |
| BRNN (Batch 64) | 52.55 | 28.81 | 71.44 | 28.66 | |
| Large | RBMTS | 62.08 | 27.32 | 75.14 | 27.59 |
| SMT | 44.73 | 40.17 | 72.56 | 38.83 | |
| RNN | 52.72 | 28.35 | 74.68 | 27.69 | |
| BRNN (Batch 32) | 54.55 | 27.37 | 75.63 | 26.99 | |
| BRNN (Batch 64) | 50.86 | 30.38 | 73.33 | 28.85 |
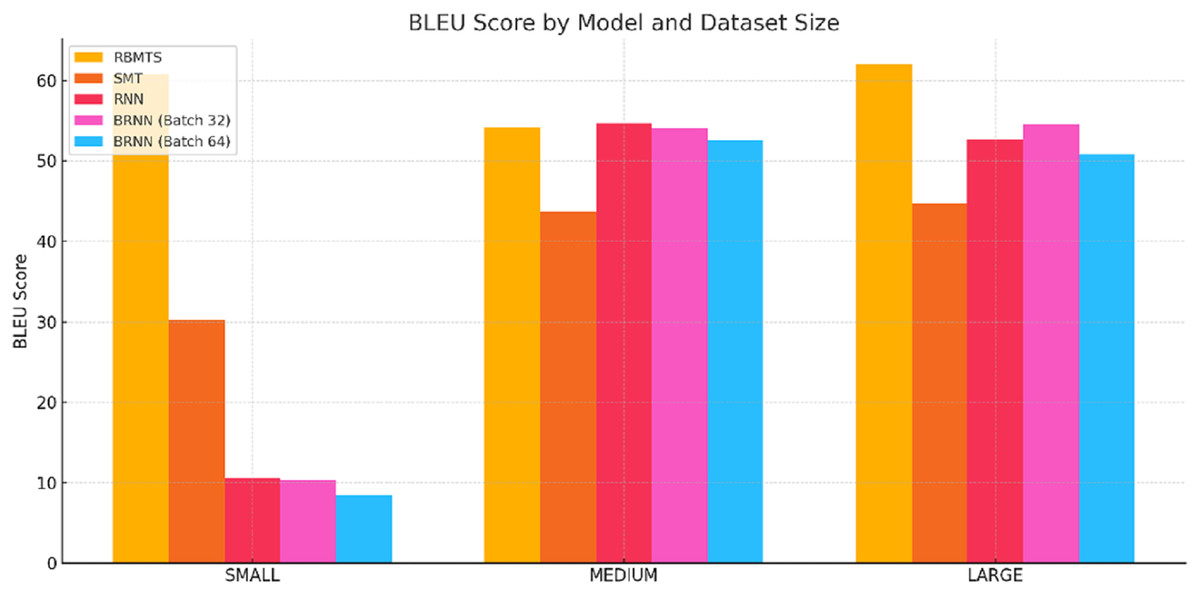
Figure 5: BLEU score comparsion of Hindi-to-Dogri translation models across small, medium, and large sentences categories.
{kind=link}
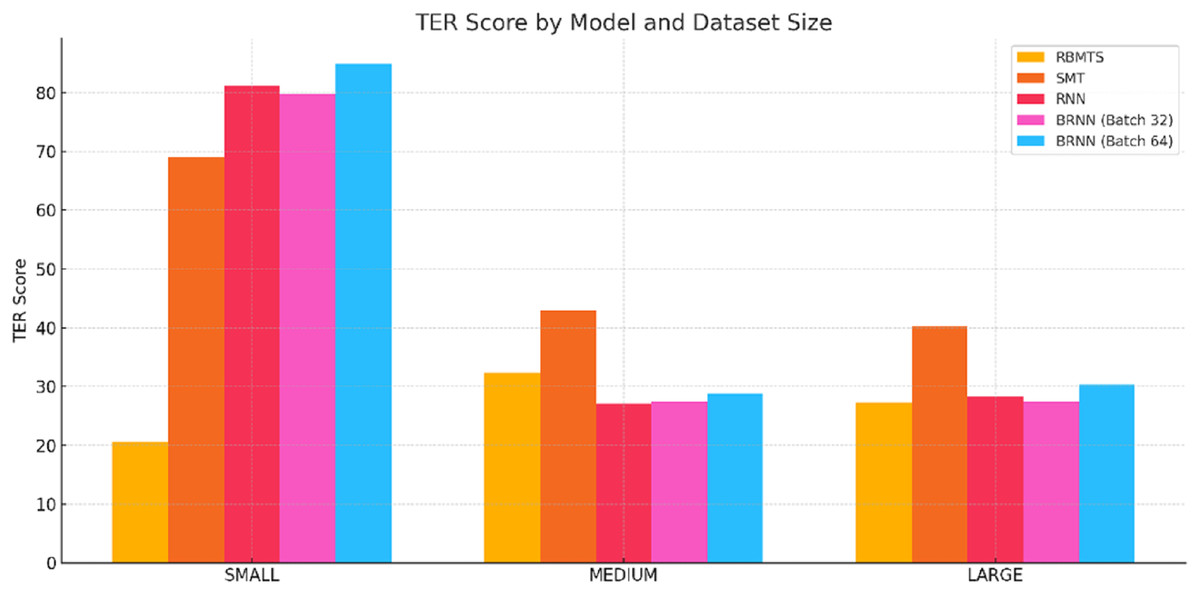
Figure 6: TER score comparsion of Hindi-to-Dogri translation models across small, medium, and large sentences categories.
{kind=link}
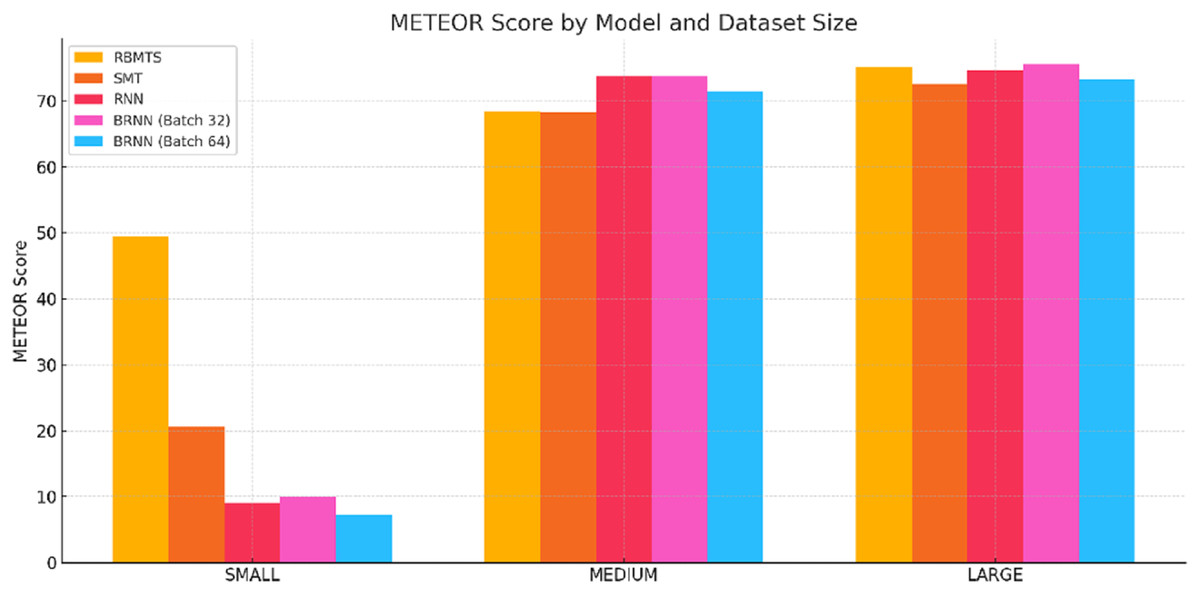
Figure 7: METEOR score comparsion of Hindi-to-Dogri translation models across small, medium, and large sentences categories.
{kind=link}
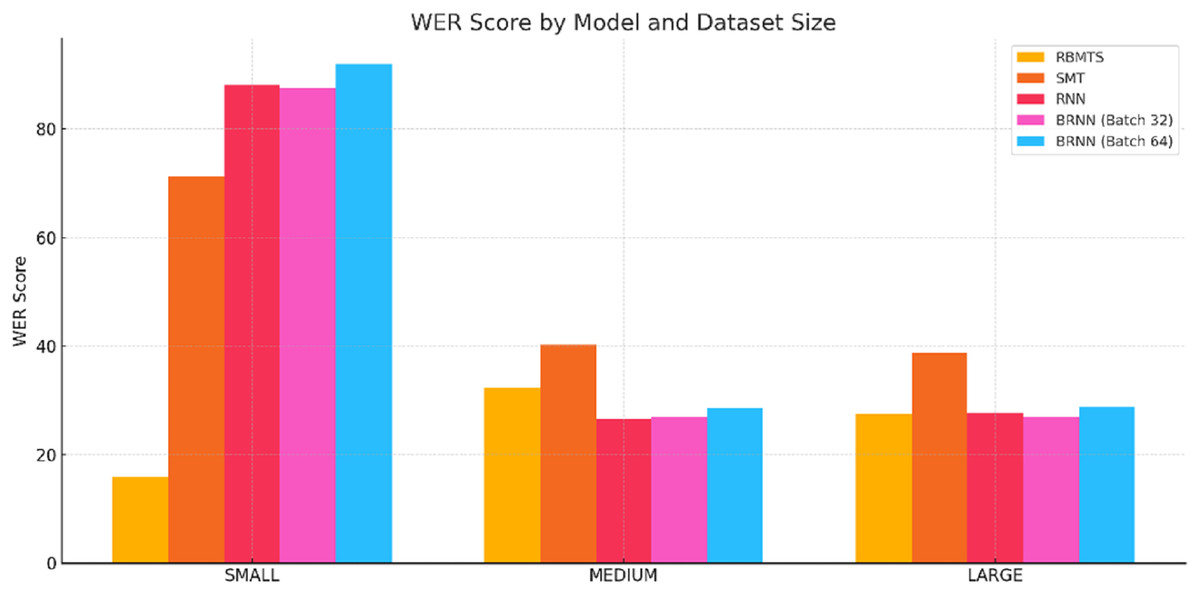
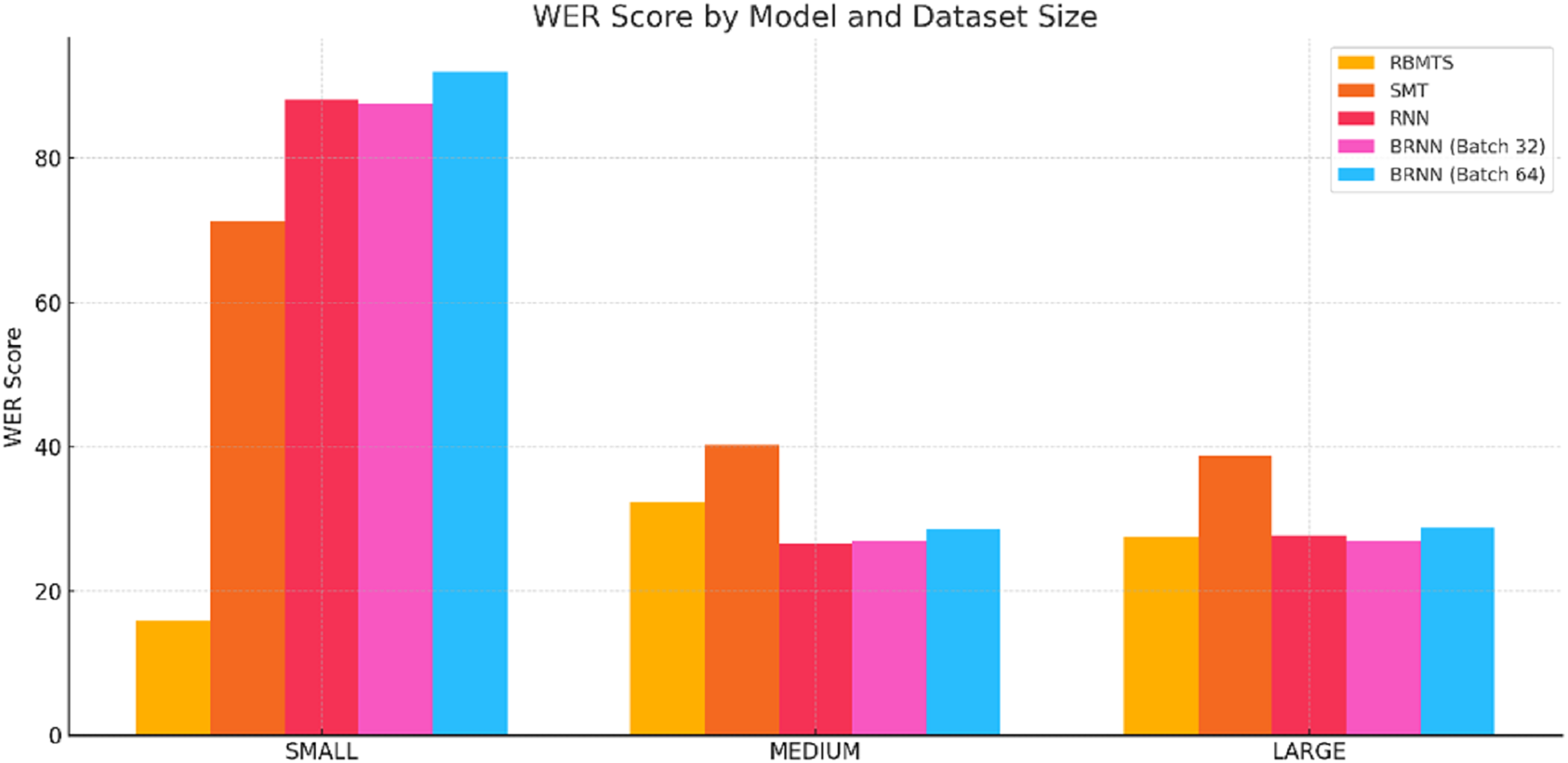
Figure 8: WER score comparsion of Hindi-to-Dogri translation models across small, medium, and large sentences categories.
{kind=link}
BLEU score analysis
RBMTS attained strong BLEU scores across different sentence lengths (60.78–SMALL, 54.17–MEDIUM, 62.08–LARGE), although the RNN model achieved a slightly higher score (54.73) for MEDIUM-length sentences. Overall, this indicates the strong performance of RBMTS in generating surface-level word matches.
SMT performed reasonably well on MEDIUM and LARGE sentences (43.65 and 44.73, respectively) but struggled with SMALL sentences.
NMT models, especially RNN and BRNNs, showed lower BLEU scores on SMALL sentences but improved substantially on MEDIUM and LARGE datasets. This suggests neural models are more effective in handling complex, longer sentences where context plays a greater role.
TER score analysis
RBMTS showed the lowest TER (i.e., fewer edits needed) for SMALL and LARGE sentences, demonstrating fluency and accuracy in simpler structures.
NMT models had higher TER for SMALL sentences, likely due to overfitting or difficulty handling short context.
For MEDIUM and LARGE sentences, RNN and BRNN-32 achieved better TER than SMT, with BRNN models showing slightly better edit efficiency, especially on LARGE sentences.
METEOR score analysis
RBMTS again led in SMALL and LARGE sentences, but NMT models (RNN and BRNNs) outperformed both RBMTS and SMT in the MEDIUM sentences, where semantic understanding is more important.
Interestingly, BRNN-32 achieved the highest METEOR score for LARGE sentences (75.63), indicating its superior ability to maintain semantic equivalence and word alignment in longer contexts.
WER score analysis
RBMTS had the lowest WER across all sentence’s sizes, reflecting fewer word-level errors and better literal translation.
SMT and NMT models, particularly RNN and BRNNs, had significantly higher WER in SMALL sentences, reinforcing the observation that short sentences pose challenges for context-dependent models.
In MEDIUM and LARGE sentences, BRNN-32 exhibited the best WER among neural models, indicating its improved reliability in realistic sentence lengths.
Human evaluation of results
For expert manual evaluation, an Excel spreadsheet was compiled containing Hindi source sentences along with their corresponding Dogri translations generated by various models. Three native Dogri-speaking professional linguists evaluated the translations based on three metrics: Adequacy, which measures how well the translated text preserves the meaning of the original Hindi input; fluency, which assesses the grammatical correctness and naturalness of the Dogri output; and ambiguity, which evaluates the clarity of the translation and whether it is prone to multiple interpretations or confusion. Each of these metrics adequacy, fluency, and ambiguity was rated using a five-point Likert scale, where a score of 5 indicates excellent quality (i.e., complete meaning preservation, flawless grammar, and clear interpretation), while a score of 1 indicates poor quality (i.e., significant meaning loss, serious grammatical errors, or high ambiguity).
Table 9 outlines the rating scale used for adequacy, fluency, and ambiguity. Higher the value means better results. The final scores were calculated by averaging the ratings across all evaluators and sentences, as shown in the equation:
-
-
N be the total number of evaluated sentences
-
-
M be the total number of human evaluators
-
-
s_{i,j} denote the adequacy score assigned by evaluator j to sentence i
-
-
f_{i,j} denote the fluency score assigned by evaluator j to sentence i
-
-
a_{i,j} denote the ambiguity score assigned by evaluator j to sentence i
| Score | Adequacy | Fluency | Ambiguity |
|---|---|---|---|
| 5 | Dogri output fully preserves meaning of Hindi sentence. |
Native-level Dogri; no grammatical or stylistic issues. |
Completely clear; no ambiguity or confusion |
| 4 | Minor details are missing but meaning is mostly intact. |
Small errors but very natural overall. |
Slightly unclear in rare cases, but meaning is generally obvious. |
| 3 | Some parts are missing or altered; overall idea is understandable. |
Understandable but contains awkward or incorrect phrases. |
Some ambiguity present; meaning requires interpretation. |
| 2 | Only a small part of the meaning is conveyed. |
Hard to read; poor grammar. | Significant ambiguity; multiple possible interpretations. |
| 1 | Translation is incorrect or meaningless. |
Broken Dogri; hard or impossible to understand. |
Highly ambiguous or completely unclear meaning. |
Metric score (M_X)
For any evaluation metric X (where X ∈ {A, F, A_m}, corresponding to Adequacy, Fluency, and Ambiguity, respectively), let:
-
-
x_{i,j} denote the score given by evaluator j to sentence i for metric X.
The score for metric X is then calculated as:
A set of 100 Hindi sentences of varying lengths was collected for manual evaluation. Using the equation , the evaluation scores were calculated and are presented in Table 10. The comparative manual evaluation scores, analyzed in the following section, are presented in Fig. 9.
| MT system | Adequacy score |
Fluency score |
Ambiguity score |
|---|---|---|---|
| RBMTS | 2.9 | 2.8 | 2.2 |
| SMT | 2.2 | 2.2 | 2.6 |
| RNN | 2.68 | 2.6 | 2.8 |
| BRNN (Batch 32) | 2.71 | 2.65 | 2.9 |
| BRNN (Batch 64) | 2.58 | 2.58 | 2.7 |
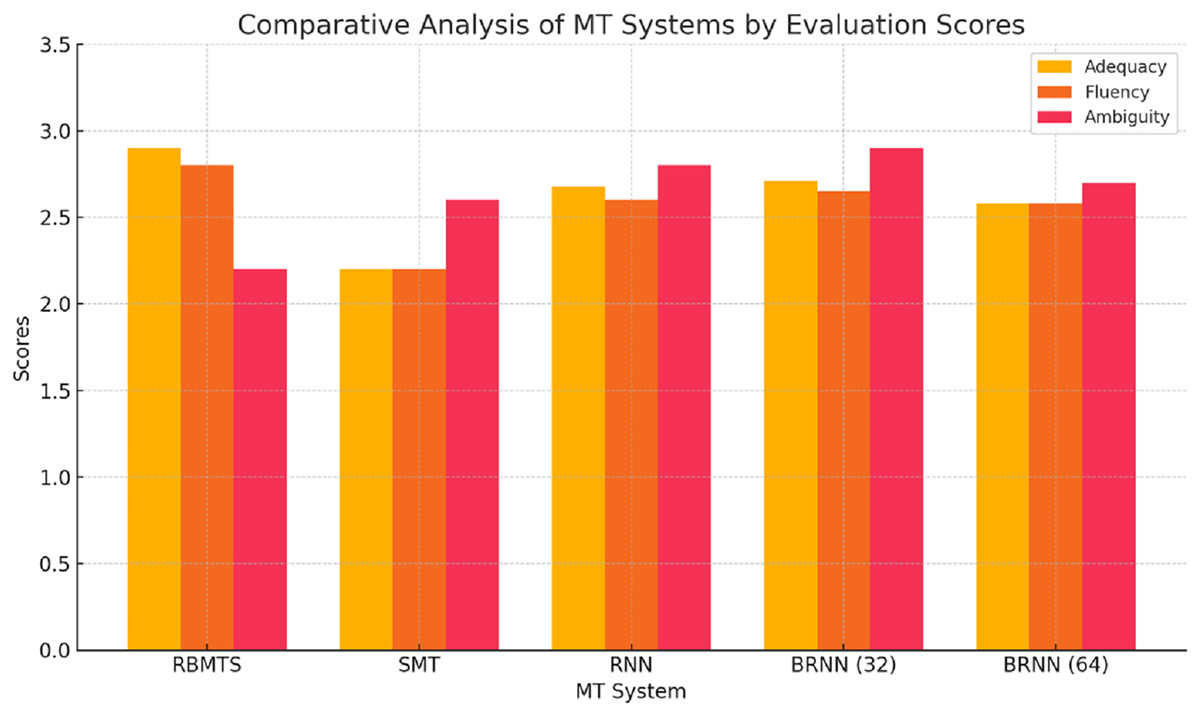
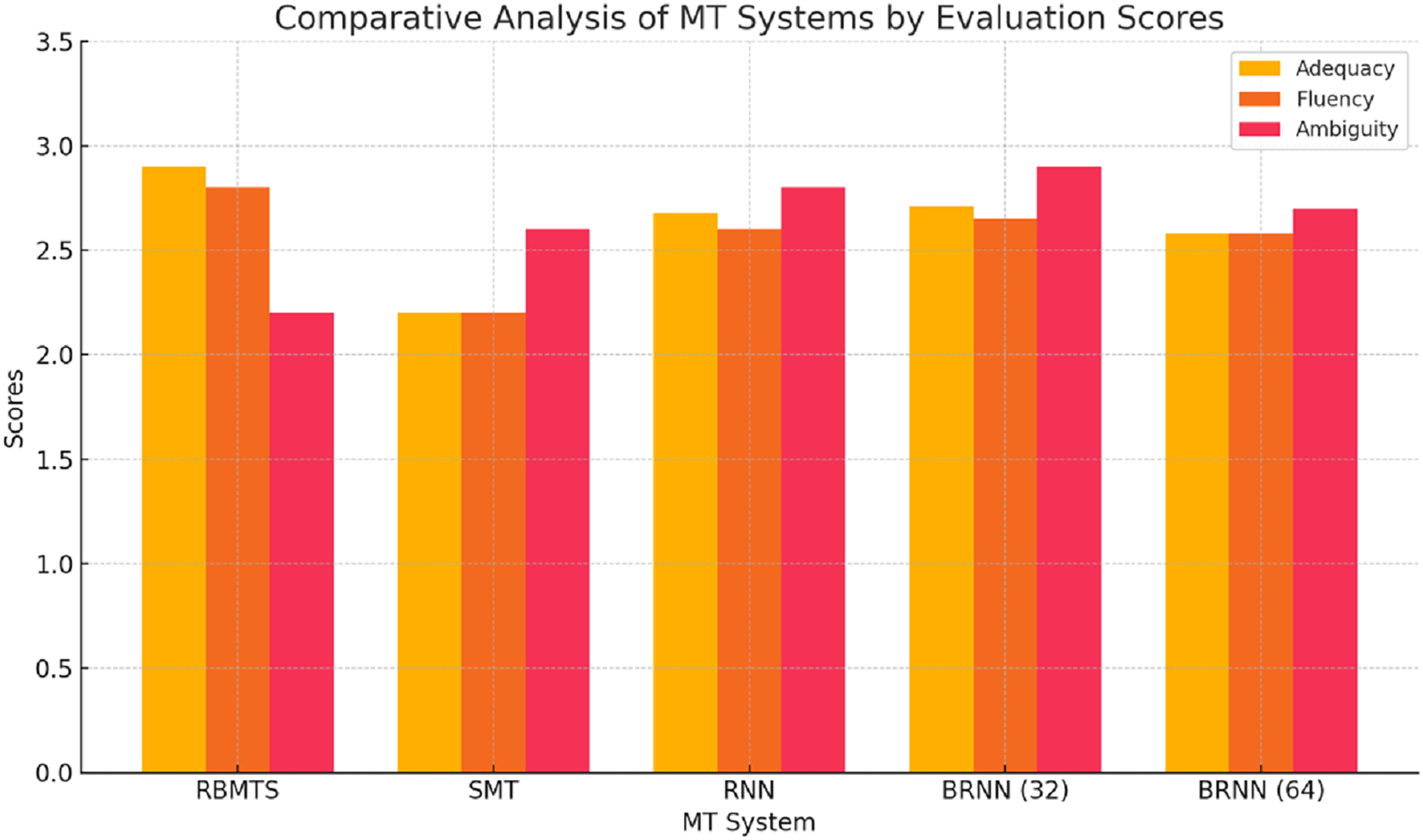
Figure 9: Comparative analysis of MT systems by manual evaluation scores.
{kind=link}
RBMTS: outperforms other systems in adequacy (2.90) and fluency (2.80), suggesting it can better preserve meaning and grammatical structure. However, its ambiguity score (2.20) is the lowest, indicating that while accurate, its outputs may lack clarity or sound overly rigid due to rule limitations.
SMT: receives the lowest scores in adequacy and fluency (2.20 each), showing it often fails to retain complete meaning and produce natural sentences. Its relatively higher ambiguity score (2.60) indicates that its output is somewhat clearer, possibly due to over-simplified phrasing.
RNN: improves upon SMT in all areas, particularly in ambiguity (2.80), highlighting that it produces more contextually coherent and less confusing translations. However, it still falls slightly behind RBMTS in adequacy and fluency.
BRNN-32: achieves the highest ambiguity score (2.90) and slightly edges out RNN in adequacy and fluency, indicating that it provides a better balance of meaning retention and sentence clarity. The bidirectional context handling improves its translation quality noticeably.
BRNN-64: shows comparable results but with a slight dip in all scores compared to Batch 32. This may reflect that larger batch sizes don’t always translate to better sentence-level precision, possibly due to convergence smoothing in training.
Sample output
Among the 100 sample sentences chosen for manual expert evaluation, three examples are provided to showcase how each model translates the given Hindi text. The accuracy of each output is evaluated by comparing it with a reference translation in Dogri:
Hindi Text 1: तािक लोगों को सुिवधा िमल सके (tāki logoan ko suvidhā mil sake)
Dogri Reference Text 1:  (tāanje lokean gī suvidhā thhoī sakai)
(tāanje lokean gī suvidhā thhoī sakai)
Dogri Text 1 (RBMTS):  (tāanje lokean gī subadhā milla sakai)
(tāanje lokean gī subadhā milla sakai)
Dogri Text 1 (SMT): 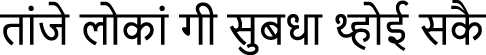 (tāanje lokāan gī subadhā thhoī sakai)
(tāanje lokāan gī subadhā thhoī sakai)
Dogri Text 1 (RNN): तांजे लोकें गी सुबधा िमली सकै (tāanje lokean gī subadhā milī sakai)
Dogri Text 1 (BRNN-32): 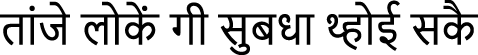 (tāanje lokean gī subadhā thhoī sakai)
(tāanje lokean gī subadhā thhoī sakai)
Dogri Text 1 (BRNN-64): तांजे लोकें गी सुबधा िमली सकै (tāanje lokean gī subadhā milī sakai)
Hindi Text 2:  (maiṅ bas sē yātrā kar rahā hūṅ)
(maiṅ bas sē yātrā kar rahā hūṅ)
Dogri Reference Text 2:  (mean bassa thamāan jāttarā karā dā āan)
(mean bassa thamāan jāttarā karā dā āan)
Dogri Text 2 (RBMTS):  (mean bassa shā jātarā karā dā āan)
(mean bassa shā jātarā karā dā āan)
Dogri Text 2 (SMT):  (mean bassa par yātrā karā dā āan)
(mean bassa par yātrā karā dā āan)
Dogri Text 2 (RNN): में बस्स थमां जात्तरा करा दा आं (mean bassa thamāan jāttarā karā dā āan)
Dogri Text 2 (BRNN-32):  (maian bas thamāan jāttarā karai karade āan)
(maian bas thamāan jāttarā karai karade āan)
Dogri Text 2 (BRNN-64): 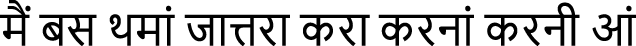 (maian bas thamāan jāttarā karā karanāan karanī āan)
(maian bas thamāan jāttarā karā karanāan karanī āan)
Hindi Text 3: 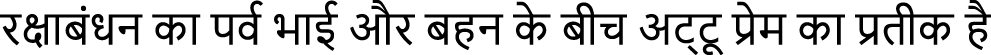 (rakṣhābandhan kā parva bhāī aur bahan ke bīch aṭṭū prem kā pratīk hai)
(rakṣhābandhan kā parva bhāī aur bahan ke bīch aṭṭū prem kā pratīk hai)
Dogri Reference Text 3: 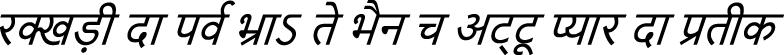 (rakkhaṭī dā parva bhrā’ te bhain ch aṭṭū pyār dā pratīk)
(rakkhaṭī dā parva bhrā’ te bhain ch aṭṭū pyār dā pratīk)
Dogri Text 3 (RBMTS): 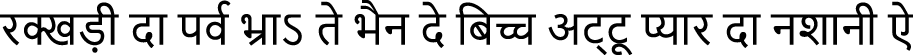 (rakkhaṭī dā parva bhrā’ te bhain de bichcha aṭṭū pyār dā nashānī ai)
(rakkhaṭī dā parva bhrā’ te bhain de bichcha aṭṭū pyār dā nashānī ai)
Dogri Text 3 (SMT): 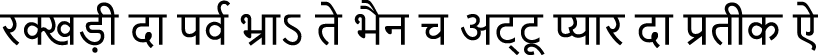 (rakkhaṭī dā parva bhrā’ te bhain ch aṭṭū pyār dā pratīk ai)
(rakkhaṭī dā parva bhrā’ te bhain ch aṭṭū pyār dā pratīk ai)
Dogri Text 3 (RNN): 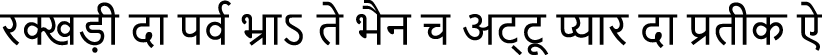 (rakkhaṭī dā parva bhrā’ te bhain ch aṭṭū pyār dā pratīk ai)
(rakkhaṭī dā parva bhrā’ te bhain ch aṭṭū pyār dā pratīk ai)
Dogri Text 3 (BRNN-32): 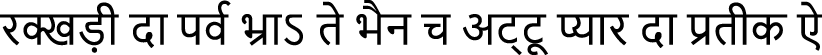 (rakkhaṭī dā parva bhrā’ te bhain ch aṭṭū pyār dā pratīk ai)
(rakkhaṭī dā parva bhrā’ te bhain ch aṭṭū pyār dā pratīk ai)
Dogri Text 3 (BRNN-64): 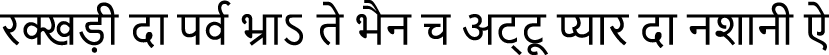 (rakkhaड़ī dā parva bhrā’ te bhain ch aṭṭū pyār dā nashānī ai)
(rakkhaड़ī dā parva bhrā’ te bhain ch aṭṭū pyār dā nashānī ai)
Conclusion
This study presents a comparative evaluation of three machine translation (MT) approaches—RBMTS, SMT, neural (RNN and BRNN with batch sizes of 32 and 64)—for Hindi-to-Dogri translation. Each method exhibits distinct strengths and limitations, making the choice of MT system highly dependent on language pair characteristics, domain specificity, data availability, and intended application. From the automatic evaluation, it was observed that RBMTS performs optimally for short and structurally simple sentences due to its reliance on handcrafted linguistic rules. However, as sentence complexity and length increase, neural models—particularly the BRNN with batch size 32—demonstrate superior performance across BLEU, METEOR, TER, and WER metrics. This model captures semantic and contextual nuances more effectively, offering a balanced solution for varying sentence lengths. SMT, while more robust than basic NMT models, consistently lags behind both RBMTS and BRNNs models. The human evaluation further supports these findings. RBMTS retains structural and grammatical fidelity and demonstrates high adequacy in meaning preservation. However, it introduces semantic rigidity, occasionally leading to ambiguity. In contrast, data-driven neural models—especially BRNN-32—yield more fluent and natural Dogri translations, showing better clarity and improved handling of ambiguous phrases. Among all evaluated systems, BRNN-32 achieves the best overall human ratings for fluency and ambiguity while maintaining competitive adequacy scores. A common limitation across all systems was their inability to handle out-of-vocabulary (OOV) or unknown words. In the case of RBMTS, such words were simply retained in the translation without being translated. Addressing this issue through advanced techniques like subword units, back-translation, or named entity recognition could substantially improve translation. Overall, while RBMTS remains a strong contender for low-resource, syntax-aligned language pairs like Hindi-Dogri, the results indicate that neural models—especially BRNNs—are better suited for scalable, flexible translation systems. With access to larger and more diverse parallel corpora, SMT and NMT models are expected to significantly improve in both adequacy and fluency. Future work will explore hybrid MT architectures that leverage the linguistic precision of RBMTS with the contextual depth of NMT, aiming to develop robust systems capable of delivering high-quality translations across diverse linguistic contexts.