
MKL-GRNI: A parallel multiple kernel learning approach for supervised inference of large-scale gene regulatory networks
- Published
- Accepted
- Received
- Academic Editor
- Othman Soufan
- Subject Areas
- Bioinformatics, Computational Biology, Data Mining and Machine Learning
- Keywords
- Gene regulatory networks, GRN inference, large-scale GRN, Systems biology, Network biology
- Copyright
- © 2021 Wani and Raza
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2021. MKL-GRNI: A parallel multiple kernel learning approach for supervised inference of large-scale gene regulatory networks. PeerJ Computer Science 7:e363 https://doi.org/10.7717/peerj-cs.363
Abstract
High throughput multi-omics data generation coupled with heterogeneous genomic data fusion are defining new ways to build computational inference models. These models are scalable and can support very large genome sizes with the added advantage of exploiting additional biological knowledge from the integration framework. However, the limitation with such an arrangement is the huge computational cost involved when learning from very large datasets in a sequential execution environment. To overcome this issue, we present a multiple kernel learning (MKL) based gene regulatory network (GRN) inference approach wherein multiple heterogeneous datasets are fused using MKL paradigm. We formulate the GRN learning problem as a supervised classification problem, whereby genes regulated by a specific transcription factor are separated from other non-regulated genes. A parallel execution architecture is devised to learn a large scale GRN by decomposing the initial classification problem into a number of subproblems that run as multiple processes on a multi-processor machine. We evaluate the approach in terms of increased speedup and inference potential using genomic data from Escherichia coli, Saccharomyces cerevisiae and Homo sapiens. The results thus obtained demonstrate that the proposed method exhibits better classification accuracy and enhanced speedup compared to other state-of-the-art methods while learning large scale GRNs from multiple and heterogeneous datasets.
Introduction
The problem of understanding gene interactions and their influence through network inference and analysis is of great significance in systems biology (Albert, 2007). The aim of this inference process is to establish relationships between genes and construct a network topology based on the evidence provided by different data types. Among various network inference studies, gene regulatory network inference (GRNI) has remained of particular interest to researchers with extensive scientific literature generated in this domain. Gene regulatory networks (GRNs) are biological networks where genes serve as nodes and the edges connecting them serve as regulatory relations (Lee et al., 2002; Raza & Alam, 2016). Standard methods for GRN inference such as RELNET (Butte & Kohane, 1999), ARACNE (Margolin et al., 2006), CLR (Faith et al., 2007), SIRENE (Mordelet & Vert, 2008) and GENIE3 (Huynh-Thu et al., 2010) mostly use transcriptomic data for GRN inference. Among these methods, our approach is modeled along the same principle as SIRENE. SIRENE is a general method to infer unknown regulatory relationships between known transcription factors (TFs) and all the genes of an organism. It uses a vector of gene expression data and a list of known regulatory relationships between known TFs and their target genes. However, integration of this data with other genomic data types such as protein–protein interaction (PPI), methylation expression, sequence similarity and phylogenetic profiles has drastically improved GRN inference (Hecker et al., 2009). A comprehensive list of state-of-the-art data integration techniques for GRN inference has been reviewed in (Wani & Raza, 2019a).
In this article, we aim to integrate gene expression, methyl expression and TF-DNA interaction data using advanced multiple kernel learning (MKL) library provided by shogun machine learning toolbox (Sonnenburg et al., 2010) and design an algorithm to infer gene regulatory networks (GRNs). Besides, we also integrate PPI data and other data such as gene ontology information as source of prior knowledge to enhance the accuracy of network inference. The problem of network inference is modeled as a binary classification problem whereby a gene being regulated by a given TF is treated as a positive label and negative otherwise. To infer a large-scale network, the MKL model needs to be trained for each TF with a set of known regulations for the whole genome. Given N TFs, we need to train N different classification models individually and then combine the results from these models for a complete network inference task. As the number of TFs increase, the number of classification models also increase, creating resource deficiency and long execution times for the inference algorithm. The proposed approach attempts to provide a solution to this problem by distributing these classification models to different processors on a multi-processor hardware platform using parallel processing library from Python. The results from these models are stored in a shared queue object which are later on used for network inference. A detailed description of the model is contained in the methods section.
Materials and Methods
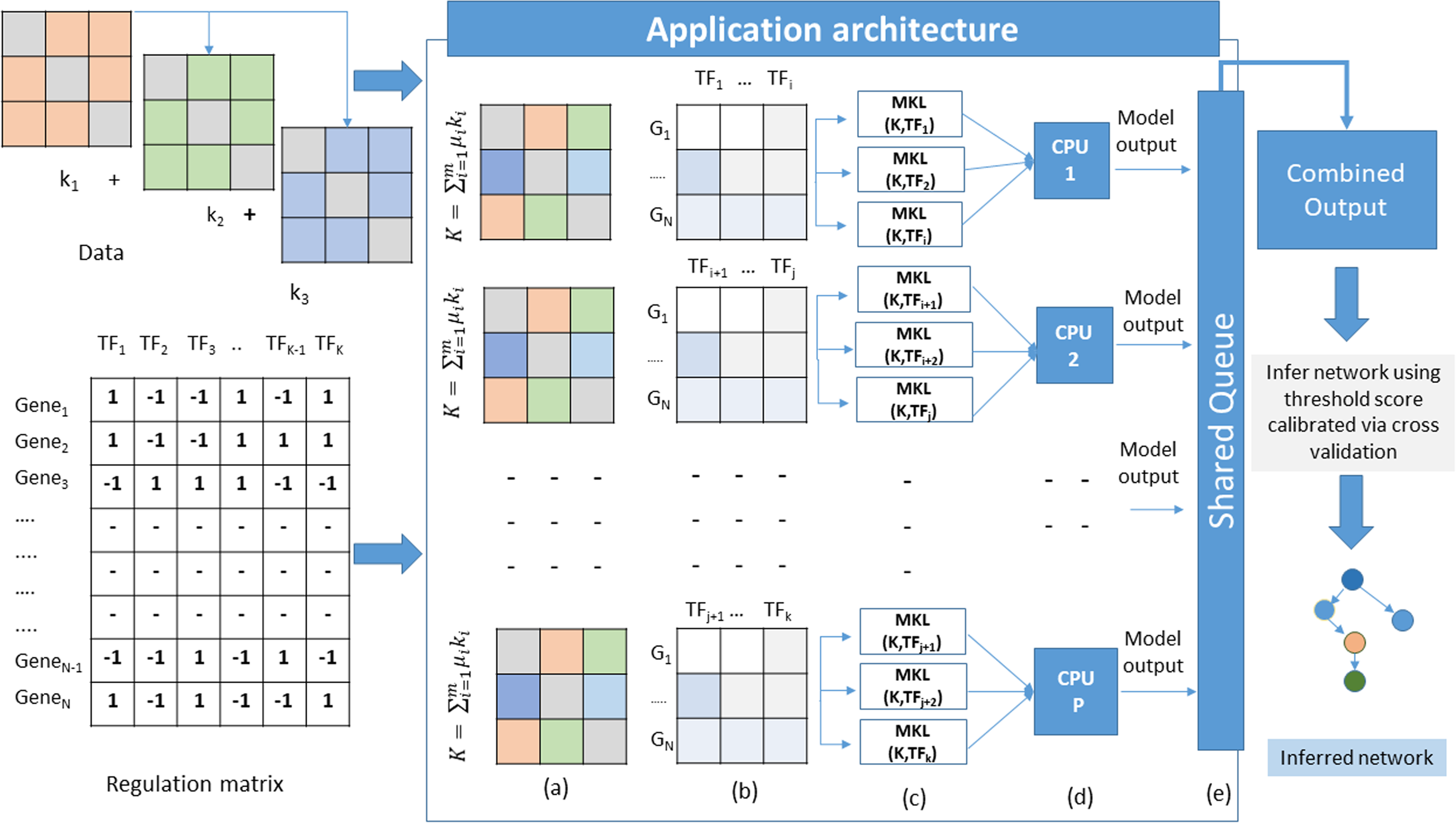
The proposed method adopts a supervised approach to learn new interactions between a TF and the whole genome of an organism. The algorithm operates on multiple datasets that characterize the genes of an organism. Since we are adopting an integrated approach, datasets such as gene expression, known TF-gene regulations, PPI, and DNA-methylation data can be combined using MKL approach. All these datasets are carefully chosen owing to their role in gene regulation. The TF-gene interaction data serves a dual purpose. It supplies the algorithm with prior knowledge about the regulatory relationships, and for each TF, the known target gene list also form the labels for the MKL classifier. For each TF, a set of known gene targets serve as positive examples. For negative examples, we divide our input into two subsets; the MKL classifier is trained using positive examples for which no prediction is needed, and the other subset contains negative examples. We perform 10-fold cross-validation using the same scheme and obtain discriminant values for all the genes with no prior regulation knowledge for this TF. This whole procedure is repeated for all the TFs. The idea here is to identify the set of genes whose expression profiles match those of positive examples even though the classifier is supplied with some false negative examples in the training set. A graphical overview of this architecture is depicted in Fig. 1. The problem of GRN inference from integrated datasets through supervised learning using MKL is not a trivial task. The nature of the complexity raises manifold while considering GRN inference of organisms with large genomes sizes. In this scenario, the model training and testing becomes TF specific. Therefore, the inference problem is decomposed into a set of classification subproblems corresponding to the total number of TFs present in the input Gene-TF interaction matrix. A sequential approach to such a problem scenario would require to run each subproblem one after the other in a loop. However, as we increase the number of TFs, the execution time of the algorithm also increases. To overcome such problems, we devise a strategy of parallel execution for the algorithm wherein multiple subproblems run simultaneously across different processors of a multi-processor hardware platform as explained in Algorithm 1.
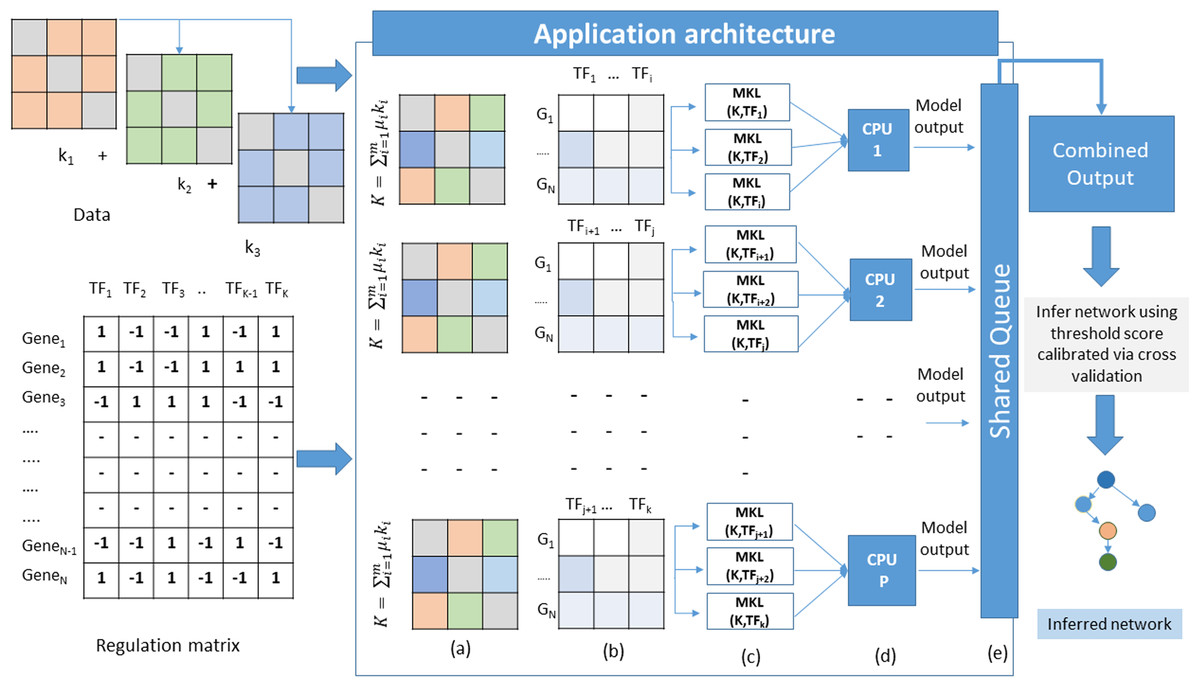
Figure 1: Application architecture of MKL-GRNI (A) Combined kernel (B) Decomposed regulation matrices (C) Parallel distribution and model building (D) Model execution (E) Writing results to shared object.
{kind=link}
| Input: k datasets D1, D2, . . . ., Dk |
| Input: Regulation binary matrix R for Classification labels |
| Output: A matrix of decision scores DS for TF-Gene interaction |
| begin |
| Transform D1, D2, . . . ., Dk int k1, k2, . . . ., kn kernels using appropriate kernel function |
| Fuse n Kernels as K = k1 + k2+…+kn |
| define mkl parameters params (C, norm, epsilon) |
| /* Distribute Source TF’s among multiple CPU’s*/ |
| foreach cpu in the cpu list do |
| do in parallel |
| foreach TF in source TF list do |
| /* Set MKL parameters and Data */ |
| set mkl.kernel ← K |
| set mkl.labels ←R |
| set mkl.parameters ← params |
| /* Obtain decision scores for MKL algorithm between each TF and all genes in the genomes*/ |
| DSTF ← ApplyMKL() |
| end |
| put DSTFk in queue Q |
| end |
| end |
| foreach q in Q do |
| DSTFk ← q.val |
| end |
| end |
Outputs generated by each model in the form of confidence scores (probability that a given TF regulates a gene) are stored in a shared queue object. Once all the subproblems finish their execution, the shared object is iterated to collect the results generated by all the models in order to build a single output matrix. In case the number of TFs is more than the number of available processors, they are split into multiple groups and dispatched to each processor with the condition that the number of TFs are divided in such a manner so that all the processors receive equal number of classification models.
Kernel methods for genomic data fusion
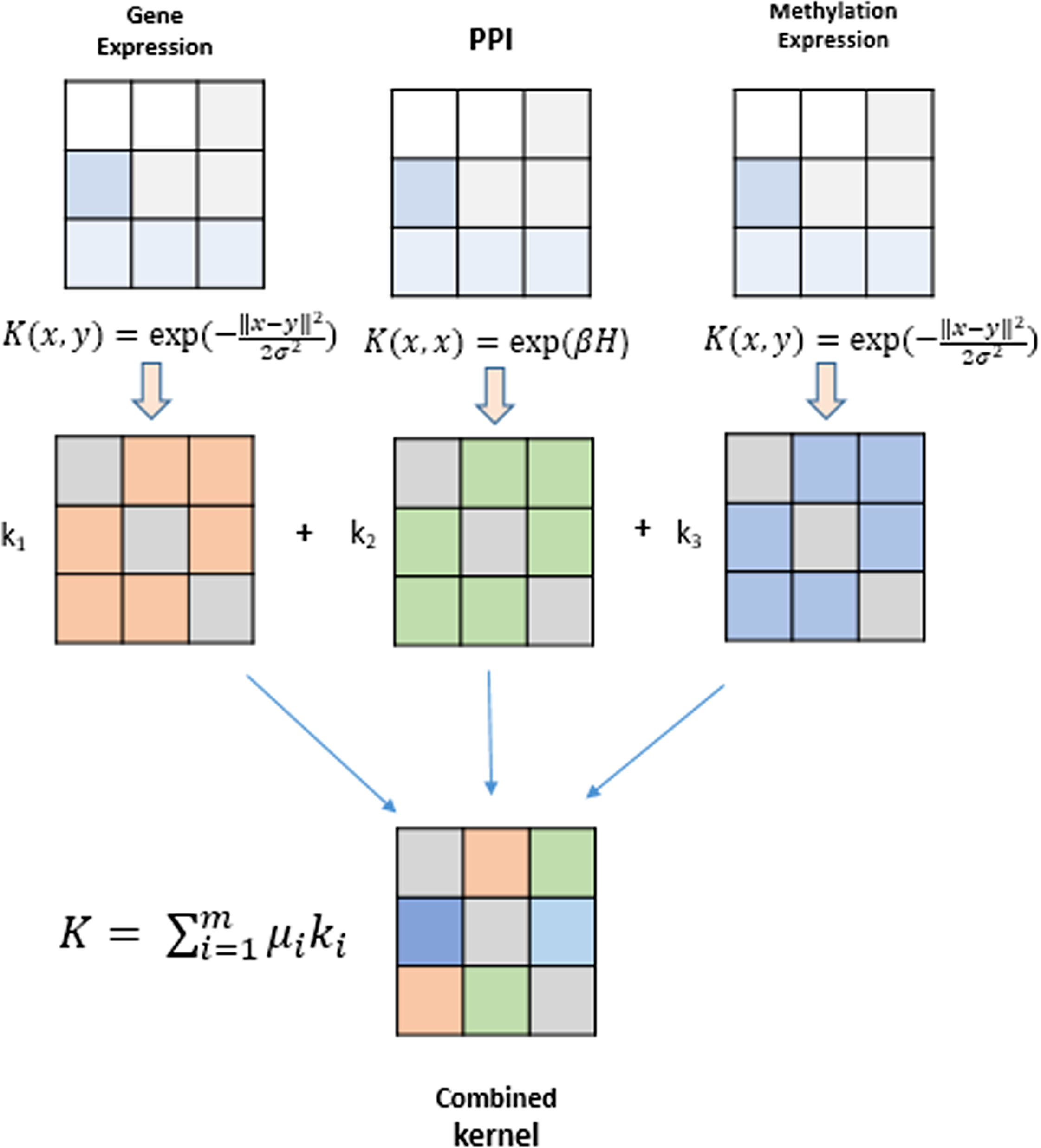
Kernel methods represent a mathematical framework which embeds data points (genes, proteins, drugs, etc) from input spaceIto feature space F by employing a kernel function. Genomic datasets viz., mRNA expression levels from RNA-seq, DNA methylation profiles and TF-gene regulation matrix obtained from different databases comprise heterogeneous datasets that can be fused using kernel methods and serve as the building blocks for inference of gene regulatory networks. A modular and generic approach to pattern analysis, kernel methods can operate on very high dimensional data in feature space by performing an inner product on the input data using a kernel function (Shawe-Taylor & Cristianini, 2004). An algorithm is devised that can work with such data and learn patterns. Such an algorithm is more generic as they operate on any data type that can be kernelized. These kernels are data specific, such as Gaussian, polynomial and sigmoid kernels for vectorial data, diffusion kernels for graph data, and string kernels for different types of sequence data. The kernel part is data specific, creating a flexible and modular approach to combine multiple modules to obtain complex learning systems. A graphical depiction of this fusion technique is shown in Fig. 2. The choice of different kernel functions for transforming datasets into their respective kernel matrices is made after a thorough analysis of literature in the field of kernel methods and MKL methods.
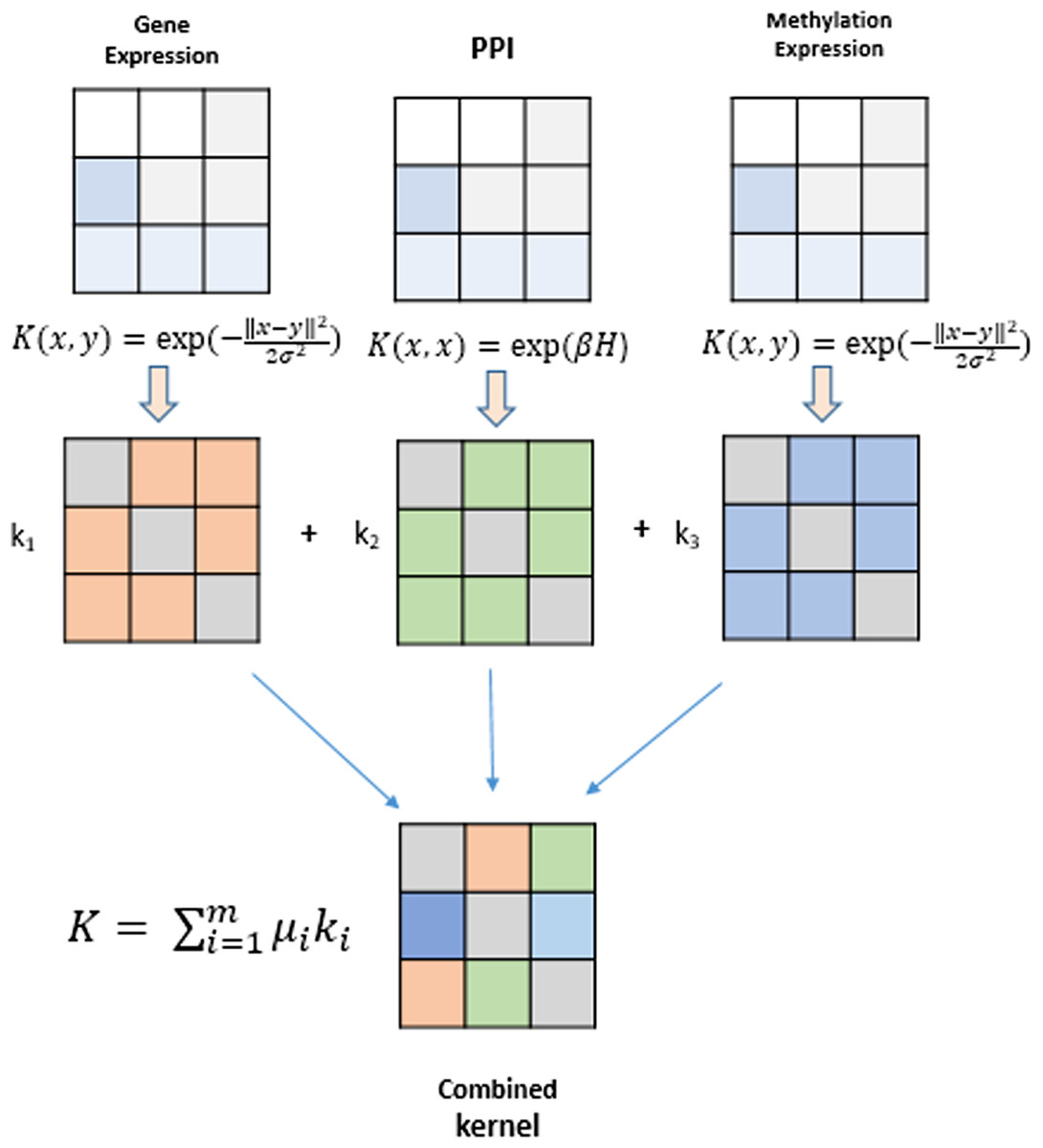
Figure 2: Genomic data fusion by combining kernel matrices from multiple kernels into a single combined kernel.
{kind=link}
MKL model
Multiple kernel learning is based on integrating many features of objects such as genes, proteins, drugs, etc., via their kernel matrices and represents a paradigm shift from machine learning models that use single object features (Sonnenburg et al., 2006). This combined information from multiple kernel matrices is provided as an input to MKL algorithm to perform classification/regression tasks on unseen data. Information represented by the kernel matrices can be combined by applying the basic algebraic operations, such as addition, multiplication, and exponentiation such that the positive semi-definiteness of the candidate kernels is preserved in the final kernel matrix. The resultant kernel can be defined by following equations using k1 and k2 as candidate kernel matrices and ϕ1(x) and ϕ2(x), their corresponding embedding in the feature space.
(1) with the new induced embedding (2)
Given a kernel set K = {k1, k2, …, km}, an affine combination of m parametrized kernels can be formed as given by: - (3) subject to the constraint that μi (weights) are positive that is, μi ≥ 0, i = 1……..m. With these kernel matrices as input, a statistical classifier such as SVM separates the two classes using a linear discriminant by inducing a margin in the feature space. To find this discriminant, an optimization problem, known as a quadratic program (QP) needs to be solved. QP belongs to a class of convex optimization problems, which are easily solvable. Shogun toolbox solves this MKL optimization problem using semidefinite programing (SDP) first implemented for MKL learning by Lanckriet et al. (2004). Based on this margin, we classify SVM algorithms into hard, 1-norm soft and 2-norm soft margin SVM. Here we use the 1-norm soft margin SVM and SDP for MKL optimization and classification from heterogeneous datasets explained in our earlier work on MKL for biomedical image analysis (Wani & Raza, 2018). A detailed literature on SVM algorithms is covered in (Scholkopf & Smola, 2001).
Datasets
To test the parallel MKL algorithm on multiple datasets, we downloaded gene expression data of Escherichia coli and Saccharomyces cerevisiae from DREAM5 Network inference challenge (Marbach et al., 2012) along with their gold standard network and human breast cancer transcriptomic data from TCGA. Some prominent features of these data are shown in Table 1.
| Organism | Genes | Samples | Transcription factors | Known regulations | Known targets |
|---|---|---|---|---|---|
| E. coli | 4,297 | 805 | 140 | 1,979 | 953 |
| S. cerevisiae | 5,657 | 536 | 120 | 4,000 | 2,721 |
| Homo sapiens | 19,201 | 1,212 | 66 | 73,052 | 12,028 |
Because the MKL paradigm provides the platform to fuse heterogeneous datasets, we download PPI data for both E. coli and S. cerevisiae from STRING database (Szklarczyk et al., 2011). The PPI data is supplied as prior biological knowledge to the algorithm in order to improve its inference accuracy as MKL can learn from multiple datasets. To supplement the human transcriptome with additional biological knowledge, we download DNA methylation expression data for all the genes in the transcriptome from the TCGA broad institute data portal (https://gdac.broadinstitute.org/). The regulation data (i.e., known interaction between genes and TFs) for E.coli and S. cerevisiae were extracted from the gold standard network provided in the DREAM dataset, however, for GRN inference in humans, the regulation data has been collected from a number of databases that store TF-gene interaction data derived from ChIP-seq and ChIP-ChIP experiments. We collected a list of 66 TFs from the ENCODE data portal (https://www.encodeproject.org/) for which ChIP-seq experiments were carried out on MCF7 breast cancer cell lines across different experimental labs. The targets of these TFs were extracted from ENCODE (ENCODE Project Consortium, 2004), TRED (Jiang et al., 2007) and TRRUST (Han et al., 2015) databases.
Hardware and software requirements
The hardware platform used in this study is an IBM System X3650 M4 server model that includes an Intel Xeon processor having 24 cores and a primary memory of 32 GB with extendable option of 64 GB. The system supports a 64-bit memory addressing scheme having powerful 3.2 GHz/1066 MHz Intel Xeon processors with 1066 MHz front-side bus (FSB) and 4 MB L2 cache (each processor is dual core and comes with 2 × 2 MB (4 MB) L2 cache). The system also supports hyper threading features for more efficient program execution. In order to exploit this multi-core and multithreading features present in the hardware system we used multiprocessing Python package to dispatch different sub-problems across multiple cores of the computing system. The process of distribution of different learning sub-problems among different cores of a multi-core machine has been demonstrated in Fig. 1. For fusion of multiple datasets we use MKL approach whereby different datasets are first converted into similarity matrices (Kernels) and then joined to generate a final integrated matrix for learning TF-gene targets. We use MKL Python library provided by Shogun Machine Learning toolbox for implementing the proposed algorithm.
Results
All the genomic datasets are transformed into their respective kernel matrices by using an appropriate kernel function. For example, datasets such as gene expression and DNA methylation expression data are transformed using a Gaussian radial basis function. The PPI data is converted into a diffusion kernel, K = eβH, where H is the negative Laplacian derived from adjacency and Degree matrix H = A − D of PPI graph. The TF-Target gene regulation data is organized as a binary matrix of labels (i.e., 1 and −1) with genes in rows and TFs in columns. The number of rows correspond to the genome size of the organism and the number of columns correspond to the total number of TFs being used for GRN inference. The elements of each column with value 1 signify that a gene gi is regulated by TFj and −1 otherwise. Such an organization of the regulation data allows us to use each column of the matrix as a label for individual classification problems in a supervised learning environment.
We perform two sets of experiments with our proposed approach in order to evaluate the scalability and the inference potential of the supervised learning from heterogeneous datasets using MKL paradigm. Our first experiment records execution times required to learn from varying genome and sample sizes on single and multi-processor architectures, given a set of TFs. Our second experiment focuses on the evaluation of inference potential of this approach on different genome and sample sizes. Since our problem of GRN inference is complex, the experiment aims to evaluate the parallel nature of the MKL algorithm by decomposing supervised inference of GRNs for multiple TFs into a number of subproblems and distribute them to multiple processors for parallel execution. Varying the genome and sample sizes in these experiments is to evaluate how efficiently MKL based models scale to large genomes where most of the GRN models developed till date do not perform optimally as reported in Marbach et al. (2012). The proposed method is implemented in Python and the code along with data is available at (https://github.com/waninisar/MKL-GRNI).
To assess the performance of the parallel MKL-GRNI on different genomes characterized by datasets in Table 1. We execute the algorithm and embed the required code for the evaluation metrics. Once the algorithm completes its execution run, all the essential metrics are recorded for further analysis. The metrics are computed to evaluate the capacity of our approach in terms of reduced computational cost and enhanced inference accuracy when dealing with complex and large-scale inference tasks. Initially the algorithm is run in sequential mode for all the organisms for a set of 32 TFs, and later on in parallel mode on 8 and 16 CPUs. Performance metrics for all the datasets are plotted in Fig. 3. A brief description of these important performance metrics is given below:
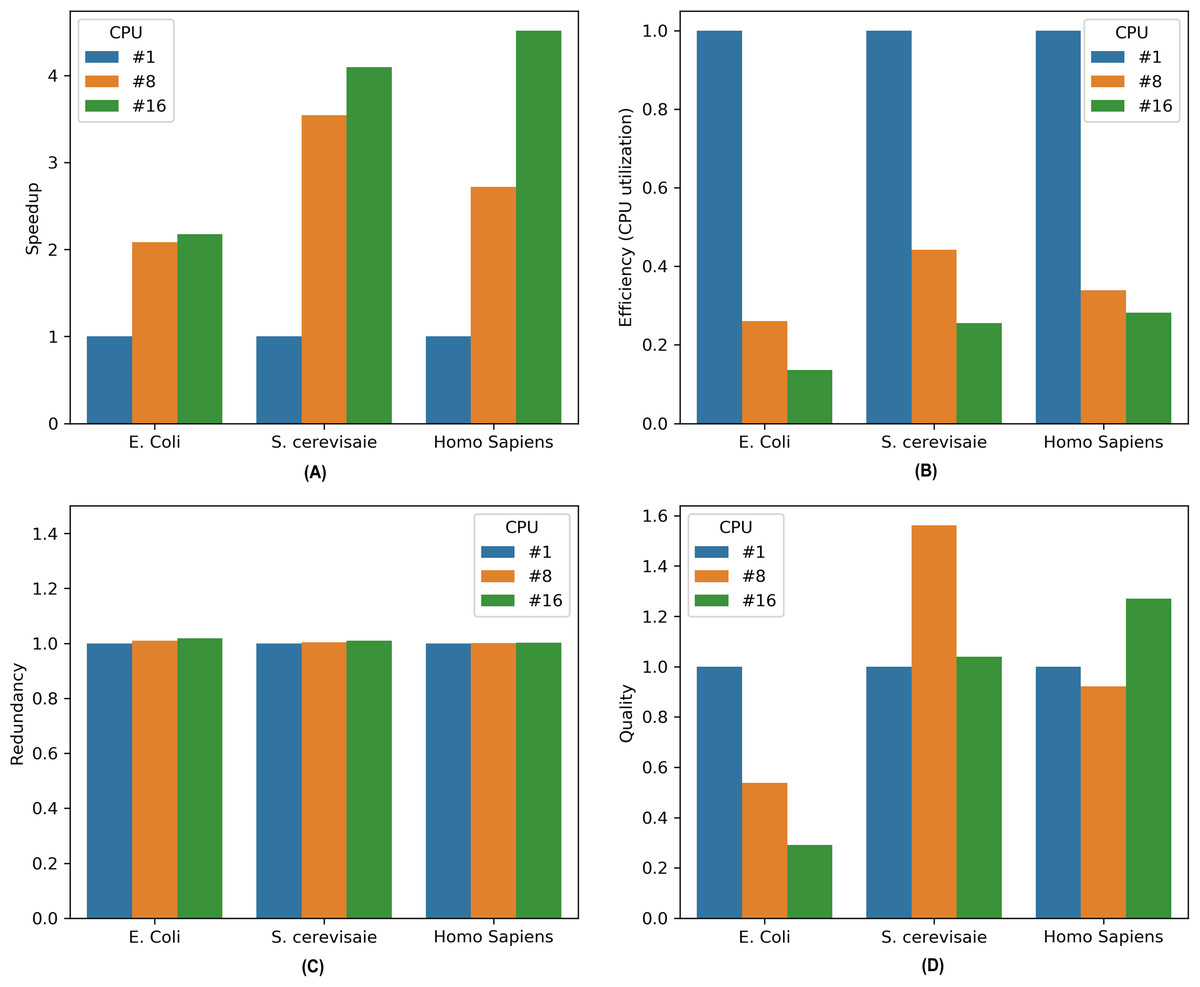
Figure 3: Performance metrics for parallel MKL-GRNI algorithm: (A) Speedup, (B) Efficiency, (C) Redundancy, (D) Quality.
{kind=link}
Speedup
We calculate speedup as a measure of relative performance of executing our algorithm in sequential and parallel processing environments. The speed up is calculated as under:- (4)
Where S(j) is the speedup on j processors, T(1) is the time it takes on a single processor and T(j) is the time program takes on j processors.
Efficiency
Efficiency is defined as the ratio of speedup to the number of processing elements (j CPUs in our case). It measures the utilization of the computation resources for a fraction of time. Ideally in parallel system, speedup is equal to j and efficiency is equal to 1. However, in practice, speedup is less than j and efficiency is between zero and one, depending on the effectiveness with which the processing elements are utilized. We calculate efficiency E(j) on j processors as given below: (5)
Redundancy
Redundancy is computed as the ratio between number of operations executed in parallel and sequential modes. It measures the required increase in the number of computations when the algorithm is run on multiple processors.
(6)Quality
Quality measures the relevance of using parallel computation and is defined as the ratio between the product of speedup and efficiency to that of redundancy.
(7)It is evident from the Fig. 1 that there is marked increase in the speedup as we move from a sequential (single CPU) to parallel execution (i.e., 8 and 16 CPUs). For an E. coli genome with a sample size of 500 and 32 TFs used for inference, the algorithm shows a sharp speedup as we move from sequential execution to parallel execution on 8 processors, however when the number of processors is increased to 16, there is marginal increase in speedup for E. coli. On the other hand, there is considerable increase in speedup recorded for 8 and 16 processors on higher genomes, such as S. cerevisiae and Homo sapiens, suggesting an increase in the capacity of the parallel algorithm to reduce the execution times. To assess the resource utilization using our parallel approach, the efficiency metric shows considerable drop in utilization of compute resources for all the three datasets, because only a section of algorithm runs in parallel. This can be inferred from the computed redundancy for sequential and parallel executions. The redundancy plot shows slight increase in terms of the computational cost incurred when running our computational problem in parallel, thereby suggesting less computational overhead as we switch from sequential to parallel mode of execution. To evaluate the relevance of parallel execution to our problem, we calculate quality metric for all the three datasets. From the barplots we can observe that parallel algorithms are less relevant when applied to smaller genomes as is evident in case of E. coli. But there is steady improvement in quality metric as move from S. cerevisiae to Homo sapiens with relevance indicator high when yeast dataset is run on 8 processors and human dataset on 16 processors. These improvements in speedup and quality metrics when running the algorithm in parallel provides us with a framework to work with more complex datasets and organisms with large genome sizes to infer very large scale GRNs using a supervised approach.
To assess the inference potential of this supervised method we compare the proposed approach with other methods that infer gene interactions from single and integrated datasets. Initially we apply MKL-GRNI to DREAM5 E.coli data, we performed a 10-fold cross-validation to make sure that model is trained on all the known regulations. At each cross-validation step, important performance metrics such as precision, recall and F1 score are recorded and then averaged for the whole cross-validation procedure. We then compared our network inference method with inference methods that predict TF-target gene regulations, such as CLR (Faith et al., 2007) and SIRENE (Mordelet & Vert, 2008). The results are recorded in Table 2.
| Method | Average precision | Average recall | Average F1 score |
|---|---|---|---|
| CLR | 0.275 | 0.55 | 0.36 |
| SIRENE | 0.445 | 0.73 | 0.55 |
| MKL-GRNI | 0.46 | 0.97 | 0.62 |
After running all the inference procedures, it is observed that the average precision , recall and F1 metrics generated by running MKL-GRNI is quite higher than those generated by other comparable methods. The improvement with MKL-GRNI can be attributed to the additional biological knowledge in the form of protein-protein interactions between E.coli genes to aid in the inference process.
To test the proposed method on integrated data, We perform a 10 fold cross-validation procedure on the input data. In this experiment, the known target genes of each organism as depicted in Table 1 are split into training and test sets. The model is trained on the features from the training set, and the network inference is performed between the genes in the test set, important evaluation metrics, such as Precision, Recall and F1 scores are recorded for each iteration and averaged across cross-validation runs. Table 3 summarizes these metric for varying genome and sample size for human breast cancer dataset and Table 4 contains results for all the three genomes.
| No. of genes | No. of samples | Average recall | Average Precision | Average F1 measure |
|---|---|---|---|---|
| 5,000 | 100 | 0.8005 | 0.5817 | 0.6582 |
| 5,000 | 500 | 0.8005 | 0.6169 | 0.6848 |
| 5,000 | 1,000 | 0.8354 | 0.6347 | 0.6968 |
| 10,000 | 100 | 0.7350 | 0.4406 | 0.5509 |
| 10,000 | 500 | 0.7660 | 0.4537 | 0.5699 |
| 10,000 | 1,000 | 0.7860 | 0.4937 | 0.6065 |
| 19,201 | 100 | 0.7499 | 0.3746 | 0.4996 |
| 19,201 | 500 | 0.7444 | 0.3893 | 0.5112 |
| 19,201 | 1,000 | 0.7499 | 0.4246 | 0.5422 |
| Organism | No. of genes | No. of samples | Avg. precision | Avg. recall | Avg. F1 measure |
|---|---|---|---|---|---|
| E. coli | 4,297 | 802 | 0.46 | 0.97 | 0.62 |
| S. cerevisiae | 5,657 | 536 | 0.42 | 0.84 | 0.56 |
| Homo sapiens | 19,201 | 1,012 | 0.37 | 0.73 | 0.49 |
It is evident from these results that the MKL-GRNI algorithm scales well for higher genomes sizes. These metrics highlight the learning and inference potential of MKL. Looking at Table 3 we observe an average recall of 80% and an average precision of 58% with an average F1 measure of 65% for a genome size of 5,000 and sample size of 100, with an increase in these metrics as we increase the sample size to 500 and 1,000 respectively. However, as we start increasing the size of the genome, these metrics start a gradual decline for smaller sample size and again show a marginal increase as we increase the sample size for a fixed genome size. Although there is no direct rule of determining the number of samples corresponding to the size of the genome in omics studies, the improvements in precision, recall and F1 measures suggests an improvement in learning and inference potential of MKL algorithm with an increase in the number of samples. Also the tabulated metrics for all the three genomes in Table 4 show a considerable decline in the evaluation metrics as we move from smaller to larger genomes, suggesting a decrease in inference potential of the algorithm for larger datasets. The possible decline in the performance metrics can be attributed to increase in the genome size as we move from simple prokaryotic to more complex eukaryotic genomes. This increase in the genome sizes versus the sample size leads to curse of dimensionality and therefore making difficult to learn properly from skewed datasets.
We also compare our MKL-GRNI with a recently developed Integrative random forest for gene regulatory network inference (iRafNet) (Petralia et al., 2015). We select DREAM5 datasets of E. coli and S. cerevisiae and integrate PPI and gene expression data from both datasets. For MKL we build Gaussian and diffusion kernels from expression and PPI data. For iRafNet , the expression data serves as the main data and the PPI data is used as support data. Sampling weights are then derived from PPI data by building a diffusion kernel as K = eH where H is a graph laplacian for PPI data. Sampling weights from K are derived as WPPIi, j = K(i, j) that is, the element K (i,j). The sampling weights thus obtained are then integrated with main data set (i.e., gene expression data). Putative regulatory links are then predicted using importance scores generated using the iRafNet R package. The AUC and AUPR scores obtained using iRafNet and MKL-GRNI are listed in Table 5.
| Datasets | iRafNet | MKL-GRNI | ||
|---|---|---|---|---|
| AUC | AUPR | AUC | AUPR | |
| E. coli | 0.901 | 0.552 | 0.925 | 0.44 |
| S. cerevisiae | 0.833 | 0.39 | 0.89 | 0.42 |
The AUC and AUPR scores of MKL-GRNI thus obtained are comparable to iRafNet for both datasets. However, iRafNet reports a lower AUC and higher AUPR scores compared to MKL-GRNI when run on E. coli data. But once we move towards a higher genome size, these scores start dropping marginally for both iRafNet and MKL-GRNI approaches. The slight higher AUC scores in case of MKL-GRNI can be attributed to some extent to the skewed class label distribution where in negative labels far outnumber the positive ones because of limited known regulations. This class imbalance leads to higher predictive accuracy (AUC) but lower precision-recall scores (AUPR). On the other hand regression based GRN inference techniques have been reported to perform well for smaller genomes with GENIE3 (Huynh-Thu et al., 2010) being a start performer in DREAM5 network inference challenges. The higher AUPR generated by iRafNet in case of E. coli can be attributed to the way potential regulators are sampled using prior information from sampling weights (PPI), therefore decreasing false positives and increasing precision and recall. But for higher genomes (i.e, yeast in our case) the performance of both approaches begins to fall as reported by (Mordelet & Vert, 2008). Present implementation of iRafNet does not provide the ability to run the random forest algorithm in parallel. Therefore, using iRafNet for GRNI of higher genomes can incur huge computational cost by running thousands of decision trees in sequential mode. Since our main motive in this study is to parallelize the inference algorithm for large-scale GRNI, the higher speedup and higher quality provided by running MLK-GRNI in parallel can be used as a trade-off for slightly lower AUPR compared to iRafNet run in sequential mode with marginally higher AUPR scores.
Discussion and Conclusion
Here we present a scalable and parallel approach to GRN inference using MKL as integration and supervised learning framework. The algorithm has been implemented in Python using Python interface to MKL provided by shogun machine learning toolbox (Sonnenburg et al., 2010). The ability of kernel methods in pattern discovery and learning from genomic data fusion of multi-omics data using MKL has already been demonstrated in a number of inference studies. Our focus here is to explore the scalability option for large-scale GRN inference in a supervised machine learning setting, besides assessing the inference potential across different genomes.
The approach undertaken can be considered as a parallel extension to SIRENE (Mordelet & Vert, 2008). Although SIRENE performs better than other unsupervised and information theoretic based inference methods as reported by (Mordelet & Vert, 2008). However, it lacks the ability to learn from heterogeneous genomic datasets that can provide essential and complementary information for GRN inference. Another limitation is the sequential execution of the TF-specific classification problems that incur the huge cost in terms of execution times as we move from E. coli genomes to more complex and large genomes of mice and humans. Therefore to facilitate very large scale GRN inference using supervised learning approach, we use the concept of decomposing the initial problems of learning GRN into many subproblems, where each subproblem is aimed to infer a GRN for a specific TF. Our algorithm distributes all such learning problems to different processors on a multi-processor hardware platform and dispatches them for simultaneous execution, thereby reducing the execution time of the inference process substantially. The results from each execution are written to a shared queue object, once all the child processes complete their execution, the queue object is iterated to build a single output matrix for genome-scale GRN inference. We also assess the inference potential of our MKL based parallel GRN inference approach by computing essential evaluation metrics for machine learning based approaches. A quick survey of scientific literature on GRN inference methods will ensure that the results obtained by our approach are comparable to other state-of-the-art methods in this domain and some cases better than inference methods that employ only gene expression data (e.g., CLR, ARACNE, SIRENE, etc. ). A drawback of our approach is that only TFs with known targets can be used to train the inference model. Also, the performance of the algorithm tends to decrease if the model training is carried out using TFs with few known targets, leading to a bias in favor of TFs with many known neighbors (i.e., hubs) and is less likely to predict new associations for TFs with very few neighbors. Besides, we are not able to identify new TFs among the newly learned interaction, nor the model can predict whether a given gene is upregulated or downregulated by a particular TF.
Therefore additional work is needed to improve the efficiency of the parallel algorithm and the inference potential of the MKL-GRNI. In our current implementation, we integrate only two datasets for GRNI, therefore leaving the scope to use more omics sources that can be integrated for improved performance of the inference model. Also, the MKL framework provides a mechanism to weigh the contribution of individual datasets that can be used to select informative datasets for integration. Further, we do not identify TFs from the predicted target genes and can be considered in future extension to this work. Besides, novel techniques to choose negative examples for training our parallel MKL-GRNI model can be incorporated to decrease the number of false positives and improve the overall precision/recall scores for genomes of higher organisms.